
基于BERT的电子病历命名实体识别
2024-03-05 08:20郑立瑞肖晓霞邹北骥
计算机与现代化 2024年1期
郑立瑞,肖晓霞,邹北骥,2,刘 彬,周 展
(1.湖南中医药大学信息科学与工程学院,湖南 长沙 410208;2.中南大学计算机学院,湖南 长沙 410083)
0 引 言
命名实体识别是指从复杂的结构化、非结构化和半结构化数据中抽取特定类型实体的识别任务,为文本结构化、关系抽取、文本摘要和机器翻译等自然语言处理任务提供基础支持,是自然语言处理的热点问题[1]。采用命名实体识别技术,可以高效地获取医疗实体、结构化病历,为医疗知识图谱,健康智能问答、智能辅助诊疗、知识订阅等服务提供支持,推动智慧医疗发展。
由于中文词与词之间没有分隔符,命名实体的识别首先需要明确词的边界,这给中文命名实体识别带来困难。中文文本还存在一词多义、多词一义、句子结构复杂、多省略等特点,语句中不同位置的相同词语的词性与词义也可能完全不同,网络的发展和应用的普及也导致表达变得更加随意与灵活,这些都加大了中文实体识别的难度[2]。要提高中文命名实体识别的正确率,需要结合句子的整体语义与语法分析,在正确理解句子语义的基础上,才能更好地根据语法分析划分出正确的实体。本文实验将充分利用中文语义和语法识别电子病历中的命名实体。
1 相关研究
命名实体识别技术主要经历了基于词典与规则的方法、机器学习、深度学习3 个发展阶段[3-4]。由于神经网络强大的特征提取功能,深度学习成为了目前命名实体识别的主流方法。基于词典的实体识别方法是通过与词典中的词进行匹配,匹配成功则识别出实体,因此字典规模的大小直接影响识别率。基于规则的实体识别方法是语言专家根据文本特点人工制造规则来实现实体识别的[5]。这2 种方法使用简单,识别准确率较高,但是词典与规则的建立需要耗费大量的人力物力,且其识别率完全依赖于词典和规则是否构建全面。基于统计的机器学习方法需要根据文本特征选择标注语料,通过对语料的学习来实现命名实体识别。常用机器学习方法有支持向量机(Support Vector Machine,SVM)、最大熵马尔可夫(Maximum Entropy Markov Model,MEMM)、隐马尔可夫(Hidden Markov Model,HMM)、条件随机场(Conditional Random Fields,CRF)。相比基于词典与规则的实体识别技术,基于统计的机器学习方法在一定程度上提高了识别准确率,但依赖于人工选择特征和标注语料的质量。近年来,基于多层神经网络的深度学习(Deep Learning,DL)模型被广泛地应用于命名实体识别任务中。相比于基于统计的机器学习方法,深度学习具有更强的泛化能力,不需要人工选择特征,可通过非线性变换自动获取特征。深度神经网络模型的核心思想是将输入的文本映射成高维度的实数向量,实数向量经过网络的各种变换将单词映射到标签空间,完成分类[6-8]。常见的深度学习模型有循环神经网络(Recurrent Neural Network,RNN)、BILSTM、卷积神经网络(Convolutional Neural Networks,CNN)、空洞卷积(Iterated Dilated CNN,IDCNN)。
2018 年Google AI 提出了Bidirectional Encoder Representations from Transformers(BERT)预训练语言模型[9],该模型以Transformer 为网络架构,可以充分描述字符、词、句子间的关系特征,在多种自然语言处理任务中都取得了优异的成绩。BERT 在大规模未标注语料上进行预训练,在面对各种各样的下游任务时只需要少量的标注语料进行微调就可以取得较好的结果[10]。因此为了解决电子病历的命名实体识别遇到的未登录词和标注数据缺乏等问题,出现了基于BERT 的各种模型。何涛等[11]提出一种结合BERT 与条件随机场的实体识别模型,通过BERT 模型学习字符序列的状态特征,并将得到的序列状态分数输入到条件随机场层,条件随机场层对序列状态转移做出约束优化。梁文桐等[12]提出了一种基于BERT 的医疗电子病历命名实体识别模型。该模型中的BERT 预训练语言模型可以更好地表示电子病历句子中的上下文语义,迭代膨胀卷积神经网络对局部实体的卷积编码,有更好的识别效果。李妮等[13]提出了基于BERT-IDCNN-CRF的中文命名实体识别方法,该方法通过BERT预训练语言模型得到字的上下文表示,再将字向量序列输入IDCNN-CRF模型中进行训练,训练过程中保持BERT 参数不变,只训练IDCNNCRF部分,在保持多义性的同时减少了训练参数。
这些年针对电子病历实体识别,基于BERT 的模型主要以BERT-CRF、BERT-IDCNN-CRF 等为主。BERT-CRF 模型是将BERT 模型与CRF 相结合,用于电子病历中命名实体的识别。其中,BERT 模型用于提取输入文本中的语义特征,CRF用于建立标签之间的依赖关系,并生成最终的标注序列,解决了传统模型无法实现一词多义、特征提取不足的问题[14-15],但由于没有考虑上下文信息,其在处理较复杂的文本序列时存在一定局限性。BERT-IDCNN-CRF 模型是将BERT模型与基于膨胀卷积神经网络(IDCNN)和CRF相结合,用于电子病历中命名实体的识别。其中,BERT 模型用于提取输入文本中的语义特征,IDCNN用于学习输入文本的上下文信息,并进行特征提取和降维处理,CRF 用于建立标签之间的依赖关系,并生成最终的标注序列。该模型考虑了上下文信息,主要优点在于使用IDCNN 进行特征提取和降维处理,能够提高模型的运行效率和准确性[16],但由于采用了IDCNN 网络结构,需要对序列进行卷积操作,会损失一些序列的局部信息。
为了避免IDCNN 损失局部信息并且提高模型的鲁棒性,本文提出一种将BERT 模型与BILSTM 和对抗训练相结合的模型BBCF,用于电子病历中命名实体的识别。
2 BBCF实体识别模型
BBCF 模型由输入层、序列建模层、解码层组成,如图1所示。输入层由预训练模型BERT的编码层构成,输入标注好的句子映射成字向量,FGM 在字向量中加入扰动后输入到Transformer 的Encoder 层后生成上下文特征向量;序列建模层为BILSTM,该层主要进行高维特征抽取;解码层为CRF 算法,用于预测句子的真实标签序列。

图1 BBCF模型
2.1 输入层BERT
BERT 是Google 以无监督的方式利用大量无标注文本训练的语言模型,由Embedding 层和Transformer 的Encoder 组 成。Embedding 层 由Positional Embedding、Sentence Embedding 和Token Embedding构成。其中Positional Embedding 通过加入序列标记的位置信息,使得模型能利用序列的顺序。公式如下:
其中,pos指的是一句话中某个字的位置,小于所有句子中最长的句子长度,i指的是字向量的维度序号,dmodel指的是字的表示维度。
Transformer的Encoder中最主要的思想是自注意力机制代替传统的RNN,使用点积进行相似度计算,来学习句子内部的词依赖关系,捕获句子的内部结构[17]。公式如下:
其中,Q、K、V是对字向量进行3次线性变换得到的字向量矩阵,dk为输入向量的维度。
BERT 设计了Masked Language Model 和Next Sentence Prediction 来预训练模型。Masked Language Model:随机遮盖或替换一句话里面的任意字或词,然后模型根据上下文来预测。Next Sentence Prediction:将2 个句子放在一起,模型根据原文预测这2句是否是前后相邻的2句。
2.2 序列建模层BILSTM
将BERT 层得到的字向量X输入到BILSTM,通过遗忘门、输入门和输出门对上下文信息进行双向的高维特征抽取。经过LSTM 模型输出得到的是能够表示单词上下文信息的向量。BILSTM 由双向的LSTM构成,LSTM通过3个门结构解决了RNN长期依赖的问题[18]。
遗忘门选择性遗忘掉一些信息:
输入门加入新的信息:
更新当前状态:
输出门输出确定输出的部分:
其中,ht-1为t-1 时刻文本的隐状态;σ为Sigmoid 激活函数;b为偏置向量;tanh 为双曲正切函数;W为模型参数矩阵[18],·表示2 个向量的点乘,*表示2 个向量的叉乘。
2.3 解码层CRF
由BILSTM 层得到的结果ht还需要输入CRF 层进行解码。CRF 可以学到句子的约束条件(例如Bbody标签后面应该是Ibody而不是Isymp),通过这些约束条件来保证最终预测结果是有效的[19]。所有标签的组合构成了路径的总和,需要从中找到得分最高的路径,即标签间的约束条件。每条路径的分数由公式(10)计算,其中Ayi,yi+1为转移分数矩阵,它是模型的一个参数,随着训练的迭代而更新;Ai,yi为发射分数矩阵,它是BILSTM 层的输出ht[20];X为观测序列,其值为{x1,x2,···,xn},是BERT-BILSTM-CRF 模 型 的 输入;预 测 序 列 标 签y=ht={y1,y2,···,yn},即BILSTM 层的输出ht。路径分数score(X,y)的最大值对应的标签路径即为最终的输出,根据标签就可以输出各类命名实体。
2.4 对抗训练
对抗训练(Fast Gradient Method,FGM)的思想主要是在梯度上升的方向找到使损失最大的扰动,然后与原样本相加得到对抗样本。对抗样本相对于原样本,所添加的扰动是微小的,但能使模型犯错。将生成的对抗样本加入到训练集中去,可增强模型对易犯错样本的识别率,从而提升模型的泛化能力。
1)计算X的前向loss,反向传播得到梯度g:
其中,J(θ,x,y)是模型的损失函数,θ是网络参数,x是输入,y是标签。
2)根据Embedding 矩阵的梯度g计算出r,并加到当前Embedding上,相当于X+r,其中:
其中,ε表示叠加在输入上的扰动。
3)计算X+r的前向loss,反向传播得到对抗的梯度,累加到公式(11)的梯度上。
4)将Embedding恢复为步骤1时的值。
5)根据步骤3的梯度对参数进行更新[21]。
3 实验与结果分析
本文实验采用的操作系统为Win10,Pytorch 版本为1.4.0,Python 版 本 为3.6;GPU 版 本 为NVIDIA 1650Ti,显 存 容 量 为4 GB,CPU 为AMD Ryzen7 4800H,系统内存为16 GB。
3.1 数据来源及处理
数据集来自CCKS2017 测评任务提供的已标注的脱敏中文电子病历,但其中存在大量标注不统一、漏标以及标注错误等问题。针对这一问题,实验时采用手工纠正,统一了数据集中字母大小写与中英文标点符号等。在保证语义相对完整的前提下,将句子切分到380 个字符以内,作为输入。数据预处理后,训练集与测试集中实体类型与实体数量见表1。

表1 实体类型与实体数量
CCKS2017 中文电子病历中的每一个字符采用BIO 标签进行标注,实体开始的第一个字符用“B”标注,实体中除首字符外其他实体字符用“I”标注,非实体的每个字符都用“O”标注[22]。实验中有5 种实体类型,因此每个字符有11 种标注可能性。部分标注样例如表2所示。

表2 数据标注示例
3.2 模型参数设置
实验中的BERT 模型采用谷歌发布的BERT_BASE 模型,该模型嵌入层尺寸为512,隐藏层共12层,隐藏层维度为768,采用12头注意力模式,并使用Gelu 激活函数。BERT-BILSTM-CRF 模型训练参数设置如表3所示。
表3 超参数
3.3 实验结果与分析
为了了解BERT-BILSTM-CRF 模型在中文电子病历上命名实体识别的效果,还在CCKS2017 中文电子病历语料上做了以下2 种模型的实验:1)BERTIDCNN-CRF 模型,模型使用预训练模型BERT 提取语义表征,输入到IDCNN 层进行编码,采用CRF 模型计算最佳实体识别路径进行预测[23-24];2)BILSTMCRF 模型,该模型使用Word2Vec 词嵌入作为文本的输入表示,输入到BILSTM 层进行编码,采用CRF 模型计算最佳实体识别路径进行预测[25-26]。
中文病历命名实体识别模型评价指标采用精确率P、召回率R和F1 值,其中F1 值是精确率和召回率的一个平衡,因此命名实体识别的效果主要以F1 值为准[27]。图2 为实验中3 种模型随迭代次数epoch 值增加而变化的结果。从图2 可见3 种模型的F1 值都随epoch 值的增加而逐渐趋于平稳状态;BERTBILSTM-CRF 模 型 相 比 于BERT-IDCNN-CRF 和BILSTM-CRF 收敛得更快、更好,并且训练过程中F1值的波动更小,说明BERT-BILSTM-CRF 模型在收敛速度上最优;BERT-BILSTM-CRF 模型和BERTIDCNN-CRF 模型无论在收敛速度还是在F1 值上都明显优于BILSTM-CRF 模型,说明BERT 提供的词向量相比Word2Vec保留了文本更深的语义信息。

图2 不同模型的F1值对比
实验中对CCKS2017 中文病历语料中的身体部位(body)、查体结果(check)、症状(symp)、治疗(cure)和疾病名称(dise)这5类实体进行识别,其结果如表4所 示。由 表4 可 见,BERT-BILSTM-CRF、BERTIDCNN-CRF 和BILSTM-CRF 整 体的F1 值分 别为92.69%、92.49%、82.60%。其中以BERT 为基础模型的F1 值远高于以Word2Vec 提供词向量的BILSTMCRF,说明BERT能够提供更准确的语义信息,更好地捕捉前后文的语义;IDCNN 通过空洞可以增加模型的感受视野,捕获全局特征,识别效果也不错。BERT-BILSTM-CRF 的F1 值又略优于BERTIDCNN-CRF,BERT 主要是通过Position Embedding的方式比较简单粗暴地编码位置信息,能否捕捉到连续的顺序信息是存疑的。BILSTM 可以对输入序列进行顺序建模,可以很好地捕捉到连续文本的顺序信息,实体在文本中都是顺序出现的,是连续的,这种连续的顺序信息可以很好地帮助识别实体。而且BERT-BILSTM-CRF 的动态词向量表示还可以识别一词多义,具有强大的信息记忆与抽取能力,能够更好地抽取上下文的文本信息。
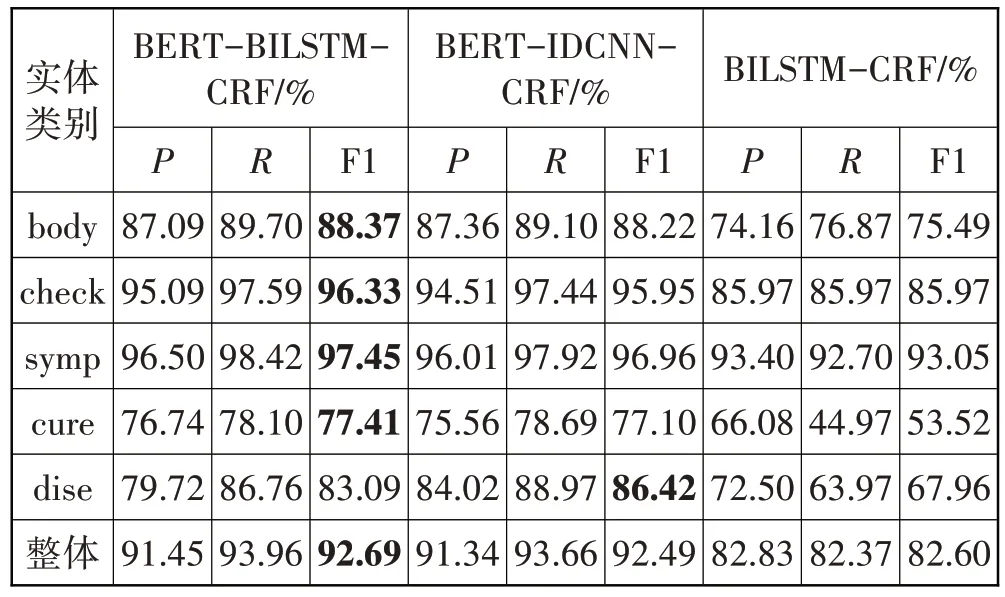
表4 各种实体识别的准确率、召回率和F1值
BERT-BILSTM-CRF 模型中不同类别实体的F1值差距也较大,其中symp 实体的F1 值最大,为97.45%;cure 实体的F1 值最小,为77.41%。由表1 可知,训练集中symp 实体的数量为12821,cure 实体的数量为4940,symp实体的训练样本是cure实体的2倍多,这导致cure 实体的F1 值较低。另外从语料分析发现cure 类型的实体一般长度较长,专有名词较多,如奥扎格雷钠注射液、头孢哌酮舒巴坦钠等,导致BERT-BILSTM-CRF模型难以识别这类实体。
为了观察对抗训练对模型的增益,移除了对抗训练的模块,实验结果如表5 所示。有对抗训练模块的模型比没有的模型在各类实体上的F1 值均有所提高,整体的F1值提高了0.15个百分点,说明对抗训练通过生成对抗样本,确实能提高模型的泛化能力。

表5 消融实验的准确率、召回率和F1值
4 结束语
在电子病历的命名实体识别任务中,相比于其他传统模型,BERT-BILSTM-CRF 模型能在较少的训练轮数下达到更好的收敛,可以节约训练成本,快速部署应用,但在识别准确率方面仍有较大提升空间。加入对抗训练模块能增强模型的泛化能力,提高识别率。针对实体长度较长且多为专有名词的语料,可以考虑建立专有名词的词表来提高识别率。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
数学小灵通·3-4年级(2020年9期)2020-10-27
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
海外华文教育(2016年1期)2017-01-20
中国卫生(2016年10期)2016-11-13
当代教育理论与实践(2015年9期)2015-12-16
中国卫生(2015年10期)2015-11-10
民族古籍研究(2014年0期)2014-10-27
