
事件驱动Q学习在呼叫接入控制中的应用
2011-01-16 07:45任付彪马学森魏振春
合肥工业大学学报(自然科学版) 2011年1期
任付彪, 周 雷, 马学森, 魏振春
(合肥工业大学计算机与信息学院,安徽合肥 230009)
事件驱动Q学习在呼叫接入控制中的应用
任付彪, 周 雷, 马学森, 魏振春
(合肥工业大学计算机与信息学院,安徽合肥 230009)
文章研究了计时报酬方式下最优呼叫接入控制问题,建立了系统的连续时间M arkov决策过程(CTMDP),根据系统特征引入后状态Q值更新方法,给出呼叫接入控制问题基于事件驱动Q学习优化算法,并给出一个数值仿真实例;仿真结果表明,该算法比Q学习具有收敛速度快、存储空间小的优势;根据实验结果分析了在最优策略下业务拒绝率与业务特征的关系。
连续时间M arkov决策过程;事件驱动 Q学习;呼叫接入控制
0 引 言
随着网络的日益普及,新业务不断涌现以及业务量的迅速增长,网络资源需求日益增加。由于网络资源的有限性,如何利用现有资源获取最大收益是每个网络运营商需要考虑的问题。呼叫接入控制(Call Admission Control,简称CAC)是解决这类问题的主要方法,一直受到广泛关注。收益获取通常采用固定报酬方式[1,2],在理论上,计时报酬方式更为合理,因此本文使用计时报酬代替传统的固定报酬,并求解在该方式下报酬最大化的呼叫接入控制问题。
目前,最优呼叫接入控制问题通常建模成CTMDP/半Markov决策过程(SMDP)[1-5],主要由于这类问题已有很多求解算法,如策略迭代、线性规划等方法能够很好地解决这类问题[1-3],但这些方法需要确切的模型参数,不利于在线学习和实际的应用。Q学习不依赖于模型,然而该方法求解呼叫接入控制问题时收敛速度慢、存储空间大[4,5]。关于排队系统接入控制问题,文献[6]研究了一种求解事件驱动MDP问题的简单Q学习算法,该算法能够有效地提高收敛速度,减少状态存储空间,因此,本文利用该算法,并根据呼叫接入控制问题特征引入后状态Q值更新方法[7],给出了问题基于CTMDP模型的简单Q学习优化算法。由于算法仅适合这类特殊的事件驱动问题,为了区别传统的Q学习,称该算法为事件驱动Q学习。
1 问题描述与CTMDP建模
考虑拥有固定带宽、多类业务的单服务节点呼叫接入控制问题。假定节点带宽为C个单位,业务划分为K类,第i(i=1,2,…,K)类业务呼叫到达率服从参数为λ(i)的独立泊松分布,接受一个第i类业务需要b(i)个单位带宽,第i类业务单位时间获得报酬(即报酬率)为r(i),离去率服从参数为μ(i)的指数分布。
针对上述描述,本文把呼叫接入控制问题建模成CTMDP,定义一个K维向量x=(x(1),x(2),…,x(i),…,x(K))描述上述节点状态,其中x(i)为当前第i类业务的在线个数,系统的状态空间为:

事件指某个业务到达或离开节点,假设任意2个事件不能在同一时刻发生,可以用一个K元组e=(e(1),e(2),…,e(K))描述事件。其中,元素e(i)=1表示一个i类业务到达事件,e(i)=-1时表示一个i类业务离开事件,e(i)=0时表示其它。于是事件集合可以表示为:
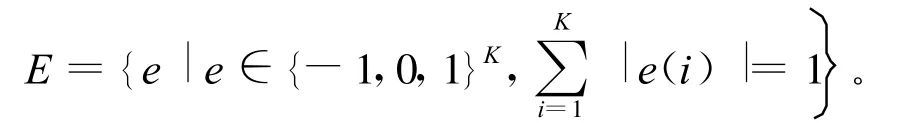
系统只有在业务到达节点时需要采取行动,假设行动不需要时间,行动集A={0,1},行动用a表示,其中a=1表示接受业务,a=0表示拒绝业务。当业务离开节点时,不需要采取行动,此时默认a=0。
由于系统的状态空间为S,事件集合为E,行动集合为A,于是平稳策略L表示状态空间与事件集的笛卡尔积到行动集的一个映射,记L:S×E→A。
系统在状态 x∈S下,若有事件e∈E发生,并采取行动 a后,则下一状态 x′可以由函数h:S×E×A→S确定,即 x′=h(x,e,a),其表达式为:

假设t0=0为系统开始时刻,tn表示第n个事件en发生时刻,则系统在(tn,tn+1]时间段的状态为xn,于是系统在这段时间的累积报酬为:

由此可以得到在策略L下的目标函数,即系统长期平均报酬为:
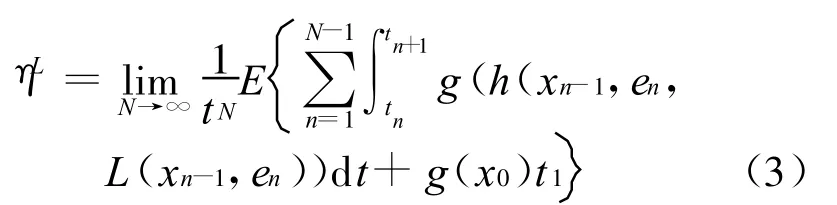
其中,x0为初始状态,由于初始时刻没有事件发生,系统直到t1时刻事件e1发生时才进行决策,因此系统在t1时刻的状态仍然为 x0,故[t0,t1]间的累积报酬g(x0)t1与决策L无关。系统的优化目标是寻找最优策略L使得系统目标函数达到最大。
2 事件驱动Q学习算法及实现
呼叫接入控制问题具有事件驱动特征,系统决策时刻为事件发生时刻,事件发生满足M arkov特性,在确定的状态和事件下,采取特定的行动后状态转移是已知的,而且行动选择较少。本文利用系统特征引入后状态Q更新方法,给出了事件驱动Q学习算法求解该问题。
后状态Q值更新过程如图1所示,其中tn、tn+1为决策时刻(即事件en、en+1发生时刻)。由决策时刻tn到tn+1的过程来说明后状态Q值更新,系统在tn时刻会发生状态转移,决策后的状态为xn。由此系统经过一段时间到达tn+1时刻,此时需要采取行动并更新tn时刻的状态Q值。后状态Q值更新是指:在tn+1时刻利用决策后的状态Q值(即是xn+1的Q值),更新tn时刻决策后的状态xn的Q值。
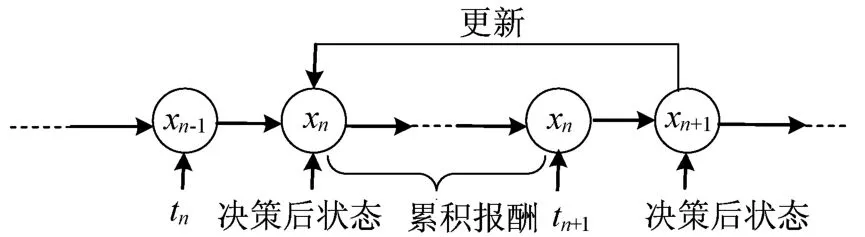
图1 后状态Q值更新过程
因此,解决在决策时刻tn+1的行动选择和Q值函数更新具有一般性。系统在该时刻状态为xn,若en+1为某个 i类业务到达事件,则行动选择如下:
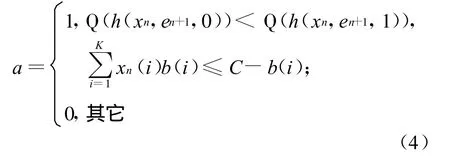
其中,h(xn,en+1,0)、h(xn,en+1,1)分别表示采取拒绝与接受行动后的系统状态。(4)式能利用行动后状态Q值函数大小选择行动,是因为此时行动只有拒绝和接受这2个状态,采取行动后的状态可由(1)式确定,而且状态Q值函数能通过查找Q值表得到,这充分利用了呼叫接入控制系统的特征。为了避免陷入局部最优解,采用ε-greedy策略选择行动。对于业务离开事件,只更新状态Q值,并默认a=0。选择行动后观察下一系统状态xn+1。
根据文献[8,9],给出该问题平均准则下的即时差分公式为:

其中,¯ηn为平均报酬的学习值,则有:

其中,c(xn)为(tn,tn+1]间的累积报酬,在这段时间内系统状态为xn,其逗留时间 Δtn=tn+1-tn,则累积报酬为:

于是,可以得到决策时刻tn+1的Q值更新公式为:

其中,γn为学习步长,这种状态Q值更新方式能有效解决平均准则下CTMDP[7]。
具体的事件驱动Q学习算法步骤如下:
(1)初始化每个状态Q 值,¯η0=0,设置学习步数 N,用 n记录学习步数,令 n:=0。
(2)观察tn时刻后系统状态xn,等待下一事件en+1发生,记录发生时间 tn+1。计算状态 xn的逗留时间Δtn,利用(7)式计算累积报酬c(xn)。
(3)如果en+1是某个业务到达事件,根据(4)式采用ε-greedy策略选择行动a,如果为业务离开事件,令行动a=0,观察确定系统的下一状态xn+1。
(4)选择学习步长γn,利用(6)~(8)式更新Q(xn)。
(5)n:=n+1,若 n >N,转第(6)步 ;否则 ,转第(2)步。
(6)学习结束,根据所得状态Q值,求解在各状态x下,各类业务到达事件e发生时的最优行动(业务离开不需要决策),从而获得最优策略L。
3 数值实例和实验结果
考虑一个实际呼叫接入控制系统实例,系统的总带宽C为12个单位,包含3类业务,各类业务参数见表1所列。设参数ε=0.15,各状态Q值均为0,初始状态为(0,0,0),学习步数 N=400万步。

表1 各类业务参数
本文分别使用事件驱动Q学习和Q学习进行模拟仿真。从统计意义上来说,Q学习所得策略对于平均报酬要好于事件驱动Q学习,这是由于Q学习需要的学习要素多,学习得更充分。2种学习算法所得平均报酬变化曲线如图2所示,这里每学习5万步产生一个策略,根据所产生策略,模拟实际系统的运行过程(模拟步数150万),统计得到该策略的平均报酬。

图2 2种学习对应平均报酬变化曲线
从图2可以看出,2种学习算法收敛于同一水平,但与Q学习相比,事件驱动Q学习在学习较少的步数时就能得到相对稳定的结果。其原因是事件驱动Q学习只存储和更新状态Q值,而其需要学习的状态值函数比Q学习少,因此状态Q值更新频繁,学习速度快。
表2所列给出了2种Q学习算法的收敛步数、收敛时间、状态空间和平均报酬。经计算,在该问题中Q学习状态空间大小为840个,事件驱动Q学习由于不需要把事件扩充为状态,其状态空间大小为140。
在INTEL双核CPU1.73 GHz,内存为1 G的PC机上对2种算法的学习用时进行测试。统计结果显示,Q学习在60×5万步后结果趋于稳定,平均用时为20.82 s,而事件驱动Q学习在16×5万步后结果就趋于稳定,平均用时仅为6.60 s,这表明了事件驱动Q学习的有效性。

表2 2种算法相关结果比较
表3所列给出了总是接受策略、Q学习所得策略和事件驱动Q学习所得策略对应长期平均报酬和3类业务的拒绝率。由表3可以看出,与总是接受策略相比,2种Q学习所得策略对应长期平均报酬有明显提高,说明2种Q学习算法均得到了较好的优化策略;2种Q学习所得策略下各参数结果非常接近,这说明2种学习算法得到的最优策略基本一致,从而进一步表明了事件驱动Q学习的有效性。另外,比较3类业务的拒绝率情况发现,在2种Q学习所得最优策略下,业务2的拒绝率相对较大,而业务1拒绝率相对较小,这表明采用计时报酬方式下,业务拒绝率与业务报酬率正相关,与业务带宽和离开率负相关。这为网络运营商制定合理的报酬率,以获得最大的网络收益提供了参考。

表3 不同策略的长期平均报酬和3类业务的拒绝率
4 结束语
本文结合后状态Q值更新方法,研究了最优呼叫接入控制问题基于事件驱动Q学习的优化算法。算法既是对Q学习在求解该类问题时的改进,也是对文献[6]给出的简单Q学习算法的扩展。在学习过程中,事件驱动Q学习只存储和更新状态的Q值函数,同时采用后状态Q值更新方法。从仿真结果可以看出,该算法能很好地解决这类问题,具有存储空间小、收敛速度快、模型无关的优点。随着业务类型的不断增加,呼叫接入控制系统将会更加复杂,事件驱动Q学习的优势也将会更加突出。另外,本文使用计时报酬代替固定报酬,并根据仿真结果分析了最优策略下业务拒绝率与业务特征的关系,由于带宽资源有限,计时报酬将会成为一种重要的发展趋势,分析这种关系对网络运营商来说具有重要的参考意义。本文讨论的是单节点呼叫接入控制问题,对于多个节点情况有待进一步研究。
[1] 周亚平,奚宏生,殷保群,等.连续时间 Markov决策过程在呼叫接入控制中的应用[J].控制与决策,2001,16(Z1):795-799.
[2] M arbach P,Tsitsiklis JN.A neuro-dynam ic p rog ramm ing approach to call adm ission control in integ rated service netw ork s:the single link case,Technical Repor t LIDS-P-2402[R/OL].Laboratory for Inform ation and Decision System s,1997.[2008-09-06].http://eprints.kfupm.edu.sa/73464/.
[3] Choi J,Kw on T,Choi Y,et al.Call adm ission con trol for m ultimedia services in mobile cellular netwo rk s:a Markov decision approach[C]//IEEE International Symposium on Com puter Communications,Antibes,2000:594-599.
[4] Senou ciSM,Beylot A,Pujolle G.Call adm ission con trol in cellular netw orks:a reinforcement learning solu tion[J].International Journal of Netw ork Managemen t,2004,14(2):89-103.
[5] Yu Fei,W ong V W S,Leung V C M.A new QoS p rovisioningm ethod for adaptive multimedia in w ireless netw ork s[J].IEEE Transactions on Vehicular Technology,2008,57(3):1899-1909.
[6] 王利存,郑应平.一类事件驱动马氏决策过程的Q学习[J].系统工程与电子技术,2001,23(4):80-82.
[7] Das T K,GosaviA,M ahadevan S,et al.Solving sem i-M arkov decision problem using average rew ard rein forcement learning[J].M anagem en t Science,1999,45(4):560-574.
[8] 唐 昊,万海峰,韩江洪,等.基于多Agen t强化学习的多站点CSPS系统的协作look-ahead控制[J].自动化学报,2010,36(2):289-296.
[9] 岳 峰.一阶非线性随机系统的学习优化控制[J].合肥工业大学学报:自然科学版,2010,33(5):679-682.
Application of event driven Q-leaning in call adm ission control
REN Fu-biao, ZHOU Lei, MA Xue-sen, WEIZhen-chun
(School of Compu ter and Inform ation,Hefei University of Technology,H efei 230009,China)
Optimal calladm ission control(CAC)based on tim e com pensation is concerned in this paper.The continuous-time M arkov decision processes(CTMDP)for the system is estab lished,and amethod of afterstate Q-value updating is introduced according to the characteristicsof the system.Then an optimal algorithm of event driven Q-learning is proposed to solve the calladmission control problem.Finally,an examp le of numerical simu lation is given.The sim ulation resu lts show that the p roposed algorithm needs lessmemory and has faster convergence than Q-learning.And on the basisof the experimental resu lts,the relationship between the rejection rate of business and the characteristics of business is analyzed under optimal calladmission policy.
continuous-time Markov decision processes(CTMDP);event driven Q-learning;call admission control(CAC)
TP202.7
A
1003-5060(2011)01-0076-04
10.3969/j.issn.1003-5060.2011.01.018
2010-02-01;
2010-06-28
国家自然科学基金资助项目(60873003);教育部回国人员科研启动基金资助项目(2009AKZR 0279);安徽省自然科学基金资助项目(090412046)和安徽省高校自然科学研究重点资助项目(KJ2008A 058)
任付彪(1983-),男,安徽界首人,合肥工业大学硕士生;
魏振春(1978-),男,宁夏青铜峡人,博士,合肥工业大学副教授,硕士生导师.
(责任编辑 张秋娟)
猜你喜欢
环球人物(2022年4期)2022-02-22
纺织科学研究(2021年9期)2021-10-14
小资CHIC!ELEGANCE(2021年32期)2021-09-18
人生与伴侣·共同关注(2020年11期)2020-11-23
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
海外星云(2015年15期)2015-12-01
出版广角(2014年22期)2014-12-12
小学阅读指南·高年级版(2014年2期)2014-05-27
中国新闻周刊(2008年4期)2008-02-18
军事历史(1997年5期)1997-08-21
