
基于上下文感知空间坐标嵌入的时空图卷积网络
2023-04-08 16:15杨超丁文文邓淦森
青岛大学学报(自然科学版) 2023年4期
杨超 丁文文 邓淦森


摘要:
针对空间复杂的非欧几里得结构,图卷积网络不易通过欧氏距离构造输入图的问题,提出了上下文感知空间坐标嵌入的时空图卷积网络(STE-STA)模型,将空间背景和相关性明确地结合到模型中,并基于地理空间辅助任务学习、语义空间嵌入和动态图的时空注意力识别手势。首先从手骨架构造一个完全连接图,通过学习地理坐标的上下文感知向量编码,以及自我注意机制对节点特征和边缘进行自动学习;然后,与主任务并行预测数据中的空间自相关。实验结果表明,在DHG-14/28数据集上,STE-STA模型识别率分别达到92.40%与87.85%,均高于目前最优模型;在SHREC′17数据集上,比时空图卷积网络(ST-GCN)分别高0.60%和0.10%。
关键词:
语义空间嵌入;时空注意力;时空掩码
中图分类号:TP391.4 文献标志码:A
手势识别广泛应用在人机交互、游戏和手语识别等非语言交流分析领域 [1-3],按输入方式分为基于图像和基于骨架的方法。基于图像的方法使用RGB或RGB-D图像作为输入,通过提取图像特征识别手势[4];基于骨架的方法是通过一系列具有二维或三维坐标的手关节进行预测[5],在精确的关节坐标下,手势识别更准确。由于深度相机的成本较低(如微软Kinect或英特尔RealSense)和手部姿态估计上取得巨大进展,很容易获得手部关节的精确坐标[6]。传统基于骨骼的手势识别方法的目的是设计功能强大的特征描述符来模拟手的动作,如利用连接关节的形状描述符表示手骨骼的形状[7]。在此基础上,结合自边缘、光流和阴影信息的多种信息源以整合多线索以跟踪高自由度关节运动和模型细化[8],或在每一帧上通过一个改进的定向梯度直方图(HOG)算法生成一个特征集,然后使用线性SVM识别手势[9]。然而,这些手工制作特性的泛化能力有限。在最近的研究中,骨架图和动力学的结合在人体行为识别上取得了突破。即给定一系列骨骼,以此定义一个时空图,其中嵌入骨骼的结构和动力学,然后提取图的特征表示来识别动作。如利用空间推理和时间栈学习(SR-TSL)的基于骨架的动作识别模型[10],亦可将图神经网络扩展到时空图卷积网络(ST-GCN)[11]。在此基础上,提出一种新的联合手势识别和三维手姿态估计的协同学习网络,该网络利用联合感知特征,增强相互学习,可以利用更有区别和代表性的关节运动信息,学习姿态和多阶运动信息[12]。双流模型是从每帧中利用多尺度特征学习每个流中所需的特性,捕获原始点云中的几何结构,获得整个作用领域的活动图以提升识别效果[13]。图卷积网络通过自适应学习人类动作动力学的空间特征,在骨架动作识别上取得了显著的成绩,然而该方法在人类行为的时间序列建模方面受到限制。为了在动作建模中充分考虑时间因素,确保信息完整,引入卷积层,利用跨时空图卷积层,确保跨时空依赖关系[14]。由于堆叠图卷积对关键动作的长期依赖性效果较差,故引入基于骨架网络的大核注意力算子(SLKA),可扩大感受野,提高信道适应性,并学习远距离时间相关性[15]。上述研究具有固定结构的预定义图来捕捉不同动作之间的动态方差,在实践中产生了次优的性能。为提高模型识别率,本文提出上下文感知空间坐标嵌入的时空图卷积网络(STE-STA)模型,包含一个地理空间位置编码器SE,在整个训练过程中学习点坐标的上下文嵌入;利用时空位置嵌入,改进时间位置嵌入;引入一种新的时空掩模操作,直接应用于所有节点之间的比例点积矩阵。
3 结果与分析
为了证明模型的有效性,实验在DHG-14/28数据集和SHREC′17数据集上开展,所用电脑为联想拯救者R9000K,处理器为八核AMD Ryzen 9 5900HX,显卡为NVIDIA GeForce RTX 3080。
3.1 DHG-14/28数据集和SHREC′17数据集
DHG-14/28数据集包含14个手势序列,有两种方式:使用1根手指和整只手。每个手势由28个参与者以两种方式执行1到10次,得到2 800个序列,根据手势、使用的手指数量、表演者和试验标记区分。序列的每帧包含1个深度图像,在二维深度图像空间和三维世界空间中22个关节的坐标形成1个完整的手骨架。使用英特尔RealSense短程深度相机收集数据集,以每秒30帧的速度拍摄深度图像和手骨骼,样本手势的长度从20帧到50帧不等。
3.1.1 网络训练 STE-STA网络是基于Pytorch平台实现的,采用学习速率为0.001的Adam优化器训练模型,批量大小为32,学习率为0.2,从每个视频中均匀地采样8帧作为输入。为了公平比较,对数据扩展,包括缩放、位移、时间插值和添加噪声,并且用第1帧的手掌位置减去每个骨架序列进行对齐。
3.1.2 模型评估 在DHG-14/28数据集上,通过留1个被试者交叉验证策略评估模型,即对数据集中的每个受试者执行1次实验。在每次实验中,选择1名受试者进行测试,其余19名受试者进行训练。验证在20个交叉验证折叠中,14个手势(没有单指配置)或28个手势(有单指配置)的平均精度。对于SHREC′17跟踪数据集,使用了数据分割,并测试了14个和28个手势的准确性。
將STE-STA模型分别与DHG-14/28数据集中较为先进模型进行比较,包括传统的手工特征方法,基于深度学习的方法和基于图的方法,结果见表1。可以看出,STE-STA模型在14手势和28手势设置下都达到了最先进的性能,和ST-GCN 都优于其他没有明确利用手的结构和动态的方法。
不同于DHG-14/28数据集,SHREC′17跟踪数据集提供了带有噪声帧的原始捕获的视频序列,视频由人类标记的开始和结束的手势裁剪,更具挑战性。表2可以看到,STE-STA模型在14个手势设置下达到了较为先进的性能,并在28个手势设置下获得了与STA-Res-TCN 相当的性能,和ST-GCN 优于所有其他没有明确利用手的结构和动力学的方法。
3.2 消融实验
STE-STA模型由3个主要组成部分组成,包括全连接骨架图结构(FSG)、时空注意模型(STA)和地理时空位置嵌入(STE),验证这些组件有效性的实验结果见表3。
(1)全连接图结构的评价:FSG与稀疏骨架图结构(SSG)进行了比较,空间边是基于手关节的自然连接来定义的,而时间边在连续帧之间连接相同的关节,模型明显优于在SSG上训练的模型。SSG对于某些手势可能是次优的,而FSG对模型几乎没有什么约束,因此能够学习特定于动作的图结构。
(2)时空注意的评价:如果只应用一个对整个图的注意模型,而不区分空间和时间域,则STA降级到GAT。通过将一个注意模型替换本文网络中的空间和时间注意模型来实现GAT,并在模型的相同设置下对其训练。可以观察到,基于STA的模型比基于GAT的模型具有更好的性能,这证明了STA的有效性。
(3)地理时空位置嵌入式结构的评价:通过训练来验证所提出STE-STA的有效性。上下文感知空间坐标嵌入的时空图卷积网络优于没有STE的模型,这说明了由STE-STA编码的身份和时间顺序信息的重要性。
图7显示了STE-STA在DHG-14/28数据集上测试的混淆矩阵,能够准确识别出手势运动的14个行为类别中的大多数动作种类。图8显示了STE-STA在SHREC′17数据集上测试的混淆矩陣,能够较为准确识别出手势运动的14个行为类别中的大多数动作种类。
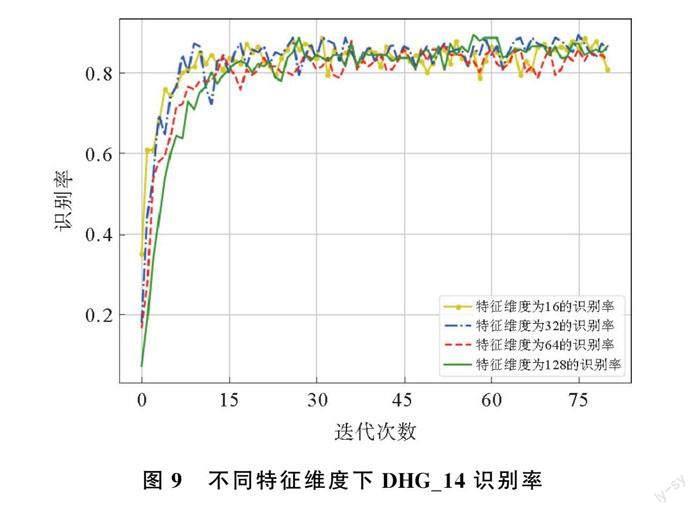
为验证STE-STA模型对于输入数据特征维数的相关性,将关节点特征经过GCN从3维提升到16维,32维,64维以及128维,表4结果显示模型仍然具有比较出色的识别效果。STE-STA模型从根本上克服了网络在空间和时间上对原始数据信息提取不充分,对模型识别率有一定的提升。
两个数据集在不同特征维度下进行80次迭代,对比识别率随着迭代次数的增加而变化情况,并利用Python对得到的相关数据进行绘制,结果如图9、图10所示。可以看出,随着迭代次数增加,识别率先增大后趋于平稳。DHG_14数据集在特征维度64维,识别率在第15次迭代以后趋于平稳,而特征维度过大或过小表现效果不佳,可能是提取信息量的不足或过饱和造成的。SHREC_14数据集不同的特征维度对识别率达到平稳的迭代次数有一定影响,并且在一定迭代次数之后,各个特征维度下的识别率差距不明显,可能的原因是经过预处理的手势,再次经过模型的提取信息量已经达到饱和。
对DHG-14/28数据集的手势动作按照大拇指,二拇指,三拇指,四拇指,小拇指以及手掌心分块,然后再对分块关节信息聚合处理,并与STE-STA网络做出对比(表5)。可以看出,分块在一定程度上不仅考虑关节点的信息,而且还考虑了每个手指与掌心的之间的相关性,补充了手骨架信息的缺失,进而提高手势运动的识别率。
4 结论
STE-STA模型在DHG-14/28数据集和SHREC′17跟踪数据集有不错的识别效果,说明STE-STA对手势动作识别的有效性。STE-STA在DHG-14/28数据集上识别率较高,而在SHREC′17跟踪数据集表现得并不突出,可能是该数据集是由SHREC′17跟踪数据集经过手势分离预处理,得到的数据经过该模型,再次进行时空信息提取,存在冗余,使得模型对该数据集识别率不高。这也是模型的不足之处,未来期望该模型在数据处理过程中能够对收集到的信息进行一定概率丢弃,避免出现信息杂糅或冗余现象。
参考文献
[1]桑康西,祝凯,刘振宇,等.基于视频的人体状态快速识别方法研究[J].青岛大学学报(自然科学版), 2021,34(1):40-45.
[2]许帅,姜俊厚,高伟,等.适用于移动设备的轻量化手势识别算法[J].青岛大学学报(自然科学版), 2022,35(2):51-56.
[3]张念凯,乔学军,热孜万古丽·夏米西丁,等.基于全卷积自加权分类器的三维颅骨性别鉴定[J].青岛大学学报(自然科学版),2022,35(3):9-15.
[4]LIU M M, ZHANG J. Gesture estimation for 3D martial arts based on neural network[J]. Displays, 2022, 72: 102138.
[5]CHEN H H, LI Y N, FANG H J, et al. Multi-scale attention 3D convolutional network for multimodal gesture recognition[J]. Sensors, 2022, 22(6): 2405.
[6]GAO Q, CHEN Y Q, JU Z J, et al. Dynamic hand gesture recognition based on 3D hand pose estimation for human-robot interaction[J]. IEEE Sensors Journal, 2021, 22(18): 17421-17430.
[7]De SMEDT Q, WANNOUS H, VANDEBORRE J P. Skeleton-based dynamic hand gesture recognition[C]// 29th IEEE Conference on Computer Vision and Pattern Recognition Workshops. Las Vegas, 2016: 1-9.
[8]LU S, METAXAS D, SAMARAS D, et al. Using multiple cues for hand tracking and model refinement[C]// Conference on Computer Vision and Pattern Recognition. Madison, 2003: 443-450.
[9]OHN-BAR E, TRIVEDI M. Joint angles similarities and HOG2 for action recognition[C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops. Portland, 2013: 465-470.
[10] SI C Y, JING Y, WANG W, et al. Skeleton-based action recognition with spatial reasoning and temporal stack learning[C]// 15th European Conference on Computer Vision(ECCV). Munich, 2018: 103-118.
[11] YAN S J, XIONG Y J, LIN D H. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]// AAAI Conference on Artificial Intelligence. New Orleans 2018: 7444-7452.
[12] YANG S Y, LIU J, LU S J, et al. Collaborative learning of gesture recognition and 3D hand pose estimation with multi-order feature analysis[C]// European Conference on Computer Vision. Glasgow, 2020: 769-786.
[13] BIGALKE A, HEINRICH M P. Fusingposture and position representations for point cloud-based hand gesture recognition[C]// 2021 International Conference on 3D Vision (3DV). London, 2021: 617-626.
[14] XIE Y L, ZHANG Y, REN F. Temporal-enhanced grap convolution network for skeleton-based action recognition[J]. IET Computer Vision, 2022, 16(3): 266-279.
[15] LIU Y A, ZHANG H, LI Y Q, et al. Skeleton-based human action recognition via large-kernel attention graph convolutional network[J]. IEEE Transactions on Visualization and Computer Graphics, 2023, 29(5): 2575-2585.
[16] CHEN X H, GUO H K, WANG G J, et al. Motion feature augmented recurrent neural network for skeleton-based dynamic hand gesture recognition[C]// 24th IEEE International Conference on Image Processing(ICIP). Beijing, 2017: 2881-2885.
[17] OREIFEJ O, LIU Z C. HON4D: Histogram of oriented 4d normal for activity recognition from depth sequences[C]// IEEE Conference on Computer Vision and Pattern Recognition. Portland, 2013: 716-723.
[18] DEVANNE M, WANNOUS H, BERRRTTI S, et al. 3-D human action recognition by shape analysis of motion trajectories on Riemannian manifold[J]. IEEE Transactions on Cybernetics,2014, 45(7): 1340-1352.
[19] BOULAHIS S Y, ANQUETIL E, MULTON F, et al. Dynamic hand gesture recognition based on 3D pattern assembled trajectories[C]// 7th International Conference on Image Processing Theory, Tools and Applications(IPTA). Hong Kong, 2017: 1-6.
Spatio-temporal Graph Convolutional Networks with
Context-aware Spatial Coordinate Embedding
YANG Chao, DINGWen-wen, DENG Gan-sen
(School of Mathematical Sciences,Huaibei Normal University,Huaibei 235000,China)
Abstract:
For the complex non-Euclidean structure of space, graph convolutional network is not easy to construct the input graph through Euclidean distance, a context-aware spatial coordinate embeddingSpatio-Temporal Graph Convolutional Network (STE-STA) model was proposed, which explicitly combines spatial context and correlation into the model, and based on geospatial auxiliary task learning, semantic spatial embedding and dynamic graph spatio-temporal attention gesture recognition. Firstly, a fully connected graph was constructed from the hand skeleton, and the node features and edges were automatically learned by learning the context-aware vector encoding of geographic coordinates and the self-attention mechanism. Then, the spatial autocorrelation in the data was predicted in parallel with the main task. The experimental results show that on the DHG-14/28 dataset, the recognition rate of the proposed algorithm reaches 92.40% and 87.85%, which are higher than the current optimal model. On the SHREC'17 dataset, it is 0.60% and 0.10% higher than Spatio-Temporal Graph Convolutional Network (ST-GCN).
Keywords:
semantic spatial embedding; temporal and spatial attention; space-time mask
收稿日期:2023-05-21
基金項目:
国家自然科学基金(批准号:62171342)资助;安徽省自然科学基金(批准号:1908085MF186)资助。
通信作者:
丁文文,女,博士,副教授,主要研究方向为人工智能,计算机视觉,图像处理与模式识别。E-mail:dww2048@163.com
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
中国新技术新产品(2020年5期)2020-05-06
计算机工程(2020年3期)2020-03-19
红领巾·萌芽(2019年9期)2019-10-09
中国听力语言康复科学杂志(2019年3期)2019-06-24
小学科学(学生版)(2018年12期)2018-12-19
中国交通信息化(2018年3期)2018-06-13
小学阅读指南·低年级版(2017年6期)2017-06-12
中国交通信息化(2016年2期)2016-06-06
中国煤层气(2014年3期)2014-08-07
