
基于BERT算法的通信投诉智能处理探索
2024-03-12 05:34蒋燕程浩辉何丹
广东通信技术 2024年2期
[蒋燕 程浩辉 何丹]
1 引言
随着5G网络普及发展,通信网络架构日趋复杂化,通信业务种类也越来越丰富;同时,随着各种即时通信、视频和游戏等实时性要求高的应用的普及,用户对通信网络的质量要求越来越高,运营商面临的投诉种类也变得多样化。传统通过人工进行投诉预处理和分拣的处理方式,难以适应问题多样化、诉求复杂化的业务场景及发展趋势的要求。因此,结合大数据、机器学习等技术,通过智能算法实现投诉的智能分类和处理对提升通信投诉处理效率、增加网络用户满意度有着重大意义。
通信运营商正逐步实现数字化转型、ICT转型[1],通信投诉处理智能化是大势所趋[2~4]。目前,针对大数据或机器学习算法在投诉处理领域应用,已有不少研究与探索,探讨了大数据挖掘、机器学习算法在投诉预测、分析等方面的可行性[5~10]。文献[5]提出了基于用户画像的标签体系,利用机器学习分类算法反复迭代实现投诉问题自动和智能化的定界和定位。文献[7]利用机器学习中的相关性分析技术,建立客户投诉与故障发生的关系模型,构建基于故障的投诉预测模型,对潜在的客户投诉进行预测。文献[8]提出了一种基于深度学习的用户投诉预测模型。通过深层网络特征学习单元从电信用户原始数据中自动学习到适合分类器分类的高层非线性组合特征,并将这些高层特征输入到传统分类器中来提高模型的精度。文献[10]建立了一种基于大数据技术的投诉分析与预测系统,基于底层信令的全量分析,可有效定位故障原因,实施基于历史投诉样本库的投诉预测,并提前进行干预。
本文结合投诉处理流程,针对在短时间内难以根据大量投诉描述文字进行准确分类及派发的痛点,提出了一种基于BERT的通信投诉智能处理方法。该方法针对投诉描述为非结构化长文本的特性,通过数据标注、模型训练,形成针对投诉文本识别及分类的BERT模型,将该模型应用于投诉受理及调度流程,通过模型输出结果实现投诉智能分类、智能流转,达到提升通信投诉处理效率的效果。
2 基于BERT的投诉智能处理
2.1 BERT 算法
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型,它采用新的掩盖语言模型MLM(masked language model)训练策略,通过无需标注的数据预训练模型,提取语句的双向上下文特征,在具体任务上根据具体数据微调学习,就能获得极好的效果[11]。
BERT采用迁移学习(Transfer Learning)模式,上游进行语言模型的预训练,下游微调并应用到具体业务中。在架构上,大量使用迁移模型Transformer编码器堆叠而成[12],如图1所示。
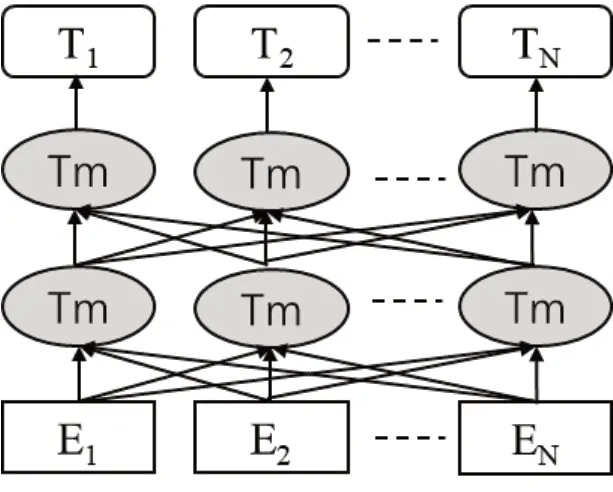
图1 BERT算法模型架构
图1中,嵌入层E提取文本词向量、段向量和位置向量三个维度的特征进入编码层,Transformer编码器Tm基于双向 Transformer 的特殊结构和自注意力(self-attention)机制,学习上下文的语义信息。
BERT 基于独特的训练策略来得到预训练模型:掩盖预测MLM和下句预测NSP(next sentence prediction)。掩盖预测训练随机遮蔽部分词,通过未遮蔽掉的词提供上下文来预测,使BERT对上下文有着更深刻的感知。下句预测通过训练使模型学习语序,理解语句间的逻辑关系,使模型能够预测句子间在顺序上是否有逻辑关系。通过这样的训练,模型不仅能学习句内信息,还能清楚地捕捉到句间逻辑,这种独特的学习模式使其在问答系统、阅读理解等问题上有出色的发挥。
2.2 基于BERT的投诉智能处理方法
通信投诉类别主要包括上网类、语音类、短信类、国际漫游类、家庭宽带类以及集团客户类等,种类多、投诉单量大、投诉描述复杂等因素均制约着人工分类的准确性,分类不准确则影响投诉的准确定界和工单准确下达。通过BERT算法对投诉工单内容实现文本语义识别及智能分类,能够智能快速对投诉进行分类,进而实现投诉工单智能定界及流转,主要实现方法如图2所示。

图2 基于BERT算法的投诉智能处理方法
工单系统调用基于BERT的智能处理AI服务,输入投诉描述信息(非结构化长文本),AI服务基于BERT算法通过实体识别、关键语句提取、短文本分类3种下游调度任务实现投诉关键信息提取及智能分类,将算法输出结果返回工单系统。工单系统根据AI服务返回结果,调用投诉定界系统执行相应类别的定界预案,获取预案输出结果。最后,工单系统将无法远程解决的投诉工单,根据投诉类别、升级投诉意向等信息派发相应责任单位处理。
2.3 基于BERT的投诉智能处理AI服务
投诉智能处理AI服务通过分别构建相应的BERT模型完成实体识别、关键语句提取、短文本分类任务,解决非机构化长文本直接分类训练样本数量级要求高、分类准确率低的难题,完成结构化关键信息提取、智能分类的目的。具体实现过程如图3所示。

图3 基于BERT的智能处理AI服务实现
图3中,实体识别BERT模型主要实现从投诉文本中识别投诉地址等信息。关键语句提取BERT模型主要实现从非结构化投诉长文本中提取关键语句内容,关键语句包括用户的投诉问题、升级投诉意向等。最后,短文本分类BERT模型实现对关键语句提取任务的输出结果进行智能分类,输出投诉类别的判定结果,三部分下游任务的输出形成AI服务的输出结果,如图4所示。

图4 基于BERT算法的投诉智能处理AI服务输出示例
BERT模型构建基于BERT-based-chinese 进行数据标注、模型训练、参数调优等步骤构建。实体识别BERT模型通过标注地址数据训练、构建;关键语句提取BERT模型以投诉问题为例,采用问答模式进行关键语句数据标注,通过提取不同类别业务异常相关问题对进行训练实现。短文本分类BERT模型通过将关键语句标注投诉分类形成训练数据构建实现。
数据标注数量级使用千条级别,各部分的数据标注样例如图5所示。

图5 各下游任务BERT模型数据标注样例
模型训练采用pytorch框架实现,模型训练过程如图6所示。
本文中AI服务算法模型采用Flask框架部署,构建的BERT模型包括3层:编码层(Encoding Layer)让机器分别阅读问题和文档,使用编码器对问题和文档的每个词进行建模,得到每个单词的向量表示;匹配层(Matching Layer)利用注意力机制,将问题中的词汇与文章中的词汇进行匹配,从而筛选出能够有效回答问题的信息;预测层(Prediction Layer)在问题和文档匹配信息融合的基础上,利用PointerNetwork找出最可能的答案开始和结束位置。3层模型如图7所示。
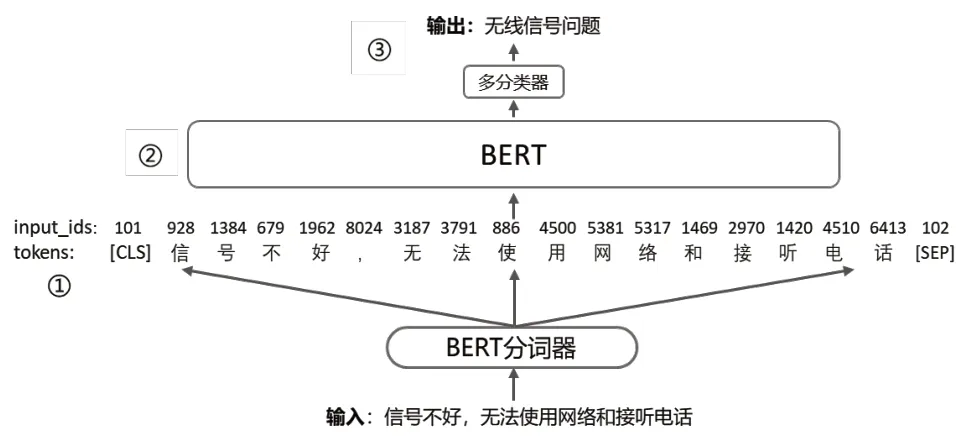
图7 BERT应用于投诉分类的三层模型
3 实验结果与分析
3.1 实验环境
本文的实验环境:操作系统为CentOS 7;CPU为Intel(R) Xeon(R) Gold 5118 CPU @ 2.30GHz;
GPU为NVIDIA V100单卡;内存为32G;Python版本为3.6.5;PyTorch版本为1.6.0。
3.2 实验数据
本文实验数据均为实际用户投诉文本数据,模型训练数据共计950条,模型验证数据7万条。依据前文所述数据处理方式,对训练数据进行地址数据标注、问答关键信息标注、分类标注,实现不同类别业务异常相关问题的实时分类。实验数据集统计如表1所示。
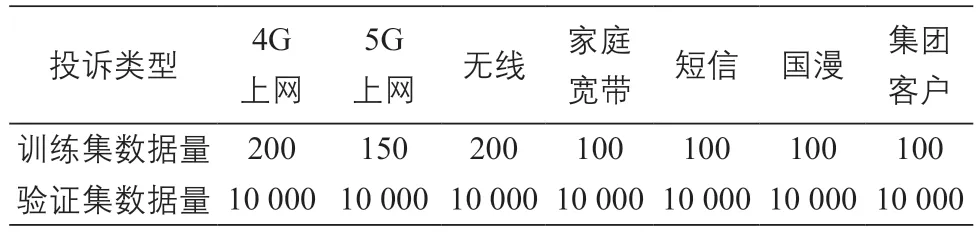
表1 各类投诉数据集
3.3 实验结果
本文采用预训练加下游任务微调模式,对标注和训练数据要求较少、对训练资源和轮次要求较少,仅需2~4轮即可达到较好效果。
在训练样本数量级不超千条、训练轮次为4次的条件下,投诉智能分类准确率能达到90%以上,且投诉分类可在1秒内自动完成。各类投诉智能分类准确率如表2所示。

表2 各类投诉智能分类准确率
通过系统实际运行,该方法能有效提升投诉分类准确性、提升投诉处理效率。相比该方案部署前,解决人工分类效率低、准确率不高的问题,投诉分类准确率从原来人工分类的50%提升至90%以上;解决投诉工单分类不准无法准确直达处理单位问题,大幅减少工单流转及处理时长,投诉工单处理耗时从原来人工处理、流转的30分钟/单下降到5分钟/单;通过智能提取升级投诉意向,提高相关投诉工单处理优先级,提升用户满意度。
4 总结
本文针对通信投诉处理流程中人工难以在短时间内根据大量投诉描述文字进行投诉准确分类及投诉工单准确派发的痛点,提出了一种基于BERT的通信投诉智能处理方法。该方法运用BERT模型完成投诉关键信息识别和智能分类,实现投诉智能定界和工单准确派送,能有效提升投诉分类准确性、提升投诉处理效率,同时自动识别有升级意向投诉提升处理优先级。
本文基于BERT的智能投诉处理方法对标注数据数量要求较少、对训练资源和轮次要求较少,具有一定的推广意义,但算法在标注数据方法及分类准确率提升上仍存在不少可优化之处,接下来将进一步研究提升。
猜你喜欢
中老年保健(2022年1期)2022-08-17
电子测试(2022年7期)2022-04-22
高技术通讯(2021年6期)2021-07-28
中学生数理化(高中版.高考理化)(2021年6期)2021-07-28
新世纪智能(语文备考)(2020年4期)2020-07-25
中国核电(2017年1期)2017-05-17
中国科技信息(2015年23期)2015-11-07
语文知识(2014年4期)2014-02-28
中国商人(2013年1期)2013-12-04
中国商人(2013年1期)2013-12-04
