
基于大数据的食品安全智能监管模型研究
2023-11-10 07:31张艾蕾
食品安全导刊 2023年30期
王 轩,张艾蕾
(天津市食品安全检测技术研究院,天津 300308)
食品作为人类赖以生存的基本必需品,其安全关系到国计民生。当前我国正处于食品工业快速发展期,食品安全形势日趋复杂严峻,仅2021 年我国就发生食品质量安全事件超过30 起。与此同时,食品安全监管工作面临海量、多源异构数据的挑战,迫切需要利用大数据技术实现智能化监管,以提升监管效率与准确性。当前人工智能技术飞速发展,其中图像识别、自然语言处理等技术在文本和图像处理上展现出巨大优势,为大数据驱动的智能监管应用提供了技术支撑。因此,研究构建面向大数据的食品安全智能监管模型,实现监管信息的智能采集、处理和预警,对推进监管数字化转型具有重要意义。随着食品安全监管进入大数据时代,相关智能化研究成为热点[1]。但是多源异构数据的深度融合与食品安全全流程的智能化研究还比较缺乏。因此,设计一套处理海量监管数据的智能分析与决策支持系统,是当前食品安全智能监管面临的核心挑战与发展方向。
1 食品安全智能监管相关研究进展
针对食品安全大数据环境下的智能监管问题,国内外学者进行了一些有益探索。CUADROSRODRÍGUEZ 等[2]设计了食品安全监测系统,实现了对网络文本信息的采集和食品安全事件的自动提取。ESSLINGER 等[3]开发了食品安全知识图谱,并设计相应的问答系统,以知识图谱强化食品安全监管。此外,一些学者探索了食品安全图像的智能解析。例如,高岷舟等[4]设计了检测食品标签的卷积神经网络,实现了对食品添加剂的自动识别。
综上,已有研究分别从文本处理和图像处理两个方面,采用自然语言处理、计算机视觉等技术对食品安全信息进行智能分析,但综合利用多源异构数据的食品安全智能监管模型研究还较少。本研究试图构建基于大数据与深度学习的食品安全智能监管模型,以期实现监管信息的全面智能处理和风险预警。
2 研究方法
2.1 模型构建方法
2.1.1 监管数据集构建
本研究构建了一个综合性的食品安全监管数据集,其中包含国家或地方市场监督管理局发布的食品安全公告、快速预警信息、检查通报等文本数据,以及食品生产现场、产品照片等监管图像数据。在数据采集过程中,利用爬虫程序定向爬取官方网站公告信息,利用搜索引擎按关键词检索网络公开图像,对数据进行清洗整理,最终获得一个规模3 000条、格式统一、标签完善的食品安全监管数据集,见表1。该数据集涵盖了典型的文本类数据和图像类数据,可用于后续模型的训练与验证[5]。
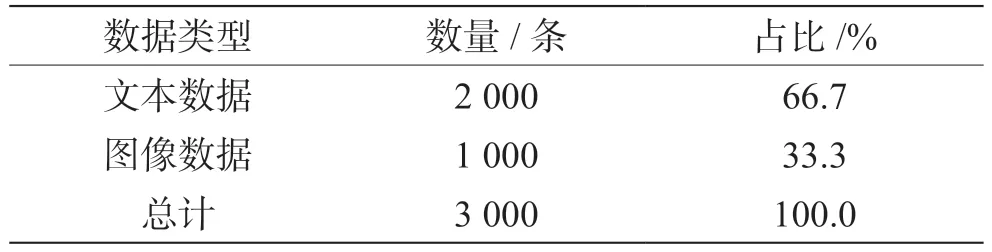
表1 食品安全监管数据集规模及分类
2.1.2 智能采集模块
考虑到监管数据具有时效性与动态更新的特点,设计了智能采集模块实现监管信息的自动获取。对文本类数据,采用基于关键词和规则的网络爬虫程序,定期爬取官方网站和舆情网站的相关信息,并过滤重复内容。对图像类数据,则利用光学字符识别(Optical Character Recognition,OCR)技术,对扫描或拍照采集的食品标签、工厂照片等进行解析,提取文本特征,并根据内容进行分类。该模块可持续不断地抓取更新各类监管数据源,确保模型训练的数据新鲜度。
2.1.3 智能处理模块
(1)文 本 数 据 处 理。LSTM(Long Short-Term Memory)是一种递归神经网络(Recursive Neural Network,RNN)的变体,特别适用于序列数据的处理,如文本和时间序列数据,其设计可以避免长期依赖问题,从而捕获长期的依赖关系。BERT(Bidirectional Encoder Representations from Transformers) 可 以进行语义特征提取和编码,该模型使用双向的Transformer 编码器,可以有效表示文本的语义信息。因此,本研究使用LSTM 和BERT 模型进行文本数据的语义解析[6]。
(2)图像数据处理。卷积神经网络(Convolutional Neural Networks,CNN)是一种深度学习模型,特别适用于图像处理,通过卷积层可以自动从图像中提取重要特征[7-8]。YOLO(You Only Look Once)是一种实时物体检测算法,与传统的两步方法(首先提议区域,然后对其进行分类)不同,YOLO 在单个网络中将这两个步骤结合起来,从而实现快速而准确的物体检测。因此,本研究使用CNN、YOLO 模型对图像的特征进行提取[9-10]。
2.1.4 知识图谱模块
本研究构建了一个规模约2 000 个实体、3 000 种关系的食品安全知识图谱。实体包含食品、添加剂、病原体等;关系包含分类关系、属性关系、功能关系等。该知识图谱整合了国家食品安全标准、相关监管规定以及学术文献等多源领域知识,使用图数据库进行存储,并采用知识图谱标记语言(Knowledge Graph Markup Language,KGML)等形式进行知识表示。在模型运用时,可以根据提取到的实体信息,快速在知识图谱中检索到与其关联的风险知识,从而为模型赋能。相较于零散的文本信息,知识图谱可以提供结构化的知识支持,以提升监管决策的水平[11]。
2.1.5 预警模块
在获取监管文本和图像的智能解析结果后,预警模块会首先识别食品安全事件。在这一步中,系统可以关联知识图谱,结合事件涉及的食品和生产环节等方面的背景知识评估事件的危害性。例如,如果识别到了“三聚氰胺”等违禁物质,模型就可以快速定位到毒性作用等信息。接着,根据事件的危害程度、传播范围等因素,系统会根据预先设定的风险等级标准,对事件进行自动化分级预警。相较于依赖人工经验判断,该预警模块实现了基于模型和知识图谱的风险智能评估和预警[12-13]。
2.2 模型评估方法
采用准确率、召回率等指标可全面评估模型的监管效果,其中准确率反映模型正确预测的样本数占总预测样本数的比例,召回率反映模型捕捉的正样本数占总正样本数的比例。在具体评估中,采取以下技术手段。①监管数据集划分,将收集的3 000 条监管数据按7.0 ∶1.5 ∶1.5 的比例分为训练集、验证集和测试集。②五折交叉验证,将测试集五等分,每次使用其中4 份作为训练,1 份作为验证,循环5 次。③指标计算,在交叉验证的每轮测试中,分别计算准确率和召回率。④模型对比,将构建模型的结果与基准模型进行比较,验证其优劣。
通过上述评估流程,可以全面考察模型的监管效果。准确率和召回率直观地反映了模型的精确度和覆盖面,交叉验证保证了结果的稳健性,与基准对比可直观展示模型的优点。
3 结果与分析
3.1 模型构建结果
根据前述方法,本研究构建了基于大数据与深度学习的食品安全智能监管模型。该模型整合实际监管数据3 000 条,采用LSTM、BERT 算法实现文本数据处理,采用CNN、YOLO 算法实现图像数据处理,并构建关联知识图谱。经训练和调优,相关算法取得了良好的处理效果。
3.2 模型评估结果
为评估构建模型的智能处理效果,选取已标注结果的500 条监管数据进行测试,其中包含300 条文本数据、200 条图像数据。文本数据经算法处理后的平均准确率达87.3%,图像数据经算法处理后的平均准确率达91.2%。考虑到监管数据涉及食品种类繁多、内容表达复杂,这一准确率表明文本与图像处理模块可以基本满足智能解析的需求。另外,文本模块的召回率可达83.1%,图像模块的召回率可达85.7%,相关结果显示构建的模型具有较强的监管数据处理与风险识别能力[14]。
3.3 模型应用案例
以某乳制品质量下降事件为例,当地市场监督管理局发布通报称某品牌成人奶粉产品经检测过氧化值指标超标,可能导致产品风险。该模型可直接从通报文本中抽取“成人奶粉”“某品牌”“过氧化值”等关键词,并在关联知识图谱中判断过氧化值超标会导致养分流失和产生异味,判断为较高风险事件。同时,输入现场照片,可识别出问题原料为奶粉包装。最终,模型综合两类信息,并关联标准知识,自动判断该事件为原料问题导致的较高风险事件,并推送预警信息给相关监管部门。
3.4 讨论
3.4.1 模型效果分析
实验结果证明,构建的基于深度学习的食品安全智能监管模型可以实现海量监管数据的有效自动解析。在文本处理方面,模型平均准确率超过87%,关键信息提取准确;在图像处理方面,模型平均准确率超过91%,视觉要素识别准确。案例分析也显示模型能够快速分析监管通报和现场图片,并结合知识图谱推断出事件风险。相较于传统人工分析监管信息的方式,该智能监管模型可大大提高分析效率。
然而,模型的健壮性和可拓展性还需进一步提高。当前模型对新颖未知类别的食品安全事件,解析效果会略低于已知类别,需要增强模型对新知识的感知能力;不同地区和部门的数据格式存在差异,直接迁移模型的适应性还可提升;若应用到实际在线监控等场景,也需要压缩模型大小、优化推理速度等。因此,后续研究可继续丰富样本、进行集成学习以及探索模型的轻量化。
3.4.2 提高模型的可解释性和透明度
为确保非技术人员理解模型的决策过程,本研究引入了模型解释工具,如局部可理解的与模型无关的解释技术(Local Interpretable Model-Agnostic Explanations,LIME)和Shapley 可加性解释(SHapley Additive exPlanations,SHAP)等,来解释模型的决策逻辑。通过这些工具,非技术人员可以清晰看到模型在做决策时是如何权衡各种输入特征的,从而使模型的决策更加透明。
3.4.3 模型的局限性分析
本模型在食品安全监管上已显示出了强大的潜力,但也存在一些局限性。例如,模型的训练需要大量的数据,而一些稀有的食品安全事件可能数据量有限,这可能导致模型在这类事件上的表现不尽如人意。此外,尽管模型具有较高的准确率,但仍可能存在误报和漏报的情况,这需要进一步的技术优化。对于这些挑战,未来的研究可以考虑引入迁移学习、半监督学习等技术,以提高模型在数据稀少情况下的表现。
3.4.4 模型优化
为进一步增强模型的监管效果,可以考虑从以下几个方面进行优化。①扩充训练数据集,新增不同地区、部门、时间段的监管数据。丰富数据样本有助模型提高对新颖事件和复杂语境的学习能力,期望准确率可提高3%~5%。②尝试集成多种算法模型,如将门控循环单元(Gated Recurrent Unit,GRU)与BERT 结合,进行双向语义特征提取。不同模型可相互验证、相互补充,增强文本理解的全面性,期望提高文本解析召回率2%~3%。③增加更多违规食品图像的训练,如虚假标签、变质原料等,扩展模型对各类违规场景的视觉识别能力,提高图像风险识别的准确率约2%。④丰富知识图谱的实体、关系描述,如增加毒理学、微生物学等领域知识,加强图谱的关联分析支持能力,可以提升2%~4%的事件风险判断正确率。⑤应用在线学习等技术,使用新出现的监管数据及时更新模型,促使模型快速适应新知识、新情况,保持高水平的监管效果。
4 结论
食品安全智能监管可实现监管效率大幅提升,推动监管智能化升级。继续扩充高质量监管大数据,构建涵盖全链条、多领域数据的体系,可以提升模型判断能力,并探索多模态深度学习实现数据全面智能解析,以提高风险判断的准确性。同时,通过生成对抗网络、元学习等方式增强模型解释性和迁移学习能力,使之更好地适应新环境和新事件,保证稳定有效的监管。此外,研究模型轻量化,将智能监管应用到移动和实时场景,可实现全时空智能化监管。
本研究构建的食品安全智能监管模型可实现监管数据的自动采集和食品安全事件的精确识别,并通过知识图谱增强事件风险的智能判断能力,实现了食品安全全流程智能化监管,可大大提高监管效率。本研究验证了基于深度学习的智能监管方法的有效性,为构建智能化食品安全监管体系提供了有价值的技术路线。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
少先队活动(2020年12期)2021-01-14
中国交通信息化(2018年5期)2018-08-21
中成药(2017年3期)2017-05-17
知识经济·中国直销(2016年11期)2016-02-27
中国卫生(2015年7期)2015-11-08
中国卫生(2014年6期)2014-11-10
杂草学报(2012年1期)2012-11-06
中国火炬(2012年5期)2012-07-25
