
基于双字哈希的PAT树词典机制的研究
2011-01-18 07:17郭宏文
黑龙江生态工程职业学院学报 2011年1期
赵 丽 郭宏文
(黑龙江生态工程职业学院 计算机技术系,哈尔滨 150025)
中文信息处理技术是重要的计算机应用技术,它已渗透到计算机应用的各个领域。中文自动分词是中文信息处理的一项重要的基础性工作,许多中文信息处理项目中都涉及到分词问题。分词的算法可分为有词典及无词典两大类。>有词典分词算法是以分词词典作为分词的基础,其中正向最大匹配算法、逆向最大匹配算法及全切分算法是基本且有效的分词算法[2]。
目前,分词词典机制种类较多,但典型的主要有整词二分的词典机制、基于TRIE树的词典机制及逐字二分的词典机制。随着研究的深入,还有其他学者提出的双字哈希词典机制、基于改进的PAT树词典机制及四字哈希词典机制。这些词典机制围绕着分词的准确率及分词速度作了逐步改进,但随着网络的发展及信息量成级数增长的趋势,分词的词典机制还有待加强和提高,以满足分词工作的需要。
本文首先介绍了基于双字哈希的词典机制及基于改进的PAT树词典机制,结合两种方法的优点,提出了基于双字哈希的PAT树词典机制,最后通过实验对新的词典机制和已有的词典机制在分词准确率及分词的时间、空间效率上做了比较。
1 两种相关词典机制的介绍
1.1 基于双字哈希的词典机制
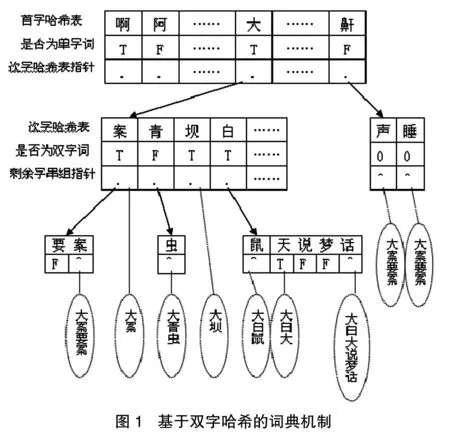
据有些学者统计,在汉语中单字词和双字词最多,可以占到94%的比例,双字词出现的频率也最高,而三字词、四字词以及多字词相对较少,且出现的频率也低。针对这种情况,有些学者提出了基于首字哈希机制的改进算法,其中学者李玉虎提出的双字哈希索引机制[3]在查询速度上有了很大的提高,双字哈希索引机制仅对词条的前两个字建立哈希索引,通过双字哈希索引,构建了深度为2的TRIE子树,词的剩余字串则按序组成类似整词二分的词典正文,具体结构可见图1。
1.2 首字哈希的PAT树词典机制
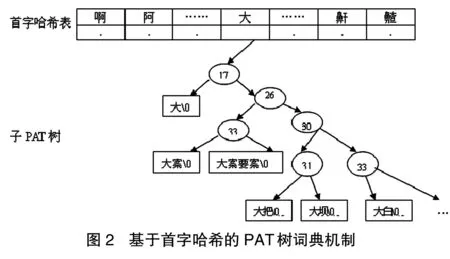
学者马哲、姚敏对基于PAT树的分词词典机制提出了改进方案,即在PAT树结构中加入了首字哈希表,把一棵大的PAT树分解成多个基于首字的小PAT树,以减小树的深度,使空间效率得到提高[4]。基于首字哈希的PAT树词典机制由首字哈希表及PAT树两部分组成,具体结构可见图2。同单纯的PAT树机制相比,基于哈希散列的PAT树词典机制在空间上多了一个首字哈希表。加入首字哈希表后,PAT树的深度减小了,因而从根结点到叶子结点的平均路径也变小了。
2 基于双字哈希的PAT树词典机制
在双字哈希的词典机制中,仅对词条的前两个字建立哈希索引,而对词余字采取类似整词二分的机制,在多字词的查询速度上有待提高。基于首字哈希的PAT树词典机制,仅对首字采用哈希机制,对词余字采用PAT树机制,这样的结构在查询速度上获得了较大进步,但在词典的存储空间及维护上,需要改善。
针对基于双字哈希的词典机制及基于首字哈希的PAT树词典机制的优点和不足,本文提出了基于双字哈希的PAT树词典机制。基于双字哈希的PAT树分词词典由三部分组成:首字哈希表、次字哈希表和词余字PAT树,具体结构可见图3。
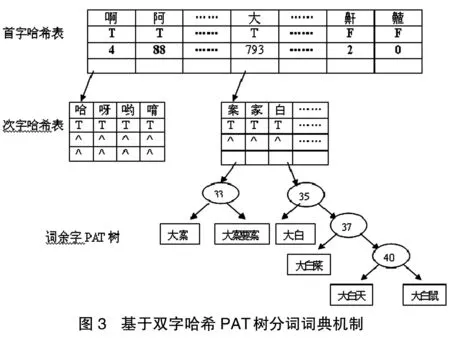
2.1 首字哈希表
首字哈希表包括首字单元、是否为词、次字入口项个数及次字入口项指针。首字哈希表的长度由常用字的个数决定。本文根据GB2312-80中所含的6 763个常用汉字,设置首字哈希表的长度为6 763个单元,哈希函数采用去留余数法,实现关键字与地址的一一对应。
2.1.1 首字单元
即词的第一个汉字及其相关信息。GB2312-80中规定汉字在计算机中存储的94个区中的第16-87个区内存放汉字且每个区中的0号位置不存放汉字,所以首字在汉字编码表中的偏移量可定义为如下公式:
C1=80H+区码+20H
C2=80H+位码+20H
M=(C1-16)×94+(C2-1)
其中M为首字在汉字编码表中的位置,C1为高位机内码,C2为低位机内码。有了这样的定义,便可以通过一步映射直接定位首字。本文采用去留余数法来构建哈希函数,即H(K)=M mod L,其中M为首字字符的机内码,L为哈希表表长。
2.1.2 是否为词
标识此首字是否为单字词。
2.1.3 次字入口项个数
标识以此首字为词的词的个数。
2.1.4 次字入口项指针
指向首字对应的次字哈希表。
2.2 次字哈希表
由于汉语词语分布不均匀,而且计算机内存空间有限,对于词次字不可能采用统一的定长表长,具体每个词次字哈希表的长度由首字对应的词次字个数和设定的哈希表的装填因子a有关,本论文中的装填因子设置为0.75,当次字哈希表中记录数所占比例超过表长的75%时,次字哈希表的长度会自动增至原来的2倍,从而降低产生冲突的可能。装填因子a可由下面公式得出
2.2.1 次字单元
即词的第二个汉字及相关信息。由两字及多字词的词次字组成,由于以首字为词的词个数不确定,所以,次字哈希表采用不定长存储。
2.2.2 是否为词
标识首字及次字组成的字串是否为二字词。
2.2.3 冲突指针域
当次字哈希散列中出现冲突时,采用链地址法来解决冲突,所以,在次字哈希表中给出冲突指针域,指向由哈希函数计算得到相同位置的词次字组成的链表。
2.2.4 余字入口项指针
指向词余字PAT树根结点。
2.3 词余字PAT树
词余字PAT树的深度与多字词的长度有关。一个词包含的字数越多,则对应的PAT树深度越深。但在汉语中,多字词所占比例很小,所以,词余字的PAT树并不会占用太多空间。
2.3.1 内部结点
用来存储词条的二进制比较位,由于一个汉字字符的机内码为16位,所以,在16n+1处出现分支;当比较位为0时,转向左子树;当比较位为1时,转向右子树。
2.3.2 叶子结点
用来存储词条信息,即汉字的机内码。
3 词典机制性能分析
本文使用搜狗网提供的互联网语料库中的MINI版作为训练集和测试集,采用基于双字哈希的PAT树机制,通过统计语言处理模式的方法,生成22词条的分词词典,最长词条为11字词。测试环境选择3GWS分词系统,此系统可加载用户自定义的词典。
3.1 分词效率的测试
为了全面分析及测试本文提出的基于双字哈希的PAT树分词词典机制的效果,笔者也选择了不同学科的文字材料对分词词典进行了测试,测试结果如下:
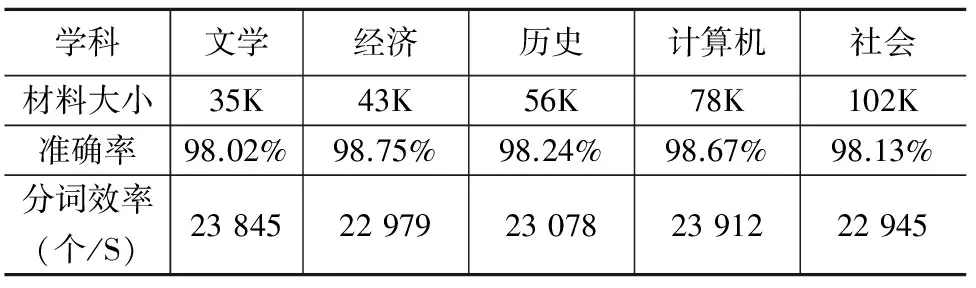
表1 基于双字哈希PAT树分词词典机制的分词效果
由上面的统计结果可以看出,本文提出的分词词典机制,对文学、经济、历史、计算机、社会等学科门类进行统计分词的准确率在98%以上,这样的准确率主要是因为采用了封闭测试的方法,所以准确率比较高。剩下的小于2%的错误主要是歧义字段,其中大部分为组合型歧义,这也是统计方法的不足之处。同时从算法处理结果可以看出,首字哈希—词尾PAT树机制减少了平均查询路径,从而使分词的效率得到了提高。
3.2 与其他词典机制的比较
下面从时间及空间角度对基于双字哈希的PAT树的词典机制、双字哈希词典机制及基于改进的PAT树机制进行比较。
3.2.1 空间
基于双字哈希的PAT树词典机制与双字哈希词典机制在前两字的处理上采用相同的方法,但在词余字的处理上前者采用PAT树机制,后者采用类似整评词二分的词典下文机制,所以在空间上基于双字哈希的词典机制要优于双字哈希的PAT树词典机制。基于改进的PAT树机制,由于只对首字采用了哈希机制,而对于词余字采用PAT树机制,这样的结构在空间上较优,前两种机制在空间效率上都要差一些。
综上可得,在空间效率上,三种词典机制的排序为:
双字哈希机制<双字哈希的PAT树机制<改进的PAT树机制
3.2.2 时间
下面通过具体的实验数据对基于双字哈希的PAT树的词典机制、双字哈希词典机制及基于改进的PAT树机制进行比较。实验环境仍为3GWS分词系统。为确保实验数据的准确性,测试使用的词典中词条数为22万,最长词条为11字词,测试方法如下:
(1)采用确定词条的查询方法,对词典中所有词条均查询一次。
(2)任取一段文本(2万字左右),采用逆向最大匹配法切分该文本。
(3)任取一段文本(3万字左右),采用逆向最大匹配法切分该文本。
三种词典机制在分词时间效率上的比较结果可见表2。
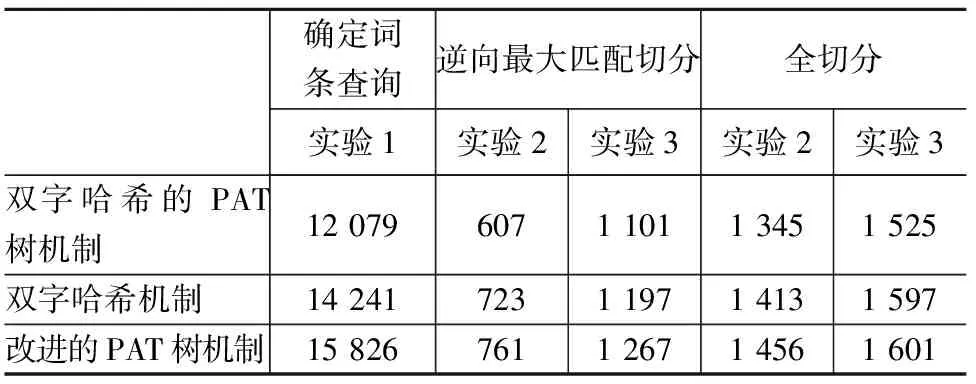
表2 三种词典机制时间效率上的比较 单位:ms
由表2可以看出,对于三种不同的词典机制,其分词的时间效率略有差异,通过实验数据可以得出,双字哈希的PAT树机制在分词的时间效率上略高于其他两种词典机制。
[1]吴栋,滕育平.中文信息检索引擎中的分词与检索技术[J].计算机应用,2004,24(7):28~31.
[2]张启宇,朱玲,张雅萍.中文分词算法研究综述[J].情报探索,2008,(11):53~56.
[3]李玉虎,陈玉健,孙家广.一种中文分词词典新机制——双字哈希机制[J].中文信息学报,2003,4(17):13~18.
[4]马哲,姚敏.一种改进的基于PATRICIA树的汉语自动分词词典机制[J].华南理工大学学报:自然科学版,2004,(32):28~32.
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
电脑爱好者(2020年20期)2020-10-22
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
知识经济·中国直销(2016年5期)2016-11-07
知识经济·中国直销(2016年4期)2016-11-07
工业设计(2016年8期)2016-04-16
知识经济·中国直销(2016年10期)2016-02-27
电脑爱好者(2015年13期)2015-09-10
信息安全研究(2015年3期)2015-02-28
