
基于知识与AW-ESN 融合的烧结过程FeO 含量预测
2024-03-04 02:04方怡静蒋朝辉桂卫华
自动化学报 2024年2期
方怡静 蒋朝辉 ,2 黄 良 桂卫华 ,2 潘 冬
随着钢铁冶金行业的不断发展,铁矿石资源日益紧缺且禀赋恶化,已难以满足高炉绿色高效低碳冶炼的需求[1-2].烧结是将贫铁矿加工成富铁矿,有利于高炉冶炼的过程,为高炉炼铁提供主要原料,其烧结矿质量对高炉的稳定顺行至关重要.
烧结矿的FeO 含量不仅是衡量烧结矿质量的重要指标,而且是影响高炉冶炼能耗、排放的重要因素.因此,实时准确获取FeO 含量对烧结过程的智能化调控、提升烧结矿质量、保证高炉平稳顺行和绿色低碳高效生产具有重要意义[3-6].
由于烧结过程中存在高温、高尘、多相共存、多场耦合等特点,烧结矿FeO 含量难以直接在线检测.通常工业现场对FeO 含量的检测,主要是采用人工定期采样,再利用重铬酸钾化学分析法、X 射线光谱分析法等方法对采样样本进行离线分析[7-9].这些方法存在检测速度慢、设备成本高、操作复杂等局限性,且检测结果时间滞后大,导致烧结矿的质量信息不能得到及时反馈,严重制约了烧结过程的精细化调控,无法满足烧结现场实时检测的需求.因此建立FeO 含量的预测模型,实现FeO 含量的高精度在线预测对于烧结过程的优化具有重要意义.目前,烧结过程FeO 含量建模方法可以总结为以下三种: 1)基于物料守恒的建模方法,主要是通过对过程的其他相关参数进行在线检测,基于物料守恒的原理,建立机理模型,计算FeO 的含量[10-12],该思路适用范围广、可解释性强,但所需的检测设备费用高昂,且各烧结厂冶炼环境和原材料各异,烧结过程发生的物理化学反应复杂多变,难以通过机理模型准确地计算出FeO 含量.2)基于烧结机尾断面图像信息,结合现场专家经验建立的软测量模型[13-15].这一类方法基于专家经验建立模型,提取到的图像信息一定程度上也能反映FeO 的含量信息.然而烧结机尾高温、多粉尘的生产环境,会极大地影响图片获取的质量,仅利用图像信息难以获取精准的FeO 含量.3)基于烧结过程生产数据建立的数据驱动模型[16-21].这一类方法不需要了解烧结过程发生的复杂反应,仅通过数学工具和智能算法对历史时刻的过程数据中包含的规律进行挖掘,就可以建立烧结矿质量指标的预测模型,因此数据驱动模型成为近年烧结过程FeO 含量建模研究的热点.
国内外学者在基于数据驱动的FeO 含量预测上做了许多相关的研究.文献[19]和文献[20]分别利用BP 神经网络和前馈神经网络建立FeO 含量的预测模型,由于上述网络存在过拟合和易陷入局部最小值的问题,取得的预测效果并不理想.文献[21]采用深度信念网络(Deep belief network,DBN)进行FeO 含量的预测,然而DBN 作为一种深度网络,需要大量训练样本且计算成本较高,难以应用于实际的烧结过程中.由于烧结过程具有动态性和时序性,烧结矿的FeO 含量不仅与当前的工艺参数有关,同时受历史时刻的工艺参数影响,这要求网络具有较强的时间序列数据处理能力.循环神经网络(Recurrent neural network,RNN)在时间序列建模上展现了良好的性能,但收敛速度慢、易陷入局部最小值和计算复杂度高等问题限制了其在实际工业过程中的应用[22-23].回声状态网络(Echo state network,ESN)作为一种特殊的RNN,具有短期记忆的显著潜力,并且对于非线性系统的动态预测表现出了良好的性能[24-26].ESN 的输入层和储藏层的权值采用随机值初始化的方式确定,只有输出层的权值需要通过训练获得,一定程度上避免了预测模型陷入局部极小值,提高了学习速率.
然而,作为一种数据驱动模型,ESN 应用于烧结过程的FeO 含量建模仍存在一定的局限性,由于烧结过程热状态参数缺失,且数据驱动模型对机理缺乏认知,易致使模型的泛化能力不足,而工业过程存在的变量漂移等问题也会导致模型的预测精度降低.针对上述问题,本文提出了一种将机理知识与数据驱动模型相结合的建模方法.通过对烧结过程的传热机理进行分析,建立了料层最高温度分布模型,从而获取烧结过程的温度分布特征,结合过程数据和专家经验,挖掘过程数据中的专家知识,实现基于数据知识的FeO 含量等级划分.获取的FeO 含量知识用于对ESN 模型输出函数的改进,实现机理知识与ESN 的融合,降低了过程扰动和噪声对预测结果的影响,同时提出了一种新的基于梯度的权重调整策略(Adaptive weight strategy)用于ESN 输出权重的学习,最终建立基于知识与AWESN (Adaptive weight echo state network)融合的烧结过程FeO 含量预测模型—基于知识与变权重回声状态网络融合的模型 (Fusion of dataknowledge and adaptive weight echo state network,DK-AWESN).基于某钢铁厂的烧结厂的实际生产数据验证了本文所提的基于知识与AW-ESN融合的烧结过程FeO 含量预测方法的有效性.
1 基于料层温度分布特征的FeO 含量等级划分
烧结矿中FeO 主要以磁铁矿和含铁硅酸盐的形式存在,如铁橄榄石、钙铁橄榄石,而含FeO 的液相铁橄榄石、钙铁橄榄石的生成温度要求极高,因此烧结料层内部热状态与烧结矿的FeO 含量关系密切,但是烧结过程的工艺特性导致实际烧结过程不能直接观察,现有的检测手段无法准确获取烧结过程各阶段的料层温度.为了建立准确的烧结过程FeO 含量预测模型,需要在建模前对烧结料层内部热状态进行深入分析.烧结料层内部热状态的变化体现为温度变化,不同时刻的温度特征信息可以反映烧结料层中FeO 的含量.因此,本节通过对烧结过程气-固传热机理分析建立烧结料层的最高温度分布模型,获取各料层的温度分布特征,结合专家经验,从过程数据中提取出一系列规则作为专家知识,利用模糊推理的方法,实现对烧结矿FeO 含量等级的划分.
1.1 烧结料层温度分布特征提取
如图1 所示,将带式烧结台车当作由若干个固定单元串联形成的整体,混合料沿y方向横向铺在烧结机上,同时在沿x方向水平缓慢移动,风箱作业使得空气垂直混合料表面竖向沿z方向流动.本节利用现场工艺参数结合传热学理论,建立基于微元 dz的烧结过程热状态模型用以计算烧结矿各层温度的最大值,实现烧结料层温度分布特征的提取.
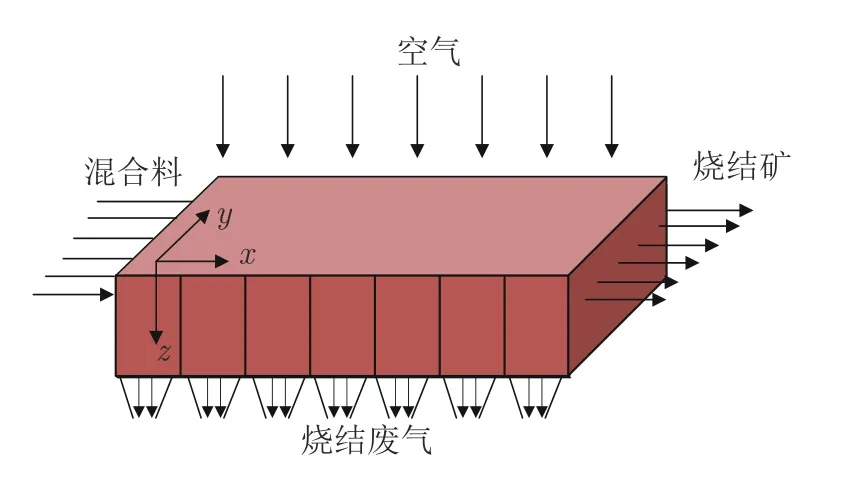
图1 烧结过程示意图Fig.1 Schematic diagram of sintering process
为方便模型计算,假设烧结过程在每一层的横向烧结状况相同,在纵向对每个无穷小厚度 dz进行气体、固体的热平衡计算[27].首先针对固体在单位体积、单位时间的热增量等于气-固单位时间、体积热交换值与反应热增量之和建立热平衡方程,其次针对气体在同样的单位时间、体积的热变化等于气-固热交换与反应热之和建立热平衡方程,即
式中,vg和vs分别表示气体流速和固体流速,ρg和ρs分别表示气体密度和固体密度,和分别表示气体比热容和固体比热容,ε表示料层孔隙率,Tg和Ts分别表示料层气相温度和固相温度,h为气-固相间对流传热系数,s为单位体积颗粒总表面积,τ为料层的有效导热系数,Rc表示化学反应的综合反应速率,ΔHc表示反应的反应焓,此处反应指焦粉的燃烧反应.
烧结过程按燃料的燃烧程度可以分为两个阶段: 1) 当燃料未燃尽时,烧结域内的热源主要来自燃料的燃烧放热,由式(1)可知烧结过程固相的热量主要由内部热源和上部气体传热供给.假设气体只在z方向上均匀流动,对于微小料层 dz,可以认为其处于静止状态的非稳态传热(vs=0).假设烧结料层不导热,料层内部只进行气固热交换,传热系数足够大使得空间内任何点有相同固相-气相温度,则有,热平衡方程为
2)当烧结过程进行到燃料耗尽的成矿区域时,假设此时只存在上层气体与下层物料的热交换,无其他反应热供给(消耗),则此时的化学反应热值q=RcΔHc为0,此时料层内部的热平衡方程为
根据上述分析,为了完善建立的热交换模型,需要建立一个合适的燃料燃烧模型及判断两式转折的临界点模型.
1)燃料燃烧模型
对于烧结过程而言,焦粉在料层中以焦炭颗粒形式存在,其作为燃料在单位时间、体积内的反应热为
式中,Rc为反应速率,ΔHc为反应焓.焦炭的燃烧过程采用一级化学反应式表示,即
焦炭颗粒在燃烧时会由外向内逐步燃尽,原粒径为r的焦炭颗粒在燃烧一段时间后剩余部分的粒径为rc.因此在燃烧过程中,焦炭颗粒的粒径可以直接反映燃料剩余量,焦炭颗粒的反应速率可以表示为
由上述参数计算可知在每个时刻 dz内的综合反应速率Rc,计算所需的参数取值如表1 所示.假设单位体积的料层包含n个焦炭颗粒,则
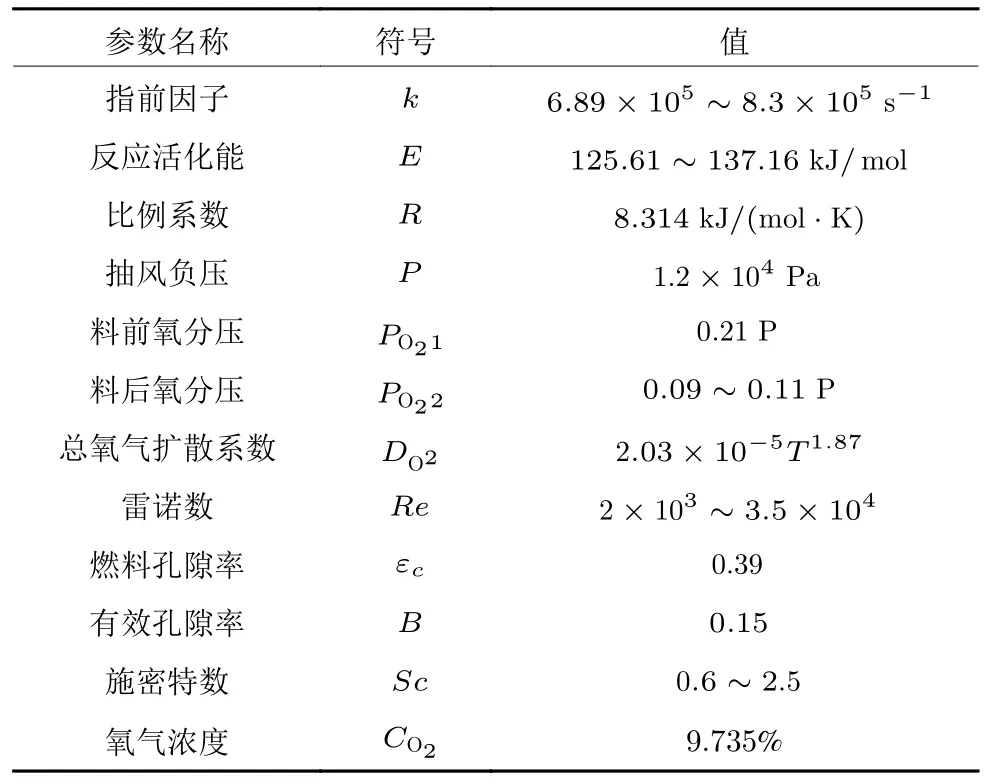
表1 反应速率计算参数表Table 1 Reaction rate parameters
式中,βc为燃料的百分含量,若已知单位体积料层中燃料颗粒个数,则可以通过计算得到每层烧结料中燃烧热为
式中,kc,km,ko的计算方式见式(6).
2)燃料是否耗尽的分界判据
当燃料颗粒未耗尽时,空气中氧气由于传质作用透过燃尽的灰层进一步与焦炭燃料接触,此时外界温度已达到焦炭700 ℃的燃点,所以仍然存在式(5)所示的一级反应.由于化学反应导致的焦炭消耗将使得焦炭粒径减少,在整个过程中单位体积内焦炭的摩尔数为
式中,ρc为焦炭密度,Mmol为碳的摩尔质量,所以在单位体积料层内包含的燃料量可以用Vmol表示,当燃料量小于Vmol时则可以判断燃料被消耗完毕.根据推导得到的燃料燃烧综合反应速率Rc,可以计算出燃烧反应t时刻后燃料的总消耗量为
易知当Vsum=Vmol时,热交换方程中燃料燃烧的部分不再作用.利用烧结过程中基于燃料是否耗尽的有、无热源分界判据结合燃料燃烧热模型可以代入式(2)和式(3)所示的两阶段的燃烧热平衡方程,最终得到的解析式为
经推导,得到了在一定假设下的完整烧结热交换模型,在满足判据的条件下分别按照有热源、无热源的固-气偏微分方程进行计算.由于模型为气-固两相的热交换偏微分方程,本文利用偏微分方程的数值解方法求解.
根据模型计算得到整个烧结料层的最高温度分布在时间维度上的变化,如图2 所示.随着吸风烧结过程的进行,烧结过程前30%阶段燃烧带的最高温度快速增加,但是在后70%阶段燃烧带最高温度增长速度变慢,尤其是后30%阶段温度基本不再增加.这是由于气固流动带来的显热增量逐渐达到饱和值,饱和温度在1 420 ℃左右,与理论分析的情况相符合.

图2 料层全时空最高温度分布Fig.2 Maximum temperature distribution of sinter bed in whole time and space
根据图3 所示的烧结料层的全时空温度分布图可清晰地看出,在整个烧结过程中,随着蓄热作用的不断进行,料层中燃烧层的温度会持续攀升,燃烧区域会持续扩大,这说明本文建立的模型能够较好地还原烧结过程的全时空传热状态.且从图3 中可以看出,烧结料层在不同时刻下的最高温度值是变化的,料层内部发生的物理化学反应也必然会存在差异,因此烧结料层最高温度是影响烧结矿FeO含量的重要热状态参数.
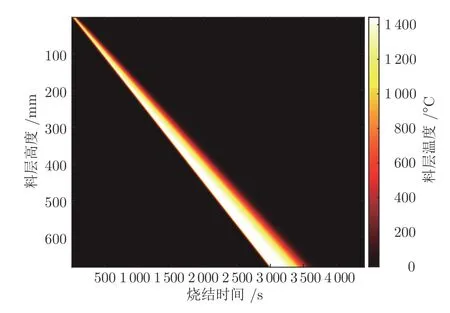
图3 料层全时空温度分布图Fig.3 Temperature distribution of sinter bed in whole time and space
1.2 烧结过程FeO 含量等级划分
烧结过程是一个机理复杂、非线性的动态时变过程.影响烧结过程的因素众多,难以通过机理分析获取准确的FeO 含量,而烧结现场的专家通常能够基于经验和生产数据大致判断FeO 含量的区间.因此,本节根据专家经验,从过程数据中提取出一系列规则作为专家知识,利用模糊推理的方法,实现对烧结矿FeO 含量等级的划分.
为了从过程数据和专家经验中获取知识,基于模糊规则对过程数据进行规则提取,提取得到的规则可以表示如下:
在上述规则中,x1表示烧结料层最高温度,x2表示料层高度,x3表示混合料燃料比,x4表示全铁,y表示烧结过程烧结矿FeO 含量等级,A1q,A2q,A3q,A4q,fq分别是x1,x2,x3,x4,y的模糊集合,且各规则的模糊蕴含关系都已知,现在根据x1,x2,x3,x4,y上的模糊集合推出新的模糊集合f*.
基于某钢铁集团烧结厂数据库中的历史数据和料层最高温度模型的计算结果,可以获得各过程参数的变化范围.基于隶属度,各参数的变化范围划分为4 个区间,即最大合适区间、中等合适区间、小合适区间以及不适合区间,各参数的隶属度函数如图4 所示.

图4 各参数隶属函数Fig.4 Membership function of each parameter
推算值与数据库中FeO 含量化验值对比如表2所示.通过对600 组样本的实验结果进行统计,烧结矿FeO 含量“偏大”数据有153 组、“正常”有396 组,“偏小”有51 组,对比推理结果与实际化验数据,仅仅29 组数据的推理结果与化验数据不符.本文建立的FeO 含量等级推理模型准确率高达95.17%,实际生产允许的误差范围为5%以内,因此,所提基于烧结料层温度分布特征提取的烧结过程FeO 含量等级划分方法的精度符合现场需求,且能为后续建立准确高效的预测模型奠定基础.

表2 FeO 含量等级推理结果与实际值对比Table 2 Comparison of the inference results with measured values of FeO content
2 基于DK-AWESN 的烧结过程FeO含量预测
面对烧结过程的强耦合性和动态复杂性,本文提出一种基于知识与AW-ESN 融合的烧结过程FeO 含量预测方法.首先,提出一种基于核函数高维映射的多尺度数据配准方法,用于构造建模样本集;其次,提出一种新的权重调整策略用于ESN 的输出权重调整;最终,基于模糊规则从过程数据中提取的FeO 含量知识融入到AW-ESN,建立DKAWESN 模型用于FeO 含量的预测.本文所提方法的总体框图如图5 所示.

图5 基于DK-AWESN 的FeO 含量预测方法框图Fig.5 Schematic of FeO content prediction method based on DK-AWESN
2.1 FeO 含量相关变量确定及输入数据集的构建
烧结矿的FeO 含量与配料参数、烧结过程检测参数和设备状态参数等过程参数息息相关.本文采用灰色关联分析法(Grey relational analysis,GRA),通过定量计算FeO 含量序列的曲线与过程参数序列的曲线之间的相似程度判断FeO 含量与过程参数的相关性,从而确定预测模型的输入变量.
在计算参数与FeO 含量之间的关联度之前,对工艺参数序列进行归一化处理,即
式中,i=0,1,2,···,m,k=1,2,3,···,n,{zi(k)}表示归一化前的第i个参数序列,zi(k) 表示序列中的第k个元素,{xi(k)} 表示归一化后的序列.{z0(k)}代表参考序列,为FeO 含量的序列,{zi(k)} 代表比较序列,为各工艺参数的序列.
完成归一化后,计算每个比较序列与参考序列的关联系数,即
式中,ρ表示分辨系数,取值范围为[0,1],本文取ρ=0.5,ξi(k) 表示第i个参数的灰色关联系数.
在计算每一个参数值的关联度系数后,根据式(14)计算烧结过程各工艺参数的灰色关联度ri.
以烧结矿FeO 含量为参考序列,烧结过程工艺参数为比较序列,从烧结数据中心选取300 组样本数据用于计算各过程参数与FeO 含量之间的灰色关联度.根据计算结果,表3 列出了灰色关联度较高的20 个参数.

表3 各过程参数的灰色关联度Table 3 The grey relational degree of process parameters
当过程变量与FeO 含量之间的灰色关联度大于0.5 时,可以认为变量与FeO 含量之间存在较强相关性.从表3 可以看出,燃料配比、料层高度、原料中氧化镁含量(CMgO)等配料参数在灰色关联分析下与FeO 含量存在较强相关性.除了配料参数,还有风箱废气温度、空支流量、烧结机机速、返矿比等10 个过程参数也具有较高相关性,因此将这15个变量作为预测模型的输入.
烧结数据中心FeO 含量的数据记录间隔为2 h,而这2 h 内对应的工艺参数的采样频率远高于FeO 含量,数据量不平衡将导致预测模型无法正常训练,且过程参数的频繁波动会造成模型精度的下降.为解决这一问题,本节提出了基于核函数高维映射的多尺度数据配准方法,对不同时间尺度的数据进行匹配,通过提高输入样本集的质量,从而提升模型的预测精度.该方法的具体步骤如下:
步骤 1.从历史数据库中收集风箱废气温度、料层透气性等q个过程参数数据以及对应历史时刻的FeO 采样数据.初始化集合
步骤 2.假定第i个过程参数在第t个FeO采样时间间隔内的数据集为通过核函数φ(·),映射到高维空间,其映射集为A=,式中φ(·) 为高斯函数,其定义为
其中,xi(k) 表示第i个输入参数序列中第k个数据点,n表示第i个过程参数序列的样本数,σ表示高斯函数的伸缩量.
步骤 3.定义={φ(xi(l))∈A|dist(φ(xi(k)),φ(xi(l)))≤γ},式中,γ为距离阈值,dist(φ(xi(k)),φ(xi(l))) 为映射点φ(xi(k)) 和φ(xi(l)) 的欧氏距离,计算式为
式中,εi表示距离系数,取值范围[0.1,0.2],,分别表示映射集在第p维的最大值和最小值,m表示映射维度.
步骤 4.若存在表示中包含的样本个数,则称φ(xi(k)) 为核心对象Mφ(xi(k)),若Mφ(xi(k))不唯一,再进行一次高维映射,重复步骤3 和步骤4,直至核心对象Mφ(xi(k))唯一,则令xi(k)∈Bi.
步骤 5.重复步骤2~4,直至计算得到所有FeO 采样时间间隔内的Mφ(xi(k)),此 时,Bi=,N为FeO 样本个数.
步骤 6.重复步骤2~5,直至计算得到全部过程变量的核心数据集Bi,最终得到输入样本集
2.2 DK-AWESN 预测模型搭建
由于烧结过程是一个动态的、时变的过程,具有强耦合、大时滞等特点.烧结过程参数在时间和空间维度上互相耦合,致使当前时刻烧结矿的质量不仅与历史的烧结矿质量相关,同时影响着未来的烧结矿质量.因此,烧结矿的FeO 含量不仅与当前的工艺参数有关,而且受历史时刻的工艺参数影响.这就要求所建模型具有动态记忆历史信息的能力,在学习新信息的同时存储历史信息.回声状态网络(ESN)具有大规模随机稀疏网络(储备池)作为信息存储和处理的单元,因此非常适合用于烧结过程FeO 含量预测.一个无输出反馈的ESN 由三个基本单元组成: 一个输入层、一个大型的循环隐藏层(储备池) 以及一个输出层.输入层是随机连接到储备池的,而储备池包含稀疏随机连接的神经元用于存储相关的信息和保存时间特性[28].假定网络的输入为x(k)∈RM,k-1 时刻储存库的状态变量为u(k-1)∈RN,标准的ESN 离散模型可以表示为
式中,y(k)∈RL是k时刻的模型输出,Win,Wres,Wout分别表示模型的输入权重、储存池的连接权重以及输出权重.其中,Win,Wres是随机生成的,Wout通常通过训练算法来计算和更新.f(·) 是存储层的激活函数,本文选择tanh 函数;fout(·) 是输出层的激活函数.
模型性能与输入数据的选择方法和网络参数的确定方法具有强相关性.本文在第2.1 节中提出了基于核函数高维映射的多尺度数据配准方法,用于建模数据集的构建.本节中,提出了一种基于梯度的权重调整策略用于ESN 输出权重的更新.首先定义网络的误差函数E(k) 为李雅普诺夫函数,即
式中,e(k) 为预测结果的误差,yt(k) 表示实测值,y(k)表示模型的预测值.网络参数的学习算法为
lr表示算法的学习率.
为了更好地证明所提模型的收敛性,对误差函数e(k) 进行泰勒展开,可得
式中,R(Θ(k)) 为皮亚诺余项.
根据皮亚诺余项的性质,可以推导得到
即存在φ>0,使得‖ΔΘ(k)‖<φ时,|R(Θ(k))|<‖ΔΘ(k)‖.由式(21)可知
所以,当‖ΔΘ(k)‖<φ时,可得
定理1 给出了参数学习算法的收敛性分析.
定理 1.若‖ΔΘ(k)‖是有界的,且也是有界的,按照式(21)训练AW-ESN 的网络参数,则存在一个满足式(26)的学习率使得网络收敛.
证明.当学习率lr被选择满足式(26),能够推得
通过式(21),可以得到
根据式(20)和式(22),可得
通过式(25),可以推导得到
当e(k)>0,式(30)可以推得
当e(k)<0,式(30)可以推得
当选择的学习率lr满足式(26)时,可以推得
由式(32)和式(33)可知,当e(k)<0 时,可以推得
通过上述推导过程可知,根据李雅普诺夫稳定性原理,如果选择合适的学习率,AW-ESN 的收敛性可以得到保证.
2.3 知识与AW-ESN 模型的融合
由于缺乏机理认知,当数据驱动模型应用于实际工业过程,面对复杂多变的工况时,模型会出现泛化性能差,从而导致预测精度下降等问题.尽管本文已经从改善建模数据质量和提出新的训练算法两个方向上开展了一定的工作,力求实现模型预测性能的提升.但是由于样本的特征量多,工业过程的数据波动仍会对模型预测性能的稳定性造成干扰.机理分析和专家经验能够反映烧结过程的本质规律,因此,通过对烧结过程机理进行分析,将过程数据中包含的专家知识与数据驱动模型相结合,能够有效弥补数据驱动模型缺失的过程信息.根据上述问题和解决策略,本节基于过程数据中提取得到的FeO 含量等级知识,将提取得到的知识与AWESN 融合,建立DK-AWESN 模型,从而减少复杂工况造成的模型泛化性能下降.
如图5 所示,在DK-AWESN 中,烧结过程的专家知识被用于改进输出层中的激活函数fout(·).基于料层温度分布特征和专家经验获取的FeO 等级知识用于构建新的激活函数g(·),从而取代原本激活函数fout(·).g(·) 的表达式为
式中,y表示模型的输出;kg1,kg2分别表示根据专家知识得到的FeO 含量等级的下限值和上限值;α表示等级系数,在本文中取值为0.5.
通过上述融合策略,机理知识被融入到AWESN 的输出激活函数中,改进后的激活函数由于融入了基于过程机理划分的FeO 等级知识,能够有效地降低由于工况波动造成的模型预测结果过高或者过低的现象.由改进的激活函数g(·) 可以看出,当预测结果超出专家知识划分的等级范围时,模型能够综合专家知识和预测结果,将最终的预测值调整回到正确的范围,从而减少预测误差、提升预测精度.
3 实例验证
为验证所提方法的有效性,本文采用我国华南地区某钢铁集团3#烧结厂数据中心2019 年1 月1 日~2019 年10 月30 日记录的生产数据进行仿真实验.表4 中列出了模型的输入变量,确定输入变量后,依据基于核函数高维映射的多尺度数据配准方法构建了建模的样本集.利用箱线图法剔除了异常值后,获得了800 个样本,其中740 个样本作为训练集,60 个样本作为测试集.为避免输入变量量纲不同导致的建模样本集构建不合理,输入变量归一化到[-1,1]之间.为更好地展示所提模型在动态的烧结过程建模上的优势,DK-ESN、AW-ESN以及ESN 模型被用于与所提模型进行实例比较验证.
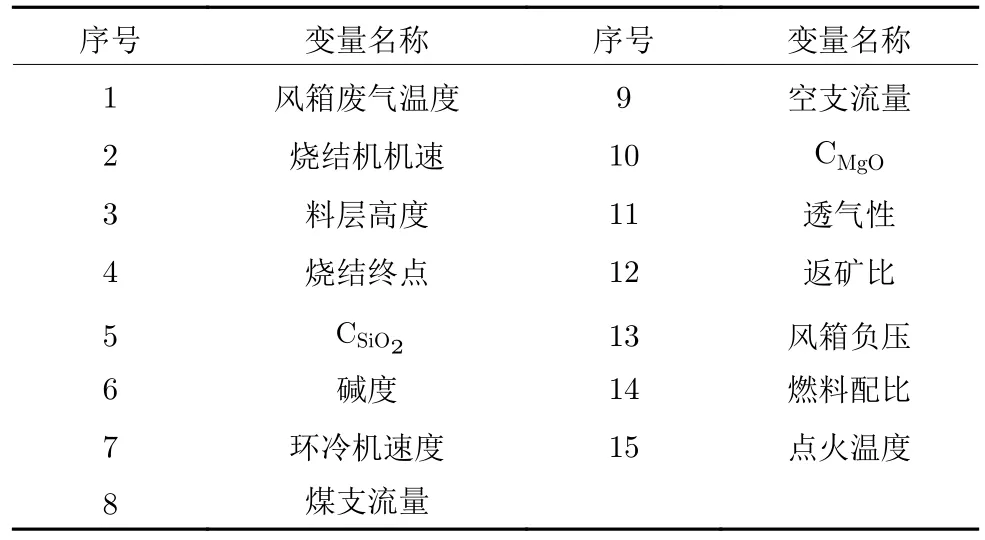
表4 模型输入变量Table 4 The input variables of the model
为更直观地对模型预测性能进行比较,选择多次实验的测试集平均命中率(Hit rate,HR)以及平均绝对误差(Mean absolute error,MAE)、均方根误差(Root mean square error,RMSE)等标准统计指标作为定量评估模型性能的指标.上述指标的计算式为
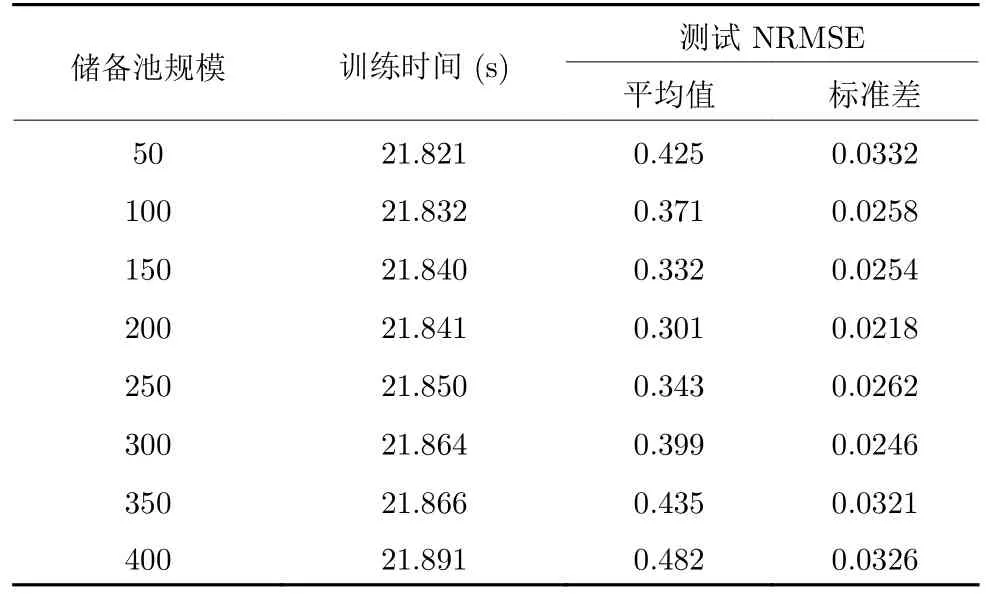
表5 储备池规模对DK-AWESN 性能的影响Table 5 Influence of reservoir size on the performance of DK-AWESN
为提升模型的预测精度,本文提出一种基于梯度的权重调整策略,建立了AW-ESN.为更直观地展示所提AW-ESN 相较于ESN 在FeO 含量预测上的优越性,图6 展示了本文所提出的AW-ESN与ESN 在同一个测试集上的预测结果.从图6中可以看出,AW-ESN 相较于ESN 具有更好的跟踪性能,在工况出现波动时,如12、13、26、27、28样本点,AW-ESN 均能实现较好的预测效果,而ESN 在第27 个样本点处出现了较大的预测误差.虽然当工况出现波动时,AW-ESN 的预测误差相较于工况平稳时也增加了,但是AW-ESN 仍然能够较好地跟踪实测值的变化趋势,展示了更好的预测性能.

图6 ESN 和AW-ESN 预测值与实际值对比Fig.6 Comparison between predicted values and actual values of ESN and AW-ESN
针对数据驱动模型缺乏机理知识致使模型泛化性能差的问题,本文将机理知识融入AW-ESN,提出了DK-AWESN.为验证融入机理知识对模型预测性能的提升,图7 和图8 分别展示了AW-ESN和DK-AWESN、ESN 和DK-ESN 在同一个测试集上的预测结果.从图7 和图8 可以看出,DK-ESN和DK-AWESN 由于融入了基于过程机理划分的FeO 等级知识,能够有效地降低由于工况波动造成的模型预测结果过高或者过低的现象.当FeO 含量偏高或者偏低时,模型预测结果与实测值之间易出现较大偏差,在这种情况下,相较于ESN 和AWESN,DK-ESN 和DK-AWESN 能够将预测结果调整回到正确的范围内,从而减少预测误差、提升预测精度.当工况平稳,预测模型预测效果较好时,融入机理知识也不会对原本的预测效果造成影响,从而保证工况平稳期的预测精度.根据上述分析可知,融入烧结过程机理知识后的数据模型能够在保证工况平稳期模型预测精度的同时,兼顾工况波动期模型预测值跟踪实测值变化趋势的能力,避免出现预测值大幅度偏离实测值的状况,实现模型预测性能的提升.

图7 AW-ESN 和DK-AWESN 预测值与实际值对比Fig.7 Comparison between predicted values and actual values of AW-ESN and DK-AWESN

图8 ESN 和DK-ESN 预测值与实际值对比Fig.8 Comparison between predicted values and actual values of ESN and DK-ESN
通过上述实验结果与分析可知,所提DK-AWESN在FeO 含量预测上展现出良好的预测性能.为进一步比较各模型的预测效果,图9 展示了各模型的预测误差,预测误差越小说明预测性能越好.从图9中可以看出,所提DK-AWESN 的预测误差相较于另外三种方法较小,预测误差的波动也更稳定,说明本文所提方法面对复杂的烧结工况具有更好的泛化性能.当工况波动较大时,所提方法的预测误差也会显著增加,但是相较于其他几种方法,本文所提DK-AWESN 受到过程数据波动的影响更小,预测性能更好.

图9 不同方法的预测误差对比Fig.9 Comparison of prediction errors of different methods
为进一步比较不同模型的预测性能,图10 绘制了不同方法得到的FeO 含量预测值和实测值的散点图.从图10 中可以看出,所提DK-AWESN 的圆形散点的分布更接近对角线,而当预测值和实测相等时,散点会处于对角线上,因此说明所提DKAWESN 模型得到的预测结果与实测值更接近.虽然仍然存在少数点偏离对角线,但与ESN 和AWESN 相比,DK-AWESN 能够较好地跟踪实测值的变化.

图10 不同方法预测值和实测值的散点图Fig.10 Scatter plot of predicted values and measured values by different methods
表6 列出了上述预测模型的预测结果评价指标,从表6 数据可以看出,AW-ESN 和DK-ESN 的预测性能相较于ESN 都有明显的提升,而DKAWESN 的综合预测性能是最好的,相较ESN 而言,在测试集上的预测命中率有较大幅度的提升,达到了86.67%.相较AW-ESN 而言,平均测试命中率提升了8.34%,平均绝对误差降低了0.047,均方根误差减少了0.044.通过以上实验及其分析证明,所提DK-AWESN 方法通过将FeO 等级知识融入AW-ESN 使得预测值的波动区间减小,一定程度上避免了由于缺乏机理认知导致模型泛化能力差的问题.采用所提方法建立的模型的精度和泛化性能相较于另外三种数据驱动模型得到了增强,能够较好地进行实际工程应用.

表6 各模型的预测性能指标比较Table 6 Comparison of prediction performance indicators for different algorithms
4 结束语
本文提出了一种基于知识与AW-ESN 融合(DK-AWESN)的烧结矿FeO 含量预测方法.在所提DK-AWESN 中,过程传热机理和专家经验中提取得到的知识与AW-ESN 相结合,实现了良好的FeO 含量预测性能.工业验证表明,本文所建模型的命中率可达到86.67%,模型预测精度受过程变量波动影响较小,具有较好的泛化能力和建模精度.通过统计分析,利用均方根误差、命中率等统计指标对所提预测模型和其他数据驱动模型的预测精度进行对比.结果表明,所提方法有效提升了模型在复杂工况下的预测精度,能够为烧结现场操作人员提供更可靠的信息,从而提高烧结过程的调控能力和现场操作人员的操作准确率,对实现烧结过程的稳定控制、提升烧结矿质量具有重要作用.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
氯碱工业(2021年6期)2021-12-25
疯狂英语·新读写(2021年8期)2021-11-05
天津医科大学学报(2021年1期)2021-01-26
世界科学技术-中医药现代化(2020年2期)2020-07-25
小学生优秀作文(高年级)(2018年4期)2018-09-11
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
少儿科学周刊·儿童版(2016年1期)2016-03-14
