
两组数据分布的一致性分析及其应用
2011-06-09 08:05谷照升刘志明
长春工程学院学报(自然科学版) 2011年3期
谷照升,刘志明
(长春工程学院理学院,长春130012)
1 问题
对于来自2个一维总体X、Y的样本,通过不同的统计方法,可以分析其不同的相关性。计算其相关系数ρXY的统计量rXY,可以反映X与Y的线性关系水平;计算其间距(欧氏距离、马氏距离、Minkowski距离等),可以得到X与Y在数量上的相近程度;计算其夹角余弦(力学上用MAC)或指数相似系数,可以度量样本间的相似度。
但分布的内在联系具有多样性,有时需要考证的不是2个分布间的数量关系,而是分布高低变化的一致程度,即X取值变大时,Y的取值相应变大还是变小。互抑关系应该是此消彼长,互惠(互助)关系则往往亦步亦趋,同高同低。本文称这种关系为分布一致水平,或分布趋势一致性。例如,在水质分析时,对n个观测点的两种污染指标总氮、总磷浓度采样,得到总氮浓度CN=(Nc1,Nc2,Nc3,…,Ncn),总磷浓度 CP=(Pc1,Pc2,Pc3,…,Pcn)2个样本[1-2]。需要考查的是:总氮、总磷浓度分布是否呈现出同高同低;或相反,总氮浓度越高,总磷浓度越低;还是二者分布上相互独立,没有显著的关联。其结论对寻找污染过程、污染源、污染机理有很大帮助。这类问题很多。例如,同一批学生2门不同课程的成绩关系,2种生物数量在不同地区的分布情况,等等。目前为止,尚未有合适的统计方法对这样的考查目标给出定量分析或描述。
本文将对这一类问题(2个任意总体分布的一致性)给出相应的归一化的统计量,并对这一统计量的性质做了严格的论证,为其应用提供了理论依据。最后,给出几个应用模型。
2 思路
设{Z0,Z1,…,Zn-1},{W0,W1,…,Wn-1}分别是基于n个观测点的2组不同属性或指标的观测值。将Z0,Z1,…,Zn-1按递增方式排序,仍记为Z0,Z1,…,Zn-1,即Z0≤Z1≤Z2≤…≤Zn-1,W0,W1,…,Wn-1的角标作同步调整,再将W0,W1,…,Wn-1按递增排序为WX0≤WX1≤… ≤WXn-1。X0,X1,…Xn-1是排序后{Wi}编号 0,1,…,n-1的一个排列。
显然,最理想的一致性分布(互惠关系、趋同)是 :X0=0,X1=1,…Xn-1=n-1,即W0,W1,…,Wn-1按递增排序后为W0≤W1≤…≤Wn-1,高对高,低对低。反之,若恰有X0=n-1,X1=n-2,…,Xn-1=0,即Wn-1≤Wn-2≤… ≤W0,则说明二者的对应刚好是高对低,低对高,这恰好是最大程度的互抑关系。
所以,解决问题的关键思路在于排序后数据编号间的位置关系,而不需要数据值本身参与计算。排列 X0,X1,…,Xn-1与0,1,…,n-1匹配度越大,则两者的一致水平越高。
如何刻画排列X0,X1,…,Xn-1与0,1,…,n-1的匹配度呢?
3 预备定理
定理1 设{ai}、{bi}满足0<a1<a2<a3<… <an,0<b1<b2<b3<… <bn。j1,j2,j3,…,jn是1,2,3,…,n的任一排列,n>1。
(1)若j1,j2,j3,…,jn不是n,…,2,3,1顺序的排列,则有
(2)若j1,j2,j3,…,jn是非自然排列1,2,3,…,n(逆序数 >0)则有
证明 用归纳法。
n=2时,a1b1+a2b2-(a2b1+a1b2)=a1b1-a2b1+a2b2-a1b2=(a1-a2)b1-(a1-a2)b2=(a1-a2)(b1-b2)>0,所以(1)、(2)成立。
(a)若r=1,则当i=1,2,3,…,k时,ji恰好取遍2至k+1,即bji恰好取遍b2至bk+1,同时k+1-(i-1)也恰好取遍2至k+1,即bk+1-(i-1)(i=1,2,3,…,k)也恰好取遍b2至bk+1。
将b2至bk+1仍理解为由k个元素组成的递增数列。根据式(1)有所以
(b)若r>1,总有某个jp=1,p<k+1且当i=1,2,3,…,k时,ji取不到 r。这时 apbjpapbk+1-(p-1)=apbr-apbk+1-(p-1)+apbjp-apbr


根据式(1)仍有
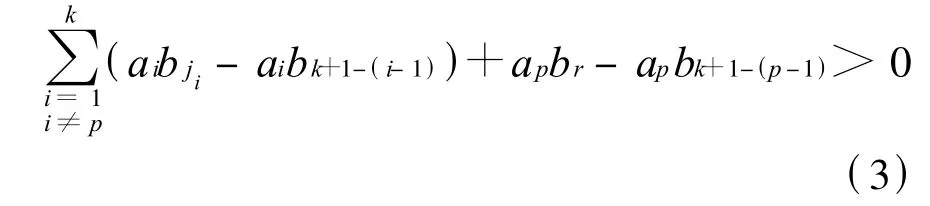
而apbjp-apbr+ak+1(br-b1)=apb1-apbr+ak+1(br-b1)=ap(b1-br)+ak+1(br-b1)=(ak+1-ap)(br-b1)
由于p<k+1,所以ak+1-ap>0,故(ak+1-ap)(br-b1)>0即

(a)若r=k+1,则当i=1,2,3,…,k时,ji恰好取遍1至k,即bji恰好取遍b1至bk。
(b)若r<k+1,总有某个jp=k+1,p<k+1且当 i=1,2,3,…,k时,ji取不到r。这时apbjpapbp=apbr-apbp+apbjp-apbr


在2,3,…,k,i≠p)与ap共同不重复遍历a1至ak,bji与br不重复遍历b1至bk。
而apbjp-apbr+ak+1(br-bk+1)=apbk+1-apbr+ak+1(br-bk+1)=ap(bk+1-br)+ak+1(br-bk+1)=(ak+1-ap)(br-bk+1)
由于 p<k+1,所以ak+1-ap>0,故(ak+1-ap)(br-bk+1)<0即
最后证明(3)。当 i=1,2,3,…,n时,ji和n-(i-1)恰好遍历1至k一次,所以

再由(1),(3)得证。
4 分布趋势一致性统计量及其数字特征
约定E(*)、D(*)分别表示 *的期望、方差,n是一自然数,n>1。
(X0,X1,X2,…,Xn-1)是0,1,2,…,n-1的一个排列,取
在第2部分定义的刻画排列X0,X1,…,Xn-1与0,1,…,n-1的匹配度的统计量

满足
定理2 0≤DL≤1。
证明 在定理1(3)中,取ai=i-1,bi=i-1,得 DL ≤1。仅当 Xi=i时DL=0,Xi=n-1-i时DL=1。i=0,2,3,…,n-1。
定理3 若(X0,X1,X2,…,Xn-1)是0,1,2,…,n-1的等可能随机排列,则
证明(X0,X1,X2,…,Xn-1)是 0,1,2,…,n-1的等可能随机排列,则

要刻画(X0,X1,X2,…,Xn-1)与(0,1,2,…,n-1)的一致水平(分布趋势一致性)(distribution uniformity level),可定义统计量UL=1-DL。
则UL同样满足:0≤UL≤1;当(X0,X1,X2,…,Xn-1)是0,1,2,…,n-1的等可能随机排列时,
统计量UL或DL取值的含义是:UL的值越接近1,说明(X0,X1,X2,…,Xn-1)的取值排列越接近自然排列(0,1,2,…,n-1);UL的值越接近0,说明(X0,X1,X2,…,Xn-1)的取值排列越接近逆序数最大的排列(n-1,n-2,…,1,0)。根据定理3,若UL的值接近0.5,说明(X0,X1,X2,…,Xn-1)的排列与排列(0,1,2,…,n-1)基本没有关系。
5 统计量UL应用的数学模型
回到第2部分的问题上。设{Z0,Z1,…,Zn-1},{W0,W1,…,Wn-1}分别是基于n个观测点的2组不同总体Z,W(属性或指标)的观测值。且有Z0≤Z1≤Z2≤…≤Zn-1,W0,W1,…,Wn-1按递增排序为WX0≤WX1≤… ≤WXn-1。X0,X1,…Xn-1是排序后{Wi}脚标编号0,1,…,n-1的一个排列。可以直接定义{Zi}与{Wi}的分布一致水平

定理4 ULZ,W=ULW,Z
证明 在上述标记下,对每个0≤i≤n-1,记Xi=j。若先将{Wi}排序后重新调整下标编号,为W0≤W1≤W2≤…≤Wn-1,再将调整下标编号后的{Zi}排序为ZY0≤ZY1≤…≤ZYn-1,则有Yj=i。从而ULZ,W中的(Xi-i)2刚好对应ULW,Z中的(Yj-j)2。证毕 。
根据定理4,在实际应用时,只需将2组数据递增排序,任选一组为准,重新标记下标编号,用新的编号计算ULZ,W。
通常{Zi}与{Wi}中都可能存在多个值相同的情况,排序后,这些点是相邻的,比如,z0=0.3,z1=0.1,z2=0.2,z3=0.3;w0=1.0,w1=2.1,w2=1.0,w3=1.3。
排序后为z1,z2,z0,z3或z1,z2,z3,z0;以及w0,w2,w3,w1或w2,w0,w3,w1。
这时,ULZ,W因排序方式的不同会得到不同的值。所以,需要约定对排序后相同的数据段在重新编制下标序号时参照另一组数据按从小到大、或从大到小实现,这时会分别得到最小ULZ,W和最大ULZ,W。可根据实际要研究的模型按需求计算。
注:脚标编号用0,1,…,n-1(从0开始),是为和计算机编程的表达习惯一致。若编号改用1,2,…,n-1,n,则只需定义
6 应用举例
6.1 教学评估
用{Zi}与{Wi}分别表示一个班全体学生某两科(如外语和高数)的成绩,计算ULZ,W可以确定这两门课程在知识关联、能力需求、学习效果上是否存在某种互助或互抑的相互关系。
6.2 不同污染质浓度分布的相关性分析
在水库水质分析中,设{Zi}与{Wi}分别表示两种污染质在n个点的浓度,计算ULZ,W能够辅助判断,二者在污染源和迁移过程上是否具有内在的一致性。
6.3 同一地区不同生物种群的互抑、互惠关系分析
设{Zi}与{Wi}分别表示两种生物(如狼和羊)在n个点(或n个时期)的生存水平,计算ULZ,W可以获知,二者是互抑型关系,还是互惠型关系。或者没有明显的关联。
7 遗留问题
对ULZ,W可以给出改进算法或给出更易于计算的定义。在 2个样本特定的关联或影响水平上,ULZ,W的分布函数及相关数字特征的研究,进而得到能够用于区间估计和假设检验的分布规律。这些,都是仍需解决的问题。
[1]郑文瑞,王新代,纪昆,等.非确定数学方法在水污染状况风险评价中的应用[J].吉林大学学报:地球科学版,2003,33(1):59-62.
[2]谷照升,刘晓端,徐清.密云水库水质分布的相关性研究[J].岩矿测试,2004,23(4):278-284.
猜你喜欢
公民与法治(2022年5期)2022-07-29
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
现代农村科技(2021年2期)2021-03-15
科普童话·学霸日记(2020年1期)2020-05-08
绿色科技(2019年12期)2019-07-15
小天使·一年级语数英综合(2019年2期)2019-01-10
科技视界(2016年19期)2017-05-18
燕山大学学报(2015年4期)2015-12-25
