
句法分析与消解PCFG改进
2012-07-13 03:06金新生
电子设计工程 2012年4期
金新生
(河南省财经学校 河南 郑州 450012)
句法分析是自然语言处理的一个基本问题。许多自然语言处理任务,比如机器翻译、信息获取、自动文摘等都要依赖句法分析的精确结果才能最终获得满意的解决。随着信息社会的到来,人们对自然语言处理的需求日益迫切,因而对句法分析的研究具有重要的意义。
所谓句法分析是根据给定的语法,自动地推导出句子的语法结构,即句子所包含的句法单位和这些句法单位之间的关系。句法分析的目的主要有两个,一个是确定句子所包含的谱系结构,另一个是确定句子的各成分之间的关系。目前为止,句法分析的研究大体分为两种途径:基于规则的方法和基于统计的方法。而这两种途径目前分析的精确度仍然不高,离实际应用还有不少差距。
1 概率上下文无关文法
概率型上下文无关文法[1](Probabilistic Context Free Grammar or Stochastic Context Free Grammar)是最早也是最常用的句法分析分析模型,它是上下文无关文法的展,将CFG的每一条规则与概率组合,就构成PCFG。
PCFG的分析过程与非概率型上下文无关文法相同,也是从非终结符S开始扩展。通过概率型上下文无关文法赋予每棵分析树一个概率,当句子具有结构岐义时,可以利用该概率来选择句子的分析结果t*,即

分析树t的概率就是生成t所用到的所有产生式的条件概率的乘积:

其中,r是产生式,D(t)表示用于生成分析树t的有序产生式集合。
1.1 规则的概率
概率上下文无关语法跟非概率的上下文无关语法基本,区别只是在于给每条句法规则附加一个概率值。所给的概率值可以是来自语感,或者来自语料统计。不管来源如何,都必须满足:左部分符号相同的若干条规则,其概率之和等于1。
1.2 语句的概率
一棵分析树的概率,等于推导出这棵分析树时所使用的各条规则的概率的乘积。如,“咬/vt死/adj了/utl猎人/noun的/de狗/noun”得到的两棵分析树的概率计算如下所示[3]:


结果表明,前一种分析的概率小于后一种分析,这主要是因为在我们的语法中,由名词类短语构成句子的概率(0.1)小于由动词性短语构成句子的概率(0.2),由动词结构加“的”构成“的”字结构的概率(0.4)小于由名词性结构加“的”构成的“的”字结构的概率(0.6)。
同时也表明,这个词串分析为合法的句子(S)的概率是:

这个概率也就是语句“咬/vt死/adj了/utl猎人/noun的/de狗/noun”的概率。如果一个词串不合语法,其概率为0。
对于给定一个语句W=w1w2…wn和一部概率上下文无关语法G,有以下3个基本问题需要研究:
1)如何快速计算由语法G产生语句W的概率P(W|G)?
2)如果语句W有岐义的,如何快速选择概率最高的分析?
3)如何调整语法G的参数(即每条规则的概率),使得P(W|G)最大?
解决这些问题,需要引入两个概念:内部概率(Inside Probability)和外部概率(Outside Probability)。
1.3 内部概率
设A是语句推导过程中用到的一个非终结符,它的起点为i,终点为j;A的内部概率就是用语法G从A推导出词串wi…wj的概率。
我们先假定G中所有规则都遵从乔姆斯基范式,即,假定从A开始推导时所用的规则或者形如 “A→a”,或者形如“A→B C”(A,B,C)是非终结符,a是终结符)。 当规则右部是一个终结符时,有i=j,A的内部概率就是规则“A→n”的概率:


内部概率的计算是递归的,求一个非终结符的内部概率,需要先求出它的所在局部分析的各构成成分的内部概率。有了内部概率的概念,就可以顺利地解决上面提到的第1个问题。所谓“由语法产生语句W的概率”,就是α1,n(S)的内部概率。
有了内部概率的概念,上面提到的第2个问题也很容易解决。如果非终结符A是多个起点、终点都相同的局部分析的根,我们总是选择内部概率最大的那个局部分析,作为以后在若干个内含式岐义分析中排除那些概率较低的分析。如果起始符S是起点为1,终点为n的局部分(整个句子的分析可看成是一个特殊的局部分析)的根,并且这样的局部分析有若干个,我们最后就选择内部概率最大的那个局部分析作为输出结果。
1.4 外部概率
解决第3个问题(规则概率的调整)需要用到外部概率的概念。非终结符A的外部概率,是指给定概率上下文无关语法G和语句W时,推导出A的上下文的概率。
先考虑A是整个语句捆绑后的符号(或者从生成的观点看,是由A推导出整个语句)这一特殊情形,这时A(在句子范围内)没有上下文,如果A=S,A的外部概率为1.0,否则为0。

等式右边是一个克罗奈克函数,两参数数值相等时函数值为1,否则为0。
接下来,再进行一般化处理。A的外部概率涉及3个方面:
1)A做了哪个局部分析的成分,因为这个局部分析的上下文(姑且称之为“大语境”)必然也是A的上下文,它的外部概率必须影响A的外部概率;
2)这个局部分析所使用的规则的概率;
3)这个局部分析的构成成分中,A以外的其他构成成分的内部概率的乘积,因为其他构成成分也是A的上下文。
把这3种概率相乘,就得到A处于这个局部分析中的外部概率。如果只有一个这样的局部分析,那么它就是A的外部概率;如果存在多个这样的局部分析,可以用类似的方法得到A在每一个这样的局部分析中外部概率,经求和就得到A的外部概率。这样,当使用的规则不限于乔姆斯基范式时,外部概率的计算公式可重新表达为:

其中,是所有以A(A的起点和终点分别是i和j)为构成成分之一的局部分析的集合,C是这种分析的根,first(e)和last(e)是这种局部分析的起点和终点,rule(e)是这种局部分析用的规则,rhs(e)是这条规则的右部符号,即该局部分析的构成成分;B是该局部分析的外部概率;由此层层上推,必须先求出整个词串的概率。
1.5 规则使用的期望次数
现在我们来讨论如何调整语法G的参数。一个朴素的想法是,从训练语料(由已经标注句法结构的句子组成)中计算每条规则的使用次数;某规则的使用次数除以跟它左部相同的全部规则的使用次数之和,就是该规则的概率[1-2]。即:

其中,A是一个非终结符;ξ和μ都是由终结符和/或非终结符组在成的符号串,后者包括前者。
当规则不限于乔姆斯基范式时,计算期望次数的公式是:

其中,P(w1,…,w2)是整个语句的概率,即 α1,n(S)。 显然,如果这个概率为0(语句不合语法),就不应计算该语句分析过程中任何规则的使用次数。如果语句的概率大于0,我们则对于该规则的每一次使用,都计算该符号的外部概率、该规则的概率以及每个构成成分的内部概率,并且将这些概率相乘,然后求和,除以该语句的概率,便得到使用该规则的期望次数。
1.6 语法参数的调整
概率上下文无关语法的第3个基本问题是,如何调整语法G的参数,使得P(W|G)最大。为此,开始时可以随机地给每条规则赋予一个概率(但左部相同的规则的概率之和必须为1),得到语法G0;接着从训练语料用公式计算每一条规则的期望次数,并重新估计每一条规则的概率,得到语法G1。重复这些步骤,得到语法G2,G3,……,直到规则的概率收敛于最大似然估计值。每得到一部新的语法,都有可能使得训练语料中的平均概率有增加,因为语法中规则的概率更趋向于合理。不过,这种优化仍是局部的,并且是跟语料的性质有关的。如果语料的代表性不够,就很难说规则的概率估值是否合理。举一个极端的例子,假定训练语料训练语料仅仅包含语句“孩子/noun喜欢/vt狗/noun”,使用的是本章所列的句法规则,最后的结果“S→NP”、“S→VP”等规则的概率为 0,也就是说,把这些规则都“优化”掉了。所以语料的规模要有一定的代表性。
1.7 算法基本步骤
1)随机地给每条规则赋予一个概率,得到语法G0;
2)建立局部分析;
3)计算合法句子的概率;
4)获取外部概率;
5)获取规则使用的期望次数;
6)重新估计规则概率,得到语法Gi;
7)若得到的概率已收敛,则终止,否则转到步骤2)。
2 改进过的PCFG算法
2.1 用句子内部短语结构搭配+短语内部语义相关度进行句法消岐[2-4]
研究这两个句子:
例1:维修/vt图书馆/noun的/de空调/noun
从图 1A中结构抽取可得:“维修空调”(VP→VC NP,动宾结构),“XX 的空调”(定中结构),明显地“的”字结构在这样并没有起决定性作用。查 《知网》、《现代汉语语法信息词典》数据库、《现代汉语搭配词典》、《现代汉语实词搭配词典》,有“维修电机(动宾结构)”,而“空调”与“电机”的相似度为0.390 947,比较高,因此维修空调相关度为0.470 947,同样比较符合动宾结构搭配。从图1B中结构抽取可得:“维修图书馆”(VP→VC NP,动宾结构),“XX 的空调”(定中结构),查上述知识库:装修房子(动宾结构)。“房子”与“图书馆”相似度为0.111628,而“装修”与“维修”相似度为0.186047,所以“维修”和“图书馆”的相关度只有:0.106047。通过计算,我们很容易选择图1 A的分析。
例2:装修/vt图书馆/noun的/de工人/noun

图1 “维修图书馆的空调”结构分析Fig.1 Structure analysis of“repair of the library’s air conditioning”
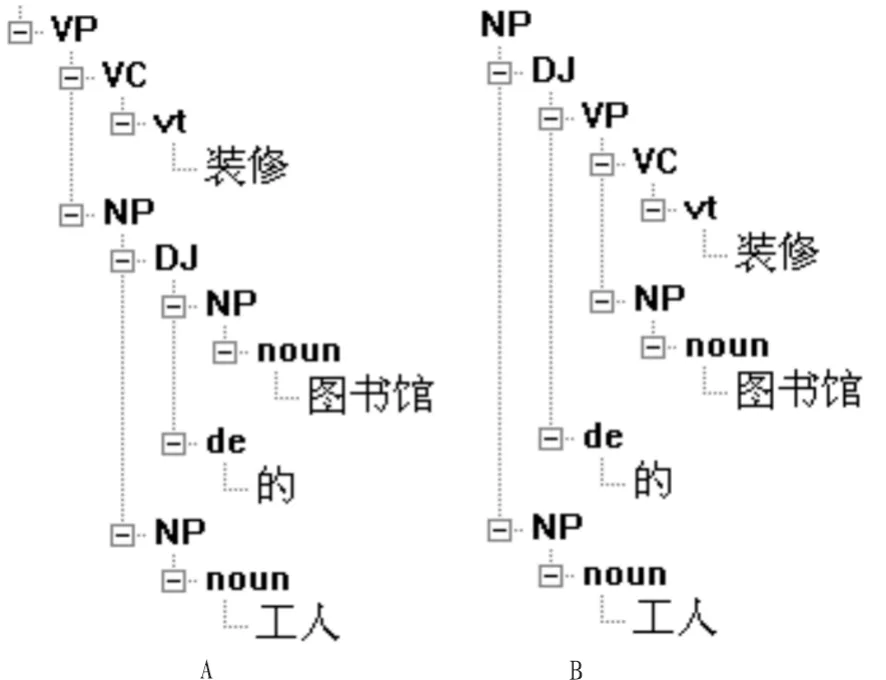
图2 “装修图书馆的工人”结构分析Fig.2 Structure analysis of workers of the library’s renovation
同样方法,我们可以轻松选择图2B的分析。
由此可知,句子结构内部的短语结构搭配(结构相关)和由词组的短语语义内部的相关度对消解这种句型岐义起决定作用。
2.2 利用逻辑相关解决岐义
再看看下面的句子:
例3:
1)孩子/noun喜欢/vt穿/vt好/adj衣服/noun
2)天/noun 很/adv 冷/adj,/jw穿/vt好/adj衣服/noun
从结构分析来看,利用词语搭配和语义相关度很难排岐。 但“天冷”→“穿好”,“喜欢”→“好衣服”,存在逻辑相关。
2.3 利用句子间成分前后相关进行消岐
考察下句:
例句4 I saw a girl with a telescope

图3 “喜欢穿好衣服”的结构分析Fig.3 Structure analysis of people being fond of fashion dress
根据上面实验结果,有3种意思:(为了能正确表达,本文为它加了上下文)
1)我用望远镜看到一个女孩(I took the telescope when I went out this morning,今早我出门时带上了望远镜,分析这个句子结构说明“我”与“望远镜”实际相关。)
2)我看到一个女孩和一个望远镜 (That telescope placed on goods,那个望远镜放在货架上,说明望远镜与女孩实际意义距离较大,实际相关度小。同时没有找到与“我”的特殊相关关系。)
3)我看到一个女孩带有望远镜。(Looked carefully,the telescope was in girl’s hand仔细一看,望远镜在女孩手中。说明望远镜与女孩实际存在相关。)
综上所述,我们可以定义句子成分结构语义关联度来进行句型消岐[2-3]:

其中:RPhraseStruct是句子总相关度;RPhraseStruct是短语搭配相关度,符合的取 1,不符合者取 0;R(Wi,Wj)phrase短语内部两个词汇意义相关度,可利用公式计算参考;LogicR是逻辑相关,符合取1,不符合取0,由于逻辑相关目前比较难计算,故此项可暂时省略;RContextInfor句间成分实际相关度,存在则取1,不存在则取0。
利用(9)对PCFG结果进行计算,Rsentence取最大值作为最后输出,则可有效地解决一些如上述类型的句子岐义。
3 结束语
由于汉语语法层次模糊的特点,所以以往很多学者分别研究的是未登录词、分词、词类、词义、句法各阶段最优,但是事实表明,未登录词、分词词类标注等都要不同程度地用到了句子结构信息和上下文语境信息,在不充分考虑到这些因素情况下的“各层最优”隐含着不少错误,并且这些错误会逐放大,可以想象:若未登录词认别错误,会对分词有影响,分词消歧错误,那么后面的所谓“词类标注、词义标注、句法分析”全部变成无稽之谈。故笔者在研究大量资料后,这种符合人的大脑思维方式的全局回溯式寻优应该是最好的解决办法,这也是笔者现在正在努力的方向。
[1]刘群,李素建.基于《知网》的词汇相似度计算[C]//第三届汉语词汇语义学研讨会,台北:中文计算语言学,2002.
[2]许云,樊孝忠,张锋.基于《知网》的语义相关度计算[J].北京理工大学学报,2005,25(5):411-414.
XU Yun,FAN Xiao-zhong,ZHANG Feng.Semantic relevancy computation based on HowNet[J].Journal of Beijing Institute of Technology,2005,25(5):411-414.
[3]陈小荷.现代汉语自动分析——Visual C++实现[M].北京:北京语言文化大学出版社,2000.
[4]詹卫东.面向中文信息处理的现代汉语短语结构规则研究[M].北京:清华大学出版社,2002.
[5]周强.基于语料库和面向统计学的自然语言处理技术介绍[J].计算科学,1995,22(4):36-40.
ZHOU Qiang.Natural language processing technology based on corpus and for statistics[J].Computing Science,1995,22(4):36-40.
[6]周强,黄昌宁.汉语概率型上下文无关语法的自动推导[J].计算机学报,1998,21(5):387-392.
ZHOU Qiang,HUANG Chang-ning.Chinese probabilistic contextfree grammar automatic derivation[J].Chinese Journal of computers,1998,21(5):387-392.
[7]刘群,张华平,俞鸿魁,等.基于层叠隐马模型的汉语词法分析[J].中国科学院计算技术研究所计算科学,2001(4):211-214.
LIU Qun,ZHANG Hua-ping,YU Hong-kui,et al.Chinese lexical analysis base on Hierarchical hidden Markov model[J].Institute of Computing Technology of Chinese Academy of Sciences,2001(4): 211-214.
[8]郭池,陈骏,王启祥.一种基于语料库的词义消岐策略[J].计算机学报,2005(6):99-102.
GUO Chi,CHEN Jun,WANG Qi-xiang.Word sense disambiguation strategy base on corpus[J].Journorl of Computer,2005(6):99-102.
猜你喜欢
新世纪智能(语文备考)(2020年4期)2020-07-25
时代英语·高一(2019年1期)2019-03-13
新高考(英语进阶)(2017年10期)2017-12-23
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
语文知识(2014年4期)2014-02-28
小雪花·初中高分作文(2009年8期)2009-11-16
