
农业知识图谱构建数据集
2024-04-29 05:01陈雷,周娜,朱芃璇,袁媛
农业大数据学报 2024年1期
关键词:知识图谱


摘要:通过信息技术提高农业生产的效率、优化农业生产中的问题对我国农业发展至关重要。目前,信息技术的发展产生了海量数据,这些数据大多以碎片化、非结构化的形式分布在网络上。尤其在农业领域,使用传统搜索引擎进行信息检索难以高效准确地获取其中有价值的农业信息,往往需要消耗大量的时间和精力从海量无组织的数据中进行二次收集和整理。针对上述问题,本文通过网络爬虫技术挖掘公开的农业网站中的数据,经过自动化或半自动化数据清洗、去噪等过程,将非结构化的数据重新组合成结构化的数据,最终以知识图谱的方式进行存储。所构建的农业知识图谱数据集包括粮食作物、经济作物、水果、蔬菜等11个农业大类、共计8 481个小类的条目数据,每个小类条目对应一种农业生物或药物。具体包括粮食作物461种、经济作物2 208种、水果1 294种、蔬菜257种、食用菌118种、花木1 161种、水产142种、农药113种、农作物病虫害1 605种、兽药519种、中草药603种。根据该数据集构建的农业知识图谱三元组达到90 508条,规模较大、覆盖品类较为广泛,能够为农业知识问答、推荐系统等人机交互友好的智能应用研发提供基础数据支撑;同时,在生成式大模型中融入农业领域知识图谱,有助于在垂直领域上实现更为高效、精准的信息检索和智能决策。
关键词:农业数据;网络挖掘;知识图谱;数据集
1 引言
近些年,农业信息化的发展在网络上产生了海量数据,这些数据大多以非结构化、碎片化的形式存在,传统搜索技术难以高效准确地发现所需数据,往往需要数据需求者消耗大量的时间和精力从海量无组织的数据中进行二次收集和整理。因此,亟需一种结构化的数据表示方法以剔除无关信息并有效组织有价值的信息,从而降低信息获取、分析和应用的难度。
2012年,谷歌提出的知识图谱(Knowledge Graph)[1]采用<实体1,关系,实体2>三元组对知识进行结构化表示,构成网状的知识结构[2],可用于各类复杂场景的知识分析与智能决策,已在经济[3-4]、医学[5]、药物分析[6]等领域广泛应用。这为解决上述农业领域知识表示与信息检索的难题提供了良好的思路和参考。农业知识图谱可以实现分散数据集的相互关联与有效整合,有助于实现高效的数据检索[7]和知识推理[8],成为国内外学者持续关注的研究主题。CHEN等[9]构建的AgriKG是一个面向农业全领域的知识图谱,使用自然语言处理和深度学习技术识别非结构化文本中的农业实体和关系并链接到知识库中;许鑫等[10]通过网络爬虫技术获取小麦品种信息,对抓取的数据进行清洗、抽取、融合、实体识别、关系抽取等处理,构建了小麦品种知识图谱;张嘉宇等[11]为解决农业知识图谱对病虫害防治相关实体和关系刻画不够细致问题,构建了苹果病虫害知识图谱;陈明等[12]构建了花卉病虫害知识图谱,使得花卉病虫害知识更加规范、完整;张朋朋等[13]采用Python爬虫和OCR技术对数据进行处理,最终获得5类奶牛疫病261条数据,构建了中国奶牛疫病知识图谱。
上述研究大多构建的是某一种或某一类农业对象的知识图谱,规模相对较小,难以满足农业数据组织与搜索的需求。本研究通过网络爬虫技术快速挖掘网络数据,经过数据清洗、去噪等一系列预处理,得到包括11个农业大类、共计8 481个小类的条目数据,据此构建的农业知识图谱三元组达到90 508条,规模较大、覆盖品类较为广泛。
2 数据采集与处理方法
构建农业知识图谱数据集主要分为三个阶段:数据采集、数据预处理、数据存储。数据采集主要是确定数据的来源以及数据的挖掘;数据预处理是将挖掘的数据进行去噪、清洗等操作;数据存储是选择适当的形式存储获得的结构化数据,为后续抽取三元组、构建知识图谱做准备。
2.1 数据采集
网络上的农业数据虽然种类繁多,但是分类明确、属性清晰的结构化数据非常少。因此,在这样的条件下,构建农业知识图谱首先要筛选农业领域分类清晰且每個农业数据条目都附带有相应的属性说明的网络数据源。根据以上要求,作者在查阅众多网站后,采用“中国农业网(http://www.zgny.com/)”和“农博数据(http://shuju.aweb.com.cn/breed/breed-1-1.shtml)”这两个公开网站作为数据挖掘的来源。
同时,不同网站数据结构和属性不同,根据构建知识图谱所要求的数据完整性和类型一致性等约束条件,最终选择了11类属性条目相对完整且一致的农业数据作为构建知识图谱的数据来源。如图1所示,花卉类需要具有分类名称、品种名称、国家级审定编号等属性。数据来源确定后,使用Python语言编写脚本用于目标网页数据的爬取,其中主要采用requests和xpath库进行html页面解析并挖掘文本数据。获得的原始数据包括11个农业大类、共计8 481个小类的条目数据,具体包括粮食作物461种、经济作物2 208种、水果1 294种、蔬菜257种、食用菌118种、花木1 161种、水产142种、农药113种、农作物病虫害1 605种、兽药519种、中草药603种。
2.2 数据预处理
从网络挖掘的文本数据一般存在两个问题:一是属性及其描述通常包含在大段非结构化的文本中,且文本中包含特殊符号等噪声;二是即使数据类别相同,其包含的数据属性也是不一致的,如图2所示。因此,需要对挖掘的数据进行清洗、去噪等预处理。
首先,采用脚本语言编写正则表达式以批量去除文本中的网页标记等特殊字符,示例如图3所示,能够对英文字母大小写、阿拉伯数字、标点等特殊字符进行相应的处理。
然后,对文本使用随机采样的方式抽取每类数据中所包含的属性,进行筛选后确定每类数据最终的属性构成,如表1所示。最后,按属性名称从长文本段落中提取相应的属性描述。完整的数据预处理流程如图4所示。
2.3 数据存储
基于预处理后的数据构建知识图谱,需要进行实体识别、关系抽取等前期工作才能获得相应的三元组。为了简化这些工作,本文进一步将预处理后数据以结构化的形式进行存储,使得能够较为方便地从其中的单条数据构建出多个<实体,属性名,属性描述>或<实体1,关系,实体2>形式的三元组。如图5所示,以花木数据中虎眼万年青条目为例,可以构成<虎眼万年青,别名,海葱>、<虎眼万年青,产地,原产南非>等三元组。
3 数据内容
本文构建的农业知识图谱包含11个农业大类、共计8 481个小类的条目数据,具体每类数据的数据量如表1所示,每类数据保存在相应的JSON文件中,以大类的英文命名。
条目具体内容包括品种名称和品种属性描述,其中品种名称作为键,属性描述作为值,以字典形式存储,如图6所示。示例中,“紫云英”“小丽花”等品种名称作为键,其“别名”“产地”“习性”等属性的描述作为值,形成字典形式的结构化数据进行存储。
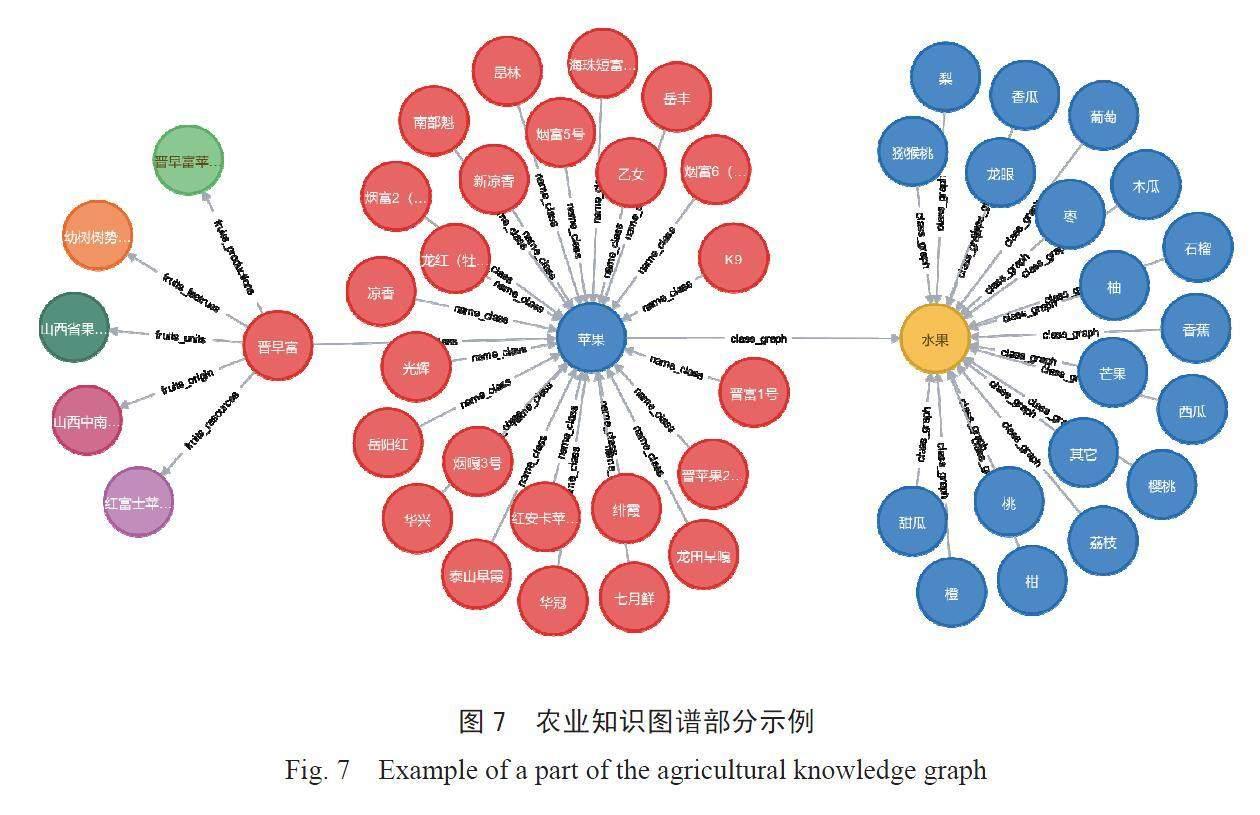
根据上述数据存储方式能够较为方便地抽取出90 508条知识图谱三元组,从而构建农业知识图谱。所构建的知识图谱部分如图7所示。
4 质量控制和技术验证
在数据采集阶段,采用多种方法控制数据质量,其中为获取到分类明确、属性清晰的农业数据,对农业领域网站进行搜索和筛选,最终选择较为专业且规范的网站作为数据来源,保证每条农业数据的来源真实可靠。
在数据预处理阶段,除了数据清洗、噪声去除等自动化方式,作者团队中还配备长期从事农业信息化研究的科研人员对所挖掘的农业数据及类别进行检查和分析,逐条检查预处理之后的文本,纠正可能存在的数据错误,包括文本噪声完全去除和数据类型及属性是否与表1一致等检查,进一步保证了数据的准确性和一致性。
在数据存储阶段,以规范的JSON格式存储数据,结构清晰,便于自动化解析和处理,提高构建农业知识图谱的效率。
在数据的技术验证阶段,首先依据此数据集构建了农业知识图谱。然后,对知识图谱中的实体和关系进行完整性检查。由于受限于数据来源网站,所构建的数据集不可避免地存在数据不完整的现象。对于原始数据中缺失的部分属性,在构建的结构化数据中相应地标注为“未知”,以便为后续知识图谱扩充或知识补全方法的研究提供标签信息。最后,为验证该数据集的有效性,搭建了基于文本分类的农业知识问答系统[14],基于构建的农业知识图谱进行答案的检索,从系统应用的角度对数据集进行验证。
5 数据价值与使用建议
目前农业知识图谱大多只包含某一种或某一类农业对象,本数据集涵盖11个大类的农业数据,共计8481个小类,根据此数据集构建的农业知识图谱规模较大、覆盖品类较为广泛。数据价值主要体现在如下两方面。
(1)直接作为知识推理研究的知识库。可在该数据的基础上利用知识补全等方法对数据进行扩充,进一步提高知识的完整性。
(2)为智能农业应用研发提供基础数据支撑。研究人员可以结合自然语言处理技术,快速搭建农业知识问答[14-15]、推荐系统[8]等应用软件。
随着生成式大模型的快速发展,在大模型中融入农业领域知识图谱,有助于在垂直领域上实现更为高效、更为精准的信息检索和智能决策。
6 数据可用性
数据库(集)的访问与获取信息如下:
中国科技资源标识码(CSTR):17058.11.sciencedb. agriculture.00016;
数字对象标识码(DOI):10.57760/sciencedb. agriculture.00016。
数据服务系统网址:https://doi.org/10.57760/ sciencedb.agriculture.00016,允许公开获取。
数据作者分工职责
陈雷,数据分析、质量控制及论文撰写指导。
周娜,数据汇总及论文撰写。
朱芃璇,数据获取、质量控制及汇总整理。
袁媛,数据分析、质量控制及論文撰写指导。
伦理声明
本文数据不涉及伦理声明相关的内容。
利益冲突声明
作者声明,全部作者均无会影响研究公正性的财务利益冲突或个人利益冲突。
参考文献
[1] SINGHAL A. Introducing the knowledge graph: things, not strings [EB/OL]. (2012-05-16) [2023-08-22]. https://blog.google/products/ search/introducingknowledge-graph-things-not/.
[2] 刘峤,李杨,段宏,等. 知识图谱构建技术综述[J].计算机研究与发展, 2016, 53(3): 582-600. DOI:10.7544/issnl000-1239.2016. 20148228.
[3] 陈晓军,向阳. 企业风险知识图谱的构建及应用[J]. 计算机科学, 2020, 47(11): 237-243. DOI:10.11896/jsjkx.191000015.
[4] 杨波,廖怡茗. 面向企业动态风险的知识图谱构建与应用研究[J]. 现代情报, 2021, 41(3): 110-120. DOI:10.3936/j.issn.1008-0821.2021. 03.011.
[5] SONG Y, CAI L, ZHANG K, et al. Construction of Chinese Pediatric Medical Knowledge Graph[C]. Joint International Semantic Technology Conference, Hangzhou, China, November 25-27, 2019. DOI:10.1007/ 978-981-15-3412-6_21.
[6] GONG F, WANG M, WANG H, et al. SMR: Medical knowledge graph embedding for safe medicine recommendation[J]. Big Data Research, 2021, 23:100174. DOI:10.1016/j.bdr.2020.100174.
[7] 王栋,周菲,李颖芳,等. 我国甜樱桃产业知识图谱构建研究[J]. 中国果树, 2023, 2023(1): 104-108. DOI:10.16626/j.cnki.issn1000-8047. 2023.01.021.
[8] 赵继春,孙素芬,郭建鑫,等. 农业在线学习资源知识图谱构建与推荐技术研究[J]. 计算机应用与软件, 2022, 39(8): 69-75. DOI:10. 3969/j.issn.1000-386x.2022.08.010.
[9] CHEN Y, KUANG J, CHENG D, et al. AgriKG: an agricultural knowledge graph and its applications[C]. Database Systems for Advanced Applications, Chiang Mai, Thailand, April 22-25, 2019. DOI:10.1007/978-3-030-18590-9_81.
[10] 许鑫,岳金钊,赵锦鹏,等. 小麦品种知识图谱构建与可视化研究[J]. 计算机系统应用, 2021, 30(6): 286-292. DOI:10.15888/j.cnki.csa. 007986.
[11] 张嘉宇,郭玫,张永亮,等. 细粒度苹果病虫害知识图谱构建研究[J]. 计算机工程与应用, 2023, 59(5): 270-280. DOI:10.3778/j.issn.1002- 8331. 2205-0556.
[12] 陈明,朱珏樟,席晓桃. 基于知识图谱的花卉病虫害知识管理方法[J]. 农业机械学报, 2023, 54(3): 291-300. DOI:10.6041/j.issn.1000-1298. 2023.03.029.
[13] 张朋朋,李全胜,孔繁涛,等. 中国奶牛疫病知识图谱构建数据集[J]. 中国科学数据, 2023, 8(2): 257-264. DOI:10.11922/11-6035.nasdc. 2022.0011.zh.
[14] ZHU P, YUAN Y, CHEN L, et al. Question answering on agricultural knowledge graph based on multi-label text classification[C/OL]. Seventh International Conference on Cognitive Systems and Information Processing (ICCSIP2022), December 17-18, 2022, Fuzhou. DOI:10.1007/978-981-99-0617-8_14.
[15] 封晨,楊文,孙冠群. 基于知识图谱的智能问答系统研究[C]. 第三十七届中国(天津)2023I、网络、信息技术、电子、仪器仪表创新学术会议,天津, 2023. DOI:10.26914/c.cnkihy.2023.022844.
引用格式:陈雷,周娜,朱芃璇,袁媛.农业知识图谱构建数据集[J].农业大数据学报,2024,6(1): 1-8. DOI: 10.19788/j.issn.2096-6369.100002.
CITATION: CHEN Lei, ZHOU Na, ZHU PengXuan, YUAN Yuan. A Dataset for Constructing Agricultural Knowledge Graph[J]. Journal of Agricultural Big Data, 2024,6(1): 1-8. DOI: 10.19788/j.issn.2096-6369.100002.
A Dataset for Constructing Agricultural Knowledge Graph
CHEN Lei1,2, ZHOU Na1, ZHU PengXuan2, YUAN Yuan1,2*
1. School of Electronic and Information Engineering, Anhui Jianzhu University, Hefei 230601, China; 2. Institute of Intelligent Machines, Hefei Institutes of Physical Science, Chinese Academy of Sciences, Hefei 230031, China
Abstract: Improving the efficiency of agricultural production and optimizing the problems in agricultural production through information technology is crucial for the development of agriculture in China. At present, the development of information technology has generated massive amounts of data, which are mostly distributed on the Internet in fragmented and unstructured forms. Especially in the domain of agriculture, using traditional search engines for information retrieval is difficult to efficiently and accurately obtain valuable agricultural information, often requiring a lot of time and effort to collect and organize secondary data from massive unorganized data. To address the above issues, this paper utilizes web crawler technology to mine data from publicly available agricultural websites. Through automatic or semi-automatic data cleaning, denoising, and other processes, unstructured data are recombined into structured data, which is ultimately stored in the form of a knowledge graph. The dataset for constructing agricultural knowledge graph includes item data for 11 agricultural categories, such as grain crops, cash crops, fruits, vegetables, etc. Specifically, it includes 461 types of grain crops, 2 208 types of cash crops, 1 294 types of fruits, 257 types of vegetables, 118 types of edible fungi, 1 161 types of flowers and trees, 142 types of aquatic products, 113 types of pesticides, 1 605 types of crop diseases and pests, 519 types of veterinary drugs, and 603 types of Chinese herbal medicines, totaling 8 481 subcategories. The agricultural knowledge graph constructed based on this dataset has 90 508 triplets, which can provide basic data support for the development of human-machine interactive intelligent applications such as agricultural knowledge Q&A and recommendation systems. Meanwhile, integrating agricultural knowledge graph into generative large language models can help achieve more efficient and accurate information retrieval and intelligent decision-making in vertical domains.
Keywords: agricultural data; network mining; knowledge mapping; datasets
猜你喜欢
现代情报(2016年11期)2016-12-21
现代情报(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
现代情报(2016年10期)2016-12-15
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
中国远程教育(2016年9期)2016-11-19
商场现代化(2016年23期)2016-11-17
中国教育信息化·基础教育(2016年9期)2016-10-18
电脑知识与技术(2016年7期)2016-05-19
