
模糊学习算法机器人相互协作模型研究
2012-08-26 08:05吴永琢
制造业自动化 2012年18期
吴永琢
WU Yong-zhuo
(青岛酒店管理职业技术学院,青岛 266100)
0 引言
在多机器人系统中逐渐采用多智能体技术,例如足球机器人就是其典型。它要求在复杂环境下,实现机器人的控制和相互协作。行为学习能够有效提高机器人的适应能力,传统的方式得到的信号并不理想。决策体系结构是整个系统的关键,本文选择了强化学习算法,同时引入了具有专家经验的模糊推理来弥补Q学习收敛性较差的缺点。通过建立模糊规则库,并且根据状态和动作不断调整Q学习参数,提高决策系统的自适应能力和速度。通过仿真实验,证明模糊Q学习算法的效果。
1 决策结构模型
决策系统通过感知器接收视觉系统收集的赛场的综合信息,并分析信息、建立规则库、Q学习、决定策略,最后将它们发送给通信系统。机器人的决策系统结构如图1所示,包括:模糊化模块、模糊规则库、Q学习单元、行为融合等。它主要负责决策进攻、防守,分析实时的现场环境、对方策略,利用模糊的Q学习算法对决策模块进行优化,然后将指令发送给机器人,控制它们的行动方式是进攻或避障。

图1 决策模型结构图
2 Q学习算法
强化学习是一种机器学习方法,是从环境到行为的映射学习,在机器人、智能控制等领域有许多应用。强化学习通过动作-评价获取知识,不断改进方案来适应周围环境。Q学习算法是强化学习中的一种,它和模型无关。
Q 学习方法的待学习目标函数用Q(s, a)表示,计算公式为:

其中0≤g≤1,r(s, a)表示立即回报,V×(s)是最优策略值。
在 Q学习中选择动作采用概率方法,选择动作ai的概率表示为:

将评估函数推导后得到:
进入老龄化社会以来,福利国家的经验促使中国政府也认识到国家必须为日益增多的老年人提供适当的生活保障,承担起必要的照顾和帮助老年人的责任。2000年开始采取一系列措施解决老年人的养老问题,其中最重要的就是调动和引导社会力量提供老年服务。而这个阶段与改革开放初期福利化改革的根本区别在于强化国家责任和推进社会化进程的并行及有效平衡。养老服务业管理体制的核心是理顺和规范政府和社会的关系,既要充分发挥政府的主导作用,又要充分发挥社会力量的主体作用;政府部门职责权限边界明确,社会力量权利义务具体清晰。
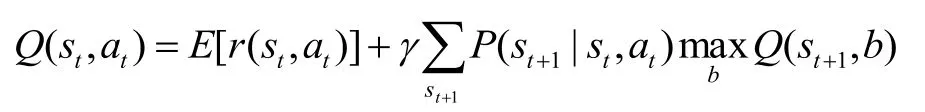

当Agent 应用在空间连续的环境,Q学习算法在连续的状态空间和动作空间的离散化, 效率低、收敛慢,因此本文提出基于模糊的Q学习算法来处理例如足球机器人比赛等多人相互协作的状态。
3 模糊Q学习算法和实现
足球赛场情况瞬息万变,因此状态空间数据量庞大,用Q学习算法会需要比较长的学习过程,因此本文在Q学习算法上将其优化,通过建立一个模糊规则库,将庞大的实际状态转化成为数不多的模糊状态,大大降低了状态空间数据的大小,从而提升学习速度。
3.1 算法设计
采用IF_THEN的模糊规则,在agent受到状态向量x后,利用模糊推理方法计算输出空间的每一分量权值:
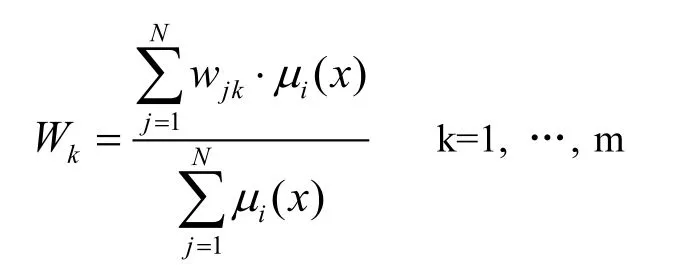
mi(x)表示IF_THEN规则里x的隶属度。动作选择采用模糊推理的方法,实行利用策略。当动作由agent执行以后,环境会给agent提供奖惩信号。假设收到奖励信号r,那么模糊规则的权值表示:
其中r表示受到的奖励,wmax是wk的最大值,a'jk表示自适应学习率。
建立的模糊规则表如表1所示。
3.2 算法的执行
Q学习的过程为:
1)观察目前的状态s;
2)通过计算状态被选中的概率,选择确定并且执行一个动作a;

公式中,T表示温度,其值的大小表示随机程度,值越大表示随机性就大。初始学习时,T值偏大,随着学习的深入,T值就逐渐降低来保证学习的良好效果。
3)观察下一个新状态s';
4)从环境中收到一个回报、强化的信号r;
5)根据状态和动作相应的调整Q值;
a表示状态动作被选频率,系数g=0.9。根据Q值来调整行为融合的加权值l。等到学习结束以后,l就按照贪婪策略来取值,Q值最大的就是对应l的加权值。
6)新状态满足条件,则结束本次学习;否则返回第2步执行。
4 仿真实验及结果
该方法的实验是在机器人足球仿真平台Robot Soccer上。在实验时的主要参数设为:学习率初始设为0.8,折扣因子0.9,选择动作时按照随机策略。

图2 Q学习曲线图

表1 模糊规则表
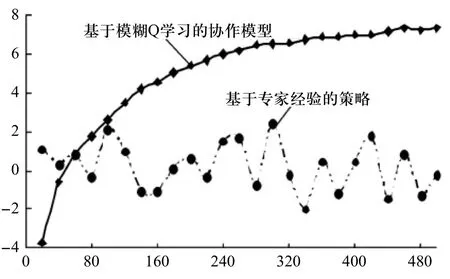
图3 净胜球统计对比图
图2表示的是机器人的进攻策略Q值,可以发现学习步数的增加,Q值迅速上升,到300步左右时,Q值就基本稳定在0.35。可见,模糊Q学习效果好、速度快。
接着分别采用传统的经验策略和模糊Q学习算法策略两种方式进行净胜球比赛统计,结果如图3所示。
在图3中进行了500场次的比赛,统计结果表明,传统的按照专家经验的净胜球明显没有优势和规律性,基本上在0上下震荡。而模糊Q学习模型就呈上升趋势,刚开始学习的阶段,输的比较多,没有经验的策略来得好。这说明系统还在学习,但随着比赛场次的增加,Q学习的不断改进开始逐渐显示其优势了,曲线明显上升,净胜球开始变成正值。到后来曲线走向开始变得平缓,是因为采用模糊Q学习方法后已经学到了比赛对方的大部分策略。实验结果表明,模糊Q学习策略很有效。
5 结束语
多机器人相互协作问题是机器人技术中的重要课题,本人设计了一个决策系统模型,首先分析了传统Q学习算法并指出其学习速度慢、收敛性差的不足,提出了模糊Q学习算法,建立了模糊规则库,将众多的实际状态映射成不多的模糊状态,减小了状态空间又提高了速度;然后设计了算法的学习过程等;最后通过仿真平台Robot Soccer将传统的经验策略和模糊Q学习策略比较,实验结果表明模糊Q学习算法的速度比较快、效果更好。
[1]张汝波, 杨广铭. Q学习及其在智能机器人局部路径规划中的应用研究[J]. 计算机研究与发展, 1999, 36(12):1430-1436.
[2]刘金馄. 机器人控制系统的设计与Matlab仿真[M]. 北京:清华大学出版社, 2008.
[3]vincente Feliu, Jose A.Somolinos, Andres Garcia.Inverse Dynamics Based ControI System for a Three-Degree-of-reedom Flexible Arm[J]. IEEE Trans.on Robotics and Auomation. 2003. 12(6): 1007-1014.
[4]Chang Deng. Meng Joo Er. Automatic generation of fuzzy inference systems by dynamic fuzzy Q-learning[C].Systems, Man and Cybernetics,2003. IEEE International Conference on, Volume:4, Oct. 5-8, 2003, 3206-321.
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
纺织科学研究(2021年9期)2021-10-14
数学小灵通(1-2年级)(2021年4期)2021-06-09
小学生作文(低年级适用)(2019年5期)2019-07-26
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
读友·少年文学(清雅版)(2018年12期)2018-04-04
Coco薇(2017年11期)2018-01-03
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
山东青年(2016年3期)2016-02-28
军事历史(1997年5期)1997-08-21
