
基于通道注意力机制的视频超分辨率方法
2024-01-01 10:46陈雅玲朱永贵
中国传媒大学学报(自然科学版) 2023年5期
陈雅玲,朱永贵
(中国传媒大学数据科学与智能媒体学院,北京 100024)
1 引言
随着高清专业影视摄像机、高清显示设备、高清视频监控等高清视频系统在生活中的逐步普及,人们对高分辨率视频的需求也随之增加,但高清、超高清视频资源相对较为稀缺,这就需要使用视频超分辨率技术重建出更多高质量的视频资源。视频超分辨率技术不仅可以提高视频的分辨率,恢复视频丰富的细节信息,还有助于降低高清或超高清视频的传播成本,被广泛应用在视频监控、视频成像、多媒体和医学等领域中。
相比传统的超分辨率插值技术,基于深度学习的超分辨率技术能更好地恢复图片的纹理细节及视觉效果。2014年,Dong等[1]首次提出超分辨率卷积神经网络(Super‑Resolution Convolutional Neural Network,SRCNN),证明使用卷积神经网络可以学习低分辨率图像到高分辨率图像的非线性映射。随着卷积神经网络在超分辨率技术发展中表现出显著的优势,基于深度学习的超分辨率技术不断涌现,并成为主流的研究方法之一。在此基础上,视频超分辨率技术更注重视频帧间信息的利用,可以看成是图像超分辨率技术的延伸,现阶段基于深度学习的视频超分辨率技术根据网络框架主要可以分为两大类:一是迭代网络,二是循环网络。
现有的基于迭代网络结构的算法以滑动窗口的方式,取连续的低分辨率视频帧作为网络的输入,通过不断迭代重建高分辨率的视频序列。然而这类网络结构对长距离依赖关系的捕获受限于窗口的大小,其性能难以达到实际应用的需求。相比之下,循环网络按时间顺序处理视频帧的方式可以弥补滑动窗口的缺陷,从而更有效地利用视频帧间信息。本文以循环网络为基础,在隐藏态中引入残差连接以保留纹理细节,避免梯度消失的问题,同时使用注意力机制增强通道间的有用特征信息,提出了一种基于通道注意力的循环残差注意力网络视频超分辨率方法。
2 相关工作
2.1 基于深度学习的视频超分辨率方法
在基于迭代网络框架的视频超分辨率方法中,对帧间信息的利用通常采用运动估计和运动补偿方法。然而,此类方法不仅计算量较大,并且依赖于精确的运动估计。Tian 等[2]提出了时域可变形对齐网络(Temporally‑Deformable Alignment Network, TDAN),可以在不计算光流的情况下自适应地对齐相邻帧和目标帧,提升网络的空间变换能力,进而有效地提升模型性能。Ying 等[3]使用可变形三维卷积网络(De‐formable 3D Convolution Network, D3D),灵活提取时空信息同时进行帧间运动补偿,生成的高分辨率视频具有较好的流畅度。Jo 等[4]使用动态上采样滤波器(Dynamic Upsampling Filters, DUF)提取时空特征,避免了运动估计和运动补偿带来的潜在误差。渐进融合网络[5]引入非局部残差块捕获长距离时空相关性,以隐式运动补偿的方法利用时空信息。基于迭代网络的方法虽然在多个基准上表现卓越,但该网络结构往往只考虑窗口内有限的视频帧,从而限制了此类算法在实际中的应用。
循环神经网络具有记忆特性,网络会将序列中先前时刻的信息应用到当前的计算中,适用于处理自然语言、视频、音频等序列数据。因此,基于循环网络的视频超分辨率算法可以利用历史信息和当前信息增强低分辨率帧的纹理细节。Frame‑Recurrent Video Super‑Resolution(FRVSR)[6]首次将循环网络结构引入到视频超分辨率领域,提出了一个端到端训练的帧循环网络框架,在相邻帧间采用显式运动估计和扭曲操作,既能有效利用帧间信息,又能保证时间上的连续性。Fouli 等[7]采用与FRVSR 相似的策略,提出Re‐current Latent Space Propagation(RLSP),但二者对时间信息的利用方式并不相同,RLSP 通过隐藏态传递时间信息,将三个连续帧输入隐藏态,避免了显式运动估计存在对齐误差且计算量大的问题。Residual Invertible Spatio‑Temporal Network(RISTN)[8]中采用残差可逆模块和残差密集卷积模块提取时空信息,在模块中引入残差连接以降低信息丢失的可能性。Ha‐ris 等[9]提出循环反向投影网络(Recurrent Back‑Projection Network, RBPN),根据相邻帧和相邻帧间的光流学习残差,使用反向投影迭代提取目标帧丢失的细节,弥补了循环神经网络的不足。
以上这些视频超分辨率方法的隐藏态中包含多个卷积层,传播过程中卷积层会对输入信息进行不可避免地衰减,从而导致纹理细节丢失,有些方法的输入帧较多,当遇到大运动场景时,输入帧越多,信息传播的准确性越差。本文以连续的两个视频帧作为输入,并在隐藏态中引入残差连接,增加网络的稳定性,保留更多的纹理细节。
2.2 注意力机制
注意力机制与人类的视觉注意力机制相似,将关注点聚焦于重要的信息上,降低对次要信息地关注,高效地从大量信息中筛选出有价值的信息。在超分辨率任务中,引入注意力机制可以使网络关注到更为重要的特征信息,提高模型的表现力。Hu等[10]提出了挤压与激励网络(Squeeze‑and‑Excitation Network, SENet),研究特征图通道间的依赖关系。Wang等[11]提出高效通道注意力机制,在SENet的基础上改进了注意力模块,避免了维度缩减带来的副作用,提高捕获通道间依存关系的能力,同时使模型更加轻量化。Residual Channel At‐tention Network(RCAN)[12]在残差块中加入通道注意力机制,自适应地调整各通道权重,增强有用特征。本文在残差块中引入通道注意力机制,在深层残差网络中充分挖掘和利用通道间的特征信息。
3 循环残差注意力网络框架
本文提出了一种基于通道注意力的循环残差注意力网络,在循环神经网络中加入残差结构,以便于更好地保留图片纹理细节,通过引入通道注意力机制,增强网络提取特征的能力。该网络模型由浅层特征提取模块、残差注意力模块和像素重组模块三部分组成,模型结构如图1所示,网络以连续两个低分辨率帧和先前输出的高分辨率帧以及隐藏态特征作为输入,先通过浅层特征提取模块获得初始特征图,将其输入残差注意力模块组进行深度的特征提取,再经过像素重组模块将特征图从低分辨率空间映射到高分辨率空间,最后与经过上采样的参考帧相加获得重建的高分辨率图像,网络中所有卷积层的卷积核大小均为3×3,中间层通道数设为128。
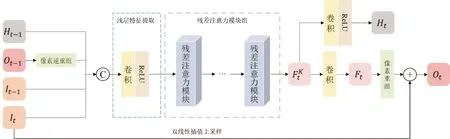
图1 循环残差注意力网络结构
3.1 浅层特征提取
将t 时刻输入网络的低分辨率帧序列表示为:{It-1,It},其中It为参考帧,It-1为相邻帧,先将低分辨率帧It-1、It与上一时刻的隐藏态特征Ht-1和输出Ot-1输入浅层特征提取模块,用一层卷积运算和ReLU激活函数对输入的特征信息进行初步提取,得到浅层特征图,用公式表示为:
其中,σ( )· 表示ReLU激活函数,Conv( )· 表示卷积操作,[ ]· 表示按通道拼接,Ôt-1是经过像素逆重组的上一时刻输出帧,这一步操作是为了保证网络的输入尺寸一致。在初始时刻,上一步的输出和隐藏态特征均初始化为零。
3.2 残差注意力模块
传统的循环神经网络随着网络加深会出现梯度消失,从而无法学习长距离依赖关系,He 等[13]提出使用残差学习,引入残差连接可以保证网络在输入特征不变的基础上学习到新的特征,使网络具有稳定提取深层特征信息的能力。实验结果显示,残差连接可以有效解决梯度消失的问题。此外,由于残差块中的批量归一化层(Batch Normalization Layer, BN 层)会对图像特征进行归一化,破坏原本的色彩分布和对比度信息,影响图像的输出质量,受Lim 等[14]启发,本文将残差块中BN层移除,不仅可以提高网络输出质量,还能节约存储资源和算力资源。
为了提高模型的表达能力,本文还在经过修改的残差块中引入通道注意力机制,形成残差注意力模块,对不同通道的特征图赋予不同的注意力,使网络集中学习图片的高频信息,提高辨别学习的能力,该模块的结构如图2所示。

图2 残差注意力模块
在t 时刻,将经过浅层特征提取的初始浅层特征图输入第一个残差注意力模块,通过K个残差注意力模块对进行深层特征提取,具体过程如下:
在第k个残差注意力模块中,先输入上一个模块的输出结果进行残差特征学习,获得残差特征信息X kt:
再将输入通道注意力结构,对进行全局平均池化,池化结果为一维张量Z,其中第c 个通道的池化过程为:
其中,Zc和分别表示通道向量Z和残差特征信息的第c 个通道,H和W分别表示第c个通道特征图的高和宽。
为了学习各通道间的依赖关系,使用卷积对Z 进行通道下采样,使输出通道数变为原来的1/r,再使用卷积进行通道上采样,恢复原始通道数,生成各个通道的权重S:
其中δ( )· 表示sigmoid 函数,Ur和Dr分别表示比例因子为r的通道上采样和下采样,这里设置r= 16,通过卷积的方式使通道数按比例缩放,最后获得各通道的注意力权重。
将输出的注意力权重按通道加权到残差特征信息的通道上:
最后,引入残差连接,将经过通道注意力加权的残差特征信息与输入的特征信息相加获得该残差注意力模块的输出:
依次经过残差注意力模块组,学习到特征信息,再对其分别进行一次卷积得到深层特征信息Ft,进行一次卷积和ReLU激活函数得到隐藏态特征Ht:
3.3 像素重组模块
如图3 所示,亚像素卷积层的本质是将多通道的特征图重新排列,从而完成从低分辨率张量TLR到高分辨率张量THR的重构,这个过程也可以称为像素重组,即从H×W×c转化为rH×rW×c r2,H和W分别为图像的高和宽,r为比例因子。同理,为了在网络输入阶段将上一时刻的高分辨率输出Ot-1与低分辨率帧拼接起来,也需要对Ot-1进行像素逆重组,保证网络的输入尺寸一致,像素逆重组与像素重组过程相反,它将图像的空间特征重新排列为多通道的下采样子图像,且不会造成信息丢失。

图3 像素重组模块
网络的最后将经过残差注意力模块组生成的深层特征信息Ft进行亚像素卷积,并与经过上采样的低分辨率参考帧It相加,获得高分辨率输出Ot:
其中,PS( )· 表示亚像素卷积,US(·)表示双线性插值上采样。
4 实验设置与结果分析
4.1 数据集与实验参数
本文采用Vimeo‑90k 数据集作为训练集,该训练集涉及大量的场景和运动,包含64612个7 帧的视频段,每帧图像尺寸为448×256。训练时将高分辨率图像先裁剪成256×256 的大小,再使用σ= 1.6 的高斯模糊和比例因子为4 的下采样,最后获得64×64 的低分辨率图像。另外,选取Vid4、UDM10、SPMCS 数据集作为测试集评估模型的效果。
在训练阶段,使用PyTorch构建网络,设置初始学习率为1 × 10-4,每60个epoch乘0.1直至结束,共训练70个epoch,mini batch 设置为8,总迭代次数约560000次。使用Adam 优化器优化网络参数,设置β1= 0.9 ,β2= 0.999,权重衰减为5 × 10-4。在损失函数的选取上,Zhao 等[15]经过实验证明,在图像复原领域L1 损失比L2 损失更容易得到更小的损失值,这是由于L2 损失容易陷入局部最优点,且L2 损失会导致图像过于平滑[16],相比之下,使用L1 损失更能提升模型性能,获得更好的视觉效果,因此本文选择使用L1损失作为损失函数,计算公式如下:
其中,N为输入网络的总帧数。
模型测试阶段,采用峰值信噪比(Peak Signal‑to‑Noise Ratio,PSNR)和结构相似性系数(Structural Similarity Index Measure,SSIM)作为客观评价指标,在测试集上逐帧计算超分辨率输出帧与原高分辨率帧在亮度(Y)通道上的PSNR 和SSIM,PSNR值越大,说明超分辨率重建的效果越好,SSIM 越接近1,则生成的图像与原图的结构相似度越高,视觉效果越好。
4.2 网络深度验证
在保持其他参数不变的前提下,分别设置了由10个和20个残差注意力模块构成的网络进行网络深度验证实验,在测试集上的测试结果如表1 所示。实验证明,PSNR和SSIM随着残差注意力模块的增加而增加,这是因为超分辨率的本质是学习低分辨率图像和高分辨率图像间的非线性映射,更深层的网络模型就意味着更好的表达能力,模型通过加深网络学习到更复杂的变换,从而可以拟合更复杂的特征输入。但一味地加深网络可能使PSNR 和SSIM 趋于饱和或者导致梯度不稳定,从而造成模型性能难以提升甚至下降。此外,加深网络带来的庞大的数据量和计算量使其对硬件设备的要求也随之增加,因此需要选择合适的网络深度进行训练。经过对比,综合考虑模型性能和训练成本等问题,本文最终选用20个残差注意力模块进行实验。

表1 网络深度验证结果对比(PSNR(dB)/SSIM)
4.3 算法先进性验证
将本文提出的算法与传统的双三次插值(Bicu‐bic)算法以及FRVSR[6]、D3D[3]、RBPN[9]和DUF[4]等多个基于深度学习的视频超分辨率算法在Vid4数据集上进行比较,使用PSNR 和SSIM 作为4 倍超分辨率重建效果的评价指标,比较结果如表2 所示。根据表2 可知,本算法在Vid4 数据集上的PSNR和SSIM 分别为27.39dB 和0.835,超分辨率效果总体上优于以上其他模型的效果,PSNR 有0.08-3.94dB 的提升,SSIM 提升0.003-0.219。此外,各模型的参数量与PSNR 的对比关系如图4 所示。总体来说,本文提出的模型参数量适中,与模型的性能取得了较好的平衡。

表2 各模型在Vid4上的测试结果对比(PSNR(dB)/SSIM)

图4 各模型参数量与PSNR对比关系
图5对比了不同方法在Vid4 测试集中的calendar和city 两个场景进行4 倍超分辨率重建后的视觉效果。放大图中蓝色框区域,通过细节对比可以看出,本算法在calendar 中恢复的文字及纹理清晰,细节丰富,颜色过渡相比其他方法也更接近于真实图像。在city 中,经其他方法生成的图像均有一定程度的模糊和结构失真,从细节图可以看出本文算法生成的图像中,墙面的网格结构更加清晰,能较好地恢复出建筑物的外观细节。再选取SPMCS 和UDM10 中的视频片段进行比较,从图6 中auditorium 的放大区域可以看出,相比于其他方法,本算法生成的图像中钢架的形变较少,边界清晰,墙上数字的轮廓也相对更好辨认。在Jvc_009_001 的视频帧中,仔细观察屋檐和木门部分,D3D 和DUF 生成的图片相对更模糊,尤其是屋檐的瓦片,与原图有较明显的区别,本算法对屋檐和木门的恢复则具有更好的视觉效果,在细节上更接近原图。

图5 各模型在Vid4上的重建结果对比

图6 各模型在SPMCS和UDM10上的重建结果对比
5 结论
本文提出的循环残差注意力网络以低分辨率视频帧以及前一时刻的输出帧和隐藏态特征作为输入,使用加入通道注意力机制的残差块进行特征提取,经过亚像素卷积提升分辨率再与上采样的参考帧相加,重建出高分辨率视频帧。通过与传统的双三次插值和其他基于深度学习的视频超分辨率算法进行对比实验,验证了本文算法可以更有效地利用帧间信息恢复更多的高频细节,减轻图像噪声,主观视觉效果更好,客观评价指标更优,但在大运动场景中的重建效果还有待加强,后续将继续研究改进。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
传媒评论(2017年3期)2017-06-13
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
第二课堂(课外活动版)(2016年2期)2016-10-21
