
基于SegFormer的钛板缺陷涡流C扫描检测图像分割
2024-04-26 15:48李肇源叶波邹杨坤包俊曹弘贵
化工自动化及仪表 2024年2期
李肇源 叶波 邹杨坤 包俊 曹弘贵

基金项目:云南省基础研究计划(批准号:202301AS070052)资助的课题:云南省中青年学术和技术带头人后备人才基金(批准号:202305AC160062)资助的课题。
作者简介:李肇源(1996-),硕士研究生,研究方向为电磁无损检测。
通讯作者:邹杨坤(1994-),助教,研究方向为电磁无损检测、结构健康监测,zouyangkun@kust.edu.cn。
引用本文:李肇源,叶波,邹杨坤,等.基于SegFormer的钛板缺陷涡流C扫描检测图像分割[J].化工自动化及仪表,2024,
51(2):181-191.
DOI:10.20030/j.cnki.1000-3932.202402006
摘 要 为了获得涡流检测图像中缺陷的形状与长度信息,对检测图像进行图像分割是其中一种重要的方法。由于边缘效应的影响,TA2钛板涡流C扫描图像中缺陷区域边缘模糊、对比度低,导致通过图像分割后估计的缺陷长度与实际值差别过大,难以通过图像分割方法对缺陷长度进行准确估计。针对此问题,提出一种基于SegFormer的钛板缺陷涡流检测图像分割方法。首先,利用涡流C扫描成像获得TA2钛板表面裂纹缺陷检测图像数据集;根据SegFormer网络的结构组成,设计基于SegFormer钛板缺陷涡流检测图像的分割框架和分割流程,并进行网络参数的设置。随后,利用钛板表面裂纹缺陷检测图像数据集对4个分割模型分别进行训练和测试,并利用平均交并比、平均精度和训练时间对其分割效果进行评价。实验表明:相比于Deeplabv3+、Swim Transformer和OCRNet,SegFormer具有更好的分割效果,更快的训练速度。可视化和定量化结果表明:与非深度学习方法相比,该方法具有更小的缺陷长度估计误差。
关键词 深度学习 SegFormer 钛板缺陷 电涡流检测 图像分割
中图分类号 TP391 文献标志码 A 文章编号 1000-3932(2024)02-0181-11
钛及其合金综合性能优异,耐热性、耐蚀性、弹性、抗弹性和成型加工性良好[1],被广泛应用于航空航天、石油化工、生物工程等领域,其中板材应用最为广泛,约占钛材总消耗量的50%[2]。钛板生产过程中容易产生各种缺陷,其中,当板材表面存在残留氧化层时,其与基体相比塑性较差,冷轧时沿轧向出现一系列小孔洞,轧制后会产生大量条状裂纹[3]。产生的裂纹缺陷可能会对钛板的使用产生恶劣影响,造成严重的安全问题。
为了确保钛板的安全使用,对钛板进行无损检测十分必要。涡流检测是常用的一种无损检测方法,该方法具有的效率高、成本低、非接触性、易于对检测结果进行数字化处理等优点,使涡流检测成为钛板缺陷检测的理想方法[4]。为了获得钛板缺陷的形状与长度信息,对钛板缺陷涡流检测图像进行图像分割是其中一种重要的方法。图像分割的基本思想是利用图像中的空间结构信息、颜色及纹理等信息,把图像分成若干个特定的、具有独特性质的区域,并提取感兴趣目标的技术和过程。随着对图像分割方法的不断深入研究,出现了阈值分割、聚类分割、基于邊缘检测的分割方法等早期分割算法。文献[5]针对生产线上金属板表面光照不均匀和白、灰细颗粒相间的特点,将一维、二维Wellner自适应阈值算法应用到这种场景,并结合高斯加权距离,提出一种针对金属板表面图像分割的高斯加权自适应分割算法,可对金属板表面白、灰相间的现象进行有效地滤除,提高分割精度。文献[6]针对TA2钛板涡流C扫描图像中缺陷区域与背景区域混杂,边缘对比度低的问题,提出基于简单线性迭代聚类(Simple Linear Iterative Cluster,SLIC)超像素算法和密度聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)算法的涡流C扫描图像分割方法,实现了与传统图像分割方法相比,更加精确的分割。
近几年,基于深度学习的图像分割方法逐渐代替其他图像分割算法。与非深度学习分割算法不同,深度学习方法通过多层神经网络自动提取有效特征,特别是神经网络模型可以提取包含局部细节的特征图像,以及图像的高级语义特征。深度学习方法自然地被引入到金属表面缺陷图像分割中。文献[7]设计一种用于分割小样本金属表面缺陷图像的三重图推理网络,将小样本金属表面缺陷分割问题转化为缺陷区域和背景区域的小样本语义分割问题,提高工业场景下的图像分割性能,并通过广泛的对比实验和消融实验,证明了方法的有效性。文献[8]针对铝板缺陷涡流检测图像存在背景噪声干扰的问题,提出基于改进生成对抗网络的铝板缺陷电涡流检测图像分割方法,并通过与传统的图像分割方法进行对比,证明了所提方法的先进性。文献[9]设计了一种采用高分辨率隧道磁阻(TMR)阵列传感器的涡流检测系统,开发了针对该系统所成图像的图像分割算法,实现了铝板表面缺陷涡流检测图像的分割,且具有较小的定量化误差。可以看出,基于深度学习的分割方法是目前金属检测图像分割的主流方法。作为分割方法的主流,基于深度学习的图像分割方法以平均交并比(Mean Intersection over Union,MIoU)即真实值和预测值的交集和并集之比,作为衡量图像分割算法的一项重要指标,较高的MIoU代表着更好的分割效果。近几年,研究者们以提高自己方法在分割公共数据集上获得更高的MIoU为目标,随之出现了许多高精度的分割方法,首先是文献[10]提出Vision Transformer(ViT)网络,此网络通过引入Transform[11]
框架将公共数据集ADE20K[12]的MIoU精度第1次提升到50%,超过了之前主流网络HRnet[13]和
OCRNet[14]的效果;再是Swin Transform[15]对ViT进行了改进,取得了更高的MIoU值。然而,这些方法是利用更加庞大的计算量来换取更高的MIoU,训练和使用这些方法往往需要更高的硬件配置以及更长的训练时间。针对此问题,文献[16]提出了SegFormer网络,凭借对Transform框架的再次深层次优化,在获得更高精度的前提下极大地提升了网络模型的实时性与鲁棒性,并减少了高分辨率图像的训练时间。
由于边缘效应的影响,TA2钛板涡流C扫描图像中缺陷区域边缘模糊、对比度低,导致通过图像分割后估计的缺陷长度与实际值差别过大,难以通过图像分割方法对缺陷长度进行准确估计。因此,笔者基于SegFormer网络,提出一种钛板缺陷涡流检测图像分割方法。
1 SegFormer概述
SegFormer是基于Transformer的高效率、高性能、轻量级的分割模型。图1为钛板缺陷涡流检测图像分割所采用的SegFormer网络结构,它主要由编码器和解码器两部分组成。编码器利用金字塔思想,采用分级Transformer Block[11]生成高分辨率粗特征和低分辨率细特征;解码器为一个轻量级的多层感知机(Multilayer Perceptron,MLP)解码器,融合这些多级特征,生成最终的分割掩膜。SegFormer具有相同的结构但不同体量的6个网络模型SegFormer-B0~SegFormer-B5。SegFormer-B0结构紧凑、效率高,是用于快速分割的轻量级网络模型;而SegFormer-B5是用于最佳性能的最大模型,编码器规模最大,虽然具有更高的精度,但是对训练环境的硬件有较高要求。因此,笔者选取参数数量最少的SegFormer-B0网络模型,后续仅对SegFormer-B0进行介绍。
SegFormer-B0模型参数见表1[16]。
1.1 SegFormer的编码器
SegFormer的编码器由4个Transformer Blocks组成,输入的图像在经过每个Transformer Block之后得到的特征图的分辨率分别变为输入图像的、、、,这4个不同分辨率的特征图之后会在解码器中进行融合。如图2所示,每一个Transformer块均由Efficient Self-Attention模块、混合多层的前馈神经网络(Mix Feed Forward Networks,Mix-FFN)模块[17]和Overlapped Patch
Merging[11]模块构成。
图2 Transformer Block结构
Efficient Self-Attention类似于普通的Self-Attention[18]结构,但是使用Sequence Reduction[19]以减少计算的复杂度。假设进入该模块的图像数据维度为N×C,即N个维度为C的向量,且N=H×W,H、W分别为图像的垂直像素数与水平像素数,根据Self-Attention的计算式[18]:
Attention(Q,K,V)=SoftmaxV(1)
可以得到此时的计算复杂度为O(N)。
其中,Attention(Q,K,V)为最终得到的注意力的值;矩阵Q、K、V分别是查询向量(Query Vector)矩阵、键向量(Key Vector)矩阵和值向量(Value Vector)矩阵,Q为编码器输出的特征图,K为解码器输出的特征图,二者都代表着输入图像的特征,V为输入图像;Softmax为归一化指数函数;d为一个常数,d的设置是用于平衡“Q和K点积的量级会随着它们的维度的增加而增加,导致将Softmax函数推到具有非常小的梯度的区域”这一问题,所以只是一个帮助数值量级转换的标量,会根据具体情况设置,甚至在量级低时可以删除d。
对于缺陷图像分割来说,分割的目的是找到图像中和缺陷描述相关的局部图像,缺陷部分的特征为Q和K,整个被分割的图像就为V。
如果输入的数据是高分辨率图像,会使得计算量非常巨大。Sequence Reduction用以下方法减少序列的长度:
=Reshape,C·r(K)(2)
K=Linear(C·r,C)()(3)
输入维度为N×C矩阵K,通过一个常数r将矩阵K重塑成×(C·r)维。然后通过线性变换,将(C·r)变为C,这樣矩阵K的维度就变成了×C,计算复杂度就成为了O。每个Transformer Block中r的值见表1。
如图1、2所示,Overlapped Patch Merging使用ViT[10]中的Patch Merging方法可以将H×W×C的特征合并成×C的向量来降低特征图分辨率,能够更好地提取多级特征,用同样的方法可以得到剩下3个特征图,这些不同分辨率的特征图之后会在解码器里进行融合。
1.2 SegFormer的解码器
解码器中MLP Layer的结构如图3所示,其中,i表示第i个Transformer Block的输出。
图3 MLP Layer结构
从图1~3可以看出,来自编码器的4个不同分辨率的特征图经过一次MLP Layer后融合在一起,再经过一次MLP后获得最终结果。最终的结果也称为预测掩膜,预测掩膜覆盖于被测试图像表面得到预测结果,提取出的掩膜就是分割的最终结果。
这个轻量级的解码器结构避免了过多的计算量和复杂的调参工作,减少了对高分辨率图像的训练时间。
2 基于SegFormer的钛板缺陷涡流检测图像分割
在设置好SegFormer的训练参数后,将训练集中的检测图像及其标注图像逐一输入到SegFormer中以进行训练。训练完毕后,导出训练好的SegFormer*。将测试集输入SegFormer*,得到对应的掩膜。然后,再次对掩膜进行边缘提取,得到最终的分割结果。
基于SegFormer的钛板缺陷电涡流检测图像分割方法的具体流程如下:
a. 初始化。设置SegFormer网络训练参数,输入钛板表面缺陷检测图像数据集。
b. 零补充。输入一张分辨率为H×W维度为C的检测图像,若H与W不能被4整除,则进行零补充,使其可以被4整除。
c. Transformer编码阶段1。将经过步骤b处理的检测图像输入第1层Transformer Block中,进行下采样,获得分辨率×维度为C的特征图,并将多级特征图传递给MLP Layer。
d. Transformer编码阶段2。将步骤c得到的多级特征图输入第2层Transformer Block中,进行下采样,获得分辨率×维度为C的特征图,并将多级特征图传递给MLP Layer。
e. Transformer编码阶段3。将步骤d得到的多级特征图输入第3层Transformer Block中,进行下采样,获得分辨率×维度为C的特征图,并将多级特征图传递给MLP Layer。
f. Transformer编码阶段4。将步骤e得到的多级特征图输入第4层Transformer Block中,进行下采样,获得分辨率×维度为C的特征图,并将多级特征图传递给MLP Layer。
g. MLP解码阶段1。将步骤c~f的4张特征图分别输入MLP Layer,分别通过一次MLP后,进行一次上采样,获得4张分辨率×维度为C的特征图。
h. MLP解码阶段2。将步骤g获得的4张特征图在通道方向融合在一起,通过一次MLP后,生成预测掩膜。
i. 重复步骤b~g,直至计算不收敛。
3 实验和结果
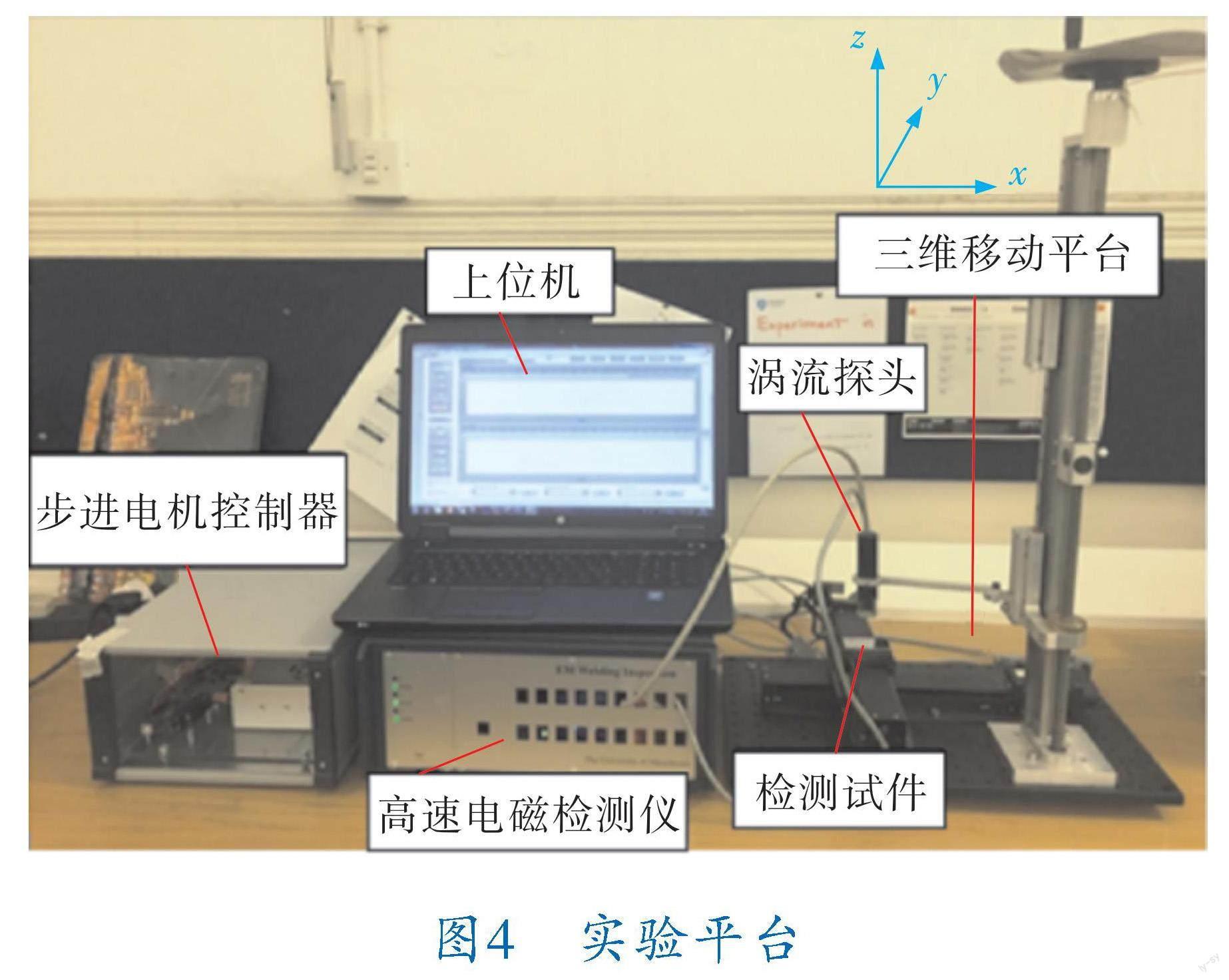
钛板缺陷涡流C扫描检测所用检测系统如图4所示,由高速电磁检测仪、涡流探头、步进电机控制器、三维移动平台与PC上位机组成。其中,高速电磁检测仪[20]由曼彻斯特大学电气与电子工程学院成像与信号处理小组自主研发,该仪器可在5~200 kHz频率下工作,并以100 kbit/s的速率进行数字解调,信噪比最高可达96 dB;平台控制器用于控制三维移动平台在试件表面移动的过程,三维移动平台用于控制涡流检测探头在被检试件表面移动。
图4 实验平台
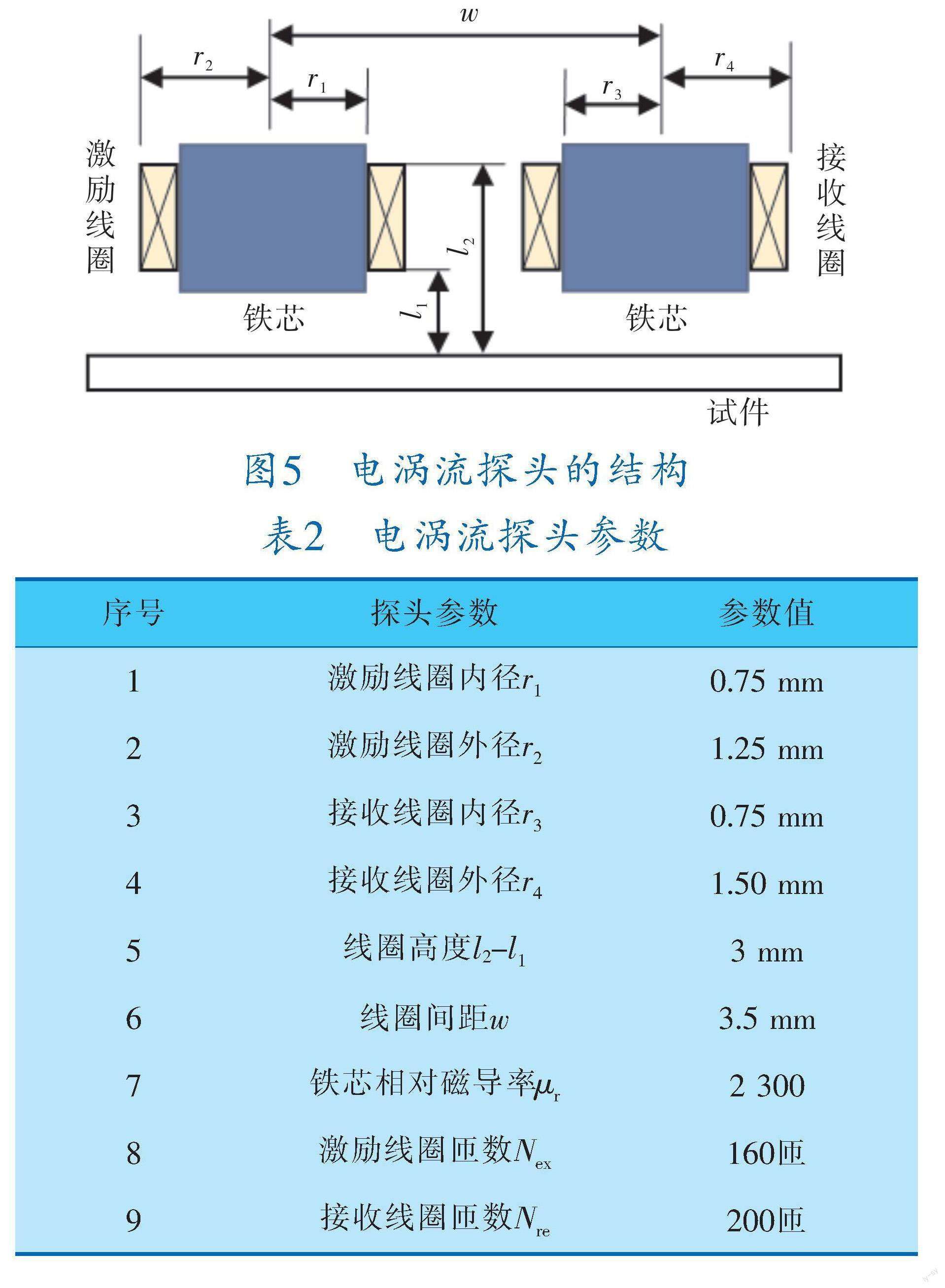
涡流探头的结构如图5所示,具体参数和尺寸见表2。实验采用的涡流探头为圆柱形激励,线圈由线径为0.08 mm的漆包铜线绕制而成,激励线圈和接收线圈绕制的匝数分别为160、200匝。
图5 电涡流探头的结构
表2 电涡流探头参数
待测试件尺寸为100 mm×100 mm×3 mm的TA2钛板(图6),该钛板试件表面平均分布有9个模拟实际金属试件中疲劳裂纹的刻槽,钛板表面缺陷的具体参数见表3,TA2钛板每一行缺陷的长度分别为4、8、12 mm;每一列缺陷的深度分别为
0.5、1.5、2.5 mm。
图6 TA2钛板
表3 试件缺陷参数
使用涡流探头对试件进行C扫描时,探头的提离高度为0.5 mm;x、y轴方向步进为0.4 mm与1.25 mm;每个裂纹扫描点数为40×20,区域为
15.6 mm×23.75 mm。为了扩充图像样本,对试件中9种缺陷在9个不同起始位置下重复扫描1次,共获得81组实验数据,扫描方式如图7所示。
图7 扫描方式示意图
试件缺陷处电导率与磁导率变化会引起涡流探头感应电压虚实部变化,将这一变化进行绘图,用图像上颜色深浅程度的变化来表示,图像中颜色或灰度的深浅代表了钛板的损伤程度,颜色或灰度越深的位置表示材料损伤越严重。为了使检测信号更加明显,使用无缺陷处的信号作参考,用检测信号减去无缺陷处的信号。数据预处理后发现,电压实部在缺陷中心位置达到最小,而虚部变化刚好相反[21]。同时还发现,相同缺陷的实部峰-峰值平均比虚部大一个数量级。这是因为实部变化主要由涡流损耗引起,与被测材料的电导率有关,而虚部主要由磁导率决定[20],钛作为一种非铁磁性材料,缺陷引起的磁导率变化很小。根据以上分析,感应电压实部变化范围较大,能更好地反映缺陷信息,因此本次实验全部使用实部信息进行处理与成像。
所获得81组数据通过Matlab软件进行绘图获得的图像样本如图8所示。另外,为了更好地对缺陷長度进行定量,利用Matlab进行图像像素插值,使所成图像分辨率达到2 375×1 560。
采用麻省理工计算机科学和人工智能实验室研发的开源图像标注工具Labelme[22]进行每个图像标注工作。图像标注是指给原始图像添加标签的过程,这些标签帮助深度学习模型在训练完成后,遇到从未见过的图像时也能准确识别图像中的内容。整幅图像表示的涡流C扫描区域长宽为23.75 mm×15.6 mm,因此可以使用软件像素尺(Pixel Ruler)辅助寻找检测图像上符合缺陷实际长度与宽度的边缘,逐像素地将缺陷边缘标记出,形成一个封闭区域,此区域为缺陷的最终标签。图9显示了训练集中随机一张图像的标注结果。
从81个图像样本中随机抽出60个样本作为
图9 涡流C扫描图像标注结果
训练集,剩余21个样本作为测试集。但在随机选取前,需保证测试集和训练集中不同编号的缺陷图像至少有1张。为了扩充样本,采用剪切与插值手段,将训练集扩充为300个样本,测试集扩充为105个样本。
本研究采用经典网络模型Deeplabv3+[23]、与SegFormer发表时间相近的分割模型OCRNet[14]以及和SegFormer同一网络架构的Swim Transformer[15]
作为对比模型,并与SegFormer形成对比实验。4个模型设置的训练参数见表4。
模型的训练时间会因电脑配置及软件版本的不同而有所区别,本研究中的所有训练都在Windows 10操作系统下运行,配置为2.20 GHz六核处理器,16 GB RAM,NVIDIA GeForce GTX 1060显卡,6 GB显存。
为了进行系统比较,采用MIoU、平均精度(Mean Accuracy,MAcc)和训练时间3个指标来衡量所有网络模型的性能。假设分割的对象有k类,那么MIoU和MAcc可由下式表示:
MIoU=(4)
MAcc=(5)
其中,P代表正样本,简单来说就是组成所要分割缺陷的像素就是正样本;相反,剩下的与缺陷无关的背景部分为N,也即负样本;TP为真正样本,表示预测结果为正样本,实际值也为正样本,预测正确;FN为假负样本,表示预测结果为负样本,实际值为正样本,预测错误;FP为假正样本,表示预测结果为正样本,实际值为负样本,预测错误;TN为真负样本,表示预测结果为负样本,实际值也为负样本,预测正确;MIoU越大,正样本分割正确的像素占除去负样本分割正确的像素后的总像素的比值越大,代表方法的分割效果越好;MAcc越大,正负样本分割正确的像素占总像素的比值越大,代表方法的分割精度越高。
各模型分割指标详见表5,可以看出,SegFormer相比Deeplabv3+、Swim Transformer和OCRNet,有着较高的MIoU和MAcc。但从训练所需时间上来看,SegFormer所需的时间是远少于其他几种网络的。
表5 各模型分割指标
在测试集中每个缺陷随机选取一张图像,使用SegFormer进行分割,结果如图10所示。
为了进一步验证SegFormer方法的有效性,将SegFormer分割结果与分割算法Otsu[24]、Canny[25]
以及SLIC超像素算法和DBSCAN算法结合的分割算法SLICD&BSCAN[6]进行对比。采用估计误差(Evaluation Error,EE)进行分割性能评估,估计误差EE的定义为:
EE=×100%(6)
其中,估计长度EL(Evaluation Length)代表所用方法分割后,对分割出的区域进行长度的测量所获得的长度信息,mm;真实长度TL(True Length)為物理意义上使用测量工具对现实的裂纹长度进行测量所获得的长度信息,mm。
从测试集中随机选取每个缺陷的检测图像各1张,共9张图像,这9张图像的分割结果如图11和表6所示,可以看出,SegFormer相对于3个非深度学习分割算法,具有估计误差较小的优势,且从整体形状来看,分割结果的宽度明显更接近试件缺陷的真实宽度。
4 结束语
针对TA2钛板表面缺陷图像中缺陷区域边缘模糊、对比度低、难以实现缺陷长度的准确估计的问题,提出一种基于SegFormer的钛板缺陷涡流检测图像分割方法,构建了基于SegFormer的钛板缺陷电涡流检测图像分割框架并进行训练与测试。实验表明,相比基于Deeplabv3+、OCRNet和Swim Transformer的分割模型,SegFormer具有0.934 8的MIoU和0.966 6的MAcc,略优于Deeplabv3+以及Swim Transformer,远高于OCRNet。从训练所需时间上来看,SegFormer所需训练时间远少于其他几种网络,具有较快的训练速度。可视化和定量化结果表明,与Otsu、Canny和SLIC&DBSCAN这3种非深度学习方法相比,SegFormer具有更小的缺陷长度估计误差。
本研究的后续工作主要针对以下3方面进行:
a. 结合涡流C扫描图像的特点,优化SegFormer分割模型,在提高分割效果的同时,增强模型的抗干扰能力。
b. 本文仅进行了TA2钛板表面裂纹缺陷图像分割,后续将进行其他金属和其他类型缺陷的检测图像分割,以进一步验证方法的普适性。
c. 开发一种可集成在涡流检测装置中的金属表面缺陷的实时成像与分割系统,用户在利用检测装置对金属表面缺陷进行检测后,可实时获得缺陷的形状与尺寸信息。
参 考 文 献
[1] 金和喜,魏克湘,李建明,等.航空用钛合金研究进展[J].中国有色金属学报,2015,25(2):280-292.
[2] 李明利,舒滢,冯毅江,等.我国钛及钛合金板带材应用现状分析[J].钛工业进展,2011,28(6):18-21.
[3] 黄德明,杨雄飞,韦青峰,等.TA17合金冷轧板材表面条状裂纹缺陷成因分析[J].钢铁钒钛,2013,34(1):26-30.
[4] CHEN X, HOU D B, ZHAO L,et al. Study on defect classification in multi-layer structures based on Fisher linear discriminate analysis by using pulsed eddy current technique[J].NDT&E International,2014,67:46-54.
[5] 薛志文,杨傲雷,费敏锐,等.用于金属板图像分割的自适应阈值算法[J].电子测量技术,2017,40(7):85-89.
[6] 陈宸,叶波,邓为权,等.基于SLIC超像素算法和密度聚类的TA2钛板表面缺陷定量化评估研究[J].电子测量与仪器学报,2019,33(11):128-135.
[7] BAO Y Q, SONG K C, LIU J, et al.Triplet-Graph Reasoning Network for Few-Shot Metal Generic Surface Defect Segmentation[J].IEEE Transactions on Instrumentation and Measurement,2021,70:1-11.
[8] 张琦,叶波,罗思琦,等.基于改进生成对抗网络的铝板缺陷电涡流检测图像分割[J].激光与光电子学进展,2021,58(8):337-345.
[9] SUN K, QI P, TAO X, et al.Vector magnetic field imaging with high-resolution TMR sensor arrays for metal structure inspection[J].IEEE Sensors Journal,2022,22(14):14513-14521.
[10] YUE X Y,SUN S Y,KUANG Z G,et al.Vision Transformer with Progressive Sampling[C]//International Conference on Computer Vision(ICCV).Piscataway,NJ:IEEE,2021:377-386.
[11] VASWANI A, SHAZEER N, PARMAR N,et al.Attention is all you need[J].Advances in Neural Information Processing Systems, 2017, 30:5998-6008.
[12] ZHOU B L, ZHAO H, PUIG X,et al. Scene parsing through ADE20K dataset[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recogn-
ition.2017:633-641.https://www.zhangqiaokeyan.com/academic-conference-foreign_meeting_thesis/0705011
251997.html.
[13] SUN K,XIAO B,LIU D,et al.Deep High-Resolution Representation Learning for Human Pose Estimation[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway,NJ:IEEE,2019:5686-5696.
[14] YUAN Y,CHEN X,WANG J.Object-contextual repr-
esentations for semantic segmentation[C]//European Conference on Computer Vision(ECCV).Glasgow,MT,UK:ECCV,2020:173-190.
[15] LIU Z,LIN Y T,CAO Y,et al.Swin transformer:Hierarchical vision transformer using shifted windows[C]//IEEE/CVF International Conference on Computer Vision(ICCV).Piscataway,NJ:IEEE,2021:9992-10002.
[16] XIE E,WANG W,YU Z,et al.SegFormer:Simple and efficient design for semantic segmentation with transformers[C]//Neural Information Processing Systems(NIPS).New Orleans,LA,USA:NIPS,2021:12077-12090.
[17] ISLAM M A,KOWAL M,JIA S,et al.Global pooling,more than meets the eye:Position information is encoded channel-wise in cnns[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE,2021:793-801.
[18] FU J,LIU J,TIAN H,et al.Dual attention network for scene segmentation[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition.Piscataway,NJ:IEEE,2019:3146-3154.
[19] WANG W,XIE E,LI X,et al.Pyramid vision transformer:A versatile backbone for dense prediction without convolutions[C]//Proceedings of the IEEE/CVF international conference on computer vision.Piscataway,NJ:IEEE,2021:568-578.
[20] XU H Y,AVILA J R S,WU F F,et al.Imaging X70 weld cross-section using electromagnetic testing[J].NDT&E International,2018,98:155-160.
[21] 包俊,葉波,王晓东,等.基于SSDAE深度神经网络的钛板电涡流检测图像分类研究[J].仪器仪表学报,2019,40(4):238-247.
[22] TORRALBA A,RUSSELL B C,YUEN J.Labelme:Online image annotation and applications[J].Proceedings of the IEEE,2010,98(8):1467-1484.
[23] CHEN L,ZHU Y,PAPANDREOU G,et al.Encoder-Decoder with atrous separable convolution for sema-
ntic image segmentation[C]//European Conference on Computer Vision(ECCV).München,BAV,Germany:ECCV,2018:801-818.
[24] OTSU N.A threshold selection method from gray-level histogram[J].IEEE Transactions on Systems Man Cy-
bernetics-Systems,1979,9(1):62-66.
[25] CANNY J.A Computational Approach to Edge Detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1986,8:679-698.
(收稿日期:2023-04-18,修回日期:2023-05-17)
Image Segmentation for Eddy Current C-scan Detection of
the Titanium Plate Defects Based on SegFormer
LI Zhaoyuana,b, YE Boa,b, ZOU Yangkunb,c, Bao Junb,c, CAO Hongguia,b
(a. Faculty of Information Engineering and Automation; b. Key Laboratory of Artificial Intelligence of Yunnan Province;
c. Faculty of Civil Aviation and Aeronautics, Kunming University of Science and Technology)
Abstract For purpose of obtaining both shape and length information of the defects in eddy current inspection images, image segmentation becomes an important method. Due to the influence of edge effects, the edge fog and low contrast ratio of the defect area in eddy current Cscan image of TA2 titanium plate causes a significant difference between the estimated defect length after image segmentation and the actual value and its difficult to accurately estimate defect length through image segmentation methods. In response to this issue, a SegFormerbased image segmentation method for eddy current testing of the titanium plate defects was proposed. Firstly, having the eddy current Cscan imaging used to obtain a dataset of surface crack defect detection images for TA2 titanium plates; and then, having the structural composition of the SegFormer network based to design a segmentation framework and process for defect eddy current detection images of titanium plates and setting network parameters; and finally, having the titanium plate surface crack defects detection image dataset employed to train and test four segmentation models, including having average intersection and union ratio, average accuracy and training time adopted to evaluate their segmentation effects. Experimental results show that, as compared to Deeplabv3+, Swim Transformer and OCRNet, the SegFormer has better segmentation performance and faster training speed. The visualization and quantification results indicate that, compared with nondeep learning methods, this scheme has smaller defect length estimation error.
Key words deep learning, SegFormer, titanium plate defect, eddy current testing , image segmentation
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
科技视界(2016年26期)2016-12-17
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
电脑知识与技术(2016年24期)2016-11-14
电脑知识与技术(2016年24期)2016-11-14
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
