
结合扩张金字塔的脑部医学图像融合
2024-04-01 06:41马为民郑茜颖
电视技术 2024年1期
马为民,郑茜颖
(福州大学 物理与信息工程学院,福建 福州 350108)
0 引言
目前,医学影像在临床诊断的作用越来越突出。不同模态的医学图像提供不同的信息[1]。综合利用多模态信息,实现多模态图像医学融合,加强各个模态之间的信息互补性,在临床上具有重要的意义[2]。近年来,许多基于深度学习的方法已经被证明是成功的图像融合方法[3-5]。2017 年,LIU Y 等[6]提出了基于卷积神经网络(Convolutional Neural Networks,CNN)的图像融合网络,利用图像补丁对和模糊版本的深度神经网络映射,实现了源图像和焦点图像的直接映射。然而,由于训练策略的局限性,这种方法适用的场景局限在多焦点图像。为了克服这一缺点,LI H 等提出Dense Fuse[7],一种新型的基于密集型自动编码器的网络,整体结构由编码器、融合器和解码器3 部分组成。在训练阶段,融合器被丢弃,变成一个自动编码器网络,用于提取源图像的特征和重构解码源图像的特征;在测试阶段,加入融合器后,对融合后的图像进行重构解码。MA J 等人[8]将生成对抗网络(Generative Adversarial Networks,GAN)结构引入图像融合,提出了Fusion GAN,在生成器和鉴别器之间建立对抗游戏,在对抗策略下生成融合图像。HUANG J 等人[9]提出了一种多生成器和多鉴别器的条件对抗网络MGMDcGAN。两种cGAN 相互配合,使得该网络呈现出更好的视觉效果。FU J 等引入残差金字塔注意力结构MSPRAM[10],结合了剩余网络和金字塔注意力的优点,提取比单一剩余注意力更多的信息或者把金字塔注意力机制看成层数的增加并保持更好的深层次特征和表达能力;另一个网络结构MSDRA[11]利用双残差注意网络同时注意和获得重要的细节特征,在融合中避免网络梯度消失和爆炸。FU J 等人提出级联密集残差网络CDRNet[12],利用多尺度密集网络和残差网络作为基本结构,通过三级级联得到多级融合网络。多模态医学图像通过网络的每一级训练,得到输出融合图像逐步增强,融合图像越来越清晰。
尽管深度学习用于医学融合取得了一定的成果,但仍然存在着融合图像模糊、边缘信息不丰富以及大量细节丢失等问题。为了解决这些问题,本文提出了基于扩张金字塔特征提取的图像融合算法,网络整体继承以前的成果,由特征提取器、特征融合器和特征重构器3 个部分构成。特征提取器使用了由扩张金字塔特征提取组成的算法,通过浅层特征和深层特征的结合,增强了图像的特征提取能力。特征融合器中,本文提出了改进的功能能量比(Functional Energy Ratio,FER)特征融合策略,提高了特征融合效果。特征重构器由4 层卷积构成,把高维特征逐步降低并最终输出融合图像。为了更好地完成优化任务,本文提出基于L2损失和VGG-16 的联合损失函数。通过大量实验表明,本文方法相比当前的融合算法有更优的性能。
1 本文算法
本文算法的整体框架包括4 个部分,如图1 所示。第一,扩张金字塔特征提取模块,结合金字塔特征提取的优点,加入扩张层,进一步提升特征提取能力,实现图像浅层和深层次特征的结合。第二,融合策略模块,完成深层次特征图像融合工作,设计了改进FER 融合策略。第三,特征重构模块,将融合后的高维特征转化为输出图像。第四,混合损失函数,在L2损失函数基础上加入基于VGG-16 的网络损失函数,进一步提高本文算法的性能。

图1 算法总体框架
1.1 扩张金字塔特征提取
本文的扩张金字塔特征提取是基于金字塔注意力机制来设计的[13]。本文中一个特征金字塔注意力机制通过实现金字塔网络的U 形结构,使用了1 个3×3 卷积、2 个3×3 卷积和3 个3×3 卷积并融合3 种不同尺度的特征信息,更加准确地表达邻域尺度的上下文特征;又引入了下采样再上采样的软注意力操作使得原始特征与金字塔注意力相乘,防止因为层数的增加而丢失原始的信息,从而进一步提高模型性能。1 个金字塔注意力机制的数学表达式为
式中:Q(x)为输出特征,x为输入特征,V(x)是下采样上采样的软注意力函数,P(x)是金字塔型网络,即1 个3×3 卷积、2 个3×3 卷积和3 个3×3 卷积。
本文中,金字塔模型由3 个金字塔注意力机制组成,通过3 次下采样在经过金字塔注意力机制后再经过3 次上采样构成了金字塔模型。金字塔模型的基本结构如图2所示。然而,金字塔模型的下采样操作和层数的增加可能会丢失信息和图像中的精细细节。为了解决这个问题,本文分别利用1、3、5 这3 种不同的扩张卷积在浅层的图像特征上进行多尺度的特征提取,利用3 种不同的扩张卷积得到3 种不同的感受野,进一步提高浅层特征的利用,加强图像的细节信息。扩张卷积多尺度浅层特征被提取,再送入金字塔模型进一步提取深层次特征,最终将这些特征用通道连接的方式完善浅层和深层特征。因此,本文算法结合了浅层和深层的图像特征,有更好的特征提取和表达能力。扩张金字塔特征提取如图1Fusion Net 中的Extractor 所示。
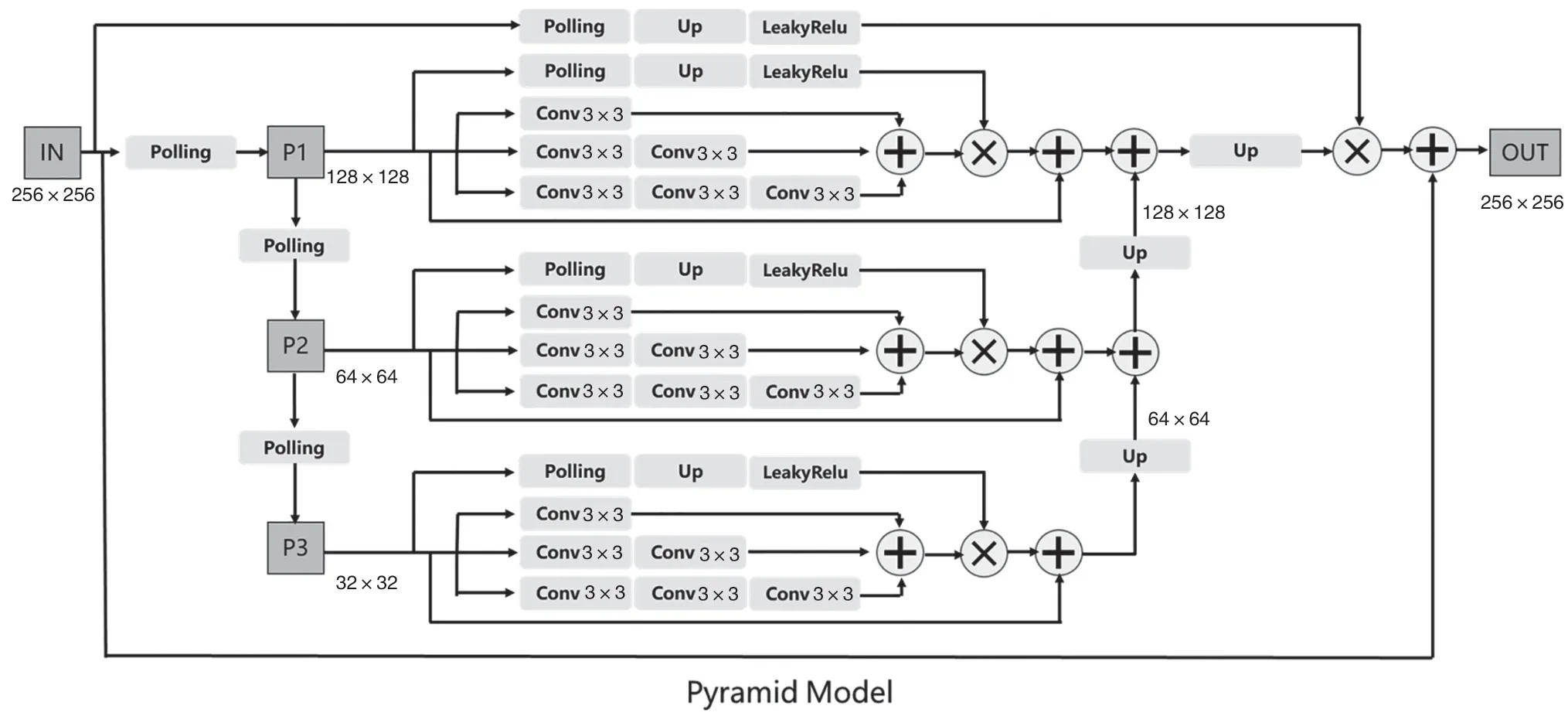
图2 金字塔模型
1.2 融合策略
融合策略是在融合模型中将提取的两张输入图像的特征转化为单一的图像特征的过程。假设I1、I2是输入的两张特征图,F是融合图像。加法策略(Addition)是将两张特征图简单相加,数学表达式为
平均策略(Average)在加法策略的基础上除以2,数学表达式为
FER[10]在加法策略和平均策略加入了特征图权重信息的融合策略,数学表达式为
FER在特征图权重中未考虑归一化的特征权重。本文提出改进的FER 融合策略,用Softmax 函数把特征图归一化到0、1 之间,数学表示为
式中:xi是输入特征图I1、I2上的像素点,S(xi)1、S(xi)2分别是I1、I2经过Softmax 函数的输出结果,F是融合图像。
1.3 特征重构
特征重构输入是融合后的图像特征,用于从图像中生成融合的可见图像,在降低特征维数的同时尽可能保留更多的图像细节。本文使用一个具有64 通道3×3 的卷积与输入64 通道数进行运算,然后连续使用3 个分别具有32、16、1 通道的3×3的卷积将通道数从64 依次减少到1,最终得到一张1 通道的图像输出。特征重构的结构如图1 Fusion Net 中的Reconstructor 所示。
1.4 损失函数
损失函数是影响深度学习的重要因素之一。不同的损失函数对神经网络的优化和收敛有着不同的影响。大量研究表明,混合损失函数的优化性能往往超过单一的损失函数,因此本文采用基于内容损失和基于预训练权重的VGG-16 训练网络。基于内容的损失用于计算融合图像和输入图像之间的像素差平方,L2损失[14]具有收敛速度快的特点,有利于网络快速收敛;VGG-16 的低层次特征图包含丰富的局部边界信息,高层次特征图则可以捕捉全局语义信息,用其在特征图上进行监督。L2的数学表达式为
式中:F是融合图像,I是输入图像,L、W是图像的长、宽。
基于VGG-16 的损失函数数学表达式为
式中:Fi和Ii是融合图像和输入图像经过VGG-16的第i层特征提取结构,是计算Fi和Ii的二范数。因此,总的损失函数数学表达式为
2 实验结果分析
2.1 数据集和实验设计
本实验使用脑图谱公共数据集(http://www.med.harvard.edu/AANLIB/home.html)进行训练和评估。数据集分割成训练集和测试集。SPECT-MRI数据集321 对用于训练,32 对用于测试。图片的大小都是256×256,SPECT 是伪彩色图像,MRI是灰度图像。图像都是成对输入模型训练。
所有的模型都是基于PyTorch 框架设计实现的。网络优化器用Adam,学习率设置为10-4去优化和降低融合损失函数;训练轮数Epoch 等于100,由于图形处理器(Graphics Processing Unit,GPU)的限制,每次的批次大小Batch_size 等于4。实验所用的计算机配置是Inter(R) Core(TM) i9-11900K@3.50 GHz,GPU 是NVDIA GeForce RTX 3080 Ti 显卡。
2.2 评价指标
过去已经提出了许多对于图像融合的评价指标。不同的指标反映了不同角度图像的融合性能。因此需要评价融合图像的不同指标。
峰值信噪比(Peak Signal to Noise Ratio,PSNR)[15]是最大信号功率与信号噪声功率两者之比。PSNR越大,代表图像质量越好。PSNR 的数学表达式为
式中:It是输入图像,I1、I2是输入图像对,MAXF是融合图像F中像素最大值,m、n是图像的行数和列数。
结构相似度(Structural Similarity,SSIM)[16]是一种衡量两幅图像相似度的指标,能反映场景中物体结构的属性,并将失真建模为亮度、对比度和结构3 个不同因素的组合。SSIM 的范围在[0,1],SSIM 越大,图像失真越小。SSIM 的数学表达式为
式中:μx、μy是图像的均值,σxy是图像的协方差。
特征相似度(Feature Similarity,FSIM)[17]基于相位一致性和梯度的大小评价参考图像的质量。FSIM 认为一张图像中所有像素并非具有相同作用。FSIM 越大,图像越接近参考图像。FSIM 的数学表达式为
式中:S是图像的结构信息,PC是相位一致性,x属于图像整个空间域。
熵(EN)[18]表示一张图片包含的信息丰富度。熵值越大,意味着融合图片包含的信息越丰富,融合质量越好。EN 的数学表达式为
式中:pF(i)是融合图像灰度值为i的概率。
2.3 融合策略比较
本文第1.2 节讨论了Addition、Average、FER和改进FER 几种融合策略,比较了这几种策略的可视化结果和客观评价指标。图3 显示了不同融合策略的对比,可以看出,Addition 策略融合图像整体偏亮,对SPECT 的效果并不好;Average 策略和FER 策略相较于Addition 策略,亮度缓和了,但是仍然存在融合图像边缘细节模糊;本文算法改进FER 相较于其他3 种融合策略整体图像感官更好,图像的边缘信息保留更加丰富。

图3 不同融合策略对比图
本文还进行了客观指标定量比较,结果如表1所示,加粗数字代表最优指标。可以看出改进FER策略虽然在EN 表现较弱,但是在PSNR、SSIM、FSIM 这3 个指标都达到了最优的效果。PSNR、SSIM 和FSIM 指标证明了融合图像与源图像有很强的相关性,更多地结合了MRI和SPECT图像的特征,保留了源图像的更多细节信息。因此,改进FER 策略相较于其他3 种融合策略不仅有更好的整体图像感官,而且具有更好的定量性能,能更好完成图像融合工作。

表1 不同融合策略的性能对比
2.4 融合结果比较
为了证明所提出算法的有效性,本文比较了现有通用的图像融合算法,包括MSPRAM[10]、DILRAN[11]、CDRNet[12],比较了不同算法的可视化结果和客观评价指标。对比实验可视化结果如图4所示。从融合结果可以看出,CDRNet 算法整体图像质感不好,融合图像整体效果偏亮;MSPRAM 算法和DILRAN 算法在某些边缘细节上存在细节丢失,导致边缘细节模糊或者看不见。本文的融合结果相比以上3 种算法,在整体观感上有更好的效果,看起来比其他算法更加自然,同时在边缘细节信息上保留了更多细节轮廓信息,特别在对比度较弱的细节边缘有着更好的融合效果。
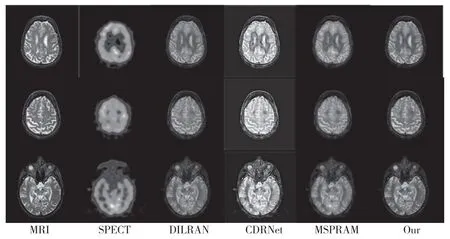
图4 不同算法对比图
此外,融合结果的客观指标如表2 所示,本文算法相对于参考算法的PSNR、SSIM 和FSIM 指标是最高的,EN 指标处于第二。在融合结果客观指标评价上,所提算法的整体性能优于其他比较算法,最优的PSNR 表明本文的融合图像的质量损失最小,图像质量最好。SSIM 和FSIM 指标则说明本文的融合图像保留了原始图像更多细节上的信息,与原始图像相似度更高。

表2 不同算法的性能对比
为了证明所提出的基于L2和VGG-16 网络损失的联合损失函数的有效性,本文比较了两者的性能,结果如表3 所示。可以看出,联合损失函数在PSNR、SSIM 和FSIM 的指标优于单一的L2损失。

表3 不同损失函数的性能对比
综上,本文算法不仅在视觉效果上有更优的观感,而且在客观指标上性能也更好,PSNR、SSIM和FSIM 指标证明了融合图像与源图像有很强的相关性。清晰、高度相关的图像可以帮助医生更好地准确治疗,因此所提的融合算法在该领域有一定的作用和参考价值。
3 结语
本文提出了一种结合扩张金字塔特征提取的算法用于脑部医学图像融合。扩张型金字塔对原始多模态图像特征的浅层和深层特征的结合,防止了图像边缘细节的丢失。特征融合中提出了改进的FER 特征融合策略,实验结果表明有更好的观感,能够保留更多的图像细节信息。本文利用特征重构器还原出融合图像,提出一种基于L2损失和VGG-16 网络损失的联合损失函数,进一步学习图像的细节信息。大量的实验表明,与参考算法相比,本文的算法整体视觉质量比较高,在细节方面保留了更多原始多模态图像的细节信息,在客观指标如PSNR、SSIM 和FSIM 上有更好的表现。
猜你喜欢
环球时报(2022-09-19)2022-09-19
Contemporary Social Sciences(2021年5期)2021-11-22
数学小灵通·3-4年级(2021年5期)2021-07-16
少儿美术(快乐历史地理)(2019年2期)2019-06-12
今日农业(2019年15期)2019-01-03
电子制作(2018年19期)2018-11-14
童话世界(2017年11期)2017-05-17
自动化学报(2017年11期)2017-04-04
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
