
结合YdUaVa颜色模型和改进MobileNetV3的视频烟雾检测方法*
2021-10-10 04:16程江华华宏虎罗笑冰
国防科技大学学报 2021年5期
刘 通,程江华,华宏虎,罗笑冰,程 榜
(国防科技大学 电子科学学院, 湖南 长沙 410073)
快速检测烟雾有利于及早发现火灾,降低火灾危害。传统的烟雾传感器需要烟进入传感器且浓度达到一定程度才能检测到烟雾,难以在室外开放空间使用。基于视觉的烟雾检测技术不受空间限制、覆盖区域大、成本低,是室外烟雾检测研究的主要方向[1]。就烟雾目标的视觉表现而言,颜色[2]、纹理[3]和运动[4]特征是常用的烟雾检测特征,基于这些传统特征检测烟雾目标通常具有复杂度低、检测效率高的优点,但往往检测正确率偏低,因为烟雾的颜色、纹理特征并不显著,运动特征受自然界的其他物体运动干扰较大,自然界中存在许多与烟雾类似的目标,如云等,导致烟雾目标的可靠检测非常困难。采用深度学习提取图像或者视频中的烟雾目标的深度特征,相比传统特征而言不受人为选择影响,特征泛化能力更强,在大数据集下性能通常优于传统特征,是近些年烟雾检测的主流方法。常用的卷积神经网络(Convolutional Neural Networks, CNN)、区域卷积神经网络(Region-CNN, R-CNN)等网络模型都可以用于烟雾目标的检测[5],也有专门针对烟雾特性优化的深度网络模型,如深度归一化卷积神经网络(Deep Normalization and Convolution Neural Network, DNCNN)[6]。该网络将传统CNN中的卷积层改进为批规范化卷积层,有效地解决了网络训练过程中梯度弥散和过拟合的问题,以此加速训练过程和提高检测效果;并且对训练样本进行了数据增强,从而解决正负样本不平衡和训练样本不足的问题。目前基于深度学习开展的烟雾检测研究主要是提取烟雾图像中的深度特征,没有充分利用烟雾运动特性的深层特征,在烟雾检测性能上还有待提升,尤其是虚警率还偏高。而且,采用深度网络通常运算效率偏低,难以满足烟雾视频检测应用对时效性的要求。
为进一步降低视频烟雾检测中的虚警率和提升检测效率,本文提出一种结合YdUaVa颜色模型和改进MobileNetV3的视频烟雾检测方法。首先提出YdUaVa颜色模型,描述相邻帧烟雾的运动和颜色变化特征;然后在分块图像中利用YdUaVa颜色模型粗筛选疑似烟雾图像块;最后结合烟雾快速检测要求改进MobileNetV3网络结构,实现视频中烟雾的快速可靠检测。
1 YdUaVa颜色模型
烟雾检测领域目前采用CNN、DCNN等深度网络来提升烟雾特征的显著性和稳健性,进而提升烟雾检测性能。通常是将RGB图像送入深度网络,在R、G、B三个通道上提取特征。然而,R、G、B三个通道不能很好地展示烟雾的视觉特性。通过对烟雾的视觉特性进行分析发现:烟雾的亮度会随着颗粒的浓度以及成分的变化而大幅变化,可能很亮,也可能很暗,但烟雾的色度比较均匀且稳定,而且烟雾是运动的,存在向上和向四周的扩散运动。基于此,提出YdUaVa模型,用于更好地描述烟雾的视觉特性。基本思路是:在YUV颜色模型上,计算Y空间上相邻帧图像的变化图像,用于反映烟雾的运动扩散特性;对U空间和V空间的图像进行均值滤波,用于反映烟雾的色度变化特性。具体地,对于视频中的第k帧图像,有:
(1)
(2)
(3)
图1展示了烟雾视频wildfire_smoke_4.avi[7]中RGB、YUV和YdUaVa三种模型在第115帧的对比情况。在RGB和YUV的各颜色分量中,烟雾与白云等颜色相近目标的差异不显著。在YdUaVa



图1 三种颜色模型对比Fig.1 Comparison of three color models
模型的三个分量中,运动的烟雾与类烟雾的白云有了较为明显的差异,而且烟雾与背景的颜色差异仍然得以体现。因此,采用YdUaVa模型既利于表征烟雾的运动特性,又能描述烟雾的颜色差异,更适于提取烟雾的显著和稳健特征。
2 疑似烟雾图像块检测
运用深度网络检测图像中的烟雾目标通常采用以下两种方式:
一是按照网络模型的输入要求将视频图像进行变换,之后送入网络模型得到图像的分类结果,如MobileNetV3的输入图像为224×224的三通道RGB图像。在实际图像中,烟雾区域通常只占据整幅图像中的一小部分,此时烟雾目标并不显著,难以训练较好的模型。
二是采用目标检测的思想,主要包括两类方法。一是two-stage的方法,如Fast R-CNN。此类方法先生成许多候选框,然后对每一个候选框进行分类和回归来完成目标分类工作,精度较高但效率偏低[8]。二是one-stage的方法,如SSD。此类方法通过一遍网络搜索即可得到目标的位置和类别信息,速度较快但仍难以满足实时视频检测的要求[9]。
事实上,对于森林火灾监测预警等视频烟雾检测应用而言,其主要任务是快速判断实时视频中某时刻是否存在烟雾,而并不关心烟雾的面积、轮廓等详细信息。因此,为了实现视频中烟雾目标的快速检测,采用分块的思想,先将图像划分为互不重叠的子块,然后将各子块的图像送入深度网络模型进行分类。与前述的第一种方式相比,在各个图像块中,烟雾目标的显著性会得到提升,便于训练出分类性能好的深度网络模型。与前述的第二种方式相比,图像块的数量与多尺度候选框的数量相比是非常小的,从而可以提升整体的运算效率。进一步地,还将对送入深度网络模型的图像块进行滤波处理,依据烟雾的运动和颜色特性筛选出疑似烟雾的图像块,仅将疑似烟雾区域的图像块送入深度网络模型进行分类,这样又将提升视频烟雾的检测效率。
图像分块的思路具体是:首先将输入图像的尺寸调整为560×448;然后按照从左到右、从上到下的顺序,将图像划分为互不重叠的56×56的图像子块,每幅图像共可划分为80个图像子块。需要解释的是,图像子块尺寸是为适应后续改进的MobileNetV3网络而定的,将后续网络的输入图像尺寸设计为56×56,可以更多地继承原网络的结构优势以及已训练好的模型资源。
对于每一个图像分块,依据烟雾的运动和颜色特性来检测疑似烟雾图像子块。具体是在YdUaVa颜色模型上,统计每一个图像子块中疑似烟雾像素点的数量N,当N超过图像子块面积的10%时,就认定该图像子块是疑似烟雾图像子块。这里,疑似烟雾图像块的筛选条件比较宽松,目的是尽可能避免遗漏,后续会通过深度网络模型对疑似烟雾图像块进行细分类,滤除此处虚检的图像块。其中,疑似烟雾像素点是依据烟雾的运动和颜色特性来判定的,公式为:
(4)
式中:gk(x,y)=1表示第k帧图像中的像素点(x,y)为疑似烟雾像素点,否则不是。T1和T2为经验阈值,通过观察小样本烟雾像素点在YdUaVa颜色模型上的变化情况主观确定,为宽松起见,取T1=10、T2=40。
3 改进的MobileNetV3网络
为了满足视频烟雾检测对于烟雾检测效率的要求,以及前端嵌入式视频采集处理平台部署的要求,通常需要采用轻量级网络模型实现烟雾图像深度特征的提取及烟雾目标的识别。MobileNetV3网络是谷歌新推出的轻量级网络,其中的MobileNetV3 large版本相对于MobileNetV2而言,在COCO上达到相同精度的前提下,速度可提升25%[10]。这对于视频烟雾检测的效率提升而言很有意义。因此,基于MobileNetV3 large版本设计视频烟雾检测的网络模型。主要从视频烟雾检测的实际出发,对MobileNetV3 large版本进行改进,基本思路是:
第一,为了提取显著性和稳健性更强的烟雾运动和颜色变化特征,对MobileNetV3网络的输入层进行改进,具体是采用YdUaVa颜色模型替代MobileNetV3网络常用的RGB颜色模型。YdUaVa颜色模型如第1节所述。
第二,由第2节所述,深度网络的目标是对疑似烟雾区域的图像进行分类,结合这一需求,对MobileNetV3 large版本的网络结构进行修改,修改后的网络结构如表1所示,具体修改内容包括:
1)在第一层,“Input”的尺寸改为562×3,以适应疑似烟雾区域的尺寸。同时,步长“s”改为1,在这一层卷积运算过程中不降低特征尺度,但扩展了通道数。
2)合并了原始MobileNetV3 large版本网络结构的第二层和第三层,因为结合本文第一层的修改,原始的第二层和第三层存在较大的冗余,在修改后的结构中,第二层网络能够抽取相似的特征,而且由于删除了一层网络,运算效率得以进一步提升,且资源占用也相应减少。
3)在最后一层,根据应用需求,只需要判断疑似烟雾区域是否为真实的烟雾区域,这是个二分类问题,因此将“#output”改为2。
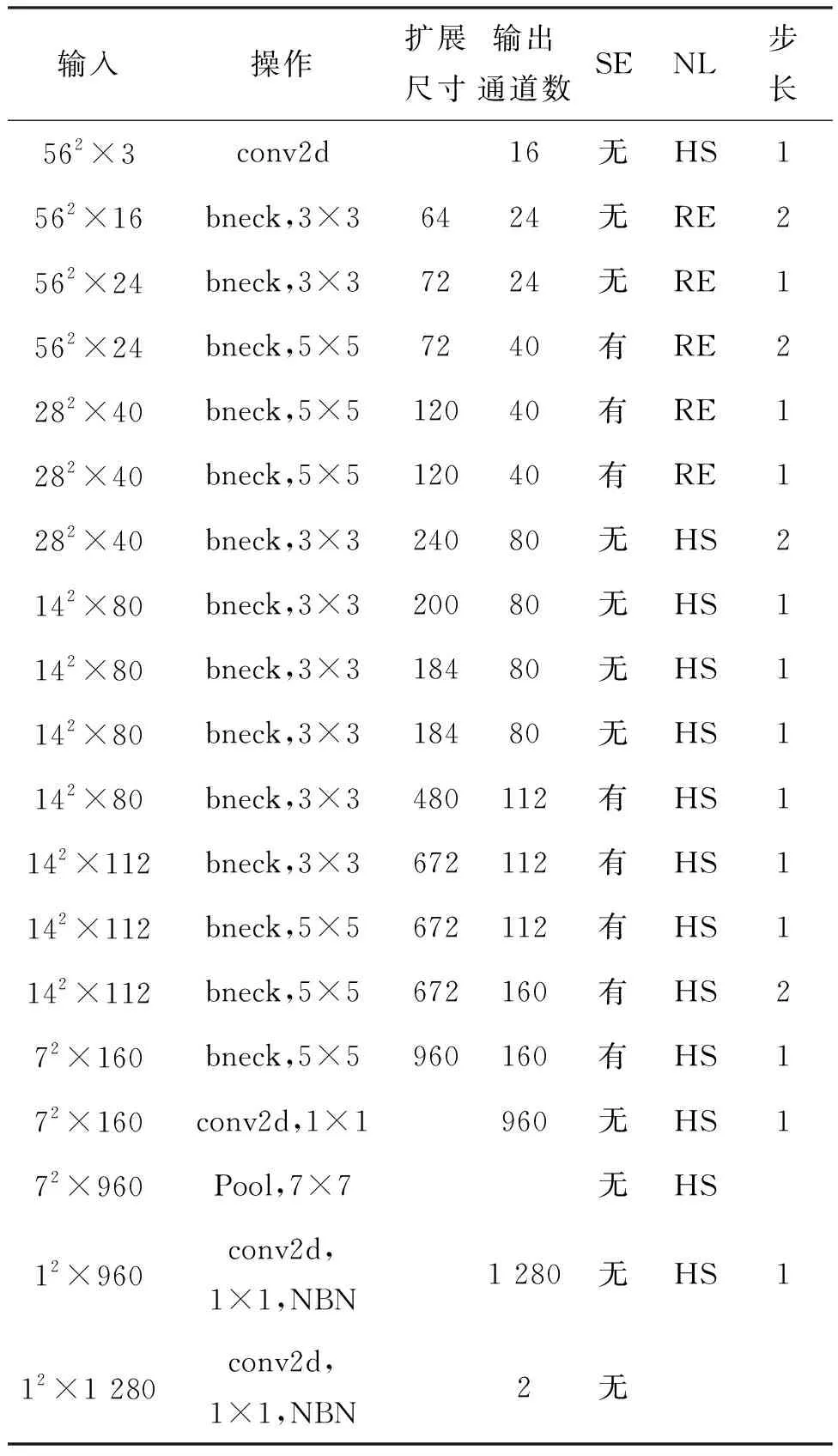
表1 改进的MobileNetV3网络
4 算法实现
综上所述,算法的主要实现步骤如下所示。
Step1:采用双线性插值方法,将视频的第k帧图像尺寸调整为560×448;
Step2:依据式(1)~(3),计算第k帧图像的YdUaVa颜色模型;
Step3:依据式(4),判别疑似烟雾像素点;
Step4:依据第2节所述,统计各个56×56的图像子块的疑似烟雾像素点数量,筛选出疑似烟雾图像块;
Step5:将疑似烟雾图像块送入第3节所述的改进MobileNetV3网络模型,开启多线程并行计算,只要有一个疑似烟雾图像块分类结果为烟雾,则判断第k帧图像为烟雾图像,继续下一帧检测。
5 实验与分析
5.1 实验说明
选择烟雾检测领域公开的视频数据集进行实验仿真,包括Yuan公开的3段烟雾视频和3段非烟雾视频[11],以及CVPR实验室公开的4段烟雾视频和10段非烟雾视频[7]。其中,每段视频的前500帧用作测试。剩余的视频帧都用作训练。
视频烟雾检测的评价指标选用文献[6]所述的准确率(Accuracy Rate,AR)和虚警率(False Alarm Rate,FAR),同时增加检测帧率(detected frames per second,dfps)指标,用于评测算法的运算效率。实验平台环境为: Windows 7系统,python 3.6.2、tensorflow 1.11.0和keras 2.2.4软件平台,NVIDIA GeForce GTX1080Ti显卡和Intel Core i7-8700K CPU。
5.2 网络模型训练
改进的MobileNetV3网络模型的训练方法是:对于训练数据,先按照第4节所述的Step 1至Step 4生成视频中每帧图像(第一帧除外)的各个56×56图像子块的YdUaVa图像,其中疑似烟雾图像块的YdUaVa图像与其他图像块分开存放。然后分别从中人工筛选出烟雾图像块和非烟雾图像块的YdUaVa图像,并为每一个图像块人工设定标签,烟雾图像块标签为1,非烟雾图像块标签为0,构建正负样本集。筛选的正样本集图像数量为12 182,负样本集图像数量为42 860。基于该数据集训练表1所示的改进MobileNetV3网络模型,训练过程的损失曲线和精度曲线如图2所示。同时,存储YdUaVa图像对应的RGB图像,同样人工设定标签,构建正负样本集,作为后续对比实验中所对比方法的训练样本集。
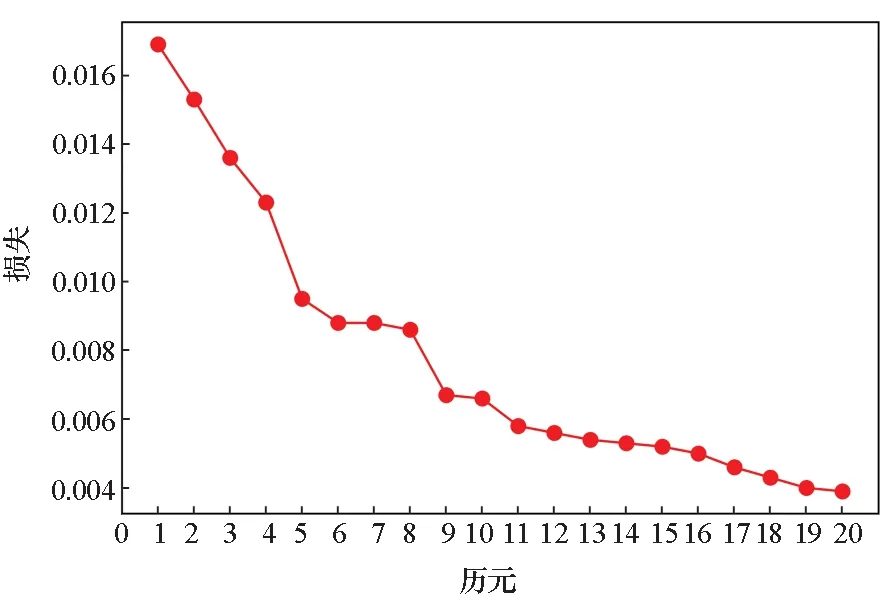
(a) 损失曲线(a) Loss curve
5.3 实验对比分析
5.3.1 不同输入图像和网络的对比测试
主要创新之处包括:1)提出YdUaVa颜色模型,作为深度网络模型的输入;2)采用图像分块和疑似烟雾块筛选,降低虚警率和提高运算效率;3)改进MobileNetV3网络。下面对比这三个阶段所达到的性能指标,如表2所示。其中,实验1直接用原RGB图像作为MobileNetV3 large版本网络的输入(网络模型训练数据集为训练数据中的RGB图像);实验2先对RGB图像进行分块(分块方法与本文所述一致),然后再将图像块采用双线性插值方法归一化到224×224,之后再作为MobileNetV3 large版本网络的输入(网络模型训练数据集为YdUaVa图像对应的RGB图像构建的正负样本集);实验3采用分块后的YdUaVa图像作为改进的MobileNetV3网络的输入;实验4是在实验3的基础上,对输入的YdUaVa图像块进行疑似烟雾块的粗筛选,然后再送入改进的MobileNetV3网络进行细分类,详见第4节的算法实现。由表2可见,采用RGB图像作为输入时,AR偏低且FAR偏高,这主要是因为测试视频中烟雾目标较小,在整幅图像中特征不够显著。实验2对RGB进行分块之后,AR提升较为明显,但因为参与分类的图像块大幅增加,检测帧率明显降低。实验3采用分块后的YdUaVa图像作为改进MobileNetV3网络的输入,因为YdUaVa图像相比RGB图像更能呈现烟雾的显著特征,虚警率有一定下降。同时由于改进MobileNetV3网络层数减少且输入层尺度下降,检测帧率也有一定提升。进一步地,实验4对输入的YdUaVa图像块进行疑似烟雾块的粗筛选,降低了静止目标可能引起的虚警,从而降低了虚警率,而且检测帧率也得以提升。而且,由于式(4)中疑似烟雾像素点判决的参数T1和T2设置宽松,实验中经过疑似烟雾块粗筛选之后尽管存在部分烟雾占比很小的真实烟雾块被误判为非烟雾块,但每一帧烟雾图像中仍能检测出多个疑似烟雾图像块,而每帧图像中最终只要检测出一个真实的烟雾图像块就会将该帧图像标记为烟雾图像,因此粗筛选没有引起漏检,实验4的准确率指标在虚警率下降后得以提升。
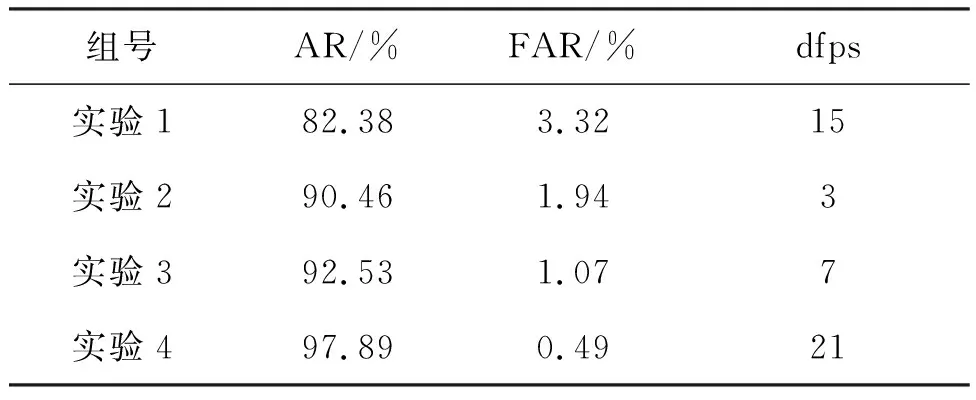
表2 不同输入图像和网络的实验结果
5.3.2 不同方法性能对比
表3给出了本文方法与部分常用的烟雾检测方法的性能对比结果。其中,对比方法中使用的图像训练数据集是5.2节所述的存储YdUaVa图像对应的RGB图像构建的正负样本集。由表3可见,采用深度学习的烟雾检测方法(DNCNN,MobileNetV3+SSD和本文方法)的准确率普遍高于传统方法的特征提取方法(HS′I,LBP+LBPV和optical flow),这主要是因为烟雾的颜色、纹理、运动特征都不是特别显著,人为选择最优的特征比较困难,难以单一鉴别能力强的特征。但是深度学习方法往往复杂度高,检测帧率一般较低,相对而言,使用轻量级网络(MobileNetV3+SSD和本文方法)可以提升运算效率,而本文方法在使用轻量级网络前先采用运动、颜色等快速筛选策略剔除了大量的非烟雾区域图像子块,进一步降低了运算量。使用运动特征的烟雾检测方法(optical flow和本文方法)的虚警率通常较低,这是因为场景中与烟雾颜色、纹理类似的物体比较多,容易引起虚警,而运动可以剔除大量静止物体,从而降低虚警率。综合分析,本文方法使用YdUaVa颜色模型融合烟雾的空间域分布特性和时间域变化特性,快速剔除非烟雾区域图像块,同时改进MobileNetV3轻量级网络来快速提取鉴别能力更强的烟雾特征,视频烟雾检测的准确率最高,虚警率最低,而且检测帧率在深度学习方法中最高,尽管与传统特征提取方法相比检测效率偏低,但基本能满足视频烟雾检测对时效性的要求。
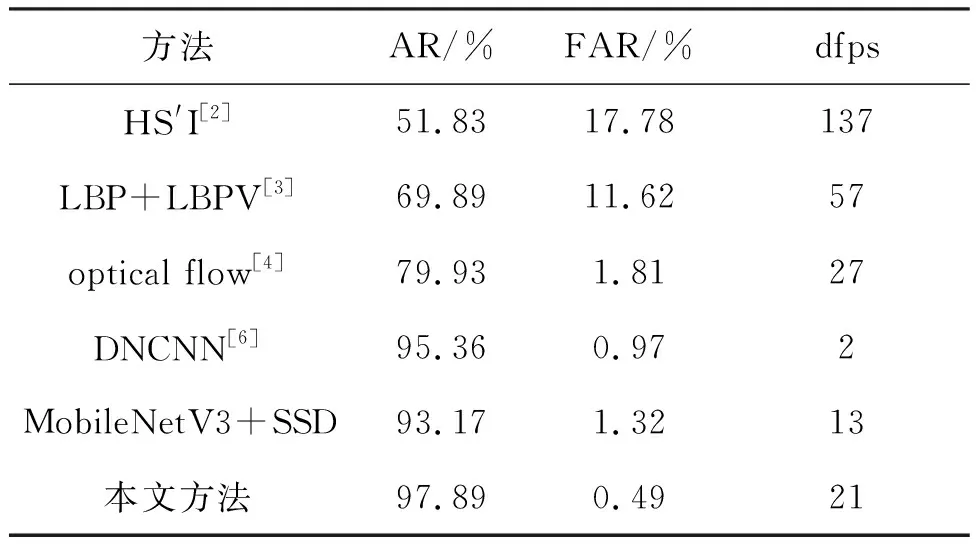
表3 不同方法的实验结果
6 结论
利用计算机视觉技术检测视频中的烟雾是近些年火灾探测领域的热点研究方向。为降低视频烟雾检测中的虚警率和提升检测效率,提出YdUaVa颜色模型,该模型可以表征烟雾的颜色和运动变化特性,有助于快速筛选出疑似烟雾图像块和提取鉴别能力强的特征。在此基础上,改进MobileNetV3网络模型,可以快速准确地对疑似烟雾图像块进行细分类。仿真实验证实本文方法准确率高,虚警率低,且检测帧率高,但检测帧率仍然不能充分地满足实时性的要求,后续还需进一步提升。
猜你喜欢
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
小学阅读指南·低年级版(2021年3期)2021-03-19
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
华人时刊(2019年13期)2019-11-26
当代陕西(2017年12期)2018-01-19
少儿科学周刊·儿童版(2015年11期)2015-12-17
科学启蒙(2014年12期)2014-12-09
意林(2011年10期)2011-05-14
