
一种基于UFFT的数据流分类器
2011-01-16 05:31甄田甜张玉红王海平胡学钢
合肥工业大学学报(自然科学版) 2011年1期
甄田甜, 张玉红, 李 燕, 王海平, 胡学钢
(合肥工业大学计算机与信息学院,安徽合肥 230009)
一种基于UFFT的数据流分类器
甄田甜, 张玉红, 李 燕, 王海平, 胡学钢
(合肥工业大学计算机与信息学院,安徽合肥 230009)
文章提出一种基于极速决策森林(UFFT)的加权装袋算法(UFFT-w b),它采用加权装袋算法模型,以UFFT算法构建基分类器。实验表明,该算法具有确定分割点及选择分割属性花费时间少、构建新结点占用空间小及可以增量式构建等特点,与基于C4.5算法的加权装袋算法模型相比,在保持相似精度的基础上,时间性能有一定程度的改进。
数据流;集成分类器;极速决策森林;加权装袋算法
随着计算机网络的飞速发展和信息存储技术的不断进步,众多应用领域如网络入侵检测、股票实时分析、卫星气象监控、信用卡交易以及电子商务管理等[1-3]拥有了大量的数据流,数据流具有无限性、快速性等特点,如何在数据流上及时有效地进行实时分类预测,给数据挖掘领域带来了极大的挑战。
数据挖掘领域中常用决策树进行分类预测。最早的决策树系统要追溯到文献[4]中ID 3算法,而C4.5算法[5]是ID3的改进版,加入了对连续性属性和窗口处理,但时间花费较大。近些年,面向数据流领域出现一些新的发展,如文献[6]提出了VFDT,文献[7]提出了 VFDT的改进算法VFDTc,两者不足在于由用户确定何时决定分裂叶子结点的阈值,不同的阈值会影响分类精度。文献[8]提出了Random forests,森林中生成每棵树都是基于同一个由随机样本构成的容器,且彼此独立,多棵树以投票进行分类决策;文献[9]提出了UFFT,该算法并不使用Random forests的随机方法,而是将类标号是k类的问题化为k(k-1)/2个二叉树问题。它采取二次判别式来选择分割值,用信息熵来评价分割属性,使用Hoeffding边界决定何时分裂叶子结点,该算法在处理大中型数据集时,与其它算法相比,在时间性能方面具有优势。
以上使用单分类器预测未知样本,而集成方法是通过聚集多个分类预测来提高分类准确率,如文献[10]设计的SEA算法,它按到达时间将训练数据划分成大小相等、互不重叠的“有序数据块”,并分别对每块数据构造基分类器;当基分类器个数达到最大值时,采用启发式的替换机制选择基分类器;文献[11]设计了weighted-bagging算法,考虑不同基分类器性能间的差异,提出了根据分类器分类错误率动态改变权值的技术;文献[12]设计了adaptive boosting算法等,提出了自适应集成分类器综合挖掘方法,将boosting思想应用于数据流分类中;文献[13]设计了一种基于相反分类器的数据流分类算法IWB,通过从期望分类能力较低的分类器中分析并验证相反分类器,若和当前概念相近时更新集成模型获得高精度;文献[14]设计的Ewamds算法,是通过减小被基分类器正确分类的实例的权值以增强具有不相似概念的实例对新分类器的影响,从而使算法能快速发现和适应新概念;以上这些工作都是以C4.5作为基分类器来研究集成分类技术的。
C4.5作为功能强大的算法,本身也具有一些弱点,如时间开销,即在每个决策点,连续型属性要被分段,并排序求得分割点和分割属性;C4.5是非增量式构树,即生成一棵树后不能利用随后到来的新数据对树进行继续生长。这些弱点具有很大的局限性,不适合处理数据量大、要求实时性的数据流。
因此,本文提出一种基于 UFFT的weighted-bagging集成分类器算法(UFFT-w b)[11],它是将UFFT作为基分类器应用到weighted-bagging算法中,通过实验可知,基于UFFT的集成分类器精度相近,在时空性能上更具有优势。
1 UFFT算法
UFFT[9]算法是一种有监督的学习算法,它将多类问题转化为多个二叉问题,由多个二叉树组成森林。UFFT与C4.5比较,在以下方面做了改进:①使用二次判别式来确定分割点,只需统计各属性的样本均值和方差,无需占用较大空间和消耗大量时间排序,这是该算法相对C4.5及其它算法的最大优点;②使用Hoeffding[15]不等式决定分裂结点个数,使得分裂结点个数的取值对算法性能影响降至最低;③叶子结点带有贝叶斯与最大类的混合分类方法来测试数据,这既考虑到贝叶斯方法可以充分使用叶子结点信息,又兼顾到最大类方法在小样本数据下,相对较高分类精度的优点。
UFFT采用二次判别式分析方法来确定分割点,二次判别式方法是指假设各个属性均满足正态分布。将 X轴划分为(-∞,d1)、(d1,d2)、(d2,+∞)3部分。其中,d1和 d2是表示p(-)φ{(x-,σ-)}=p(+)φ{(x+,σ+)}的 2 个根,p(-)是负类估计,p(+)是正类估计,x和σ分别是样本期望和方差,从d1和d2中选择一个更接近样本均值的(用di表示)。将样本按属性Atti分为 2类 ,即“Atti<=di”和“Atti>di”。
UFFT使用信息熵作为评判标准选择最佳的分裂属性,根据期望和方差,结合概率密度公式计算出每个属性在大于和小于分割点di时的正负类别分布概率。而属性i对应的信息熵H(Atti)的计算方法为:
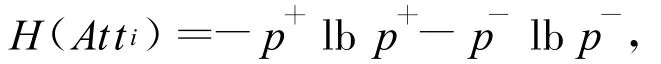
其中,p+是属性类标号为正时的概率;p-是属性类标号为负时的概率。选取最大熵对应的属性作为分裂属性,将该属性的分割点作为该分支结点的分割。
叶子结点进行分裂时,当且仅当从上次分裂后到达该结点的实例数大于 N(min)值时才允许分裂,本文N(m in)值是通过计算Hoeffding不等式推导出来的表达式计算得到。由于树高限制或者未达到分裂实例个数,叶子结点会出现不纯性,即其中有不同类标号的记录。针对这种不纯性,UFFT采用朴素贝叶斯和最大类相结合的方法。采用贝叶斯,则使用了更多的叶子结点信息,即考虑类别分布的先验概率和各属性值对应的条件概率。而采用最大类,则在小样本下性能较好,弥补贝叶斯方法在这点上的不足。
2 一种基于UFFT的数据流分类器
本文提出一种基于极速决策森林(UFFT)的加权装袋算法,简称UFFT_wb分类器。本文采用的加权装袋(weighted-bagging)思想凸出代表新概念的分类器,而淘汰不适合当前到来数据的分类器,以此来适应当前数据变化的方向,获得较高精度。UFFT_wb分类器采用 UFFT算法构造基分类器,与基于C4.5的 weighted-bagging数据流分类器(简写为C4.5_wb分类器)比较,该方法建树所需时间较少,且具有增量式增长树结构的特性。
2.1 UFFT_wb算法流程
首先对算法中用到的符号说明如下:EC表示集成分类器,初始值为Null;K为EC的基分类器最大个数;Ci表示EC中第i个分类器;数据流DS;S表示当前数据块;b lock表示当前数据块大小;weight[i]表示Ci的权值。
在新数据块S到来时,利用 S先构建新的UFFT基分类器C num,并刷新EC中原有的各个分类器权值。当EC中的分类器个数达到K+1时,删除EC中权值最小的那个基分类器,保持EC中均为高权重基分类器。
具体过程描述如下:

2.2 基分类器权值更新

考虑到随机模型不包含有用的知识,抛弃误差等于或大于E r的分类器。为计算方便,使用公式wi=E r-Ei对Ci进行加权。
2.3 算法分析
(1)时间复杂度。假设使用block大小的数据块S构建一个基分类器的时间复杂度为O(f(block)),为计算其权值而分类测试数据的时间复杂度远远小于新建分类器的时间复杂度,故忽略不计,那么,数据流可分割成n个block大小数据块,时间复杂度为O(n f(b lock))。由此可知,一个集成分类器的时间复杂度取决于构建一单个分类器的时间复杂度。已知UFFT算法构建基分类器的时间复杂度为O(n),C4.5的为O(n lb n)。在相同的基分类器个数条件下,UFFT_wb时间性能将远小于C4.5_wb时间复杂度。
(2)空间复杂度。叶子结点在计算信息增益率求分割属性时,C4.5需预留一段存储空间存放到达该结点的所有实例,并对实例进行排序,计算求得分割点和分割属性。而UFFT利用新到来的实例更新每个叶子结点的期望和方差,结合概率密度公式计算得出信息增益率,无需占用空间专门用于计算分割点和分割属性。UFFT在初始化一个结点时,也仅仅需要一段公共的存储池,存放当前到来的一段数据,用于对新结点进行更新,一旦更新完毕,该存储池清空。
3 实验结果
为验证 UFFT_wb,本节用实验评估算法。实验工作采用 UCI数据库中Waveform数据和Hyperp lane数据[16]。W aveform具有3类类标号,按属性维数分为21维、40维2种Waveform数据集(简称waveform_21、waveform_40)。设定UFFT基分类器的参数初始值为δ=0.05,τ=0.01,N(min)=300,实验硬件为CPU1.83GH z、2G内存的PC机,系统环境为W indow s XP+Visual C++。
3.1 参数讨论
为了考察单个分类器树高h、分类器最大个数K、数据块b lock取值的变化对算法性能的影响,分别在waveform_21、waveform_40上进行实验,2种数据集均取100 k个实例(1 k=1 000)。
树高影响单个 UFFT分类器的分类精度变化,由图1所示可知,树高高度越高,单个UFFT分类器的精度逐渐降低。在waveform_21、waveform_40数据上,高度保持在1~5左右,精度一般在0.78以上,高度超过6以上,精度降至0.76左右。其原因是单个分类器树高过高会造成过拟合。树高为1的树是树桩,即单个UFFT转化为若干个贝叶斯分类器组。在文献[17]中也证明了h为5对于决策森林较合适,故本文选择为5。
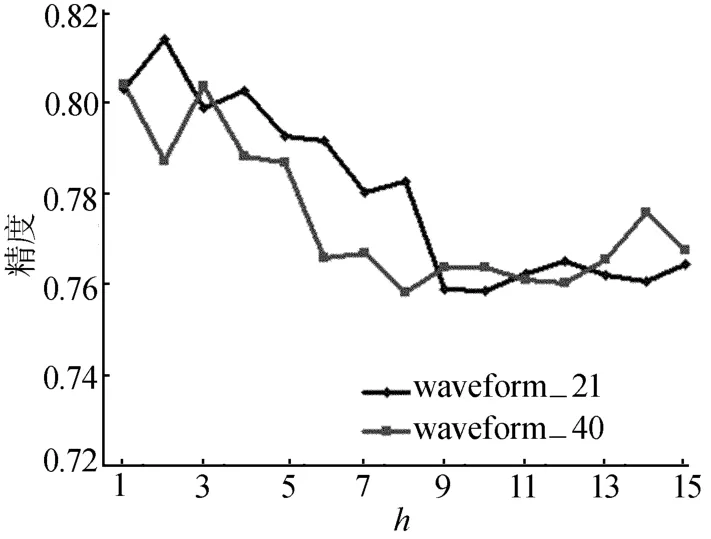
图1 树高取值对单UFFT精度影响
由于在硬件条件限制下,分类器个数不可能无限制增加,故需讨论合适的分类器个数,达到最优分类精度。如图2所示,当数据块block取1 k时,UFFT_wb分别在4、6、8个基分类器条件下,分类精度比较高;C4.5_wb在分类器个数取10时,分类效果最佳。为了在随后的比较试验中,能够使得C4.5_wb达到最佳的分类效果,这里选择10作为UFFT_wb基分类器数。
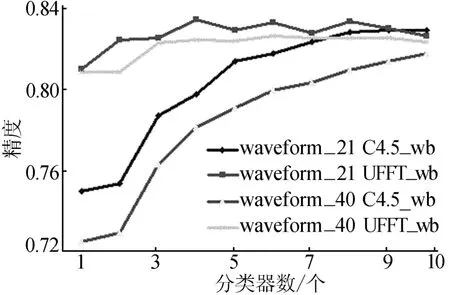
图2 K取值对集成分类器精度影响
由表1所列可知,当数据块大小 b lock取0.8、1、2 k时,UFFT_wb分类效果更优。由于block较小会导致过拟合,b lock较大又会使基分类器对新概念不够敏感,比较试验时,选择1 k作为block取值。

表1 数据块b lock取值对UFFT分类精度影响
3.2 与C4.5_wb对比试验
根据上述讨论,UFFT_w b的参数分别是:单个基分类器树高h为5,数据块b lock大小为1 k,基分类器个数 K为10,确定参数后,进行比较试验。
UFFT_wb和C4.5_wb处理w aveform_21、waveform_40数据集,数据量分别从 100~1 000 k的时间开销,如图3所示。从图3可以看出,C4.5_wb的运行时间开销随着数据量的增长逐渐高于 UFFT_wb。在waveform_21数据集上,UFFT_wb的所有大小数据集的平均运行时间开销是 C4.5_w b的 81.5%;在 waveform_40数据集上,UFFT_wb的所有大小数据集的平均运行时间开销是C4.5_wb的83%。因waveform数据集是3个类标号,每个基分类器生成3个二叉树。UFFT_wb系统共有10个基分类器,新建了30个树,虽然树结构复杂,但仍然表现出较好的时间性能。

图3 对waveform_21和w avefo rm_40分类的时间节省比
UFFT_wb和C4.5_wb处理w aveform_21、waveform_40数据集,数据量分别从 100~1 000 k的精度,见表2所列。UFFT_w b在精度上要高于C4.5_wb,在waveform_21数据集上,所有大小数据集的平均精度相差约1%,在waveform_40数据集上,所有大小数据集的平均精度相差约 1.6%,总体上,UFFT_wb略高,和 C4.5_wb在精度上相似。

表2 在waveform_21、w aveform_40分类精度比较
同时,本文也对Hyperp lane的数据集做了实验,其时间、精度性能比较见表3、表 4所列。所用的Hyperp lane参数设置如下:num driftatts=2,m agchange=1,nosie=5%,Si∈{10,-10},数据量为500~1 500 k;UFFT_wb的参数设置:树高 h=5,数据块 block=1 000,分类器个数K=10。由表3可知,随着数据量的增加,UFFT_wb的时间性能依然保持较高优势,UFFT_wb的平均运行时间开销是C4.5_wb的64.74%。虽然精度偏低,略低于C4.5_wb,而时间性能较好,平均节约时间约35.26%。
通过以上几组实验表明,UFFT_wb在保持精度的同时提高了时间效率,总体上满足了处理大数据量数据集的实时性要求。

表3 在Hpyerplane时间性能比较 s

表4 在Hpyerplane精度性能比较
4 结束语
本文提出一种基于UFFT的weighted-bagging的数据流分类算法(UFFT_wb),它是采用UFFT算法来替代C4.5算法构建基分类器。与C4.5_wb算法相比,UFFT_wb在处理大数据集具有相似分类精度,一定程度降低了时间开销,进一步满足大型数据的实时处理要求。但是算法在处理概念漂移数据和抗噪性上存在劣势,如何提高算法检测概念漂移能力和解决抗噪性问题将是下一步研究的目标和方向。
[1] Golab L,¨Ozsu M T.Issues in data stream managemen t[J].SIGMOD Rec,2003,32(2):5-14.
[2] Supratik B,Sue M.Netw ork performance monitoring and m easurement:techniques and experience[C]//MMNS Tutorial,2002:461-470.
[3] 倪志伟,黄 玲,李锋刚,等.数据流管理与挖掘研究[J].合肥工业大学学报:自然科学版,2005,28(9):1157-1162.
[4] Quinlan JR.Induction of decision trees[J].Machine Learning,1986,1(1):81-106.
[5] Quinlan JR.C 4.5:programs formachine learning[M].San Francisco,CA:Morgan Kaufmann Pub lishers Inc,1993:68-70.
[6] Dom ingos P,Hu lten G.Mining high-speed data stream s[C]//Proceedings of the 6 th ACM SIGKDD International Con feren ce on Know ledge Discovery and Data M ining,2000:71-80.
[7] Gama J,Rocha R,M edas P.Accuratedecision trees form ining high-speed data streams[C]//Proceedings of the 9th ACM SIGKDD International Conferece on Know ledge Dis-covery and Data M ining,2003:523-528.
[8] Breiman L.Random forests[J].Machine Learning,2001,45(1):5-32.
[9] Gama J,M edas P,Rocha R.Forest trees for on-line data[C]//Proceedingsof the 2004 ACM Symposium on Applied Com puting,2004:632-636.
[10] StreetW,K im Y.A stream ing ensemble algorithm(sea)for large-scale classification[C]//P roceedings of the 7th ACM SIGKDD International Conference on Know ledge Discovery and Data M ining,2001:377-382.
[11] W ang H,Fan W ei,Yu P,et al.M ining concep t-drifting data stream s using ensemb le classifiers[C]//Proceedings of 9 th ACM SIGKDD InternationalConferen ce on Know ledge Discovery and Data M ining,2003:226-235.
[12] Chu Fang,Zaniolo C.Fast and ligh t boosting for adap tive mining of data stream s[C]//Proceeding of the 5th Pacific-Asia Conference on Know ledge Discovery and Data M ining,2004:282-292.
[13] 王 勇,李战怀,张 阳,等.基于相反分类器的数据流分类方法[J].计算机科学,2006,33(8):206-209.
[14] 胡学钢,潘春香.基于实例加权方法的概念漂移问题研究[J].计算机工程与应用,2008,44(21):188-191.
[15] Loh W Y,Shih Y S.Split selection method s for c lassification trees[J].Statistica Sinica,1997,7:815-840.
[16] H u Xuegang,Li Peipei.A sem i-random m ultiple decisiontree algorithm for m ining data streams[J].Jou rnal of Com puter Science and Technology,2007,22(5):711-724.
[17] Hu lten G,Spencer L,Domingos P.M ining time changing data stream s[C]//Proceedings of the 7th ACM SIGKDD International Conference on Know ledge Discovery and Data M ining,2001:97-106.
A data stream classifier based on UFFT
ZHEN Tian-tian, ZHANG Yu-hong, LIYan, WANG Hai-ping, HU Xue-gang
(School of Compu ter and Inform ation,Hefei University of Technology,H efei 230009,China)
In this paper,a new data stream m iningmethod called UFFT-wb is proposed,which isbased on the weighted-bagging m odel and uses the u ltra fast forest tree(UFFT)algorithm to build the base classifier.Experiment results show thatUFFT-w b hasitsown characteristics,such as the less time to choose the cutpoint for splitting tests,the little space to build new node,the incrementalconstruction and so on.Compared w ith thew eighted-bagging algorithm based on C4.5,thismethod is superior in the time consumption w hilem aintaining the sim ilar accuracy.
data stream;ensemble classifier;ultra fast forest tree(UFFT);weighted-bagging algorithm
TP181
A
1003-5060(2011)01-0065-06
10.3969/j.issn.1003-5060.2011.01.016
2009-12-23
国家自然科学基金资助项目(60975034);安徽省自然科学基金资助项目(090412044)和合肥工业大学科学研究发展基金资助项目(2010HGXJ0013)
甄田甜(1983-),女,安徽合肥人,合肥工业大学硕士生;
胡学钢(1961-),男,安徽当涂人,博士,合肥工业大学教授,博士生导师.
(责任编辑 张秋娟)
猜你喜欢
电子制作(2021年14期)2021-08-21
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
中国惯性技术学报(2019年6期)2019-03-04
数学物理学报(2018年1期)2018-03-26
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
西北工业大学学报(2015年3期)2015-12-14
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
中国卫生(2014年7期)2014-11-10
