
混合超启发式算法求解复杂两级车辆路径问题
2024-03-02 01:53尹丹,胡蓉**,钱斌,郭宁
云南大学学报(自然科学版) 2024年1期
尹 丹,胡 蓉**,钱 斌,郭 宁
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.云南省计算机技术应用重点实验室,云南 昆明 650500)
随着电子商务的快速发展,物流调度的重要性日趋显著.传统的车辆路径问题(vehicle routing problem,VRP)即仓库直接服务客户的运输方式,难以满足日益增长的需求量;并且多数城市对大型车辆采取限行措施,由此形成两级车辆路径问题(two-echelon vehicle routing problem,2E-VRP)[1].2EVRP 增加了中间设施中转站,中心仓库通过中转站间接服务客户的方式可将大型车辆限制在城市中心之外,在改善城市交通的同时,提高了服务效率[2].同时,全球气候变暖愈加严重,物流调度中的交通运输已成为碳排放的主要来源之一,考虑运输车辆的燃油消耗或碳排放量受到重视[3].此外,在实际情况中,客户的需求往往存在不确定性.譬如,快递公司提供揽收服务时,难以明确客户的需求[4].在上述背景下,本文针对揽收货物的情况,研究模糊需求下的绿色两级车辆路径问题(green twoechelon vehicle routing problem with fuzzy demand,G2E-VRPFD).由于G2E-VRPFD 属于NP-hard 问题.故研究G2E-VRPFD 的建模及其求解算法具有理论价值和现实意义.
2E-VRP 在快递服务、杂货店和电子商务等领域内应用广泛[5].2E-VRP 最先由Feliu 等[1]提出,并建立数学模型.随后,针对以最小化运输总成本为优化目标的2E-VRP 得到了广泛的研究,Zeng 等[6]设计一种基于贪婪随机自适应搜索算法与变邻域下降算法的混合算法进行求解;Breunig 等[7]设计一种改进大邻域搜索算法进行求解;Liu 等[8]设计一种混合模因算法进行求解;Yan 等[9]设计一种基于图的模糊进化算法进行求解;Wang 等[10]基于距离对客户分类将该问题划分为多个VRP 子问题,并设计一种混合蚁群算法求解分解后的子问题;Wang 等[11]考虑了顾客的位置和购买行为等相似特征设计了一种结合聚类算法的增强遗传算法进行求解.针对绿色两级车辆路径问题(green twoechelon vehicle routing problem,G2E-VRP)研究较为有限,Wang 等[12]以最小化驾驶员工资、燃油成本和装卸成本之和为优化目标,设计一种混合变邻域搜索算法进行求解;李正雯等[13]针对带时间窗的绿色多车型两级车辆路径问题(green twoechelon heterogeneous-fleet vehicle routing problem with time windows,G2E-HVRP-TW),以最小化车辆固定成本、时间窗惩罚成本和油耗成本之和为优化目标,设计一种学习型离散排超联赛算法进行求解.
模糊需求车辆路径问题(vehicle routing problem with fuzzy demand,VRPFD)是模糊车辆路径问题(fuzzy vehicle routing problem,FVRP)的一种.现有文献多采用模糊理论处理车辆调度中的不确定因素.王连锋等[14]针对VRPFD,以最小化运输总成本为优化目标,建立其模糊期望值模型,设计一种混合并行粒子群算法进行求解.马艳芳等[15]针对模糊需求下的绿色同时取送货问题(green vehicle routing problem with simultaneous pickup and delivery with fuzzy demand,GVRPSPDFD),以最小化运输总成本为优化目标,将三角模糊数转化为模糊期望值,设计一种改进的遗传禁忌搜索算法进行求解.目前对于VRPFD 已有一定研究,但对实际中广泛存在的G2E-VRP 尚未看到模糊需求下的建模和智能算法求解方面的相关研究.
G2E-VRPFD 综合考虑了2E-VRP 和GVRPFD的特点,更符合现实揽收要求.对2E-VRP 的求解,智能算法已有一定研究.在大多数研究中,都将两级问题视为一个整体,对其进行编码和求解[6-9],由于该类问题的两级问题相互耦合且决策变量复杂,造成解空间规模庞大且编码较为繁琐,仅凭智能算法本身的搜索机制难以在短时间内将算法搜索引导至解空间的较优区域,易造成算法的搜索效率低下.针对两级问题的特性,已有学者成功采用聚类分解将问题分解为多个相同的子问题,再设计智能算法依次对每个子问题进行求解,然后对各个子问题的解合并,获得原问题的解[10-11,13];该类结合分解的方法能将智能算法搜索空间限制在较优区域内,提升智能算法对问题解空间的搜索效率.因此,本文采用结合聚类分解的智能算法对G2E-VRPFD进行求解.
超启发式算法(hyper-heuristic algorithm,HHA)是解决复杂优化问题的一种新型算法.通常被描述为“搜索启发式算法的启发式算法”,该算法通过一种高层策略(high-level strategy,HLS)动态操控多个底层启发式算子(low-level heuristic,LLH)实现对问题解空间的搜索.由于HHA 较于传统的启发式算法拥有良好的通用性,并且无需进行复杂的参数设置即可获得稳定且高质量解[16],因此被用于求解各类车辆路径问题[17-19].基于文献[17-19]调研可知,高效的启发式算法作为HLS 与结合问题特点构造的LLH 是设计HHA 的关键.分布估计算法(estimation of distribution algorithm,EDA)是基于概率模型的算法,能有效避免传统智能算法中存在对较优解模式破坏的问题[20];然而,大部分学者均使用二维概率模型的EDA 求解VRP 相关问题[21-22].由于二维概率模型只能学习操作块信息而无法学习操作块所在的位置信息,使算法在采样生成新个体时可能会因操作块放置不合理而导致算法搜索效率降低,这在引导算法搜索时具有较大的局限性.而三维概率模型通过学习优质解中操作块的位置信息[23],在一定程度上减小对优良解的破坏,提升算法的搜索效率.因此,本文HHA 的高层策略采用基于三维概率模型的EDA 来优化高层个体.此外,HHA 已被成功用于求解多类VRP 上,但尚未发现用于求解2E-VRP 及其相关问题.
综上所述,本文建立最小化车辆运营成本和油耗成本之和为优化目标的G2E-VRPFD 模型.根据G2E-VRPFD 这类问题的解空间复杂且两级问题互耦合的特点,提出一种混合超启发式算法(hybrid hyper-heuristics algorithm,HHHA)进行求解.首先,设计一种聚类分解算法将G2E-VRPFD 分解成多个子问题,用以合理缩小问题的求解规模,实现对两级问题的解耦.其次,利用增强超启发式分布估计算法(enhanced hyper-heuristic estimation of distribution algorithm,EHHEDA)对各个子问题进行求解;然后将各子问题的解合并,得到原问题的解.在EHHEDA 的高层策略域设计一种基于三维概率模型的分布估计算法,该概率模型用于描述优质个体的序结构信息,并通过采样该模型来动态确定由底层操作域中各搜索算子所组成的排列,更好的保护较优解模式不被破坏.在EHHEDA 的底层操作域设计10 种有效邻域搜索算子,对问题解执行深入的搜索,并在每个算子中加入重升温操作的模拟退火机制作为问题解的接受准则,在算法陷入局部最优解时能在一定概率下跳出.最后,通过在不同规模测试集下的仿真实验和算法对比,验证了所提算法在求解G2E-VRPFD 的有效性.
1 G2E-VRPFD 的问题描述及数学模型
1.1 G2E-VRPFD 问题描述及相关假设G2EVRPFD 包括两级物流网络,如图1 所示,第一级网络中含有一个中心仓库、多个中转站和多台可用的大型车辆;第二级网络中含有多个中转站、若干个客户点和多台可用的小型车辆.在揽收过程中,二级车辆先从中转站出发向若干个客户揽收货物,并存放在中转站内;一级车辆再从中心仓库出发为多个中转站揽收货物,其中客户的需求具有一定模糊性.该模型要求在给定目标(运输总成本最小)和约束条件下对客户进行服务,合理安排车辆及服务路线以实现运输总成本最小化.该模型假设:①中心仓库、中转站和客户的信息已知;②在物流网络中,同级网络揽收车辆相同;③中转站仅负责货物中转,不储存货物,同一中转站或客户的货物不得拆分揽收,中心仓库不能直接服务客户;④车辆从中转站或者中心仓库空载出发;每辆车所服务的客户总需求不能超过该车辆的最大载重量;⑤中转站容量(或中心仓库容量)、可用车辆数、揽收能力满足客户点(或中转站)服务要求;⑥车辆空载出发,可同时派出多辆车(不超过可用车辆总数)进行揽收服务.

图1 G2E-VRPFD 示意图Fig.1 Schematic diagram of G2E-VRPFD
1.2 期望模糊需求在现实揽收货物场景中,由于各种不确定因素,客户很难给出一个精确的需求量,通常会根据经验给出一个大致的范围,并在范围中取一个可能的需求值.因此,针对这种需求不确定的情况,本文参考文献[15]引用模糊变量,将客户需求设置为三角模糊数,使用三角模糊数的期望值对客户的模糊需求进行定量处理.
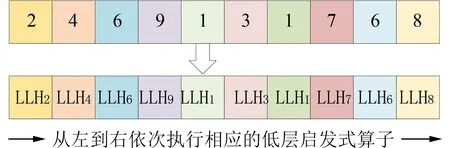
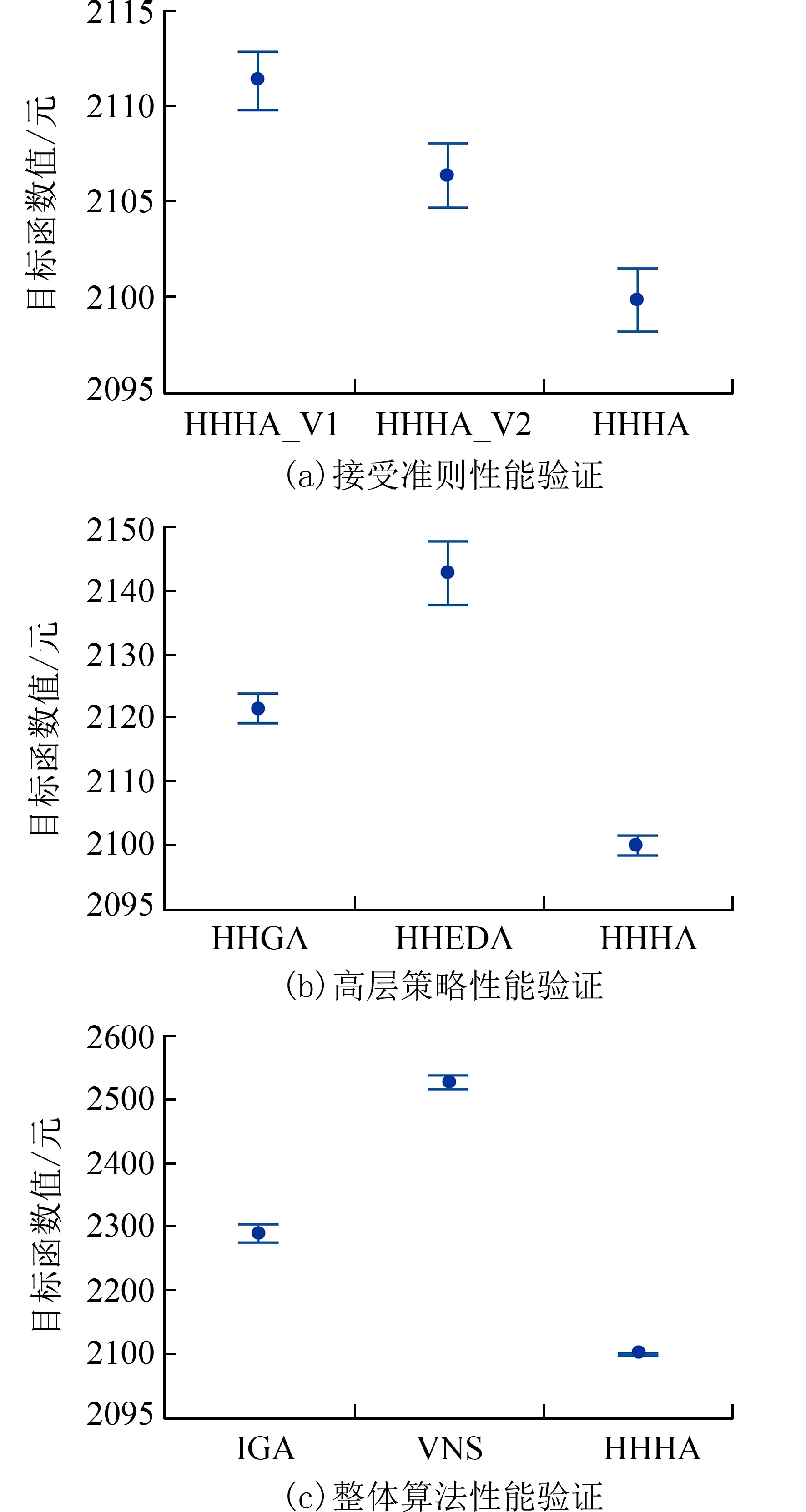
设一客户的模糊需求A=(q1,q2,q3),其中0 设A边 为fA和gA的三角模糊数A=(q1,q2,q3),可得: 定义1区间随机集S~R(A)的期望值称为模糊数A 的期望区间[24],E(A)可表示为: 定义2模糊数A的期望区间的中心称为该数的期望值,用ε(A)表示[24],即: 1.3 问题建模 1.3.1 目标函数 G2E-VRPFD 的优化目标为运输总成本最小化,其中运输总成本(F)包含4 个部分,分别为一级车辆的运营成本(F1)、一级车辆的油耗成本(E1)、二级车辆的运营成本(F2)和二级车辆的油耗成本(E2).F1和F2的计算如下: 碳排放主要来源为车辆使用燃油量,文献[25]表明,燃油消耗量与碳排放量成正比,因此本文采用文献[12]中考虑速度、载重、距离、发动机排量等因素的综合油耗模型计算油耗量,并通过油耗量折算为成本加入运输总成本中.其符号定义如表1所示.根据该模型,一级车辆燃油消耗量成本(E1)和二级车辆燃油消耗量成本(E2)的计算如下: 表1 油耗模型符号定义表Tab.1 Fuel consumption model symbol definition table 式中:c1=KξNV/kψ,c2=ξβ/1 000kψεω,c3=ξ(g(sinθ+Crcosθ))/1 000kψεω. 1.3.2 混合整数线性规划模型 本节所涉及的数学符号及说明如表2 所示. 表2 GVRPFD 模型符号定义表Tab.2 GVRPFD model symbol definition table 问题优化目标为: 式(13)和式(14)表示各级网络中,使用的车辆总数不超过该级拥有的车辆总数.式(15)表示中转站的模糊需求为该中转站所服务的客户模糊需求之和.式(16)表示一个客户有且仅由一个中转站为其服务.式(17)表示中转站的容量约束.式(18)表示中心仓库不能直接服务客户.式(19)表示在第二级物流网络中,每条路径的起点与终点均为同一个中转站,且每个客户有且仅由一辆二级车辆对其进行服务.式(20)和式(21)表示相同节点无路径连接.式(22)表示在第二级物流网络中,开始和结束都应为中心仓库.且每个中转站有且仅由一辆一级车辆为其服务.式(23)和式(24)表示揽收过程中不能超过对应车辆的最大负载.式(25)~(27)表示决策变量. 1.4 问题特点分析及求解思路由图1 可知,G2EVRPFD 第一级问题为GVRPFD,第二级问题为模糊需求下的绿色多车场车辆路径问题(green multidepot vehicle routing problem with fuzzy demand,GMDVRPFD). 该问题的两级问题相互耦合,改变第二级问题的解会影响第一级问题的解.若直接使用智能算法对问题进行整体编码和求解,解空间为第一级问题和第二级问题解空间乘积,并且随着客户数量的增加,造成解空间规模十分庞大;若设计合理的聚类算法将第二级问题分解为ns个相对简单的子问题,则共有ns+1 个GVRPFD 子问题,再对分解后的各个子问题进行求解,此时问题解空间为各子问题解空间之和,该方法可极大程度缩小问题解空间,并能将算法限制在较小且较优的区域进行搜索,缩短算法搜索时间,提升智能算法的搜索能力.因此,根据G2E-VRPFD 的特点分析,本文先采用聚类分解策略分解为ns+1 个GVRPFD 子问题,再设计智能算法对其求解. 本文采用K-medoids 聚类算法将问题分解为多个GVRPFD 子问题,然后设计EHHEDA 依次求解每个子问题,再合并各子问题之解,得到整个问题的解. 2.1 聚类分解策略由于K-medoids 算法聚类结果相当紧凑,且对孤立点和噪声数据的敏感性小[26].因此,本文将K-medoids 的聚类算法应用到求解G2-VRPFD 中,将第二级问题分解为ns个GVRPFD.具体步骤为: 步骤1将中转站坐标设为该算法的初始聚类重心. 步骤2计算各个客户点到聚类重心的欧式距离.将客户点分配为最近的聚类重心. 步骤3将每类中每个客户点均作为聚类重心,计算每个客户点到该类中其余客户点的欧式距离,然后选择欧式距离和最小的点作为新的聚类重心.Ci是聚类重心,Pi是非聚类重心.计算公式如下: 步骤4重复步骤2 和步骤3,直至聚类重心不再改变. 2.2 增强超启发式分布估计算法求解子问题对于将G2E-VRPFD 聚类分解后的每个GVRPFD 子问题,均采用EHHEDA 求解.EHHEDA 由高层策略域和底层操作域组成,在EHHEDA 的高层策略域采用基于三维概率模型的EDA,用于合理学习高层个体的优良模式,其高层个体是由底层操作域中各搜索算子所组成的排列.在底层操作域设计10 种有效邻域搜索算子,并加入重升温操作的模拟退火机制作为问题解(即底层个体)的接受准则,对问题解执行深入的搜索. 2.2.1 编码与解码 在高层策略域种群中,每个高层个体采用十进制的编码方式,一个序号代表相应的底层启发式算子;且每个个体都由10 个底层启发式算子 LLHc构成,可允许每个算子重复出现,一个高层个体编解码示意图如图2 所示.解码时,按高层个体中底层启发式算子的排序,依次对问题解空间执行搜索.高层个体的评价值等于对相应的低层个体执行底层启发式算子搜索后的目标函数值.在底层操作域种群中,每个底层个体为原问题的解.本文将G2E-VRPFD 分解后的ns+1个子问题分别用相同的方式进行编码,编码方式采用基于客户以及中转站排序的十进制编码.譬如,在第G代中转站i服务8 个客户,可记为=[1,2,3,4,8,7,5,6],解码过程中,在满足车辆容量约束的条件下,将中的客户从左到右分配给各车辆,解码后可得到该中转站所有车辆的服务路径=[(1,2,3),(4,8),(7,5,6)]. 图2 高层个体编解码示意图Fig.2 Schematic diagram of coding and decoding of highlevel individuals 图3 统计矩阵模型生成Fig.3 Generation of statistical matrix model 2.2.2 种群初始化 为避免种群中的解分布过于集中,导致无法对问题解空间进行充分搜索,本文在初始化时,设置每个高层个体和底层个体均随机生成,且每个高层个体中的底层启发式算子不重复出现. 2.2.3 底层启发式算子 LLH 中每个底层启发式算子是直接对问题解空间进行搜索,因此LLH设计的好坏决定了搜索能力与解的质量.本文根据问题特性,在算法底层操作域中设计了10 种有效的邻域搜索操作算子,LLH1至 LLH6为车辆内路径邻域操作算子,LLH7至 LLH10为车辆间路径邻域操作算子.具体为: (1) LLH1: Swap(πi,j,m,n),m≠n.πi,j表示中转站i中的车辆j服务路线.在 πi,j中,随机选择两个不相邻客户m和n,将m和n交换,生成新的路径 (2) LLH2: 2-Opt(πi,j,m,n),m≠n. 在 πi,j中,随机选择两个客户m和n,将m和n之间的客户服务顺序逆序,生成新的路径 (3) LLH3: S hift(πi,j,m,n),m≠n. 在 πi,j中,随机选择两个客户m和n,将客户m插入在客户n之前,生成新的路径 (4) LLH4: S wap_two(πi,j,m,n),m≠n. 在 πi,j中,随机选择两个相邻的客户m和n,将客户m与客户n交换,生成新的路径 (5) LLH5: S hift_two(πi,j,s,m,n),s≠m≠n. 在πi,j中,随机选择两个相邻的客户m和n插入到随机选取 πi,j中的客户点s之前,生成新的路径 (6) LLH6: Swap_n(πi,j,s,w,m,n),s≠w≠m≠n.在 πi,j中,随机选择两对相邻的客户s、w与m、n交换,生成新的路径 (7) LLH7: Swap*(πi,j,m,πi,l,n),j≠l. 在 πi,j中 随机选取一客户点m;另外,在 πi,l中随机选取一客户点n,将m和n交换,生成新的路径 (8) L LH8: S hift*(πi,j,m,πi,l,n),j≠l. 在 πi,j中随机选取一客户点m;在 πi,l中随机选取一客户点n,将m插入到n之前,生成新的路径 (9) LLH9: Swap_two*(πi,j,m,n,s,w),j≠l,m≠n,s≠w. 在 πi,j中随机选取两个相邻的客户点m和n;在 πi,l随机选取两个相邻客户点s和w,将m、n和s、w交换,生成新的路径 (10) LLH10:Swap_one*(πi,j,m,n,πi,l,s),j≠l,m≠n. 在 πi,j,随机选取两个相邻的客户点m和n;在 πi,l随机选取一个客户点s,将m、n和s交换,生成新的路径 温度通过式(30)影响底层启发式操作. 式中:Δf为每执行一次底层启发式算子得到的新解与旧解适应度值的差值.迭代时,每个高层个体中的底层启发式操作对相应的解均内部执行5 次,若 Δf<0,则替换旧解;否则生成一个随机数r∈[0,1],若r小于概率P,则接受这个较差解,否则不接受. 随着迭代次数的增加,温度越来越低,根据概率P值接受差解的可能性随之降低,模拟退火机制的停滞导致一直在贪婪搜索,陷入局部极小解时停滞不前,降低算法的搜索性能.因此,本文在模拟退火机制中加入重升温操作,算法最优解持续未改变时,适当提升温度,从而激活较差解的接受概率,对当前解进行一定概率的扰动.升温公式如下: 式中:Δt为最优解持续未改变的迭代次数,u和b为常数. 2.2.4 分布估计算法 三维概率模型基于二维概率模型,能够进一步准确记录操作块在优质解中的具体位置信息,保护较优解操作序列不被破坏,从而合理地引导种群进化方向.因此,本文设计一种基于三维概率模型的分布估计算法作为高层策略,对高层策略域种群进行优化. 在高层个体中,将整个底层启发式操作序列中的两个相邻操作视为操作块.高层个体π1=[2,4,6,9,1,3,1,7,6,8]为 例,其中 [2,4]、[4,6]、[6,9]等为操作块,共有9 个操作块. 为研究高层策略域中优质个体启发式操作序列中的操作块分布特征,设计了一种统计矩阵模型构建三维概率模型.用于统计优质高层个体中操作块[y,z]在位置x上的分布特征,层次结构如式(32)所示,统计方式如式(33)所示. 歌唱是通过声音来表现的。在艺术性歌唱中,歌唱的音色就好象绘画中的色彩,音色的好坏可直接影响歌唱的效果,是音乐中极为动人,最直接触动观众,也是表达真情实感不可缺少的条件。不同的音乐表现不同的音乐形象。歌唱者要学会巧妙地运用自己的声音色彩。根据作品内容,选用恰当的音色,贴切地表现作品。 2.2.6 算法流程 求解子问题的EHHEDA 具体步骤如下: 步骤1算法参数初始化,三维概率矩阵初始化; 步骤2随机初始化高层策略域种群和底层操作域种群. 步骤3将高层个体中的每个底层启发式操作算子对相应的底层个体执行搜索,每执行一次搜索采用模拟退火机制判断是否要接受该解,直至种群中所有高层个体都执行完毕. 步骤4评价底层种群,并将种群中底层个体和对应的高层个体按照目标函数值升序排序. 步骤5选择高层种群中的Nmax×ρ个优质个体,更新统计矩阵. 步骤6更新三维概率矩阵. 步骤7轮盘赌采样更新高层策略域种群. 步骤8若最优解持续超过b代未改变,模拟退火机制采用公式(31)重升温;否则,采用公式(29)降温. 步骤9判断是否到达终止条件.若算法达到终止条件,则输出最优解;否则调整至步骤3. 目前暂无G2E-VRPFD 的标准测试数据,故本文采用文献[6]中的部分算例组成的测试集,客户的需求量基于三角模糊数随机生成,改编后的数据地址:https://pan.baidu.com/s/12JFy_nJ-1XOB145Oz n4-eQ?pwd=a123(提取码:a123).本文利用Python 3.8对本文中所有算法进行编程测试,操作系统为Windows 10,CPU 主频为2.40 GHz,8 GiB 内存.对所选取的不同规模测试集,每种算法均在相同时间20×nc×nsms 下,运行20 次. 3.1 关键参数设置G2E-VRPFD 模型中的油耗模型中的系数设定参考文献[13],燃油费用系数设参考文献[27];运营成本系数设定参考文献[28].第2.2.3 节加入重升温操作的模拟退火机制中,初始温度T=100,b=3,系数u=10. 在HHHA 中,主要参数有种群规模Nmax、学习率 γ、精英个体所占比例 ρ和冷却系数 λ.为考察各参数设置对算法效果的影响,本节采用文献[29]实验设计方法DOE 确定HHHA 的参数取值.上述4 个参数均取4 个水平值,如表3 所示. 表3 HHHA 各参数水平表Tab.3 Level table of main parameters 基于表3,采用正交表L16(44),使用中等算例75×5_1在16 组不同水平参数组合下进行实验.每组参数在相同时间内独立运行20 次,20 次结果的平均值作为平均响应值AVG,AVG 越小则代表在相应的参数设置下算法性能越好.正交表和AVG统计值如表4 所示. 表4 正交表和 R 统计值Tab.4 Orthogonal table and R statistics 根据表4 中的AVG 统计值,得到表5 中各个参数在不同水平下的平均响应值和等级,其中等级一栏表示参数对算法性能的影响力等级排名,以及各参数的响应趋势图(图4),每组水平的最低点表示算法性能占优. 表5 HHHA 各参数响应值Tab.5 Response value of HHHA parameters 图4 HHHA 各参数在不同水平下的响应趋势图Fig.4 Response trend of HHHA parameters at different levels 由表4、表5 和图4 可知,当HHHA 的参数设置为:Nmax=40,γ=0.6,ρ=0.5,λ=0.9时,其性能在不同参数组合下的各算法中占优.因此,后续测试中按此设置HHHA 的参数. 3.2 仿真结果比较与分析本文通过所设计的接受准则、高层策略域算法以及整体算法这3 个部分,验证所提算法的有效性.其中,用R1、R2和R3分别表示一个算例独立运行20 次输出本文目标函数值最小化运输总成本的平均值、最优值和最差值. 基于所有算例独立运行20 次结果的横向均值,得到6 个不同智能算法与HHHA 比较的95%置信区间图如图5 所示,纵坐标表示横向平均目标函数值.算法区间图所处的位置越低,表示该算法性能越好;区间越小,算法越稳定. 图5 HHHA 和6 种不同算法比较的95%置信区间图Fig.5 95% confidence interval diagram of HHHA and 6 different algorithms 3.2.1 验证接受准则有效性 为验证HHHA 中底层启发式算子嵌入的重升温操作的模拟退火机制作为接受准则的有效性,在文本问题上,将其与接受准则为只接受好解的HHHA(HHHA_V1)和接受准则为模拟退火机制但是无重升温操作的HHHA(HHHA_V2)进行比较.实验结果见表6,HHHA 与HHHA_V1、HHHA_V2 的95%横向均值区间置信图见图5(a). 表6 接受准则性能验证Tab.6 Performance verification of acceptance criteria 由表6 和图5(a)可知,HHHA 优于HHHA_V1和HHHA_V2.原因在于,将只接受好解作为接受准则的HHHA_V1,迭代过程中一直在贪婪搜索,算法容易较早的陷入局部最优状态,无法跳出,在后期浪费不必要的搜索时间,降低搜索能力.而将每个底层启发式算子中嵌入模拟退火机制,未加入重升温操作作为接受准则的HHHA_V2,虽然在算法迭代前期,模拟退火机制以一定概率接受差解,避免算法较早陷入局部最小,但在后期随着温度的不断降低,导致模拟退火机制停滞,而HHHA 中的重升温操作在达到一定条件下可激活模拟退火机制,提升算法全局的搜索能力.因此在将底层启发式算子嵌入重升温操作的模拟退火机制作为接受准则有一定有效性. 3.2.2 验证高层策略有效性 为验证HHHA 中的EHHEDA 高层策略有效性,在不同规模测试集上,分别将其与传统GA 作为高层策略的超启发式算法(HHGA)和传统EDA 作为高层策略的超启发式算法(HHEDA)进行实验对比,算法其余部分保持一致.实验结果见表7,HHHA 与HHGA、HHEDA的95%横向均值区间置信图见图5(b). 表7 高层策略性能验证Tab.7 Performance verification of high-level strategy 由表7 和图5(b)可知,HHHA 优于HHGA 和HHEDA,且HHHA 更稳定.一方面,HHHA 作为一种学习型的智能算法,可避免HHGA 这类经典进化算法在每次迭代时,通过交叉变异操作对种群中较优高层个体的破坏,导致过多无效的操作,降低算法的搜索效率;另一方面,HHHA 通过学习高层个体中操作块位置信息来更新高层种群,可在一定程度上避免HHEDA 对优质操作块的破坏,更为合理地学习高层个体的优良解模式. 3.2.3 验证本文整体算法有效性 因目前无G2EVRPFD 的相关研究,为验证HHHA 的整体有效性,在本文问题上,将HHHA 与国际期刊上求解相似问题的VNS[12]和IGA[30]进行对比.其中VNS 和IGA 均是对整个问题进行编解码,无聚类分解阶段.各算法比较结果如表8 所示,HHHA 与VNS、IGA 的95%横向均值区间置信图见图5(c). 由表8 和图5(c)可知,随着客户数量的增加,HHHA 显著优于VNS 和IGA 算法,且HHHA 算法稳定型更强.表明对两级问题整体编码并求解,难以在短时间内获得满意的解.以算例21×2_1(客户、中转站和中心仓库的数量分别为21、2 和1)为例,若对该算例整体编码与求解,解空间为S1=21!×2!.如果采用k-medoids 算法将该算例的第二级问题分解为两个GVRPFD 子问题:客户数分别为12 和9,则第一级问题中的2 个中转站容量便可以根据这两个客户数固定下来,实现了两级问题间的解耦,而此时的解空间为S2=12!+9!+2!.显然,S2远远小于S1.因此,采用有效的分解策略可明显缩减搜索区域,将算法引导至较优区域进行搜索,有利于提高算法的搜索效率.此外,VNS 和IGA 这类常规的智能算法,在迭代循环时,均采用固定顺序的几个局部搜索操作对问题解空间进行搜索,未考虑到操作顺序对搜索能力的影响,使算法在对解空间搜索时有一定局限性.而HHHA 中的EHHEDA 通过采用高层策略学习优质个体中启发式操作顺序,动态混合多种底层启发式算子更新种群,实现对问题解空间的搜索,可较易发现解空间不同区域的优质解,提高算法的搜索能力.因此,HHHA 在测试算例中表现优异. 本文针对模糊需求下的绿色两级车辆路径问题(G2E-VRPFD),考虑距离、载重、速度等多个因素,使用综合油耗模型计算方法,建立以最小化车辆运营成本和油耗成本之和为优化目标的数学模型,进而结合问题特性提出一种混合超启发式算法(HHHA)进行求解.所提算法具有如下优点: (1)考虑G2E-VRPFD 的解空间庞大且两级问题相互耦合,采用K-Medoids 算法对G2E-VRPFD进行分解,可明显缩减搜索区域,从而能一定程度上避免无效搜索; (2)EHHEDA 的高层策略域采用基于三维概率模型的分布估计算法,能合理学习和积累优质高层个体的操作块信息,从而可有效引导和控制算法搜索行为,有助于提升算法搜索效率; (3)EHHEDA 的底层操作域设计10 种高效底层启发式算子(即邻域搜索算子)来共同执行对问题解空间的搜索,并加入重升温操作的模拟退火机制,以帮助算法跳出局部极小,可加大算法搜索的深度,从而能进一步增强算法性能. 通过在不同规模测试集下的仿真实验和算法对比,验证了所提算法可有效求解G2E-VRPFD.后续工作将进一步研究考虑路况的绿色两级车辆路径问题的建模与求解.

2 混合超启发式算法(HHHA)

3 实验设计与分析






4 结论
猜你喜欢
军事文摘(2023年2期)2023-02-17
杭州金融研修学院学报(2022年11期)2022-11-26
军民两用技术与产品(2022年2期)2022-06-01
上海建材(2021年1期)2021-11-22
江西建材(2018年4期)2018-04-10
安全(2015年6期)2016-01-19
太空探索(2015年9期)2015-07-12
福建人(2015年11期)2015-02-27
中国卫生(2014年12期)2014-11-12
小说林(2014年5期)2014-02-28
