
一种改进模板匹配的车牌字符识别方法
2010-12-28 01:25王建霞周万珍
河北科技大学学报 2010年3期
王建霞,周万珍
(河北科技大学信息科学与工程学院,河北石家庄 050018)
一种改进模板匹配的车牌字符识别方法
王建霞,周万珍
(河北科技大学信息科学与工程学院,河北石家庄 050018)
提出了一种改进模板匹配的车牌字符识别方法。详细介绍了车牌字符识别的过程,主要包括模板的建立,基于弹性网格的字符特征提取,模板匹配的步骤及改进方法。运用该方法不仅可减少计算量,而且提高了实时性。实验结果表明,提出的方法具有效率高、精确度好等特点,识别率可以达到90%以上。
字符分割;车牌牌照;特征提取;字符识别;改进模板匹配法
随着交通现代化发展的要求,人们越来越重视智能交通管理系统。汽车牌照自动识别系统是实现交通管理智能化的重要环节,其主要包括汽车牌照区域定位、汽车牌照字符分割和汽车牌照字符识别3个关键环节[1]。汽车牌照区域定位主要是完成汽车牌照从拍摄的图像中分割出来,也就是在1个含有汽车的画面中找出包含汽车牌照字符的最小区域。汽车牌照字符分割主要是从汽车牌照定位后的图像中将字符分离出来。字符识别是车牌识别系统中最后1个步骤,也是至关重要的一步。汽车牌照字符的识别主要是对分割出来的汽车牌照字符进行处理、特征提取与分辨。笔者在参照其他研究者工作的基础上[2],主要对现有汽车牌照识别算法进行了分析研究,实现了一种改进模板匹配的车牌字符识别方法,并给出了算法的详细描述和对应的实验结果。
1 车牌字符识别
车牌字符识别是在车牌准确定位、字符分割的基础上,对车牌上的汉字、字母、数字进行有效确认的过程,其中汉字识别是一个难点。由于车牌识别本身问题的复杂性,如何提高车牌字符的识别效果是解决车牌识别率的关键所在[3]。
对车牌字符的识别,目前常用的方法有基于神经网络的方法[4]和基于模板匹配的方法。前者具有较强的容错能力;后者具有较快的识别速度,尤其对二值图像速度更快,当车牌图像较清晰,并且前面的预处理工作做得比较好时可以获得较高的识别率[5]。考虑到目前车辆牌照所用字符只有26个大写英文字母、10个阿拉伯数字和50个左右的汉字,字符集合较小,因而在一些车辆牌照字符识别系统中首先采用了简单的模板匹配法。但是,模板匹配法对噪声很敏感,而且对字符的字体风格不具有适应性,任何有关光照、字符清晰度和大小的变化都会影响识别的正确率,因此在实际应用中为了提高正确率往往需要使用大的模板或多个模板进行匹配,而处理时间则随着模板的增大以及模板个数的增加而增加[6]。因此需要对模板匹配法加以改进以提高识别速度和识别率。
2 改进的模板匹配法字符识别过程
2.1 模板的建立
因为车牌上的汉字和现行使用的字体在样式上存在着差异,所以采用国家交通部根据GA 36—2007标准所发布的10个阿拉伯数字图片和26个英文字母和汉字的样图,然后分别切分图片来进行二值化、归一化,形成32×16的模板,模板大小的建立是根据车牌中字符的比例来缩小的。
2.2 字符特征提取
字符特征提取是字符识别的基础,也是将车牌字符形状转换为一组特征值的过程。它对车牌字符图像固有的、本质的重要特征或属性进行量测,并将结果数值化,准确高效地完成车牌字符的特征描述。
2.2.1 字符网格特征
网格特征是字符提取中常用的特征之一。网格就是将图像分成一个一个的小格子,从网格的形状划分,网格可分为均匀网格和弹性网格。其中,均匀网格是根据网格大小,把字符图像均匀地划分为若干个固定大小的子网格。该方法在字符结构比较清晰、字符不倾斜的情况下,分割简单,计算速度快,但是,由于在实际应用中,车牌图像一般会受到各种情况的干扰,所以该方法不太实用。而弹性网格是根据字符图像的笔画分布情况用非均匀的网线划分字符得到的网格,就是非均匀网格。弹性网格可根据字符图像的像素点分布情况动态地确定网格线的位置,以适应字符的笔画稠密。图1为均匀网格和弹性网格的对比图。
2.2.2 字符特征提取过程
根据车牌中字符的结构特征,对车牌中的字符进行投影,在投影波形的每个波谷处划分网格线。弹性网格对每个字符划分的网格数不是固定的,它根据特征字符的特点来划分,这样有利于笔画的分类,因为一般在笔画和笔画之间才可能有波谷的出现。由于该弹性网格的方法是根据字符图像的密度分布情况动态地确定网格线的位置,相对于普通的弹性网格能更好地适应字符笔画的变形。分割结果如图2所示。
设字符图像为f(x,y),弹性网格的特征提取步骤如下。
1)在水平方向和垂直方向分别将字符投影,将每行和每列中的特征像素进行累加,获得水平和垂直方向的直方图,即水平方向和垂直方向上的投影特征,分别记为Hor(i),Ver(j),特征向量的维数为M和N,投影公式如下:

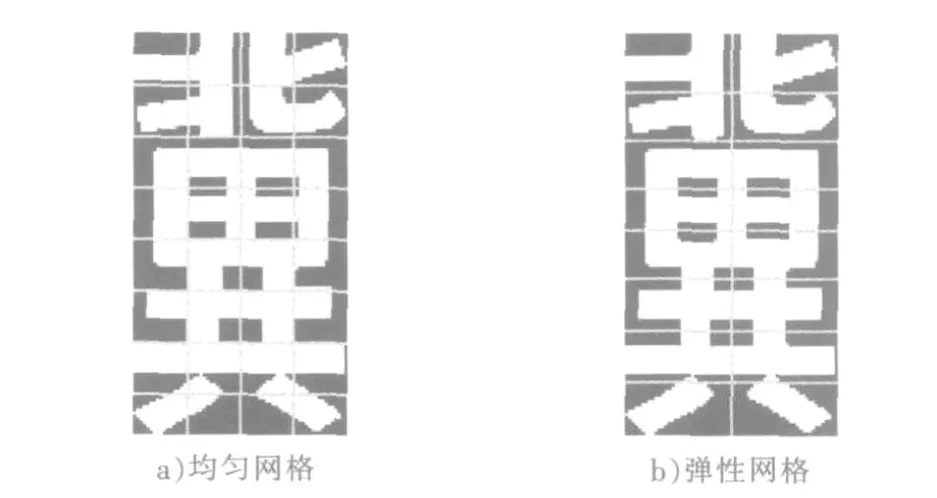
图1 均匀网格和弹性网格对比图Fig.1 Uniform grid and flexiblemesh comparison chart
2)根据水平投影或者垂直投影,选取一个阈值,以确定字符图像中什么地方应该有弹性网格线。该线的确定是根据波形的变换确定的,先确定水平网格,从字符图像的顶部开始向下扫描,找到第1个波峰,然后继续扫描。当出现波谷时,计算波峰和波谷的差值,如果差值超过阈值可确定为一网格线。依此类推,一直到整个图像扫描完。确定垂直网格和水平网格的方法一样。
3)如果扫描字符图像的过程中,没有符合上述条件的,用均匀网格特征划分。
4)计算划分好的每个网格的目标像素数,然后除以该网格的面积,得出的结果作为特征值。
5)将每个特征值组合起来,形成特征向量。
2.3 模板匹配的实现原理
设有m个类别:w1,w2,…,wm,每类的特征向量有若干个向量标识,如wi类,有


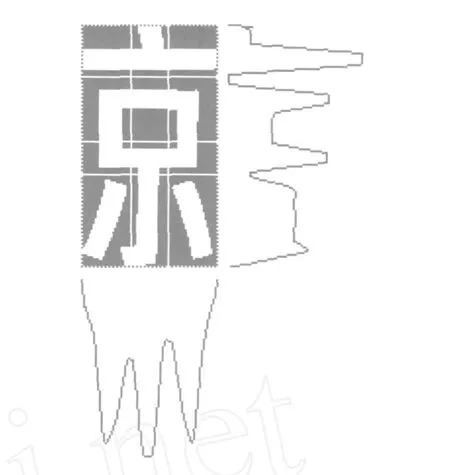
图2 弹性网格划分图Fig.2 Flexible mesh division chart
对于任意被识别的字符X,计算距离d(Xi,X),若存在某一个i,使得

2.4 模板匹配的实现步骤
1)计算待测样品X与训练集里每个样品Xi的距离采用d(X,Xi)=|X-Xi|2。
2)循环计算待测样品和训练集中各已知样品之间的距离,找出距离待测样品最近的已知样品,该已知样品的类别就是待测样品的类别。
2.5 模板匹配的改进方法
传统的模板匹配分类器将训练样品集中的每个样品都作为标准模板,用待测样品与标准模板做比较,找出最相似、最近邻的标准模板,将标准模板的类别作为自己的类别。譬如A类有8个训练样品,因此有8个模板,B类有18个训练样品,就有18个模板。任何一个待测样品在分类时都与这26个模板计算相似度,找出最相似的模板,如果该模板是B类中一个,就确定待测样品为B类,否则为A类。但这样有一个明显的缺点,就是计算量大,笔者针对车牌字符的排列方式X1X2·X3X4X5X6X7,其中X1为汉字,为各省市和部队军区简称;X2为字母,为发牌机关代号;X3X4X5X6X7为字母和数字的组合形式。
1)先对X1进行模板匹配,不是每个模板都进行匹配,用每个汉字的标准模板(标准图像中分割的字符)和目标车牌中的汉字进行比较、计算相似度。
2)找相似度最大的2个汉字,然后和它们所有的模板比较,找最相似的字符。
3)对X2进行模板匹配,从字母的标准模板中查找,然后再细分。
4)对X3X4X5X6X7也进行同样的操作。
这样可以减少比较的次数,提高识别效率。
3 实验结果及分析
车牌中字符识别一直是车牌识别的一个难点问题,笔者采用弹性网格的方法提取字符特征,用改进的模板匹配法对字符进行识别,并对改进后的模板匹配法和改进前的进行比较。字符识别测试如表1所示。

表1 字符识别测试表Tab.1 Character recognition test table
从表1中可以看出,利用改进模板匹配法对汉字、字母及数字字符的平均识别率和识别速度都有所提高,大于改进前的识别率和识别速度。此外笔者采用1 000个样本进行训练,2 000多个样本进行测试,这些样本均来自实际交通路口违章车辆图像,因此,测试结果更具一般性和普遍性。
4 结 语
字符识别是整个车牌识别过程中重要的一环,笔者选择了改进的模板匹配识别技术作为识别的方法,以车牌字符作为识别对象,设计实现了一个快速高效的车牌识别系统。通过对500幅不同背景和光照条件下的车辆图像进行试验,结果显示此方法可实现良好的定位精度和较高的识别率。
[1] 李孟歆,吴成东.基于分级网络的车牌字符识别算法[J].计算机应用研究(App lication Research of Computers),2009,26(5):1 703-1 705.
[2] 徐应涛,陆福宏,张 莹.基于填充函数法训练BP神经网络的车牌字符识别算法[J].计算机工程与科学(Computer Engineering&Science),2009,31(5):59-61.
[3] 邓红耀,管庶安,宋秀丽.投影和模板匹配相结合分割车牌字符[J].计算机工程与设计(Computer Engineering and Design),2008,29 (6):1 568-1 570.
[4] 李晓斌.一种改进BP神经网络的车牌字符识别方法[J].重庆电子工程职业学院学报(Journal of Chongqing College of Electronic Engineering),2009,18(2):90-94.
[5] 孙炎增,张前进.车牌字符识别技术的研究与实现[J].微电子学与计算机(M icroelectronics&Computer),2008,25(6):101-104.
[6] 刘朝英,王惠芳,宋雪玲,等.一种改进的模糊调节神经网络及其应用[J].河北科技大学学报(Journal of Hebei University of Science and Technology),2008,29(4):295-298.
A license p late characters recognition method based on imp roved temp late matching
WANG Jian-xia,ZHOU Wan-zhen
(College of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang Hebei050018,China)
This paper p resents an imp roved temp late matching method of license plate characters recognition.License p late characters recognition p rocess is introduced in detail,w hich includes the establishment of the temp late,the character feature extraction based on an elastic mesh,templatematching steps and imp roved methods.By using thismethod,the computational amount is greatly reduced,w hile real-time is imp roved.The experimental result show s that the p roposed method has high efficiency,accuracy and good characteristics,and the recognition rate can reach 90%.
characters segmentation;license vehicle p late;feature extraction;characters recognition;imp roved temp late matching method
TP391
A
1008-1542(2010)06-0236-04
2009-12-24;责任编辑:陈书欣
王建霞(1970-),女,河北临城人,副教授,硕士,主要从事网络与数据库方面的研究。
猜你喜欢
电子制作(2019年12期)2019-07-16
知识经济·中国直销(2017年12期)2018-01-03
成都信息工程大学学报(2017年3期)2017-11-09
能源(2017年8期)2017-10-18
知识经济·中国直销(2017年8期)2017-09-05
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
知识经济·中国直销(2016年1期)2016-08-24
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
