
基于深度学习无人机影像道路实景三维修复
2024-05-03 22:28蒋萧,邱春霞,张春森,郭丙轩,帅林宏,彭哲,贾欣
西安科技大学学报(社会科学版) 2024年1期
关键词:深度学习
蒋萧,邱春霞,张春森,郭丙轩,帅林宏,彭哲,贾欣


摘要:针对基于无人机倾斜影像实景三维重建中,移动目标对道路实景三维重建造成几何变形和纹理失真的问题,提出一种基于深度学习的无人机影像道路实景三维修复方法。首先,通过添加注意力机制的深度学习网络模型YOLOv8对影像中目标进行检测;其次,在得到影像对应目标标记的基础上,根据已生成三维Mesh模型中各三角面在可视影像集合中的投影位置,结合影像所标记目标的对应范围,统计各三角面的类别信息以此判定移动目标;最后,利用移动目标判定结果对移动目标造成的三维模型几何变形及纹理错误进行修复,实现道路实景三维重建。结果表明:改进的网络模型较YOLOv4、YOLOv5和YOLOv8模型,平均精度(mAP)值平均提升10.82%,移动目标判定准确率达97.43%。与流行国外商业软件相比,所提方法重建修复效果更佳,自动化程度更高。
关键词:实景三维重建;深度学习;Mesh模型;遮挡剔除;纹理修复
中图分类号:P 231文献标志码:A
文章编号:1672-9315(2024)01-0175-10
DOI:10.13800/j.cnki.xakjdxxb.2024.0118开放科学(资源服务)标识码(OSID):
3D restoration of road real scene based on deep learning for UAV imagesJIANG Xiao1,QIU Chunxia1,ZHANG Chunsen1,GUO Bingxuan2,SHUAI Linhong1,PENG Zhe3,JIA Xin3
(1.College of Geomatics,Xian University of Science and Technology,Xian 710054,China;2.State Key Laboratory of Information Engineering in Surveying Mapping and Remote Sensing,Wuhan University,Wuhan 430079,China;3.Wuhan Xuntu Shikong Software Technology Co.,Ltd.,Wuhan 430223,China)
Abstract:In order to address the problems of geometric deformation and texture distortion caused by moving targets on the road 3D Real Scene model based on UAV oblique photography,a restoration method of the road 3D Real Scene model is proposed using deep learning.Firstly,the YOLOv8 network,involving the attention mechanism,was employed to detect objects in the image.Secondly,based on the detected objects range,the presence of moving targets was determined by analyzing the category information of each triangular face in the mesh,according to its projection position in the visual image set.Finally,the geometric deformation and texture distortion of the 3D model were restored from the results of moving targets determination to achieve the road 3D Real Scene model reconstruction.The results indicate that the improved network enhances the mAP by an average of 10.82% over YOLOv4,YOLOv5 and YOLOv8.Furthermore,the accuracy of moving targets determination is 97.43%.Additionally,in contrast to commercial software,the proposed method demonstrates a superior restoration effect and a higher level of automation.
Key words:reality 3D reconstruction of real scene;deep learning;Mesh model;occlusion culling;texture restoration
0引言
“實景三维”是国家新型基础设施的重要组成部分,它为国家经济社会发展和各部门信息化提供统一的空间基底。倾斜摄影三维模型是实景三维地理场景表达的重要方式之一,精确的几何结构反映模型的真实形态,丰富的纹理特征表现模型的真实外观[1]。而道路场景中移动目标的存在易导致影像匹配困难,以致造成道路模型几何扭曲以及纹理失真。以往采取全人工或半人工的方式对重建后的模型进行手动修复,此过程费时费力。因此如何消除移动目标对道路三维模型重建的影响,提高道路实景三维重建的自动化程度是一个非常重要且具有实际应用价值的问题。
道路三维场景修复包括几何和纹理修复,几何修复主要是修复道路上移动目标造成的几何模型变形,纹理修复主要处理移动目标造成的纹理遮挡。道路实景三维中的遮挡分为遮挡物已经被重建出来(固有遮挡)以及遮挡物未被重建出来(移动遮挡)2类,有效地从多视影像中检测出2类遮挡是问题研究的第1步,对于第1类遮挡,由于模型已被重建出来,处理这类遮挡相对容易,目前已有比较成熟的算法,比如针对建筑物被遮挡问题,刘亚文等通过边缘提取的方法剔除了建筑物立面上的遮挡[2];贾成栋针对智能汽车采集并建立的城市街景模型,用语义分割的方法找到模型上的前景和建筑物背景,并用深度学习的方法对建筑物纹理进行学习训练,以解决建筑物模型被前景遮挡的问题[3];李妍妍也提出了将三维模型映射到二维纹理影像中以实现对密集建筑物遮挡的处理[4]。然而这些方法都无法判断道路场景中由移动车辆、行人等造成的遮挡,为此SINHA等提出依据影像的色调信息来识别此类被遮挡区域,并利用相邻影像上没有被遮挡的相同区域内像素的平均颜色值对该区域进行补偿[5]。但若样本中含有大量异常值,求得的平均值会与真实的平均值相差甚远,从而会导致判断失误。自HINTON提出采用神经网络对数据中的高层特征进行学习以来[6],基于深度学习的目标检测成为研究热点,在移动目标检测领域出现了一大批获得成功的基于深度学习检测方法,但这些流行算法面对基于无人机倾斜影像道路中小移动目标检测以及大规模实景三维数据处理仍存在方法难以胜任,以及运行消耗资源多等问题[7]。
首先基于深度学习改进的YOLOv8[8](You Only Look Once version 8)算法对影像中目标信息进行检测,在得到影像所对应的目标信息标记的基础上,根据已生成三维Mesh模型中各三角面在可视影像集合中的投影位置,结合影像所标记目标的对应范围,统计各三角面的类别信息以此判定影像所识别目标移动与否,通过剔除移动目标所标记的三角面及移动目标三维模型错误纹理实现道路三维场景的修复。
1研究方法
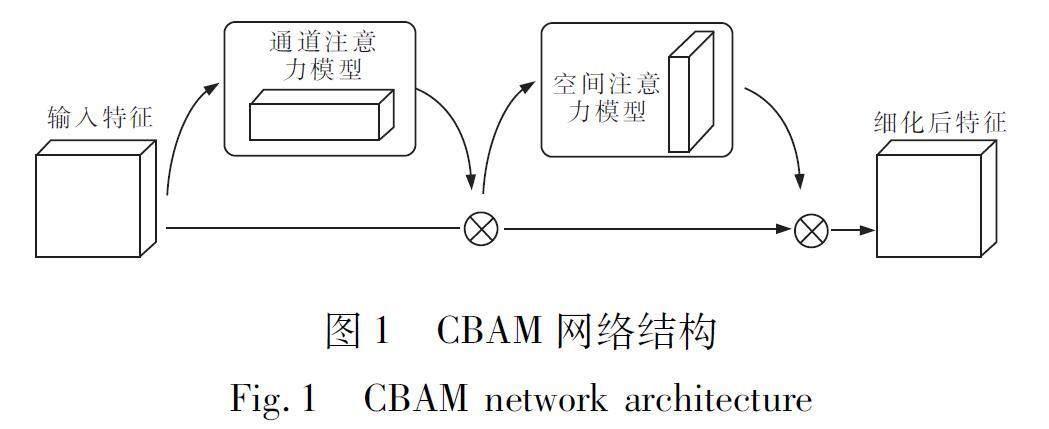
1.1基于YOLOv8改进算法无人机影像移动目标检测基于无人机倾斜影像进行道路实景三维建模,存在无人机飞行不稳定、检测目标小,且影像包含大量的地理元素,致使目标和背景不易区分等问题,因此对此类影像进行目标检测极具挑战性[9-10]。YOLOv8是目前YOLO系列算法中最新推出的目标检测算法,由Darknet-53特征提取网络、PAN-FAN特征融合网络和Decoupled-Head解耦头构成,分为输入(Input)、骨架(Backbone)、颈部(Neck)和输出(Head)4个部分。随着网络的加深,感受野持续增大,而特征图的尺寸减小,特征逐渐抽象,语义特征减弱,小目标位置信息变得越来越模糊,使得小目标的精确检测变得困难[11]。为有效实现对无人机倾斜影像道路中汽车、摩托车和人等小目标的检测,在原YOLOv8算法中增加注意力机制,通过训练和学习使模型聚焦于关键信息,即在YOLOv8网络结构的基础上增加结合特征通道和特征空间2个维度的注意力机制模块(Convolutional Block Attention Module,CBAM)[12],其中通道注意力模型可以為不同的特征通道,例如汽车、摩托车和人等特征通道赋予不同权重,得到一维通道权重向量;而空间注意力模型则可为每个特征通道中的每个特征空间赋予不同权重,生成二维空间权重向量;最后将二维空间权重向量与特征通道相乘,得到优化后的特征图,CBAM模块网络结构如图1所示[13]。
在YOLOv8网络中,经过Darknet-53网络粗提取后的特征图输入至Neck端进行特征融合,由于特征融合效果直接影响后续的检测精度,为了提升特征信息的融合效果,文中在Neck端上采样部分的Upsample结构前以及下采样部分的C2f模块后嵌入了CBAM模块[14]。改进后的YOLOv8网络结构如图2所示。
由于CBAM是轻量级的通用模块,因此可以忽略该模块的开销[15]。增加了CBAM模块之后的YOLOv8模型分别沿特征空间和特征通道重新校准特征图后合并输出,从而有效增强了模型对空间和通道两方面有效信息的关注,提升了模型的表现能力,进而增强了对后续移动目标判定结果的准确性。
1.2基于多视影像约束的移动目标判定
首先利用获得的无人机倾斜影像和影像位姿数据,采用运动结构恢复(Structure from Motion,SfM)算法[16],计算三维几何结构和相机姿态,生成稀疏的高精度三维点云。然后基于PatchMatch的多视图密集匹配算法[17]计算每张图像的深度图,并基于加权最小二乘算法选定每个视点的最优高程值,构成精密的三维点云。最后采用基于狄洛尼三角剖分的曲面重建方法对点云进行网格化,生成Mesh模型。
在基于无人机倾斜影像道路三维重建的过程中,当道路存在移动车辆等动态目标时,构建的三维模型会出现几何结构变形甚至缺失的现象[18],如图3(a)道路无人机倾斜影像中黄色车辆为静止车辆,其余车辆均为移动车辆,由图3(b)道路三维重建Mesh模型中可以看出,只有静止的黄色车辆建立起了对应三维模型,白色货车只构建了部分的三维模型,其他移动车辆三维建模均告失败。
基于多视影像约束的判定移动目标算法流程图如图4所示。
使用深度学习网络识别无人机影像中的汽车、摩托车和人等目标,再将识别出的目标范围像素坐标(u,v)反投影至Mesh网格中得到对应的三维点坐标(XW,YW,ZW),此反投影过程依赖于相机投影矩阵(P矩阵),该矩阵描述了物方坐标系到相机坐标系的映射关系,投影关系可表示为
u
v
1=1ZcPXW
YW
ZW
1(1)
式中(XW,YW,ZW)为点云的在世界坐标系下的三维坐标;Zc为物方点在相机坐标系下的z轴坐标;P矩阵构成可表示为
P=K[R|T]=fx0u0
0fyv0
001[RωRRK|-RC](2)
式中K为相机内参矩阵;fx与fy分别代表相机在x轴和y轴方向上的焦距;(u0,v0)为像主点坐标;R为旋转矩阵,Rω,R,RK分别是3个坐标轴方向上的旋转分量;T为平移量;C为摄影中心坐标。
得到三维点坐标后,统计三维点坐标所在三角面候选影像中包含该目标的比例。如果比例低于80%,可以判断该目标为移动目标,生成所有可视影像对应的移动目标掩膜影像,用于后续模型修复过程。
1.3道路实景三维修复
1.3.1几何修复
实景三维道路几何修复包括移动目标覆盖区范围确定、覆盖区错误网形删除和移动目标覆盖区Mesh网格重建3部分,考虑到道路上移动目标所占区域通常不是很大,对整体三维重建的网形不会有明显影响。文中直接将其覆盖区内的三角面删除,再对删除后形成的空洞进行修补,以达到重建Mesh网格的目的[19]。
首先在篩选出移动目标覆盖区的基础上,将覆盖区掩膜投影至成块分布的Mesh网格上,并对其做删除操作,其次通过Mesh网格块中三角形各边之间的邻接关系确定洞的边界(删除后的块区域可能会形成一个洞),在确定洞边界后进行补洞操作,操作步骤如下
1)找到孔洞的边界,计算边界边的平均长度l;
2)计算每个边界点相邻边界边之间的夹角,找到夹角最小边界点,计算它的2个相邻边界点的距离s,判断s<2×l是否成立,如果成立,则按图5(a)所示增加一个三角形;反之,则按图5(b)所示增加2个三角形;
3)更新孔洞的边界集合;
4)重复步骤(2)(3),直到完成孔洞修复。
另外,由于修补前后该区域的三角面始终位于道路平面,且始终对边界边进行操作,因此该方法能够保证修复前后该区域模型粗差较小,且修补后该区域不会产生非流形点或非流形边。
1.3.2纹理修复
纹理映射实质是将二维纹理影像映射到三维模型表面,纹理映射过程包括遮挡判断、最佳纹理源选择、匀光匀色和纹理打包等内容[20-21]。纹理修复流程如图6所示。
在基于倾斜影像实景三维重建中,Mesh模型的每个三角面都有一个可视影像列表,它记录了该三角面对应的所有可视影像[22]。对遮挡问题的处理通常包括在可视影像列表中直接删除遮挡影像和依据遮挡影像得分进行惩罚2种方式。采取基于得到的移动物体信息在可视影像列表中将包含遮挡的影像删除的方式,即采用影像一致性检验方法来剔除移动物体遮挡[23-26]。判断三角面是否被掩膜影像遮挡,认为只要三角面中的一个像素上有移动物体,则对应影像对三角面造成遮挡,即将其从三角面的可视影像列表中剔除。
在遮挡判断完成后,从可视影像列表中选择最佳影像就成为一项重要工作。最佳影像需满足2个基础条件:一是分辨率较高;二是相邻三角面间最佳影像相似度较高。除上述2个条件外,还需保证同一平面的三角面尽可能选择相同的影像。为此采用角度和面积约束的图割算法构建能量函数计算影像的得分情况,根据得分情况选择最佳影像。能量函数如下式
E(f)=Edata(f)+Esmooth(f)(3)
式中f为当前纹理块ID;数据项Edata(f)为当前三角面和备选纹理块间的符合程度;平滑项Esmooth为不同纹理块间的一致性程度。数据项计算公式如下
Edata(f)=KdataAreanor×|nnor×s|(4)
式中K为数据能的最大值;Areanor为将当前三角面投影到备选纹理块所在平面上的归一化面积;nnor为当前三角面归一化法向量;s为备选纹理块投影平面归一化主光轴的方向向量。由式(4)可知,投影面积越大且夹角越小的三角面数据能越小,纹理块得分越高[27]。
对于平滑项,判断相邻三角面所选影像是否相同。若相同,平滑能为0;若不同,平滑能取最大值。
经图割运算后,每个三角面对应的唯一一张影像,认为是其最佳影像。接着通过建立像素坐标和纹理坐标的转换关系,可实现纹理映射过程,转换关系表示如下
x=u×w
y=(1-v)×h(5)
式中(u,v)为纹理坐标;(x,y)为像素坐标;w和h分别为纹理图的宽和高[28]。
2试验与结果
2.1基于YOLOv8改进算法道路目标检测
2.1.1数据介绍
模型训练所用数据集为包含大量城市道路场景的开源数据集VisDrone、VOC以及自拍无人机倾斜影像制作数据集,其中倾斜影像数据集的相关信息见表1。将城市道路上可能涉及的移动遮挡物分为汽车、摩托车、人3类,按8∶2的比例将每组数据分为训练集和测试集[29],并对选择的影像用LabelMe工具标注。
2.1.2试验平台及评价指标
试验基于Windows 10操作系统,采用GPU为NVIDIA GeForce GTX 2060,内存为16 GB,使用Adam优化器在PyTorch中实现。采用召回率(Recall)、精度(Precision)、平均精度(Average Precision,AP)和mAP[30]作为目标检测的评价指标。Recall和Precision计算公式如下式
Precision=tptp+fp(6)
Recall=tptp+fn(7)
式中tp为目标被正确预测为车辆的个数;fp为目标被错误预测为车辆的个数。
对Precision-Recall曲线进行平滑处理,即采用每个点右侧最大的Precision值作为该点Precision值。得到psmooth(r),然后通过数值积分计算出psmooth(r)曲线下的面积即为AP值。计算公式如下式
AP=∫10psmooth(t)dr(8)
对所有类别的AP值求平均即可得mAP值,计算公式如下式
mAP=∑Ki=1APiK(9)
式中K为检测目标类别总数。
2.1.3结果对比
为验证文中改进的YOLOv8模型及CBAM模块的有效性,现移除算法网络中该模块结构,将其与YOLOv4、YOLOv5模型进行目标检测消融试验,试验结果见表2,由表2可知:改进的YOLOv8模型相较于YOLOv4、YOLOv5以及YOLOv8模型,mAP值分别提升1220%、7.85%、12.40%,特别是在行人和摩托车的检测性能上表现出色,图7为YOLOv4、YOLOv5和YOLOv8模型与改进的YOLOv8模型道路目标检测结果,其中影像1,4内部右侧为对人的检测结果;影像2内部上方为对摩托车的检测结果;影像3,4内部的右侧为对汽车的检测结果,左侧则显示对被树木遮挡的汽车检测结果。从图7可以看出,改進的YOLOv8模型更好地检测出了汽车等大型移动目标,尤其对被树木遮挡的汽车的检测效果更优。同时,对小型移动目标,如人、摩托车等目标的检测表现也更为出色。
2.2道路移动车辆判定
基于多视影像约束的移动车辆判定算法对影像中道路上运动车辆及人进行检测,结果如图8所示(从上至下车辆编号为1~8),其中图8(a)为在影像上采用外框标记的目标检测结果,人采用绿色矩形框标记,车辆采用红色矩形框标记;采用第1.2节算法进行移动车辆判定,同时认为所有行人和摩托车均对影像纹理造成遮挡,生成移动目标对应掩膜图像,如图8(b)所示。表3为影像中各车辆被投影覆盖的三角面的候选影像中存在该车辆的比例统计,以超过80%比例为阈值对移动车辆进行判定,根据表3数据得出,车辆8为静止车辆。
为验证文中移动目标检测和判定效果,在数据集1和数据集2中随机选取3张包含道路的无人机影像对其进行目标检测和移动目标判断(图9(a)),图9(b)为影像目标检测结果,图9(c)为其移动目标对应掩膜影像,表4为3张无人机影像目标检测结果统计。
从表4可以看出,影像1上的所有车辆均被检测到,影像2上有2辆车未被检测到,影像1和影像2所有移动车辆均被正确判断;影像3上有2辆车未被检测到,且有2辆移动车辆未被正确判定。以上结果表明,在目标检测到的所有车辆中,移动目标判定算法的平均正确率为97.43%。
2.3几何修复
几何修复包括移动目标覆盖区范围确定、移动目标覆盖区三角面删除、移动目标覆盖区网格补洞3个主要过程。根据移动目标掩膜结果确定移动目标覆盖区,删除覆盖区内所有三角面,最后用文中1.3.1节所示算法进行补洞操作。图10为数据集2中某局部场景修复前纹理模型和白模。
图11(a)为图10移动目标覆盖区删除结果,图11(b)为其补洞结果,图11(c)为几何修复后的白模,图11(d)为几何修复和纹理修复后的实景三维模型。
从图11(c)可以看出,通过补洞算法得到的移动车辆覆盖区三维Mesh模型更加贴近真实情况,同时也为后续纹理修复奠定了基础;以及从图11(d)可以看出,对于修复后的移动车辆覆盖区,其纹理在经过遮挡剔除后也得到相应的改善。
2.4纹理修复
图12、图13分别为2组数据(局部)剔除移动车辆前后结果对比。从图12可以看出,文中算法对移动车辆的去除基本达到80%以上,从模型多个角度可以看出,修复后模型道路区域更加平整真实;从图13可以看出,文中算法对行人密集的区域能够较好地剔除遮挡,遮挡去除后模型的视觉效果明显变好,在一定程度上消除了移动物体遮挡导致模型质量不佳的情况。
图14、图15为文中算法与商业软件ContextCapture实景三维建模效果对比。从图14和图15可以看出,文中算法在2组数据上的表现均较ContextCapture建模好,经过文中算法剔除纹理遮挡后的模型减少了由于移动物体遮挡导致的纹理拉花现象的发生。
3结论
1)改进的YOLOv8模型较YOLOv4、YOLOv5和YOLOv8模型,mAP值分别提升了12.20%、785%、12.40%,且基于目标检测结果进行移动目标判定准确率为97.43%。
2)采用的几何修复和纹理修复方法使得修复后的模型与国外三维重建商业软件的重建效果相当,个别处甚至效果更佳,有效地解决了无人机倾斜影像实景三维重建过程中的移动目标干扰问题。
参考文献(References):
[1]王维,王晨阳.实景三维中国建设布局与实现路径思考[J].测绘与空间地理信息,2021,44(7):6-14.
WANG Wei,WANG Chenyang.Thoughts on real scene three-dimensional China construction layout and realization path[J].Geomatics & Spatial Information Technology,2021,44(7):6-14.
[2]刘亚文,关振.街景建筑物立面纹理遮挡恢复方法研究[J].武汉大学学报信息科学版,2010,35(12):1457-1460.
LIU Yawen,GUAN Zhen.Occlusion removal for building facade texturing[J].Geomatics and Information Science of Wuhan University,2010,35(12):1457-1460.
[3]贾程栋.面向城市智能汽车的场景多模真实感重建技术研究[D].成都:电子科技大学,2020.
JIA Chengdong.Research on multi-mode photorealistic reconstruction technology for urban smart car[D].Chengdu:University of Electronic Science and Technology of China,2020.
[4]李妍妍.基于倾斜摄影三维模型纹理遮挡研究[J].测绘与空间地理信息,2019,42(9):178-180,185.
LI Yanyan.Research of 3D model texture occlusion based on oblique photography[J].Geomatics & Spatial Information Technology,2019,42(9):178-180,185.
[5]SINHA S N,STEEDLY D,SZELISKI R,et al.Interactive 3D architectural modeling from unordered photo collections[J].ACM Transactions on Graphics(TOG),2008,27(5):1-10.
[6]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.Imagenet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems,2012:1097-1105.
[7]GE B Y,ZUO X Z,HU Y J.Review of research on visual target tracking methods[J].Journal of Image and Graphics of China,2018,23(8):1091-1107.
[8]韩强.面向小目标检测的改进YOLOv8算法研究[D].吉林:吉林大学,2023.
HAN Qiang.Research on improved YOLOv8 algorithm for small target detection[D].Jilin:Jilin University,2023.
[9]TANG T,DENG Z,ZHOU S,et al.Fast vehicle detection in UAV images[C]//2017 International Workshop on Remote Sensing with Intelligent Processing(RSIP).IEEE,2017:1-5.
[10]TAN M X,PANG R M,LE Q V.EfficientDet:Scalable and efficient object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).IEEE,2020:10778-10787.
[11]王坤,项琦鑫.改进YOLOv4的车辆弱目标检测算法[J].中国惯性技术学报,2023,31(8):797-805.
WANG Kun,XIANG Qixin.Improved YOLOv4 algorithm for vehicle weak object detection[J].Journal of Chinese Inertial Technology,2023,31(8):797-805.
[12]WOO S,PARK J,LEE J Y,KWEON I S.CBAM:Convolutional block attention module[C]//Computer Vision and Pattern Recognition.IEEE,2018:3-19.
[13]李奇武,杨小军.基于改进YOLOv4的轻量级车辆检测方法[J].计算机技术与发展,2023,33(1):42-48.
LI Qiwu,YANG Xiaojun.Lightweight vehicle detection method based on improved YOLOv4[J].Computer Technology and Development,2023,33(1):42-48.
[14]刘瑞峰,孟利清.改進YOLOv4的车辆图像检测算法研究[J].智能计算机与应用,2022,12(12):192-195,201.
LIU Ruifeng,MENG Liqing.Research on vehicles image detection algorithm for improved YOLOv4[J].Intelligent Computer and Applications,2022,12(12):192-195,201.
[15]CHEN Z X,TIAN S W,YU L,et al.An object detection network based on YOLOv4 and improved spatial attention mechanism[J].Journal of Intelligent & Fuzzy Systems:Applications in Engineering and Technology,2022,42(3):2359-2368.
[16]FURUKAWA Y,PONCE J.Accurate,dense and robust multi-view stereopsis[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,32(8):1362-1376.
[17]JOHANNES L,ZHENG E,POLLEFEYS M.Pixelwise view selection for unstructured multi-view stereo[C]//Computer Vision-ECCV,2016:501-518.
[18]李明,张卫龙,范丁元.城市三维重建中的自动纹理优化方法[J].测绘学报,2017,466(3):228-345.
LI Ming,ZHANG Weilong,FAN Dingyuan.Automatic texture optimization for 3D urban reconstruction[J].Acta Geodaetica et Cartographica Sinica,2017,466(3):228-345.
[19]张春森,张卫龙,郭丙轩,等.倾斜影像的三维纹理快速重建[J].测绘学报,2015,44(7):782-790.
ZHANG Chunsen,ZHANG Weilong,GUO Bingxuan,et al.Rapidly 3D texture reconstruction based on oblique photography[J].Acta Geodaetica et Cartographica Sinica,2015,44(7):782-790.
[20]单杰,李志鑫,张文元.大规模三维城市建模进展[J].测绘学报,2019,48(12):1523-1541.
SHAN Jie,LI Zhixin,ZHANG Wenyuan.Recent progress in large-scale 3D city modeling[J].Acta Geodae-tica et Cartographica Sinica,2019,48(12):1523-1541.
[21]杨必胜,陈驰,董震.面向智能化测绘的城市地物三维提取[J].测绘学报,2022,51(7):1476-1484.
YANG Bisheng,CHEN Chi,DONG Zhen.3D geospatial information extraction of urban objects for smart surveying and mapping[J].Acta Geodaetica et Cartographica Sinica,2022,51(7):1476-1484.
[22]WANG S H,WANG Y,HU Q W,et al.Unmanned aerial vehicle and structure-from-motion photogrammetry for three-dimensional documentation and digital rubbing of the Zuo River Valley rock paintings[J].Archaeological Prospection,2019,26(3):265-279.
[23]黄翔翔,朱全生,江万寿.多视纹理映射中无需设定偏差的快速可见性检测[J].测绘学报,2020,49(1):92-107.
HUANG Xiangxiang,ZHU Quansheng,JIANG Wanshou.Fast visibility detection without specifying the user-defined biases in multi-view texture mapping[J].Acta Geodaetica et Cartographica Sinica,2020,49(1):92-107.
[24]杜瑞建,葛宝臻,陈雷.多视高分辨率纹理图像与双目三维点云的映射方法[J].中国光学,2020,13(5):1055-1064.
DU Ruijian,GE Baozhen,CHEN Lei.Texture mapping of multi-view high-resolution images and binocular 3D point clouds[J].Chinese Optics,2020,13(5):1055-1064.
[25]HU S,LI Z,WANG S,et al.A texture selection approach for cultural artifact 3D reconstruction considering both geometry and radiation quality[J].Remote Sensing,2020,12(16):2521.
[26]朱庆,张琳琳,胡翰,等.精细建筑物碎片化纹理优化的二维装箱方法[J].西南交通大学学报,2021,56(2):306-313.
ZHU Qing,ZHANG Linlin,HU Han,et al.2D bin packing method for fragmented textures optimization of detailed building model[J].Journal of Southwest Jiaotong University,2021,56(2):306-313.
[27]GARCIA D I,DEMIR I,ALIAGA G.Automatic urban modeling using volumetric reconstruction with surface graph cuts[J].Computers & Graphics,2013,37(7):896-910.
[28]TAN Y,KWOH L,ONG S.Large scale texture mapping of building facades[J].The International Archives of the Photogrammetry,Remote Sensing and Spatial Information Sciences,2008,37:687-691.
[29]WANG L,ZHANG H H.Application of faster RCNN model in vehicle detection[J].Computer Applications,2018,38(3):666-670.
[30]李经宇,杨静,孔斌,等.基于注意力机制的多尺度车辆行人检测算法[J].光学精密工程,2021,29(6):1448-1458.
LI Jingyu,YANG Jing,KONG Bin,et al.Multi-scale vehicle and pedestrian detection algorithm based on attention mechanism[J].Optics and Precision Engineering,2021,29(6):1448-1458.
(責任编辑:高佳)
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
