
基于用户长短期历史的多兴趣召回算法
2024-03-24 03:10欧中洪宋美娜
南京大学学报(自然科学版) 2024年1期
张 旭,欧中洪,宋美娜
(北京邮电大学计算机学院,北京,100876)
目前推荐系统多兴趣召回领域的研究主要聚焦于针对用户短期历史行为记录的建模,忽视了用户长期历史行为记录中隐含的用户长期兴趣偏好以及建立用户短期和长期兴趣偏好间的关联关系等问题.同时,在推荐系统用户长行为序列建模领域中,主流研究往往采用单个全局用户嵌入向量来表示用户的兴趣偏好,但这样会使用户多个兴趣的不同信息混合在一起,导致召回阶段的物品检测不准确.本文定义并构造了一种基于用户长短期历史的多兴趣召回算法模型,通过在两个开源数据集上进行的实验和对比分析,验证了提出的算法模型的有效性.
本文的主要贡献如下.
(1)提出一种基于用户长短期历史的多兴趣召回算法LSMNet(Long and Short Multi-Interest Network),成功建模用户长历史纪录下的多个不同兴趣偏好.
(2)通过使用图神经网络对用户短期历史表征进行增强,并利用结构化自注意力机制提取用户多个短期兴趣偏好.对于用户长期兴趣偏好,使用Transformer 结构进行建模.最后,利用门控融合网络对长短期偏好进行融合,得到用户的最终兴趣偏好.
(3)在不同的公开数据集上进行了实验,结果证明LSMNet 模型可以有效地捕捉用户长期历史中的兴趣偏好.
1 相关工作
在推荐系统的早期研究阶段,召回算法主要分两大类,即基于内容的推荐算法和基于协同过滤的推荐算法.基于协同过滤的算法主要分两类,即基于模型的协同过滤算法[1-3]和基于记忆的协同过滤算法[4-6].
召回算法按照使用几个向量代表用户兴趣偏好分为单兴趣召回算法和多兴趣召回算法.多兴趣召回算法(如Octopus[7]模型)与经典单兴趣召回算法(如Youtube DNN[8]和FAT 模型[9])相比,使用了更复杂的模型结构,并用多个高维稠密向量来代表用户潜在的兴趣偏好.和单兴趣召回算法相比,多兴趣召回算法避免将用户的多个兴趣混合在一起,提高了召回阶段候选集的准确性,实现了千人万面效果.然而,目前的主流研究都忽视了用户长期历史行为记录中蕴含的潜在信息,没有将用户的长期历史和短期历史综合考虑.
另一方面,召回算法按照模型输入的用户历史行为记录长度分为短期历史召回算法和长短期历史召回算法.如Youtube DNN,MIND 和FAT等模型均为短期历史召回算法模型,只基于用户最近的历史行为记录建模.长短期历史召回算法对用户长期历史和短期历史使用不同的模型进行建模,并将得到的用户长期兴趣偏好和短期兴趣偏好进行融合.如SHAN 模型[10]使用两层注意力网络建模用户长期偏好并与用户短期历史进行融合.ADNNet 模型[11]使用卷积神经网络建模用户短期偏好,利用门控循环单元建模用户长期偏好,通过自注意力机制将两者进行融合.
2 基于用户长短期历史的多兴趣召回算法
本节介绍基于用户长短期历史的多兴趣召回算法的模型结构,模型结构如图1 所示.

图1 LSMNet 的整体架构图Fig.1 The overall architecture of LSMNet
2.1 嵌入层在召回任务中,输入数据由物品的ID 组成,但神经网络无法直接处理ID 类特征,一种常用的做法是借助嵌入变换用一个低维度稠密向量表示物品.具体计算如下:
其中,xi表示用户在第i个位置上点击的物品对应的ID,Witem代表物品嵌入矩阵,ei表示用户在第i个位置上点击的物品对应的嵌入向量.
因为Transformer 结构和图神经网络中不能区分物品的先后顺序,所以为每个位置加上对应的嵌入向量.最终用户的物品嵌入向量如下:
其中,E表示用户历史嵌入向量,pi表示第i个位置对应的嵌入向量.
2.2 长期兴趣偏好提取模块对于物品嵌入E,将其输入2.1 中的Transformer 编码器来提取用户的长期兴趣偏好.具体的计算过程如下:
其中,LayerNorm表示层级归一化,W1和W2表示前馈网络层的权重参数,b1和b2表示前馈网络层的偏置项,max 表示取最大值,V为自注意力层的输入,Y为物品嵌入E经过一层Transformer 编码器编码后的向量.通过堆叠上述Transformer编码器,并将每一层编码器的输出输入至下一层,最终得到用户长期兴趣偏好Ilong.
2.3 短期兴趣偏好提取模块短期兴趣偏好提取模块由两个子模块组成,即图交互子模块和结构化自注意力子模块.图交互子模块负责将用户短期历史序列在图视角下进行交互计算,结构化自注意力子模块将经由图交互子模块的物品嵌入转换为多个用户短期兴趣偏好.
2.3.1 图交互子模块图交互子模块以用户历史交互物品嵌入E为输入,重新记为E0,上标表示在图交互子模块中的迭代次数,0 表示原始输入.使用对应的小写字母代表某个物品,用小标表示该物品所处的位置,如表示两轮图算法迭代后第r个位置的物品的嵌入.
首先构建一张线性图,以物品作为图节点,为相邻的历史物品间添加一条有向边,有向边的方向从较远交互物品指向较近交互物品.在图上新构建一个节点C,为该节点与用户所有输入历史物品间添加一条无向边,并初始化节点C的嵌入c0为所有历史物品嵌入的平均值.具体计算如下:
为了使物品信息能在图结构上进行传播,将节点更新过程分为两步并不断重复L次,L为超参数.第一步更新所有物品节点的嵌入,第二步更新新增节点c的嵌入.
(1)第一步,以第l次迭代为例,第r个物品节点具体的更新计算如下:
其中,MultiHead表示多头自注意力层,详细计算参考式(5);表示第r个物品的初始嵌入,表示第r个物品上一轮中的嵌入,表示前一个物品上一轮中的嵌入;cl-1表示节点C上一轮中的嵌入;为第l次迭代第r个物品临时向量;输出表示第r个物品第l次迭代后的嵌入.对每个物品节点按上述公式同时进行更新,得到第l次迭代后所有物品嵌入El.
(2)第二步,以第l次迭代为例,节点C的更新过程如下:
其中,El表示第一步计算得到的第l轮迭代后的所有物品嵌入,cl-1表示节点C在第l-1 轮迭代后的嵌入,ql为第l轮迭代中临时向量,cl表示节点C在第l轮迭代后的嵌入.
经过两步L轮迭代后,得到最终物品嵌入EL,并将其输入结构化自注意力子模块中.
2.3.2 结构化自注意力子模块对于图交互子模块的输出物品嵌入EL,重新用H标记,使用结构化自注意力机制从中提取用户多个短期兴趣偏好.具体计算如下:
其中,Softmax表示归一化指数函数,Ws1∈RK×4d和Ws2∈R4d×4表示权重矩阵,K表示用户兴趣偏好数量,d表示隐藏层维度,tanh 表示双曲正切函数,HT表示物品嵌入H的转置,Ishort∈RK×d表示用户多个短期兴趣偏好,A为计算过程中的临时变量.
2.4 兴趣融合模块通过长期兴趣偏好提取模块和短期兴趣偏好提取模块分别得到用户的长期兴趣偏好Ilong和短期兴趣偏好Ishort,使用兴趣融合模块对长短期兴趣偏好进行融合.兴趣融合模块由门控融合网络组成,对于每一个短期兴趣偏好,使用门控融合网络计算其与长期兴趣偏好的权重值并加权求和.例如,对第j个短期兴趣偏好,具体的计算流程如下:
其中,W1和W2为可学习的权重映射矩阵,b为偏置项,Gj为第j个兴趣偏好计算过程中长期兴趣偏好的权重,Vj表示用户的第j个融合兴趣偏好.将用户的所有兴趣偏好进行拼接,得到用户最终的兴趣偏好V:
3 模型训练推理
在得到用户最终兴趣偏好V后,对于某一个交互物品i,可以找到与物品嵌入ei最相似的用户兴趣向量,如下所示:
其中,argmax 表示取最大值所对应的小标,v表示与物品嵌入ei最相似的用户兴趣偏好,VT表示V的转置.
给定训练样本(u,i),通过上述步骤得到ei和v,可以计算用户u点击物品i的可能性:
其中,I 表示物品集.
模型训练时的损失函数为最小化负对数似然,具体计算如下:
其中,U表示所有用户,Iu表示用户u的交互物品集.
模型推理时,根据目标用户的多个兴趣偏好,每个兴趣偏好召回一定数量的候选物品集,将这些候选物品集合按点积相似度从大到小排序,取前Top-K 个物品作为目标用户召回物品候选集.
4 实验与结果
4.1 数据集介绍MovieLens 数据集由用户对电影的评分信息和时间戳组成,同时包含了电影和用户的部分元数据特征.用户特征含有用户的性别、年龄和所在地,物品特征含有电影标题和电影类型.
MovieLens 提供了多种大小的数据集,本文选择MovieLens-1M 数据集来衡量召回阶段的相关性能.MovieLens-1M 数据集共包含2000 年4 月25 日至2002 年2 月28 日6040 名用户对3952部电影的1000209 条评分,评分范围为1~5 的整数.
Taobao 数据集[12]是阿里巴巴提供的一个淘宝用户行为数据集,可用于隐式反馈推荐问题的研究.Taobao 数据集包含2017 年11 月25 日至2017 年12 月3 日987994 名有行为的用户在4162024 件物品上的100150807 条行为.行为包括点击、喜欢、购买、加购,额外特征只包含商品类目特征.
对于两个数据集,首先去除出现次数小于五次的冷门物品,再去除历史行为少于五次的不活跃用户.对于每个用户的历史行为记录,参考SDM(Sequential Deep Matching)[13]的方法进行处理,并将所有用户的倒数第二件物品作为验证集,将所有用户的倒数第一件物品作为测试集.
4.2 评估指标介绍命中率(Hit Rate,HR)[14]对所有的用户整体考虑推荐预测结果的准确性,表示有多少比例的用户的预测物品结果中至少包含一件与用户有交互的物品.
归一化折损累积增益(Normalized Discounted Cumulative Gain,NDCG)[14]主要用来衡量和评价搜索算法,也适用于推荐系统评估.在推荐系统领域中,根据测试集和推荐的预测结果顺序,依次计算累计增益(Cumulative Gain,CG)、折损累计增益(Discounted Cumulative Gain,DCG)、理想折损累计增益(Ideal Discounted Cumulative Gain,IDCG).归一化折损累积增益定义为折损累计增益经过理想折损累计增益归一化后的结果.
4.3 实验对比模型选取六种主流的推荐召回算法作为基线算法,与提出的算法进行对比研究.
(1)MIND[15]:是深度学习多兴趣召回经典算法之一,使用共享权重的胶囊神经网络建模用户多个兴趣偏好.
(2)Comirec-SA[14]:使用自注意力层从用户历史行为中提取用户多个兴趣偏好.
(3)Comirec-DR[14]:同样使用胶囊神经网络建模用户多个兴趣偏好.和MIND 相比,Comirec-DR 使用独享权重的胶囊神经网络,即不同的低层胶囊和不同的高层胶囊使用不同的参数.
(4)Transformers4Rec[16]:利 用Transformer结构建模用户兴趣偏好,用户最近行为对应的向量代表用户兴趣偏好.
(5)SHAN[10]:首先通过一层注意力网络建模用户的长期兴趣偏好,再利用一层注意力网络联合用户的长期兴趣偏好和短期兴趣偏好来计算最终的用户兴趣偏好.
(6)SDM[13]:通过带残差的LSTM(Long-Short Term Memory)加自注意力机制的复杂模型对用户短期兴趣进行建模,利用注意力机制对用户长期兴趣进行建模,最终通过门控神经网络融合用户长期兴趣和用户短期兴趣.
所有模型使用Tensorflow[17]实 现,并使用Adam[18]优化器对模型进行优化学习.
4.4 实验结果对比实验的结果如表1 所示,表中黑体字表示性能最优.

表1 不同召回模型的性能对比Table 1 Performance of different recall models
由表可见,LSMNet 的表现均优于其他基线模型.具体地,在MovieLens 数据集上,LSMNet的HR@50 和NDCG@100 分别提升4.49% 和2.31%;在Taobao 数据集上,LSMNet 的HR@100 和NDCG@100 分别提升8.55% 和5.68%.实验结果充分证明了该算法的有效性.
虽然和MIND 相比,Comirec-DR 去除了共享参数,理论上应该有更大的模型容量,但其在两个数据集上的表现却各有优劣,可能因为和Movie-Lens 数据集相比,Taobao 数据集含有更多噪声.
虽然SHAN 考虑了用户长期历史行为,但是因为其模型结构比较简单,表现不佳.和SHAN相比,SDM 的模型结构更复杂,所以SDM 在两个数据集上都获得了次优表现.
4.5 消融实验对比定义LSMNet 去除长期兴趣偏好提取模块的模型为LSMNet-L,去除图神经网络的模型为LSMNet-G.表2 展示了LSMNet 模型去掉部分模块后的性能表现.由表可见,去除长期历史建模模块或图神经网络后,模型的性能明显下降,而且去除长期历史建模模块后,模型性能的下降更明显.充分证明了建模用户长期历史和图神经网络的有效性.
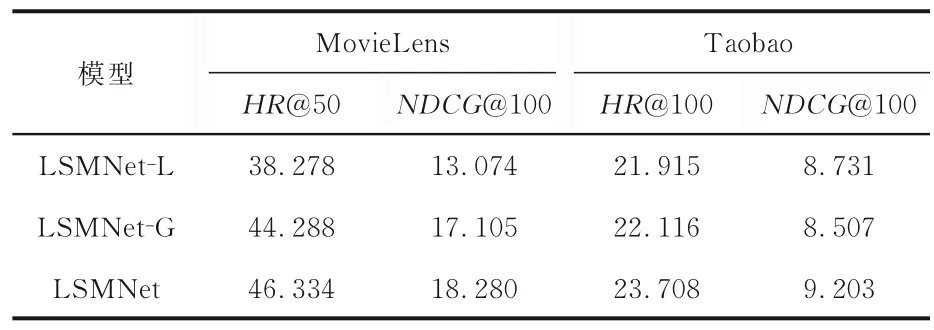
表2 模型各模块的消融实验结果对比Table 2 Performance of each module of LSMNet in ablation experiments
5 结论
本文提出一种基于用户长短期历史的多兴趣召回算法,利用图神经网络和结构化自注意力捕捉用户短期兴趣偏好,利用Transformer 架构捕捉用户长期兴趣偏好,并通过门控融合网络融合用户长短期兴趣偏好得到最终用户兴趣偏好.实验结果表明,本文提出的基于用户长短期历史的多兴趣召回算法,其性能表现优于许多已有的召回算法.该算法是可行且高效的.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
疯狂英语·初中天地(2021年11期)2021-02-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
少年漫画(艺术创想)(2019年2期)2019-06-06
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
