
基于概率主题模型的动作识别算法研究
2011-06-09 08:05王向慧
长春工程学院学报(自然科学版) 2011年3期
王向慧
(朝阳师范高等专科学校数学计算机系,朝阳122000)
概率主题模型近年来在计算机视觉领域得到了广泛应用,概率主体模型源自文本处理领域,主题模型是一种生成概率模型,也可以应用于图像、生物图像以及其他多维数据的识别、分类和数据挖掘。文献[1]提出利用时空兴趣点以及主题模型LDA(Latent Dirichlet Allocation)[2]进行动作识别,文献[3]则利用光流特征,利用改进的LDA进行动作识别。本文提出了一种新的动作识别算法,在提取视频中的时空兴趣点的基础上,利用3D-SIFT描述算子[4],采用k-means的方法生成码本,利用概率主题模型LDA,通过将每个兴趣点划分为不同的动作类别,从而实现较复杂情况下的动作识别。
1 动作表示
1.1 兴趣点检测
Dollar等人[5]提出的时空兴趣点检测方法可以从视频序列中提取丰富的时空兴趣点,本文同样采用基于Gabor滤波器和Gaussian滤波器相结合的时空兴趣点检测方法,首先使用高斯滤波器在空间域上对图像进行滤波,然后使用一维的Gabor滤波器在时间域上作用对图像序列。图1是以参数σ=2和τ=2情况下,在Weizmann数据库上的检测结果。

图1 Weizmann数据库上兴趣点检测的结果图
1.2 3D-SIFT描述算子
3D-SIFT特征描述子是由Scovanner等人[4]提出的一种三维时空梯度方向直方图,可以看作是经典的尺度不变特征变换描述算子(2D-SIFT)从静态图像到视频序列的扩展,由于能够更好地适应缩放、旋转、仿射变换以及噪声带来的影响。本文采用3D-SIFT的特征描述方式准确地捕捉到视频数据的时空特性本质。
首先,通过增加时间轴上的梯度信息将SIFT描述子从二维扩展到了三维,每一个像素点的梯度定义如下:

其中,Lx、Ly和Lt分别为x方向,y方向和时间轴t方向上的一阶导数。每一个像素点对应一个(θ,φ),描述了空间和时间上的梯度方向。然后,对θ和φ分别建立直方图,得到一个二维直方图,由此在每一个时空兴趣点一定的时空邻域内统计所有像素点的(θ,φ)信息来得到一个1×256维的特征向量。
1.3 码本表示
由于人体在外观、行为方式上以及视频拍摄角度等方面存在各种差异,因此同一种动作在不同视频中产生的兴趣点不尽相同,但针对同一种动作,这些兴趣点的特征存在着相似性。因此从兴趣点的特征集合中,提取更高层、能够代表相同动作的特征模式,将有助于动作识别。
利用“词袋”(bag-of-words)的思想,在得到时空兴趣点位置的基础上,采用k-means聚类算法对训练数据集中提取出的特征集合进行聚类,生成码本。所有时空单词组成的集合V={w1,w2,...,wn}称为时空码本,其中n为聚类中心的个数。对于不同的动作视频,视频中的每个兴趣点通过聚类,被划分为不同类别的单词,这样,一段视频可以看成是由一些单词(兴趣点)构成的一篇文档,在后续的动作识别过程中通过计算兴趣点的特征并建立概率主题模型实现对视频以及兴趣点的分类。
2 基于主题模型的识别
主题模型来源于文本处理领域,主题模型的核心思想是认为一个文档是由一系列的主题分布组成的,而每个主题又是由一系列的关键词组成。区别于传统bag of words模型,主题模型强调文档是由文档—主题—关键词3层关系组成,文档不是仅有单个主题组成。而是由多个主题组成。同样,在视频的人体动作识别领域,视频片段可以看作是由不同的动作类别(主题)构成的文档,每个动作类别由一系列表示这个动作类别的兴趣点(关键词)组成。
2.1 LDA主题模型
本文采用目前被广泛使用的主题模型LDA[2]。LDA是一种概率生成模型,其基本的思想是文档被表示为隐藏主题(latent topics)的随机混合。如图2(a)所示,对于视频集合D中的任意一段视频w=(w1,w2,...,wN),LDA使用如下方法生成:

图2 图模型
(1)选择N,这里N表示为视频的长度(包含单词的个数),且N ~Poisson(ξ);
(2)选择 θ,θ~ Dir(α);
(3)对N个单词中的每一个单词wn来说:
(a)选择一个主题zn ,其中zn~Multinomial(θ);
(b)选择一个单词wn,其中wn来源于p(wn|zn,β),这是一个在zn,β条件下的多项分布。
其中 βij=p(wj=1|zi=1),假定 Dirichlet分布的维数为k维,主题zn的维数也是k。
在给定α,β的情况下,主题的混合参数θ,N个主题的变量z,以及N个单词的一个联合分布如下:

2.2 动作识别
得到LDA模型的参数后,给定一个新的视频序列,假定测试序列表示为 w=(w1,w2,...,wN),其中wi为每个兴趣点代表的关键词,在LDA中,主要的问题就是解决给定w,α,β的情况下,θ,z的后验分布:

直接计算这个分布是很困难的,利用在文献[2]中提出的变分推断方法可计算 p(zn|w,α,β),其基本思想是利用一个变分分布q(θ,z)近似逼近p(zn|w,α,β)。首先将原始的LDA模型进行扩展,如图2(b)所示,β是一个k×V的随机矩阵,假设每一行都是独立采样于一个可交换的Dirichlet分布,选择一个可以分离的分布:
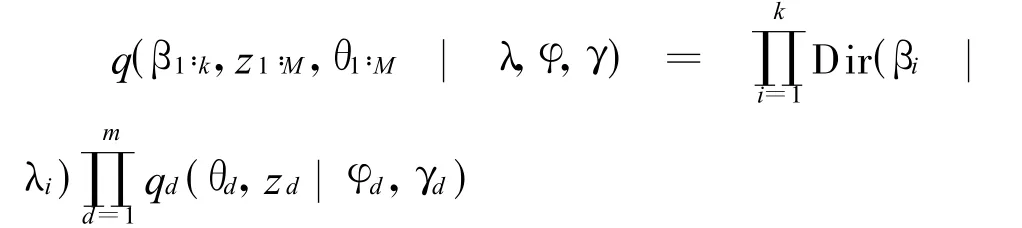
最小化q和p之间的KL-divergence,可得到下面的结果:

不断迭代可得到变分参数(γ*,φ*),然后从Dir(γ*(w))中选取一个样本θ,其中θ表示当前视频片段真正的主题混合成分。因此,真正的混合比例θ*可以从Dir(γ*(w))中产生的样本均值得到。参数 φn是p(zn|wn)的近似 。由于zn服从Mult(θ*),可得到一段视频所属类别的概率分布为 p(zn|w)
当视频中只有一个动作的时候,可采用上式计算整个视频片段中的动作类别。在实际情况中,一段视频中情况比较复杂,例如多个人做不同的动作或单个人做一系列不同的动作。在这种情况下,本文提出利用得到的φn即p(zn|wn),为每一个兴趣点表示的单词都分配不同的动作类别,这样的表示使得对整个视频的整体分类,转化为对当前帧上兴趣点代表的单词的分类。通过判断当前帧上不同类别的单词的个数,当某一类别的兴趣点的数量大于预设值的阈值时(本文设置该阈值为5),表明当前的视频中,存在该类动作。这样的分类方法能够对更复杂的视频进行处理。
3 实验结果及分析
3.1 数据库
对3个行为数据集Weizmann[6]、KTH[7]以及我们录制的视频数据库分别进行了测试,为了进一步验证本文提出的方法的有效性,我们录制了自己的动作数据库,该库包含由6个人完成的11个动作,训练数据共66段视频。为了测试更加复杂的情况,这个数据库还包括了几段在一个场景中有多个动作的测试视频。
3.2 实验结果及分析
对不同的数据集分别进行训练,本文采用留一法验证实验效果(leave one out),训练过程中,每一段视频仅仅包含一个动作,KTH数据库以σ=2,τ=2.5为的参数进行兴趣点检测,Weizmann数据库以及我们的数据库则采用σ=2,τ=2为参数进行兴趣点检测。从视频中抽取出兴趣点后,再采用3D-SIFT(时空梯度直方图)特征描述方式建立兴趣点样本特征集合,采用k-means聚类算法对样本特征集合进行聚类建立了样本空间的时空码本,建立码本后,利用 LDA模型进行学习训练。图3(a)(b)(c)分别为在这3个数据集上的识别混淆矩阵,码本大小均为1 000。


图3 识别混淆矩阵及不同码书大小的平均识别率
由于k-means聚类算法的初始类别随机产生,且聚类维数的选取对识别性能都产生影响。实验给出了不同大小的码本对识别率的影响,如图3(d)所示。可以看出,该方法受到聚类维数的影响较小。为了做进一步的对比,表1给出了本算法与其他方法的对比结果。

表1 在KTH和Weizmann两类数据库上,与其他方法的比较的结果
可以看出在识别率方面,本算法的结果已经到达或超过一些算法。以上的结果是在每段视频中仅包含一个人的情况下得到的结果,由于采用概率主题模型进行识别,视频中的每个兴趣点都被分类为不同的主题(动作类别),因此为了进一步验证该算法,在2种更加复杂的情况下分别进行了测试,如图4和图5所示。

图4 多人完成不同的动作(跳、走、跑、打拳)

图5 同一段视频中单人完成过不同的动作(行走、弯腰、行走)
实验结果表明,由于采用了概率主题模型,提出的方法不仅能识别视频中的当个动作,而且当视频中存在多个人完成不同的动作,或是同一个人完成不同的动作的较复杂的情况时,也能有效地识别。实验也同时表明抽取兴趣点的时空特征对动作进行表征,能够更好地适应光照变化以及人体的穿着和动作差异等环境因素的影响。
4 结语
通过提出一种新的动作识别算法,在提取视频中的时空兴趣点的基础上,利用3D-SIFT描述算子,和概率主题模型LDA对视频进行分类。由于主题模型将每个兴趣点划分为不同的动作类别,该方法不仅能够处理一段视频中包含一个动作的简单情况,同时也可以处理视频中包含多个动作的情况,实验结果验证了该方法的有效性。但是需要注意的是,该方法仅仅指出了兴趣点表示的动作类别,关于动作发生的位置信息,也就是动作的精确定位,并没有给出精确的结果,这也是下一步研究工作的重点。
[1]Niebles J C,Wang H,Fei-Fe L i.Unsupervised learning of human action categories using spatial-temporal words[J].International Journal of Computer Vision,2008,79(3):299-318.
[2]Blei,D M,Ng,etc.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003,13(3):993-1022.
[3]Yang Wang,Greg Mori.Human action recognition by semilatent topic models[J].IEEE T ransactions on Pattern Analysis and Machine Intelligence(PAMI),2009,31(10):1762-1774.
[4]Scovanner P,Ali S,Shah M.A 3-dimensional sift descriptor and its application to action recognition[A].Shah M.In Proceedings of the 15th international conference on Multimedia[C].Beijing,2007:357-360
[5]Dollar P,Rabaud V,Cottrell G,etc.Behavior recognition via sparse spatio-temporal features[J].IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance,2005,16(3):65-72.
[6]BLANKM,OREL I CK L G,SHECHT MAN E,etc.Actions as space time shapes[A].SHECHT M ANE.Proc of IEEE International Conference on Computer Vision[C].Beijing:2005:167-172.
[7]Schuldt,Laptev C,Caputo B I.Recognizing human actions:a local SVM approach[J].ICPR,2004,17(2):32-36.
[8]Dhillon P S,Nowozin S,Lampert C H..Combining appearance and motion for human action classification in video[J].CVPR,2008,23(1):1-8.
[9]Liu J,Ali S,Shah M.Recognizing human actions using multiple features[J].CVPR,2008,23(3):1-8.
猜你喜欢
南京邮电大学学报(自然科学版)(2022年4期)2022-09-20
四川党的建设(2022年8期)2022-04-28
中国民航大学学报(2021年3期)2021-08-04
小学生学习指导(低年级)(2020年11期)2020-12-14
通信学报(2020年3期)2020-04-06
作文大王·低年级(2018年10期)2018-12-06
纯粹数学与应用数学(2018年3期)2018-10-10
民族古籍研究(2018年1期)2018-05-21
小猕猴智力画刊(2016年5期)2016-05-14
新校长(2016年8期)2016-01-10
