
基于K-means算法的某高校各二级单位报销聚类分析统计研究
2024-05-13 16:08杨泽
信息系统工程 2024年4期
杨泽

摘要:近年来,随着国际形势的变化和我国经济社会发展的内在需要,国家对高校的经费投入逐渐加大,高校管理者如何管好、用好相关经费具有现实意义。选取某高校17个二级单位2022年全年的预约单量、经费执行进度以及问题单率等三个特征变量的数据进行K-means算法统计分析,研究结果显示K-means聚类算法可以有效反映出该高校各二级单位报销情况,为科学化评估经费使用情况提供决策参考依据,并为学校财务信息化建设提供支撑。
关键词:K-means;聚类分析;执行进度;机器学习
一、前言
近年来,随着高等教育事业的蓬勃发展,高校各项经费稳步增长,配套的经费使用管理制度也在不断更新和完善,师生们在进行财务报销时发生问题的数量也随着报销频率的升高而不断增加[1]。与此同时,对于许多高校管理者而言,如何及时有效地对二级单位的报销情况进行考评并督促二级单位不断改进完善成为摆在高校管理者面前的一个难题。考评方法选择不当也会使各个二级单位产生不解与质疑。预约单量、问题单率以及经费执行进度作为重要的财务指标,可以很大程度上反映出高校各个二级单位的经费执行情况、财务预约工作量以及对财务规章制度的理解掌握程度。通过利用这些指标对若干不同二级单位进行聚类,有利于高校管理者对二级单位进行评估与考核,对整个学校事業发展可以起到正向推进作用。相比于主观性比较强的评委打分形式,采用机器学习聚类算法对客观数据进行分类更容易让二级单位负责人与基层工作人员信服,可以有效降低矛盾和冲突的发生。然而,现阶段对于高校各个二级单位财务报销评估与分类的研究较少,评估指标的选取也缺乏统一的标准。
K-means算法作为一种易收敛、操作性强的机器学习算法[2],在电力、图像处理、高校管理等领域取得了广泛的应用[3-4]。鉴于K-means聚类算法[5]优秀的聚类效果,本文采用该算法对某高校各二级单位财务报销情况进行统计研究,以达到通过利用这些指标对不同二级单位进行聚类的目的,便于高校管理机构进行评估与考核。
二、数据挖掘和聚类分析
(一)数据挖掘
数据挖掘技术有许多细分领域,较为主流的方向是机器学习、数理统计、神经网络、数据库、模式识别等。数据挖掘是数据库知识发现(Knowledge-Discovery in Databases,KDD)中的一个步骤。数据库知识发现这个概念最早是在第11届国际联合人工智能学术会议上提出的,通常是指通过算法搜索隐藏于大量的数据中有价值信息的过程,是一种深层次的数据分析与处理方法。随着数据挖掘技术的不断成熟,应用领域也不断扩大。数据挖掘对于不同数据领域可以应用不同的数据分析方法, 其中聚类分析就是一种重要的分析方法[6]。
(二)聚类分析
聚类分析是数据挖掘中的经典算法之一,是指通过数据点的相似性将数据分为若干个集合,每个集合中的数据点之间比其他集合中的数据点相似性更高。简单来说,聚类就是将数据集按照不同相似特征归类为一个个子集,也就是许多个“类”。聚类分析应用十分广泛,不同的聚类分析算法存在各自不同的特点和应用场景,其在经济、管理、医学、心理学、气象预报、地质勘探、生物分类等诸多领域都取得了很好的效果。
三、K-means聚类分析算法
(一)K-means聚类分析算法简介
K-means算法是James MacQueen于1967年提出的,属于一种无监督、可迭代的机器学习算法。该算法需要提前给定分类簇的数目k,并随机选择样本点作为每个簇的初始中心,不断计算每个样本点与初始中心之间的欧氏距离。样本点与初始中心的欧氏距离作为标准来衡量样本点之间的相似度,欧氏距离值越小的样本点与初始中心的相似度越高,反之,相异程度越高。将距离最近的初始中心归为一簇,并对簇的中心进行重新选取。重复上述过程,直至各个簇中心位置不再发生变化,样本数据也完成划分,至此算法结束。
两个样本点x与y之间的欧氏距离表达式为:
(1)
(二)K-means聚类分析算法的优点
K-means算法作为无监督的机器学习算法,具备以下优点:第一,逻辑简单、效率较高。由于具有迭代的特性,K-means算法在少量样本聚类的情况下也能达到很好的聚类效果,该算法时间复杂度较低。第二,对于数据集是数值类型的情况,K-means算法聚类效果更好。第三,K-means优化了监督学习样本分类不合理的地方。
四、数据的获取与处理
(一)数据获取与指标选择
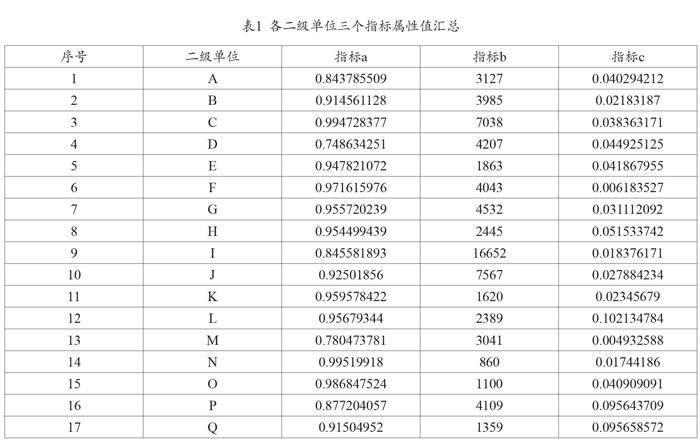
本文所用的数据取自某高校2022年财务数据,选取该高校17个二级单位作为研究对象进行聚类分析,进而得出这些二级单位报销情况的评估。所获取的数据字段包括各个二级单位的年度拨款数、年度执行数、年度预约单总量以及问题预约单总量。通过年度执行数与年度拨款数的比值可以得到各个二级单位的年度经费执行率,通过问题预约单总量与年度预约单总量的比值可以得到各个二级单位的问题单率。选取年度经费执行率、预约单总量以及问题单率这三个指标,分别表征这些二级单位的经费执行情况、财务预约工作量以及对财务规章制度的把控程度,可以有效对各个二级单位的财务报销情况进行区分。
17个二级单位对应的三个指标数据如表1所示。
(二)使用K-means算法对数据进行聚类分析
将17个二级单位分成三类,即优秀、合格与不合格,分别对应的类代码是:1、2和3。对于K-means算法可以将k的值设定为k=3。将表1的数据作为原始数据集导入MATLAB软件,经过运行程序得到的聚类结果如表2所示。对聚类结果进行可视化展示见图2。
由表2可以看出,这3类分别有4个、10个和3个单位。第1类有单位A、单位D、单位I和单位M;第2类有单位B、单位C、单位E、单位F、单位G、单位H、单位J、单位K、单位N和单位O;第3类有单位L、单位P和单位Q。
从图2的K-means聚类结果可视化也可以看出,该算法非常直观地将所有样本点划分成3个类,表明对于样本量较少的数值类型数据集,K-means算法的聚类效果非常明显。
五、将K-means聚类分析算法应用于某高校各二级单位报销统计效果
第一,有效降低主观性评估手段带来的矛盾。如果单纯依靠若干个评委打分统计评比的话,不仅会耗费大量的时间和人力、物力,还会因为过程的不透明引发各种矛盾和冲突。从前文的分析结果也可以看出,采用K-means聚类分析算法对各个二级单位的分类非常直观,更容易让基层员工信服。
第二,将对多个二级单位的划分量化为对数据的处理。K-means算法的优势之一就是对数值类型数据集具有较好的聚类准确度,所以在评估过程中可以将一些指标经过统计后的数据信息通过K-means算法的数据处理,快速准确地对这些二级单位进行分类,进而使主管部门实时掌握这些二级单位的财务状况以及报销进度情况,以便及时调整工作计划并安排下一阶段的部署实施。
第三,不同指标综合评估,得到的评估结果更具全面性。與传统的评估方法单纯依靠某个指标不同,K-means算法通过将年度经费执行率、预约单总量以及问题单率这三个指标综合进行聚类分析,指标所反映的二级单位的经费执行情况、财务预约工作量以及对财务规章制度的理解掌握程度可以全面表征各个二级单位财务状况的健康程度。
六、完善K-means聚类分析算法应用的建议
为了扩大K-means聚类分析算法在高校财务报销统计中的应用,本文提出几点建议:
第一,随着国家教育经费的投入力度不断加大以及学校申请的科研经费增长迅猛,许多学校为了做大做强某些优势研究方向,纷纷组建许多科研团队。这些科研团队在经费等方面拥有更多的自主权,这也是高校落实国家“放管服”改革的要求。许多较大的科研团队规模堪比小型的学院(研究所),在学校层面也有对这些科研团队的财务报销情况进行评估的需求。K-means算法操作简便,速度较快,可以满足学校主管部门对于这些科研团队聚类分析的需要。
第二,本文选取的三项指标在描述各个二级单位财务报销状况时稍显单薄,无法全面衡量出各个二级单位的真实情况。在这种情况下非常有必要增加一些指标。根据前文所述K-means算法对于数值类型的数据集合具有比较好的聚类准确度,然而许多指标并非数值类型。对应于本文所关注的对象高校各个二级单位就有许多指标不是数值类型,例如,有些二级单位有专职财务人员或者财务秘书,有些二级单位则没有。对于这种非数值类型的指标可以将其进行“数值化”,即有财务人员或者财务秘书的单位该指标标记为1,没有的话标记为0。通过增加指标数量全面评估各个二级单位财务报销情况。
第三,本文采用的K-means算法需要提前给定需要划分类别的数目,即需要提前给定k值,对聚类结果有很大影响。除此以外,本文选取的三项指标权重都是相同的,但在实际工作中权值未必一样。对于这种情况,有些学者采用熵值法赋权,有些研究人员采用基于变异系数的欧氏距离实现特征赋权,还有人采用AHP和熵值法相结合的方式为各个指标赋权。这些都表明传统的K-means算法并不是完美的,需要与其他算法结合并改进,完善对各个二级单位的财务报销聚类分析模型,优化聚类算法的时间复杂度与聚类效果。
七、结语
针对高校管理者对各个二级单位评估考核的现实困境,本文提出将K-means聚类算法应用于高校财务分析。通过将某高校2022年17个二级单位的财务数据作为研究对象进行聚类分析,进而得出这些二级单位报销情况的评估,即17个二级单位评估为优秀、合格与不合格的单位分别为4个、10个和3个。实验结果验证了K-means算法在对高校各二级单位报销统计聚类的可行性及有效性。
参考文献
[1]郭美彤,陈钰怡,毛彧,等.探索星级评定机制在改善高校财务报销管理中的作用——以S高校为例[J].教育财会研究,2022,33(05):63-69.
[2]罗鑫帅,高洋.基于改进型K-means算法的高校研究生成绩画像研究[J].陕西教育,2023(07):49-51.
[3]查香云,吕国良.基于K-means聚类分析的高校论文统计研究[J].浙江理工大学学报,2017,38(05):478-482.
[4]谢旭,施学鸿,杨柳,等.一种基于K-means的电力传感网信任决策方法[J].传感技术学报,2023,36(10):1643-1648.
[5]李鹏,李强,马味敏,等.基于K-means聚类的路面裂缝分割算法[J].计算机工程与设计,2020,41(11):3143-3147.
[6]王世纯,许新华,黄嘉成,等.K-means聚类算法在高校学生成绩分析中的应用研究[J].湖北师范大学学报(自然科学版),2019,39(03):113-118.
责任编辑:张津平、尚丹
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
新媒体研究(2016年19期)2016-11-18
大经贸(2016年9期)2016-11-16
科教导刊(2016年26期)2016-11-15
中国市场(2016年33期)2016-10-18
科学与财富(2016年28期)2016-10-14
科技视界(2016年20期)2016-09-29
科教导刊·电子版(2016年10期)2016-06-02
企业导报(2016年9期)2016-05-26
