
地学知识图谱引导的遥感影像语义分割
2024-03-20 01:09李彦胜武康欧阳松杨坤李和平张永军
遥感学报 2024年2期
李彦胜,武康,欧阳松,杨坤,李和平,张永军
1.武汉大学 遥感信息工程学院,武汉 430079;
2.贵州省基础地理信息中心,贵阳 550004;
3.贵州省第一测绘院,贵阳 550025
1 引言
遥感影像语义分割作为地学信息解译的基础性工作,广泛地应用于土地覆盖制图、自然环境保护、灾害应急监测、城市空间规划等领域,具有重要的应用价值(Ma等,2019)。遥感影像是地表三维世界经过大气传输到达传感器的映射,包含了丰富的地物光谱、目标形状特征和地理空间关系等信息。人类领域专家在语义分割过程中,往往需要综合考虑目标语义信息和地学先验知识才能够有效克服遥感影像的“同谱异物、同物异谱”问题,从而取得理想的分割结果(Zhu等,2017)。
传统的图像语义分割方法包括最大似然法(MLE)、随机森林(RF)、决策树(DT)、支持向量机(SVM)等基于浅层特征判别的监督分类方法(Camps-Valls 等,2014;李楠 等,2018)。这类方法一般先根据人工设计的特征描述子提取图像的光谱、纹理和几何结构特征,然后进行特征分类(肖春姣 等,2020)。传统分割方法高度依赖于人工设计特征,难以跨越底层图像数据与高层逻辑信息的语义鸿沟,其鲁棒性和精度较差。随着人工智能理论与技术的快速发展,深度学习方法广泛运用到了遥感图像处理任务中(Li 等,2018,2020,2021a)。基于深度学习的语义分割方法包括全卷积网络(FCN)、U型网络(U-Net)、分割网络(SegNet)、掩模区域卷积网络(Mask R-CNN)、深度分割网络(DeepLab)、分割Transformer(SegFormer)、多视野融合网络(MFV-Net)、PID网络(PIDNet)等深度语义分割网络方法(Long等,2015;Ronneberger 等,2015;Badrinarayanan等,2017;Zhao 等,2017;He 等,2018;Chen等,2018;Xie 等,2021;Li 等,2023;Xu 等,2023)。深度语义分割网络通过端到端的学习机制对特征提取与特征分类一体化模型自动学习,从而自适应完成分割工作,使得分割的准确度大幅提高、分割的过程也更加智能化。然而,深度学习是基于像素的数据驱动方法,通过降低在每个像素上的损失来反向优化网络模型,缺乏实体级别的学习,不能有效提取出目标形状特征,使得分割结果整体性缺失、边界模糊和随机噪声分布明显,同时受制于结构化数据驱动方法的缺陷,往往难以利用地学先验知识和实体间丰富的语义信息(如空间关系)(Liu 等,2020),导致可解释性差。以上两点不足严重制约着深度语义分割网络性能,亟需在分割过程中从实体尺度出发,综合考虑地学先验知识和实体间语义信息。
先验知识和语义信息是对规则或事实的抽象化表达,难以形式化建模。为充分利用先验知识,国内外专家学者探索了诸多方法,如辅助通道嵌入、物理模型建模、迁移学习等。辅助通道嵌入方法(Wu 等,2021)通过将领域知识作为辅助的输入通道参与网络训练测试从而进行知识嵌入。物理模型建模方法(Xu 等,2022;Li 等,2022)将物理知识融入损失函数和模型结构中来利用先验知识。迁移学习方法(Dash 等,2022;李发森等,2022;欧阳淑冰 等,2022)通过预训练等方式将领域先验知识耦合网络模型中。然而这些方法大多只考虑到特定场景下的先验知识的入,对语义信息的利用程度不够。在此背景下,遥感科学应该得到本体论、知识图谱等知识表示技术的支持。本体(Ontology)(Arvor 等,2019)作为对特定领域中概念及其相互关系的形式化表达,具有很强的知识表示能力、基于认知语义学的推理能力和共享知识的能力。地学知识图谱作为语义网络,描述了地物目标的属性以及目标之间的关系,相较于其他建模方式,能够更好的捕捉实体之间的语义关联和复杂的关系模式,有助于更好地理解和推理知识,适用于地学知识的结构化表达。其中,地学本体是地学知识图谱的骨架,地物目标作为本体的实例化对象组成了地学知识图谱的基本单元。地学知识图谱的发展经历了专家智能解译系统(Goodenough 等,1987)、地学信息图谱(张洪岩 等,2020)、地理知识图谱(Hogan等,2022)3 个阶段。传统的专家智能解译系统通过知识的规则化模仿专家的决策过程,针对性强,但适用范围小,解译精度有限;地学信息图谱是一种借鉴图谱思想构建的地球信息科学理论,系统化和抽象化地表达了地学知识,但由于面向的是整个地学领域,并不能直接用于遥感影像解译;地理知识图谱则是将当前的知识图谱理论引入到了地理科学领域,完成了地学知识的结构化表达和推理。现有遥感影像解译方法缺乏地学知识的嵌入,导致解译的可解释性和可靠性受限,这使得地学知识图谱驱动下的遥感影像智能解译具有广阔的应用前景(王志华 等,2021;李彦胜和张永军,2022;张永军 等,2023)。通过引入地学知识图谱,从中抽取符号化的地学先验知识和语义信息,并借助知识推理以完成遥感影像解译,从而提高解译结果的准确度和可解释性。在已有工作中,建筑物本体模型(Gui 等,2016)用于从SAR 影像中提取建筑物,地学知识图谱推理(Gu等,2017)被用于基于目标的高分辨率遥感影像语义分类方法,旨在挖掘利用地学知识图谱推理理论对遥感影像解译的优势。地学知识图谱嵌入方法(吴瑞 等,2022)被用于高光谱解混领域,通过先验知识来进一步提高端元选择的可靠性,从而提升解混的精度。地学知识图谱推理增强了分类结果的可解释性和可信度,但是相比于深度学习方法,其分类精度较差(Li 等,2021b)。联合深度学习与知识推理是协调数据驱动方法与知识驱动方法的重要途径(Arvor 等,2019;Li 等,2022)。在该类工作中,Alirezaie等(2019)实现了本体推理器与深度神经网络分类器在输入和输出端的交互。耦合深度语义分割网络和图卷积神经网络的遥感影像语义分割方法DSSN-GCN(Ouyang和Li,2021)借助图卷积神经网络对节点依赖关系的强大建模能力,在深度语义分割网络的特征提取的基础上引入了地物目标空间拓扑关系,从而预先将空间拓扑先验知识嵌入到了网络中,有效提高了网络的性能。虽然遥感领域已有研究引入知识来推动遥感影像解译技术(范菁 等,2017),但仍没有具体工作来探讨如何将地学知识图谱来引导优化深度网络。鉴于结构化数据和非结构化知识之间的鸿沟,如何将地学知识嵌入深度语义分割网络中以自主引导网络训练仍极具挑战性。
基于上述分析,为在深度语义分割网络分割过程中实现实体级特征自主学习以及充分利用空间语义信息与地学先验知识,本文提出了地学知识图谱引导的遥感影像深度语义分割方法,使用从地学知识图谱中抽取得到的地物目标语义信息和地学先验知识来构建实体级连通约束和实体间共生约束,从而自主引导深度语义分割网络训练。实体级连通约束通过对分割结果的实体级约束,保证了分割结果的整体性。实体间共生约束通过量化共生先验知识,实现将非结构化的知识嵌入到数据驱动的深度语义分割网络中。验证结果表明,本文提出的地学知识图谱引导的深度语义分割方法明显优于已有深度语义分割方法。
2 理论与方法
本文提出方法的总体流程图如图1。主要包括地学知识图谱构建与遥感解译先验知识提取模块、地学知识图谱引导的损失约束模块以及深度语义分割网络优化模块。地学知识图谱构建与遥感解译先验知识提取模块首先利用地学本体定义抽象类和属性关系,再从数据集标签影像中抽取实体及其属性以实例化本体类,从而完成地学知识图谱构建,最后从图谱中提取空间共生先验知识。地学知识图谱引导的损失约束模块包括常规的像素级稠密约束、实体级连通约束和实体间共生约束。数据集中的标签包含大量的连通域,这些连通域是地物目标的分割结果,连通域之间的空间共生分布是领域分类知识的体现。空间共生等地学先验知识可以根据连通域的空间分布进行抽取。实体级连通约束和实体间共生约束均以连通域为处理单元,前者计算每一个连通域单元而不是像素的损失,以实现对实体的整体性约束;后者借助空间共生先验知识完成邻域实体对中心实体的打分,该分值代表中心实体在当前邻域空间分布下所属类别的置信度,再根据分值计算损失,从而实现对实体空间分布的约束。深度语义分割网络优化模块负责网络的训练和图像的语义分割。本文提出方法是一种地学知识图谱引导的遥感影像深度语义分割方法,深度语义分割网络优化模块作为其中一部分,并不局限于特定的结构,可基于不同的深度语义分割网络构建。为了验证方法的通用性,本研究将地学知识图谱引导的深度语义分割方法作用在U-Net 和DeepLab V3+这2 种常见的网络中。深度语义分割网络通过优化加入约束的综合损失来调整网络模型,从而学习到实体级特征表示和利用空间共生知识引导分割。
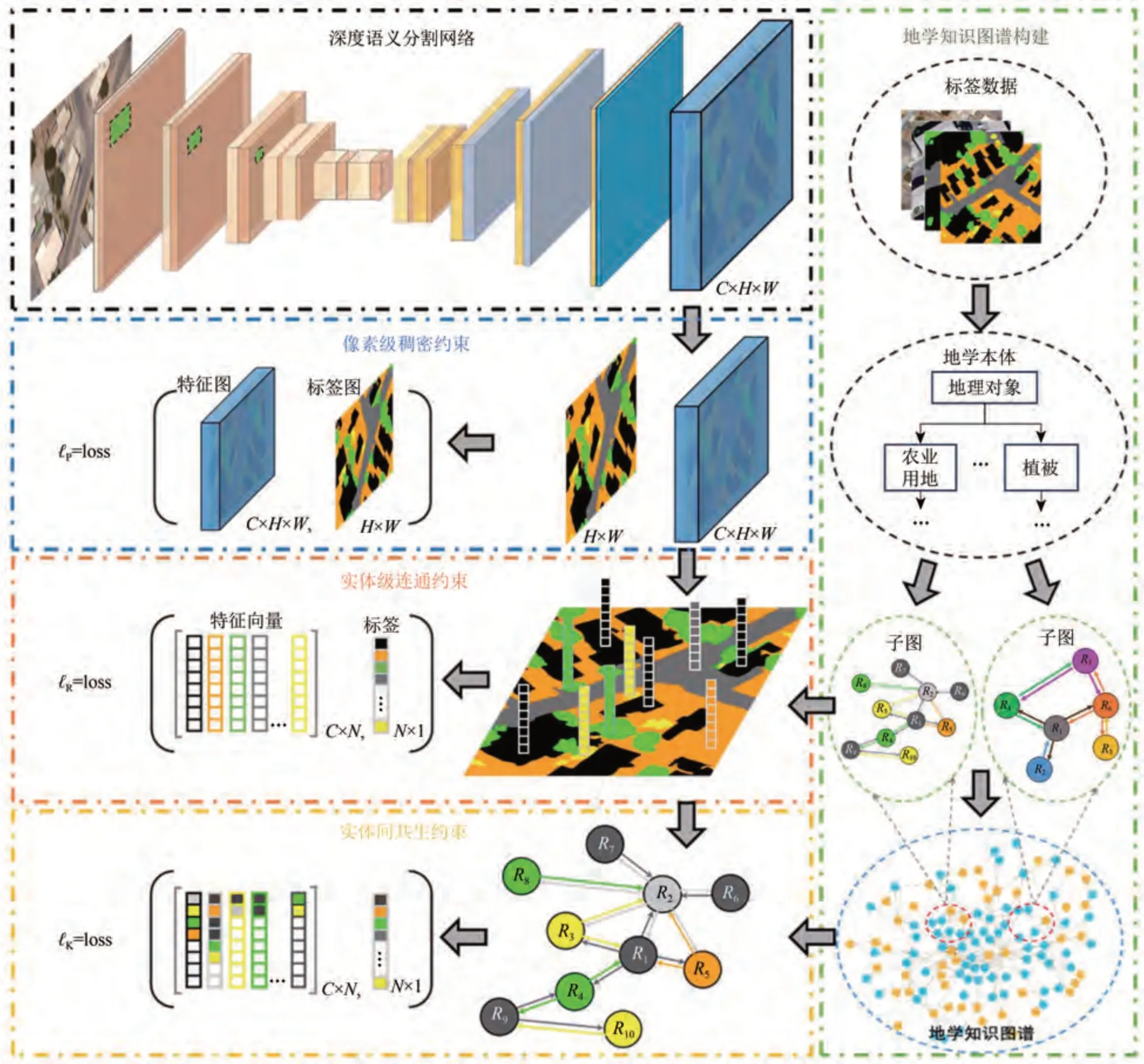
图1 本文提出方法的总体流程图Fig.1 The workflow of the proposed method
2.1 地学知识图谱构建及遥感解译先验知识提取
2.1.1 地学知识图谱构建
地学知识图谱建立在地学本体的基础上,通过实例化本体完成构建。地学本体的引入可将地学知识符号化,有助于提高知识的自主化运用水平。为建立地学本体,本文使用网络本体语言OWL(Web OntologyLanguage)描述本体。地学本体的层次结构如图2 所示。可见地物对象类(rs:GeoObject)为根类,其余子类从中衍生:一级子类主要包括水体(rs:Water)、植被(rs:Vegetation)、透水地面(rs:Ground)、农业用地(rs:Agriculturaland)、城镇用地(rs:Urbanland)、交通工具(rs:Vehicle)和其他(rs:Unknown);二级子类在一级子类的基础上细分为湖泊(rs:Lake)、河流(rs:River)、海洋(rs:Sea)、草地(rs:Grass)、树木(rs:Tree)、裸地(rs:Bareland),荒地(rs:Wasteland)、耕地(rs:Farmland)、牧场(rs:Rangeland)、建筑物(rs:Building)、道路(rs:Pavement)、车辆(rs:Car)、船只(rs:Ship)、飞机(rs:Airplane)。属性关系是本体类间或实体间联系的语义桥梁,地学本体的核心属性主要包括从属(oc:isA)等上下层属性,相邻(geo:adjacentTo)、环绕(geo:surroundedBy)、方位(geo:hasDirectionOf)等空间关系属性以及多数类(geo:MaxClass)等统计属性。图2 中上下层属性描述了实体间的从属关系,比如:“耕地”是“农业用地”,因此“耕地”和“农业用地”之间就包含上下层属性;空间关系属性描述了实体间的空间关系,“道路”环绕“车辆”,因此“车辆”和“道路”之间就包含环绕的空间关系属性;统计属性描述实体间的统计性质和特征,如某个类别在知识图谱中出现的频率等统计属性。地学本体是地学知识图谱的骨架,而实体作为本体类的实例化对象,组成了地学知识图谱的基本单元(图2)。

图2 地学本体层次结构Fig.2 The hierarchy of the geographic ontology
2.1.2 遥感解译先验知识提取
数据集的标签影像包含大量的地物目标信息,包括类别、空间分布等信息。地物目标的空间分布是地学先验知识的体现,因此可以从标签影像上地物目标的空间分布中抽取空间共生关系等先验知识。一般来说,超像素可以作为目标单元,因为受超像素分割算法的约束,影像中每个超像素是由一系列同质的像素组成的,同时超像素具有一致的形状大小,意味着形状较大的地物目标可以分割出更多的超像素,那么在获取目标单元的条件共生概率等统计属性时能够将地物目标的尺寸也一并考虑进来。鉴于地物目标尺寸信息的重要性,本文以原始影像超像素分割块对应于标签影像的区域作为本体类的实体。利用标签影像中的超像素(实体)实例化本体类,超像素中具有多数像素的地物类别作为对应实体的本体类类别,也即实体的多数类geo:MaxClass 属性。超像素的空间关系属性和统计属性作为实体的属性。若实体obj1和obj2在空间上存在公共边,则两者具有相邻属性,以三元组(obj1geo:adjacentTo obj2)表示。同理可得其他属性关系。本体类的空间共生属性是一种地学先验知识,可由统计概率表达,具体做法是在邻域内统计不同本体类实体出现的条件概率。以本体类Ci、Cj为例,统计地学知识图谱中所属Ci的实体出现的概率P(Ci),以及出现与该实体相邻的类别为Cj的实体的概率P(Ci,Cj),再根据下式即可计算出在本体类Ci实体出现的条件下邻域内出现本体类Cj实体的概率P(Cj|Ci),称P为共生条件概率。
以类别Cbuilding建筑类为例,首先统计出地学知识图谱中出现建筑类的实体的概率P(Cbuilding)以及邻域内同时出现类别为建筑类和Cpavement道路类实体的概率P(Cbuilding,Cpavement),再根据式(1)即可计算出在建筑类实体出现的条件下邻域内出现道路类实体的概率P(Cpavement|Cbuilding)。
2.2 地学知识图谱引导的深度语义分割网络优化目标函数
从遥感领域知识图谱中抽取目标实体关系知识用于自主引导深度语义分割网络训练。引导方法主要包括实体级连通约束和实体间共生约束,约束构建以标签连通域为实体。实体级连通约束以实体而不是像素为单元计算损失,实现对实体的整体性约束。实体间共生约束通过实体间空间共生知识将非结构化的地学先验知识嵌入到数据驱动的神经网络中以约束分割目标的空间分布。深度语义分割网络通过优化总体目标函数来完成遥感领域知识图谱的嵌入。深度语义分割网络的总体优化目标函数L 包括像素级稠密约束的常规损失项ℓP、实体级连通约束损失项ℓR和实体间共生约束损失项ℓK,具体计算公式如下:
式中,α和β为常数,用于调节ℓR和ℓK在总体损失中所占的比例。
2.2.1 像素级稠密约束
深度语义分割网络输出的分类置信度图F∈RC×H×W及其标签 影像Y∈RH×W计算像素级稠密损失,像素级稠密约束的常规损失项ℓP定义为
式中,F=ϕ(I,Wθ),ϕ(·)既 代表深度语义分割网络的层次化映射函数,也代表深度语义分割网络模型,I为输入图像,Wθ为深度语义分割网络的参数。C、H和W分别为图像的类别数、高度和宽度。
2.2.2 实体级连通约束
图像原始数据I输入深度语义分割网络,输出分类置信度图F∈RC×H×W,对F按通道取最大值的序号即得到分割结果。实体级连通约束损失ℓR以标签中连通域为单元进行计算,首先在分类置信度图F上对Si(1 ≤i≤N)实体区域内所有像素Pj(Pj∈Si)的分类置信度向量D按通道计算均值,得到具有通道维数C的向量,这个向量作为该实体的分类置信度向量;然后根据实体的分类置信度向量和真实类别Yi计算损失;最后取所有实体损失项的均值,该均值即为实体级连通约束损失ℓR。具体计算公式如下:
2.2.3 实体间共生知识约束
与实体级连通约束损失构建一样,实体间共生约束损失ℓK以标签中连通域为实体单元进行计算。首先确定每个实体的分类类别,取实体Si(1 ≤i≤N)的分类置信度向量将向量中最大值及其最大值序号分别作为该实体的分类置信度和分类类别k(1 ≤k≤C);其次给实体Si打分,取中心实体Si邻域内的所有实体{Sj|SjAdjacent toSi}对Si打分(邻域内共mi个实体),Si的分值由邻域内实体的分类置信度向量的最大值和共生条件概率P按类别加权求和而来,得到具有通道维数的分值向量Hi∈RC,该向量代表中心实体在当前邻域空间分布下所属各类的分类置信度;最后根据实体的基于空间分布的分类置信度向量Hi和真实类别Yi计算损失,取所有实体损失项的均值作为实体间共生约束损失ℓK。具体计算公式如下:
实体间共生知识约束和实体级连通约束的关系如图1所示。二者都以连通域单元作为基本计算单位且损失计算都依赖实体的分类置信度向量,但损失计算方式、约束角度有明显区别。其中,连通域单元是标签中各类别实体相连通的像素区域,实体的分类置信度向量是通过计算每个连通域单元的预测结果的逐通道均值得到。如图1 第3行所示,实体级连通约束计算实体的分类置信度向量和真实标签之间的损失,从实体层级对网络进行约束,使网络自主学习实体级别的特征表示。如图1第四行所示,实体间共生知识约束基于多个邻域实体的分类置信度向量和地学知识图谱中的共生条件概率得到空间分布的分类置信度向量,再计算空间分布的分类置信度向量和真实标签间损失,从领域知识的角度约束深度网络训练。实体间共生知识约束将非结构化的知识嵌入到数据驱动的深度语义分割网络中,从而自动优化分割结果的空间分布。
2.3 深度语义分割网络的优化方法
深度语义分割网络输出的分类置信度图F及其标签影像Y∈RH×W计算总体损失,通过后向传播算法降低总体损失L,从而优化深度语义分割网络。基于实体级连通约束的损失ℓR引导深度语义分割网络在训练的过程中自主学习实体级别的特征表示,使得网络输出的分割结果更具整体性,边界模糊和随机噪声现象得到抑制。基于实体间共生约束的损失ℓK根据实体间的空间共生知识调整目标的空间分布,从而实现对分割实体的空间分布的自动优化。
3 数据处理与结果分析
3.1 实验数据集
本文基于UCM 遥感数据集(Shao 等,2018)和DeepGlobe 遥感数据集(Demir等,2018)。UCM数据集包含21 个地物类别,每个类别有100 张遥感图像,每张图像尺寸为256×256像素,地面分辨率为0.3 m。样本集采用密集标注的DLRSD 数据集(Shao 等,2018),共包含17 类。参照(Alirezaie等,2019)的做法,为了缩小类别之间的相似性,本文将样本集中的17类合并成了8类,分别是植被(Tree,Grass)、裸地(Bare soil,Sand,Chaparral)、道路(Pavement,Dock)、建筑(Building,Mobile home,Tank)、水体(Water,Sea)、飞机(Airplane)、车辆(Cars)和船只(Ship)。每个类别由括号里面的原类别合并而成。为了减低类别之间的相似性,移除了包含Field 或Tennis court 类的图像。将这些筛选出来的图像按8∶1∶1的比例随机划分出训练集、验证集和测试集,分别包含1513、189和190张图像。
DeepGlobe土地覆盖分类数据集提供了1146幅亚米分辨率的遥感影像,图像尺寸为2448×2448像素。人工标注了7 类,分别是城镇、耕地、牧场、森林、水体、裸地和未知类。整个数据集分为训练集、验证集和测试集,分别包含803、171 和172 幅图像。从每个原始图像中均匀地裁剪大小为256×256 像素的图像。将裁剪后的图像按8∶1∶1的比例随机划分出训练集、验证集和测试集,分别包含10272、1280和1296张图像。
UCM 遥感数据集中,训练所使用的地学知识图谱各类别共生条件概率如表1 所示;DeepGlobe数据集中各类别共生条件概率如表2所示。表中每一行表示地学知识图谱中的类别Ci,每一列表示与Ci不同的类别Cj;表中的具体数值表示共生条件概率,即本体类Ci实体出现的条件下邻域内出现本体类Cj实体的概率P(Cj|Ci)。

表1 UCM数据集各类别共生条件概率Table 1 Symbiosis conditional probability of each category in UCM dataset
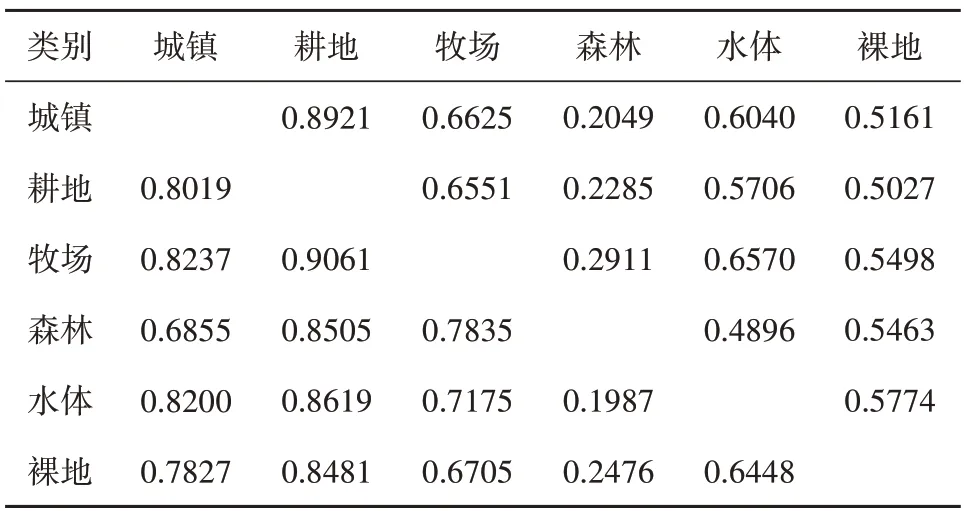
表2 DeepGlobe数据集各类别共生条件概率Table 2 Symbiosis conditional probability of each category in DeepGlobe dataset
3.2 实验设置及评估指标
在实验测试的过程中,本文采用了经典的UNet(Ronneberger 等,2015)和先进的DeepLab V3+(Chen 等,2018)深度语义分割网络。U-Net是一种用于图像分割任务的卷积神经网络,以其编码—解码结构和跳跃连接的设计而闻名,能够有效地处理医学图像和自然图像等领域的分割问题。其采用了一种类似于“U”形的结构,将输入的图像分成两个部分,分别进行卷积和池化操作,然后将它们合并起来得到最终的输出结果。这种结构可以有效地捕捉图像中的细节信息,从而提高了分割的精度。DeepLabv3+是一种用于图像语义分割的深度学习模型。它结合了全卷积网络和空洞卷积,以实现高效准确的图像分割。模型采用编码器—解码器结构,使用预训练的卷积神经网络提取特征,并通过转置卷积将特征映射上采样到原始图像尺寸。空洞卷积和自适应空洞扩张模块允许模型在不增加参数的情况下捕捉多尺度上下文信息。多尺度推理和空间金字塔池化进一步提高分割性能。DeepLabv3+在图像分割任务中取得了优秀的性能。对于网络的训练,分别采用随机梯度下降法(SGD)和交叉熵(Cross Entropy)作为优化器和损失函数。在深度学习领域中,当数据规模等条件差距较大时,为了保证网络的收敛,通常使用不同的初始学习率进行网络训练(He 等,2016)。本文中2 个数据集的数据规模和分辨率等条件差异较大,因此,在UCM 数据集和DeepGlobe 数据集上的学习率设置不同,分别为3×10-4和2×10-4。另外,超像素分割方法采用了简单线性迭代聚类SLIC(Simple Linear Iterative Cluster)(Achanta 等,2012)。所有的实验均在PyTorch 框架下使用一块NVIDIA 1080Ti GPU 进行的。
语义分割结果的评价指标采用总体精度OA(Overall Accuracy)、交并比IoU(Intersection over Union)、均交并比(Mean Intersection over Union,MIoU)和频权交并比FWIoU(Frequency Weighted Intersection over Union)。上述指标计算公式如下:
式中,n为类别的数量,TP、TN、FP和FN 分别为正类被正确判别的像素数、正类被错误判别的像素数、负类被正确判别的像素数和负类被错误判别的像素数。
3.3 超参数的敏感性分析
超参数主要包括式(2)中的α和β,α用于调节实体级连通约束损失项ℓR在总体损失L 中的占比,β用于调节实体间共生约束损失项ℓK在总体损失L 中的占比。由于ℓR和ℓK对于总体损失L 贡献比例并无法直接通过理论得到,因此我们将其设置为超参数,通过实验来探究合适的比例。在UCM 数据集和DeepGlobe 数据集上,本文使用DeepLab V3+(Chen 等,2018)作为基础网络进行超参数的敏感性分析实验。
3.3.1 UCM数据集上超参数敏感性分析
UCM 验证集上α的敏感性分析结果见表3。可见:当β=0.5 时,随着α增加,基础网络在验证集上的分割精度先上升后下降,当α=0.5 时分割精度到达顶点。在最佳α=0.5 取值条件下,β的敏感性分析结果见表4。可见基础网络在验证集上的分割精度随着α变化,当β=0.5,得到最佳精度。
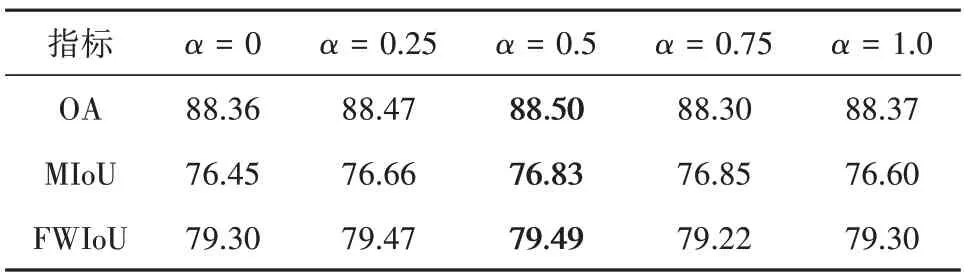
表3 在UCM验证集上α的敏感性分析(β=0.5)Table 3 The sensitivity analysis of α on the validation set of the UCM dataset(β=0.5)/%
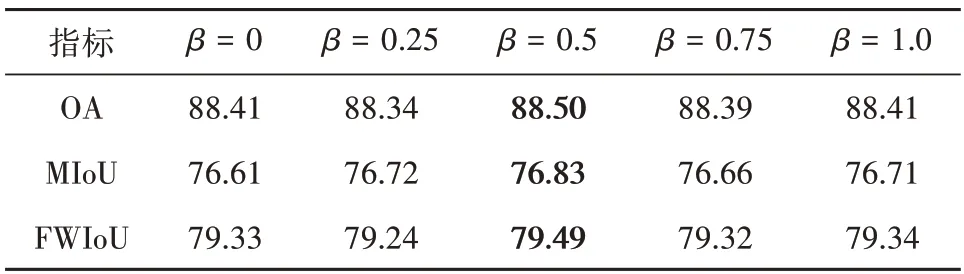
表4 在UCM验证集上β的敏感性分析(α=0.5)Table 4 The sensitivity analysis of β on the validation set of the UCM dataset(α=0.5)/%
3.3.2 DeepGlobe数据集上超参数敏感性分析
表5 为DeepGlobe 验证集上α的敏感性分析结果。可见:当β=0.5 时,基础网络在验证集上的分割精度随着α变化,当α=0.5,得到最佳精度。在最佳α=0.5取值条件下,β的敏感性结果见表6,可见随着β增加,基础网络在验证集上的分割精度先上升后下降,当β=0.5时分割精度到达最佳。
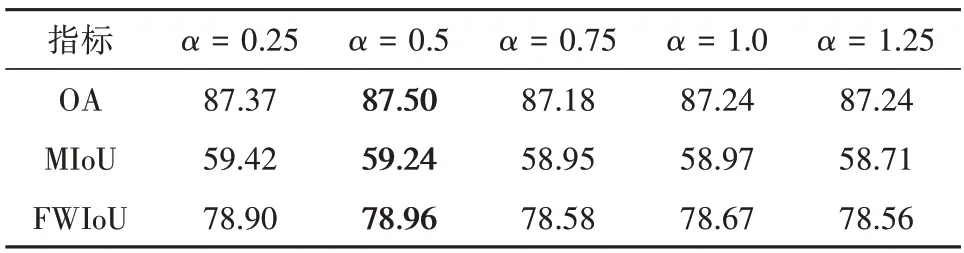
表5 在DeepGlobe验证集上α的敏感性分析(β=0.5)Table 5 The sensitivity analysis of α on the validation set of the DeepGlobe dataset(β=0.5)/%
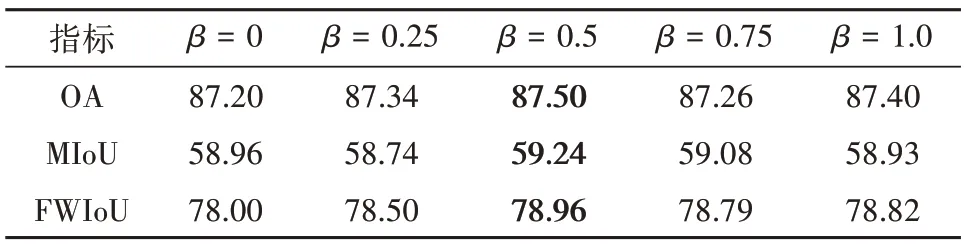
表6 在DeepGlobe验证集上β的敏感性分析(α=0.5)Table 6 Sensitivity analysis of β on the validation set of the DeepGlobe dataset(α=0.5)/%
3.4 消融实验
在UCM数据集和DeepGlobe数据集上,本文使用U-Net(Ronneberger 等,2015)和DeepLab V3+(Chen等,2018)作为基础网络进行消融实验。
3.4.1 UCM数据集上的结果
本文方法在UCM 测试集上的语义分割精度如表7所示。可见:相比于基于像素级稠密约束的常规损失(ℓP)训练的语义分割网络,加入实体级连通约束(ℓP+ℓR)训练的网络的分割精度OA、MIoU 和FWIoU 均更高,尤其是在MIoU 上提升明显,提升幅度达9%,这说明实体级学习能够有效提高深度语义分割网络的性能;综合实体级连通约束与实体间共生约束(ℓP+ℓR+ℓK)的深度语义分割网络的精度优于只加入实体级连通约束(ℓP+ℓR)的网络,这体现了空间共生知识对于遥感影像语义分割的重要性。
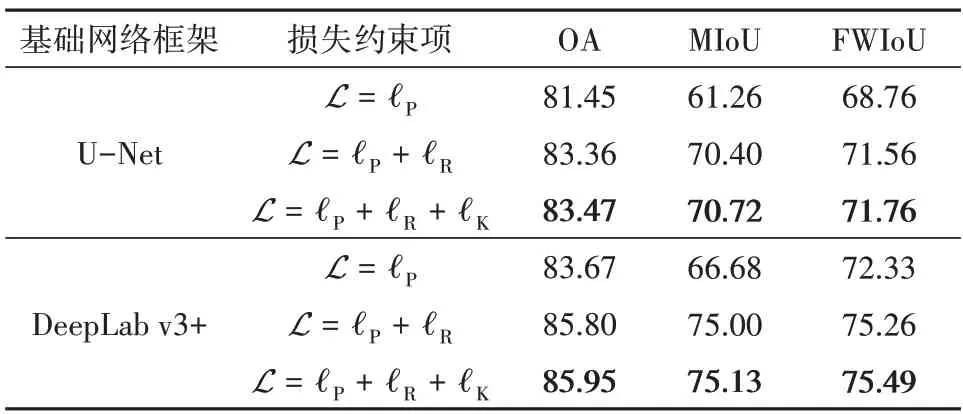
表7 在UCM测试集上的语义分割精度Table 7 The accuracy of semantic segmentation on the test set of the UCM dataset/%
深度语义分割网络在UCM 测试集上的分割结果如图3 所示。可见:实体级连通约束(ℓP+ℓR)分割结果和综合实体级连通约束与实体间共生约束(ℓP+ℓR+ℓK)的分割结果均明显优于常规的像素级稠密约束(ℓP)的分割结果;对于飞机、车辆等小目标场景,施加实体级连通约束能获取轮廓更加清晰的分割结果,对于建筑物和油罐等规则地物,施加实体级连通约束的分割结果整体性更佳,噪声较少同时轮廓更加清晰,这表明约束项使得网络学习到了实体级的特征表示。另外,综合实体级连通约束与实体间共生约束(ℓP+ℓR+ℓK)的分割结果中地物实体空间分布更加接近真实世界中的空间布局,如建筑物邻近道路与植被。

图3 UCM测试集上的可视化分割结果图Fig.3 The visible semantic segmentation of the test set of the UCM dataset
3.4.2 DeepGlobe数据集上的结果
本文方法在DeepGlobe 测试集上的语义分割精度如表8所示。可见相比于基于像素级稠密约束的常规损失(ℓP)训练的语义分割网络,加入实体级连通约束(ℓP+ℓR)训练的网络的分割精度OA、MIoU 和FWIoU 均更高,这说明了实体级学习能够有效提高深度语义分割网络的性能;综合实体级连通约束与实体间共生约束(ℓP+ℓR+ℓK)的深度语义分割网络精度优于常规的像素级稠密约束(ℓP)的网络。
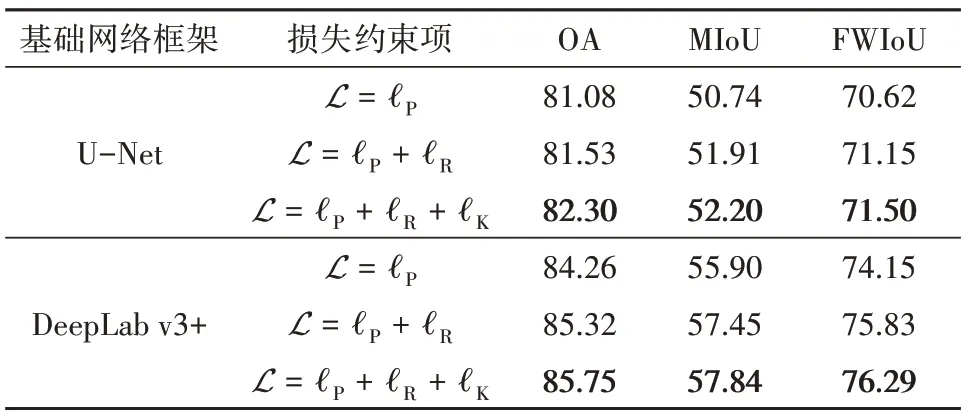
表8 在DeepGlobe测试集上的语义分割精度Table 8 The accuracy of semantic segmentation on the test set of the DeepGlobe dataset/%
图4 为深度语义分割网络在DeepGlobe 测试集上的分割结果。可见:实体级连通约束(ℓP+ℓR)分割结果和综合实体级连通约束与实体间共生约束(ℓP+ℓR+ℓK)的分割结果均明显优于基于像素级稠密约束的常规损失(ℓP)的分割结果;第一行和第二行的水体和牧场区域施加实体级连通约束与实体间共生约束(ℓP+ℓR+ℓK)的分割结果整体性更佳;第三行和第四行的水体和农业用地的分割结果施加约束后轮廓清晰,噪声更少,这表明约束项使得网络学习到了目标级的特征表示。综合以上结果可以看出综合实体级连通约束与实体间共生约束的分割结果中地物目标空间分布更加简单,一些错分目标类别被修正为邻域目标类别,从而优化了地物目标的空间布局。

图4 DeepGlobe测试集上的可视化分割结果图Fig.4 The visible semantic segmentation of the test set of the DeepGlobe dataset
3.5 与已有方法的对比分析
为进一步验证本文方法的有效性,本文选择了经典的U-Net 网络(Ronneberger 等,2015)、先进的DeepLab V3+网络(Chen 等,2018)、深度语义分割网络和图卷积网络相结合的DSSN-GCN 方法(Ouyang 和Li,2021)作为对比方法,其中DSSN-GCN 方法以DeepLab V3+作为基础网络。本文方法以DeepLab V3+作为基础网络,超参数α和β取各数据集下的最佳值。各方法在UCM 测试集和DeepGlobe 测试集上的分割精度见表9 和表10 所示。可见本文提出的地学知识图谱引导的遥感影像深度语义分割方法综合了实体级连通约束与实体间共生约束(ℓP+ℓR+ℓK),均取得最佳的分割精度,这充分验证了本文方法对于遥感影像语义分割的有效性,同时说明了在深度语义分割网络中嵌入地学先验知识的重要性。相比于地学先验知识预嵌入的DSSN-GCN 方法,本文方法能够自主运用和学习地学先验知识,从而获得精度高和鲁棒性强的分割结果。各方法在UCM 测试集和DeepGlobe 测试集上的语义分割结果如图5 和图6所示。与表9 和表10 结果一致,本文方法取得比其余方法更佳的分割效果。各方法对建筑物的分割结果表明在实体级连通损失的约束下,本文方法的分割结果更具整体性,轮廓清晰(第一行至第三行)且对于干扰较大的场景时噪声更少(第四行至第六行);实间空间共生知识约束修正了分割结果中地物目标的空间分布,使其更接近现实世界的空间布局,如第一行所示的车辆通常近邻道路(图5)。图6 中各方法分割结果也表现出类似的结论,本文方法对城镇和水体的分割结果更具整体性,对于水体轮廓的分割结果更加清晰,且对于复杂城镇场景的分割噪声更少。
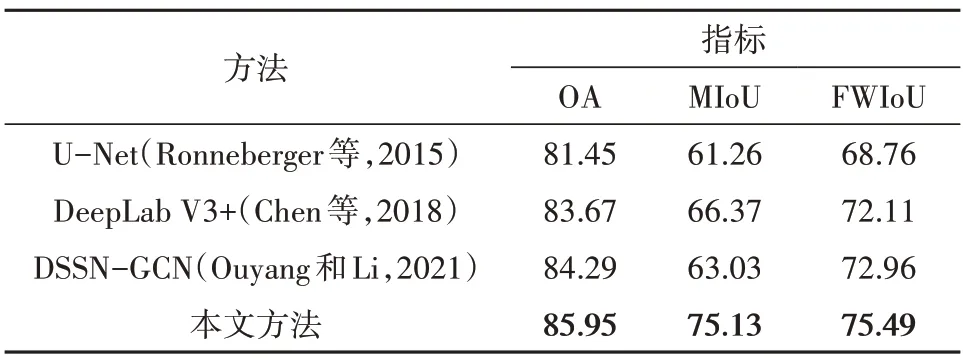
表9 各方法在UCM测试数据集上的语义分割精度Table 7 The accuracy of semantic segmentation of various methods on the test set of UCM dataset/%
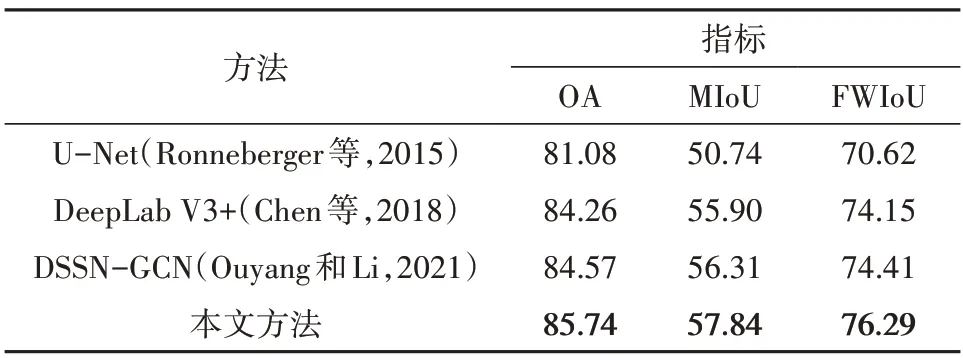
表10 各方法在DeepGlobe数据集上的语义分割精度Table 10 The accuracy of semantic segmentation of various methods on the test set of DeepGlobe dataset/%

图5 各方法在UCM测试集上的语义分割结果Fig.5 The semantic segmentation results of the test set of the UCM dataset
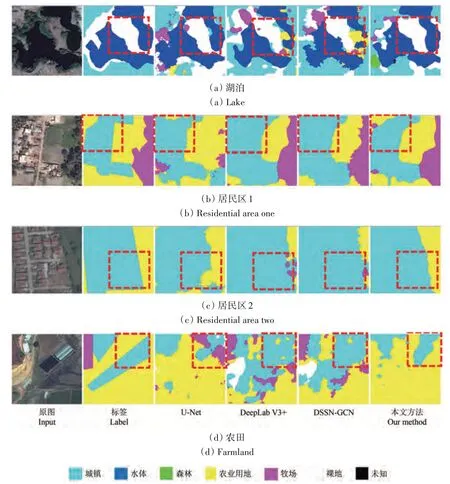
图6 各方法在DeepGlobe测试集上的语义分割结果Fig.6 The semantic segmentation results of the test set of the DeepGlobe dataset
4 结论
针对深度语义分割网络缺乏目标级学习以及难以利用地学先验知识和空间语义信息的问题,本文提出了地学知识图谱引导的遥感影像深度语义分割方法。地物目标的语义信息以地学知识图谱的形式进行表达,地学先验知识从地学知识图谱中抽取,地学先验知识和目标空间语义信息用于构建实体级连通约束损失和实体间共生约束损失。实体级连通约束损失引导深度语义分割网络自主学习目标级特征,实现了对实体的整体约束,使得分割结果更具整性并减少了边界模糊和随机噪声;实体间共生约束损失成功地将非结构化的地学先验知识嵌入到数据驱动的深度语义分割网络中,完成了对分割目标的空间分布的自动优化。本文方法有效地提高了深度语义分割网络的性能和鲁棒性,但同时也存在所采用的地学先验知识单一的问题。后续研究工作将引入更全面的地学先验知识,包括地物目标空间拓扑信息、形状结构信息等知识。
志 谢本研究的数值计算部分得到了武汉大学超级计算中心的帮助。
猜你喜欢
少先队活动(2020年12期)2021-01-14
小学生作文(低年级适用)(2020年10期)2020-11-10
数学年刊A辑(中文版)(2020年2期)2020-07-25
中国建筑装饰装修(2020年6期)2020-07-10
数学物理学报(2019年6期)2020-01-13
福建基础教育研究(2019年2期)2019-09-10
福建基础教育研究(2019年2期)2019-05-28
数学物理学报(2017年5期)2017-11-23
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
