
BP原理及其在林木胸径模拟中的实现
2011-08-09 13:02车少辉张建国段爱国骆昱春
东北林业大学学报 2011年8期
车少辉 张建国 段爱国 骆昱春
(中国林业科学研究院林业研究所,北京,100091) (江西省林业科学院)
人工神经网络(ANN)是模仿人脑结构及功能的新型信息处理系统,由许多简单的并行处理单元按某种方式相互连接而成。BP采用误差反向传播算法的模型,属于多层前馈网络的一种,也是目前应用最广泛的网络类型[1-2]。
近年来,BP在林木生长模型中应用越来越多[3-7],但有关BP理论和林木生长建模实践融为一体的介绍很少。盛仲飙[8]介绍BP原理时,主要介绍网络拓扑结构,而对神经元—网络结构—算法实现缺少系统连贯的表述。笔者从这3个方面系统剖析BP原理,阐述了其模拟S型曲线的依据,并借助MATLAB编程语言实现林木胸径仿真,以期推动BP网络的完善和在林业上的推广。
1 BP神经元的数学模型
神经网络的神经元称节点或处理单元,具有多输入单输出的属性,是模型的基本组成部分。每个节点均有相同的结构,其动作在时间和空间上均同步[9-10]。
①神经元模型如图1所示。
②神经元模型的数学表达式:
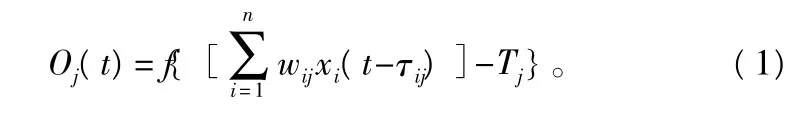
式中:Oj(t)为t时刻神经元j的输出信息;Xi(t)为t时刻神经元j接收来自神经元i的输入信息;τij为输入输出间的突轴时延;Tj为神经元j的阈值;f为神经元激活函数。
τij取单位时间1时:

引入阈值的输入 X0。令 X0=-1,W0j=Tj,则式中-Tj=X0W0j,合并得

图1 神经元模型

③神经元激活函数。f也称转移函数或活化函数。其基本作用:控制输入对输出的激活作用,对输入、输出进行函数转换;将可能无限域的输入变换成指定的有限范围内的输出。不同的神经元数学模型主要区别在于激活函数不同,使神经元具有差异的信息处理特性。
理论上说,任何可微的数学函数都可作为激活函数,线性的、S型曲线和双曲线正切是最常用的函数[11]。
a.线性激活函数:通常用在输出层,将输出结果映射到任意实数范围内。
表达式:

b.Sigmoid函数:简称S型函数,其特点是函数本身及其导数都是连续的,且是一个严格单增的光滑函数,并具有渐进特性。为实数域R映射到[0,1]闭集的非减连续函数,代表状态连续型神经元模型。
Logsigmoid表达式:

其导数为:f'(x)=e-x/(1+e-x)2,且 f'(x)=f(x)(1-f(x))。
c.双曲正切函数:激活函数的值域有时在-1~1之间变化,且关于原点奇对称。为此,常采用双极性S型函数(Tansigmoid)形式:

其导数为:f'(x)=1/2[1-f2(x)]。
有研究证明[12],双曲正切函数Tansigmoid计算速度比指数函数Logigmoid快,实际中经常采用双曲正切函数作激活函数,隐层采用非线性激活函数才可以实现非线性映射功能。
2 BP的拓扑结构
BP拓扑结构由大量神经元连接构成的一个层次型网络(如图2),包括:①含节点的输入层:用来描述问题的自变量;②具有节点的输出层:描述因变量;③一个或多个包含节点的隐层:帮助捕获数据中的非线性特征。
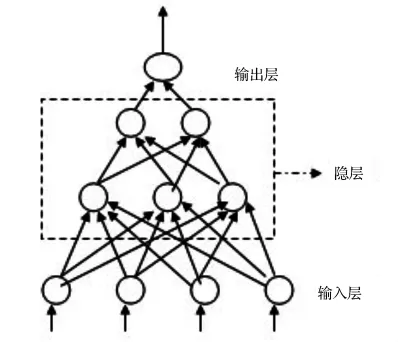
图2 BP类屋次型网络结构
前一层的输出为下一层的输入,各神经元仅接受前一层的输入,无反馈;输入层节点不具有计算功能,单单接受外来信号,并传递给各隐层节点;隐层是神经网络的内部信息处理层,负责信息变换,可设计多层;最后一个隐层传递到输出层,输出层节点具备处理信息能力,可以完成非线性和线性的映射。输入层节点不存在激活函数,隐层通常采用非线性激活函数(S型函数),输出层根据期望输出的范围,选择采用线性或非线性激活函数。大多数输出层神经元采用线性函数,非线性函数容易造成预测结果失真[13]。
K.Funahashi证明[14],单隐层的网络可以任意精度地逼近任何连续函数,只有拟合不连续函数(如锯齿波等)时,才需要两个隐层来缩小误差。而误差精度的提高实际上也可以通过增加隐含层中的神经元数目来获得,其训练效果也比增加层数更容易观察和调整[15]。输入层和输出层节点数量取决于采用自变量和因变量的数量,隐层节点数量通常采用“试凑法”和“剪枝法”确定。例如:采用林木密度、林龄、立地质量来模拟林木的胸径和树高,输入层应选3个节点,即输入样本的3个指标值作为一个网络输入向量。输出层选2个节点,代表胸径、树高。
3 BP标准算法
BP模型须经过学习和工作两个阶段来实现其功能。学习或训练过程中,各神经元的连接权动态调整规则称为学习算法或学习规则或训练规则。
BP采用一种有导师学习模式,学习阶段分解为2个过程(图3):第一,信息正向传播过程(a)。输入通过输入层经隐层到达输出层,计算每个输出节点的实际值,与期望值比较,若误差未达到规定的精度要求,即转入误差反向传播。若达到精度要求,完成此样本学习。第二,误差反向传播阶段(b)。误差从输出层经过隐层到输入层,在此过程中采用梯度下降法调整权值和阈值,经过数次迭代使得误差函数达到最小。通过不断的迭代学习,当网络对于各种给定的输入均能产生所期望的输出时,完成学习过程。

图3 BP学习模式
以单隐层BP(3-2-1)模型为例(图4),隐层采用单极性sigmoid函数,输出层采用线性函数,剖析BP算法原理。

图4 单隐层BP网络
输入向量:X=(x1,x2,x3)T,图4 中 x0=-1 为隐层神经元引入阈值而设置的;隐层输出向量Y=(y1,y2)T,图中y0=-1是为输出层神经元引入阈值而设置的;输出层神经元O输出向量为O=(o1);期望输出向量为d=(d1)。输入层到隐层之间的权值矩阵用V表示,V=(V1,V2),其中列向量V1=(v11,v21,v31)T,V2=(v12,v22,v32)T,vij表示输入层第 i个神经元与隐层神经元j的连接权值。隐层到输出层之间的权值矩阵用W表示,W=(w11,w21)T,wjk为第 j个隐层神经元与第 k个输出神经元的权值,由于输出层仅一个神经元,故k=1。v01,v02,v01分别为神经元y1,y2,O的阈值。
①信号正向传播过程中,各层信号之间的数学关系。
接受信号的输入层:X=(x1,x2,x3)T。
对于隐层:
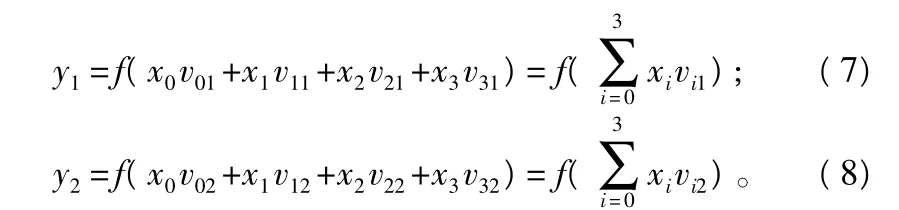
对于输出层,有

f(x)=x。将(7)、(8)式及已知量代入(9)中得网络模型的输出:
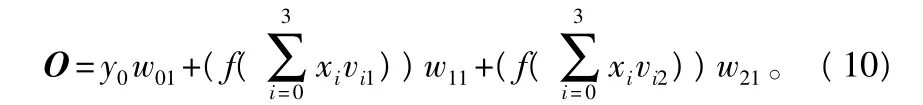
f(x)=1/(1+exp(-x))。若(10)式中的f采用线性函数,则输出向量O永远是输入值加权的某种线性组合,不可能模拟复杂的非线性曲线,就无法模拟林木生长的S型曲线。正是由于隐层采用非线性sigmoid类激活函数,才使得输出值为不同权重S型函数的线性和非线性组合值,适合模拟生长型S型曲线。
②误差的反向传播,各层信号之间的数学关系。
当网络输出O与期望输出d存在输出误差时,定义误差能量E。
E=1/2(d-o)2,将(9)、(10)式代入,
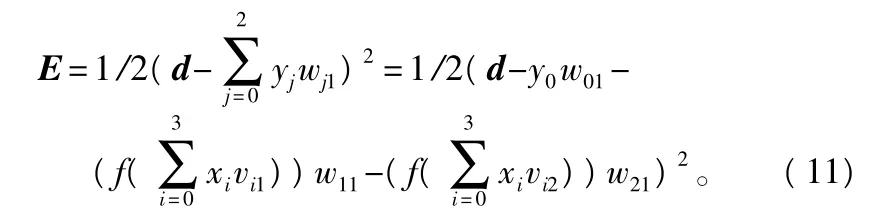
由上式可以看出,误差函数是各层权值w,v和输入x和期望输出d的函数,因此在输入和期望输出一定的情况下,调整权值可改变误差E。
误差梯度下降算法又称最速下降算法,是BP算法中最简单的一种。误差函数E,在某点(wi,vj)的梯度▽E是一个向量,其方向是E(wi,vj)增长最快的方向。显然,负梯度方向是误差减少最快的方向。
对于3层BP网络,对输出层:
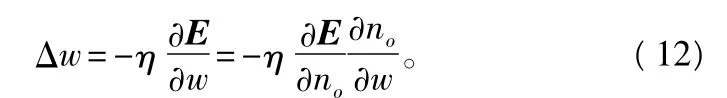
no为输出层神经元o的净输入。
对隐层:

ny为隐层神经元y的净输入。
对输出层和输入层各定义一个误差信号,令

综合式(9)和式(14),改写式(12)为:

即输出层神经元k与隐层神经元j的连接权调整量为输出层神经元k的误差信号、隐层神经元j的输出、学习率η之积的相反数。
综合式(7)、式(8)和式(15)改写式(13)为:

即隐层神经元j与输入神经元i的连接权调整量为隐层神经元j的误差信号、输入神经元i的输入、学习率之积的相反数。
如果已知输出层和输入层的误差信号就可以求出权值调整量的值,展开式(14)、式(15),输出层
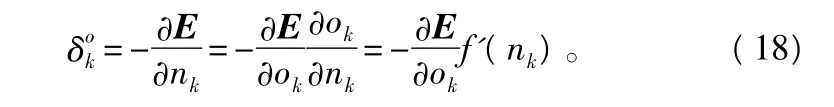
隐层

利用E=1/2(d-o)式计算式(18)、式(19)中网络误差对输出层的偏导利用式(11)中网络误差对隐层输出的偏导:
将以上两个偏导结果代入式(18)和式(19),应用sigmoid函数f'(x)=f(x)(1-f(x)),得:

其中,输出层神经元激活函数为f(x)=x;
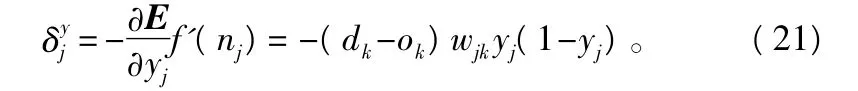
至此两个误差信号的推导已经完成,将式(20),(21)代回式(16)和式(17)推出此3层BP权值阈值调整公式为

从权值调整过程来看,BP算法有自身的缺陷:容易陷入误差局部最小值。而且标准算法收敛结果与初始点的选择有关,最终不一定能够收敛到全局误差最小点。因而各种改进BP算法应运而生,例如:建立在确定梯度下降的最优化方向上的增加动量项法,或者基于最优化理论的训练算法(共轭梯度算法、拟牛顿法、Levenberg-Marquardt算法)。
在单个处理单元层次,无论采用哪种学习规则进行调整,其算法都十分简单,但当大量处理单元集体进行权值调整时,网络就出现智能的特性,其中有意义的信息就分布地存储在调节后的权值矩阵中。
经过学习过程的网络,才是一个成熟的网络模型。给网络一个输入向量,网络根据储存的信息输出模拟结果。BP网络的工作过程很简单,不需要迭代运算。
4 BP网络林木平均胸径仿真
试验数据取自大岗山年珠林场杉木密度实验林。密度试验林于1982年使用1年生的实生苗造林,每个区组分5个水平:2 m×3 m(A 密度,1 667 株/hm2)、2 m×1.5 m(B 密度,3 333株/hm2)、2 m×1 m(C 密度,5 000 株/hm2)、1 m×1.5 m(D 密度,6 667株/hm2)、1 m×1 m(E 密度,10 000株/hm2),3 个区组,共15个小区。采用随机区组排列,每个小区外设置保护行,四角设置固定水泥桩为界。
调查方法:对每株林木进行挂牌,各小区沿等高线蛇形顺序编号,并标注胸高位置。每次调查均于林分停止生长后或下一年开始生长前进行。树龄在10 a前逐年记录,之后隔年调查1次。2~5 a时,测定每木树高、冠幅及树高达到1.3 m以上的胸径。6年生开始,在每个小区的上、中、下各选2株优势木,用以求算立地指数。截止2008年,连续观测14次。根据时间间隔一致的原则,剔除第7、9年观测数据,选用12次测量数据,共计180个样本对建立神经网络模型。
由林木生长理论可知胸径生长是一个非线性过程,适合于BP模拟。K.Funahashi证明单隐层BP模型能够以任意精度逼近任意函数,笔者选取单隐层BP模型。输入向量为林分3个属性值:林木密度D(株/hm2);立地指数S(m);林龄A(a)。输出:林木平均胸径Dg(cm)。首先,将输入输出向量分别归一化到[-1,1]区间,以消除量纲差异和加速网络收敛过程。隐层和输出层预设激活函数分别为tansigmoid函数和purelin函数;算法采用最速梯度下降法;隐层节点数用“试凑法”确定。输入向量格式为一列一个样本,包含3个属性值,同时此样本有对应的输出向量,两者构成输入输出样本对。输入的列数与输出的列数一致,即样本数量一定;而两个向量的维数(行数)可以不同。
利用MATLAB神经网络工具箱内置函数newff创建BP模型,格式为:newff(P,T,[S1S2…S(N-1)],{F1F2…F(N+1)}),P,T分别为输入和期望响应矩阵;Si为各隐层神经元的数目,不包括输入层和输出层;Fi为网路各层的传递函数类型,包括隐层和输出层的传递函数;数据集随机分配,且训练集∶验证集 ∶测试集=0.7 ∶0.15 ∶0.15,未给出的参数均取 MATLAB默认值。
P=[D;S;A];网络模型输入三维向量;
T=[Dg];期望输出一维向量;
>>W=newff(p,t,5,{‘tansig’,‘purelin’},‘traingd’);创建BP网络模型W;
>>W.trainparam.lr=0.05;设置学习率;
>>W.trainparam.epochs=1000;最大迭代次数;
>>W.trainparam.goal=0.01;最小误差;
>>[W,tr]=train(W,p,t);训练网络,存储训练参数。
>>Y=sim(W,p);仿真输出;
最后,利用postmnmx()函数对Y反归一化还原为胸径值,完成模拟过程。
为了直观理解模拟情况,笔者选择MATLAB输出的两幅图说明。图5为不同数据集实测值(x轴)与模拟值(y轴)的关系,其中训练集、测试集、验证集和全部建模数据集的相关系数 R 分别为:0.977、0.962、0.985、0.977。图 6 展示了各种数据均方误差随迭代次数的变化,图中从细到粗依次为测试数据、训练数据、验证数据的模拟误差变化曲线。其中迭代935次时,模型收敛到Ems=0.01。模型参数存储在W中,利用MATLAB相关函数可以显示具体值,在此不再累述。

图5 模拟值与实测值的相关关系
5 结论与讨论
BP网络是一种有效的建模工具,广泛适应于各个领域。林木生长建模上应用BP模型的文章也越来愈多,笔者利用MATLAB神经网络工具箱实现了胸径仿真功能(R=0.977),结果说明,采用BP静态网络逼近动态数据是一种可行的方法,为BP模型在林木生长模型中的应用提供支持。
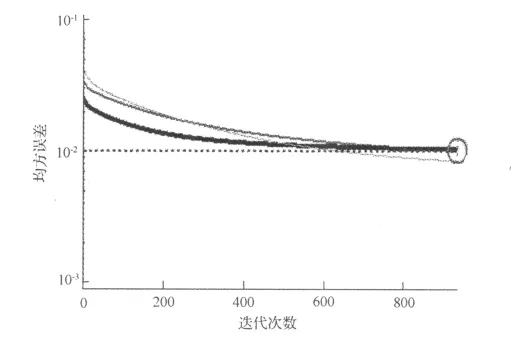
图6 均方误差随迭代次数的变化
BP标准算法(梯度最速下降算法)进行训练时,模型收敛速度慢(迭代935次),甚至有多次不收敛的情况出现;笔者侧重于研究BP原理及其在MATLAB中实现的过程,未对采用改进算法的模型进行比较。下一步的工作讨论各种算法对模型的收敛情况及其精度、泛化能力的影响。不同版本的MATLAB构建BP模型格式有些细微差别,但都能满足建模需求。
[1]Basheer I,Hajmeer M.Artificial neural networks:fundamentals,computing,design,and application[J].Journal of Microbiological Methods,2000,43(1):3-31.
[2]Rumelhart D,Hinton G,Williams R.Learning internal representations by error propagation,Parallel distributed processing:explorations in the microstructure of cognition,vol 1:foundations[M].Cambridge:MIT Press,1986.
[3]陈晨,郭芳,黄家荣,等.杉木人工林直径分布BP模型的研究[J].河南农业大学学报,2005,39(4):390-393.
[4]吴建华,卢炎生.基于神经网络的树木生长预测[J].长沙电力学院学报:自然科学版,2002,17(2):28-30.
[5]黄家荣,任谊群,高光芹.森林生长的人工神经网络建模[M].北京:中国农业出版社,2006.
[6]金星姬,贾炜玮,李凤日.基于BP人工神经网络的兴安落叶松天然林全林分生长模型的研究[J].植物研究,2008,28(3):370-374,384.
[7]洪伟,吴承祯.基于人工神经网络的森林资源管理模式研究[J].自然资源学报,1998,13(1):69-72.
[8]盛仲飙.BP神经网络原理及MATLAB仿真[J].渭南师范学院学报:综合版,2008,23(5):65-67.
[9]韩力群.人工神经网络教程[M].北京:北京邮电大学出版社,2006.
[10]田雨波.混合神经网络技术[M].北京:科学出版社,2009.
[11]Diamantopoulou M J,Milios E.Modelling total volume of dominant pine trees in reforestations via multivariate analysis and artificial neural network models[J].Biosystems Engineering,2010,105(3):306-315.
[12]Swingler K.Applying neural networks:a practical guide[M].London:Academic Press,1996.
[13]Khashei M,Bijari M.An artificial neural network(p,ád,áq)model for timeseries forecasting[J].Expert Systems with Applications,2010,37(1):479-489.
[14]Funahashi K.On the approximate realization of continuous mappings by neural networks[J].Neural Networks,1989,2(3):183-192.
[15]韩震,姜照华.基于神经网络的大连经济增长模拟与预测[J].大连理工大学学报,2001,41(6):752-756.
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
商洛学院学报(2020年4期)2020-07-08
人民珠江(2019年4期)2019-04-20
铁路计算机应用(2018年5期)2018-06-01
现代装饰(2018年5期)2018-05-26
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
电源技术(2015年5期)2015-08-22
