
基于两阶段优化算法的客户信用评估问题研究
2013-12-23 05:24王兴宇四川大学
商场现代化 2013年3期
■王兴宇 四川大学
一、前言
目前,我国的信用卡业务虽然还处于发展初期,但是随着客户贷款数量的迅速增长,为了防范潜在风险,减少发卡机构的损失。在对客户发放信用卡之前,对其进行信用评估已成为解决客户信用风险的重要方法之一。决策树是基于统计理论的非参数识别技术,可以自动进行变量选择,降低维数,分类结果表达形式简单易懂,并可有效的用于对数据的处理,所以被广泛应用于数据挖掘的分类当中。但对于现实的信用评估问题,由于客户的信息量大、属性多,单独使用决策树易造成运算过程复杂。这就需要在建立决策树之前删除多余的属性,然后再用决策树进行分类。本文利用澳大利亚银行的数据研究信用评估问题,在建立决策树之前,采用GMDH输入输出模型先挑选中对分类结果影响较重要的属性,然后再利用决策树进行分类,以达到对决策树优化的效果。
二、相关模型方法概述
1. GMDH输入输出模型
数据分组处理算法(Group Method of Data Handling)是乌克兰科学院A.G.Ivakhnenko在1967年首次提出的。GMDH作为一种自动产生模型的算法,它使用的是演化(遗传、变异和选择)的原则,实现一个模型结构综合和模型确认的自动化过程,模型从数据中自动产生,以最优的传递函数网络的形式,重复产生大量具有增长复杂度的竞争模型。进行相应的模型确认并留下最好的选择,直到产生一个最优复杂度模型。
GMDH方法有两个基本思想:(1)以黑箱方法为主要方法分析输入输出关系;(2)用基本函数的网络互联来表达复杂函数。它从参考函数构成的初始模型(函数)集合出发,按一定的法则产生新的中间候选模型(遗传、变异),再经过筛选(选择),重复这样一个遗传、变异、选择和进化的过程,使中间候选模型的复杂度不断增加,直至得到最优复杂度模型。
2.决策树理论
决策树是一种类似于流程图的树结构,起源于20世纪70年代后期和80年代初期,由J.Ross Quinlan提出了ID3算法,这种算法使用贪心方法,以自顶向下的递归的分治方式构造,将数据从根节点向下逐步划分,在内部节点上进行属性的比较,训练集即被递归地划分为子集,最后形成分类的规则。比较经典的决策树算法有基于信息熵的ID3算法及能处理连续属性的C4.5算法。
ID3算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定集合的测试属性。对被选取的测试属性创建一个节点,并以该节点的属性标记,对该属性的每个值创建一个分支并以此来划分样本。C4.5算法是对ID3算法的改进,ID3处理的是离散的属性,而C4.5算法能处理连续的属性,并在以下几方面对ID3算法进行了改进:(1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;(2)在树构造过程中进行剪枝;(3)能够完成对连续属性的离散化处理;(4)能够对不完整数据进行处理。
三、两阶段优化算法模型及算法步骤
针对信用评估这一实际问题,本文将特征提取与决策树结合起来构建算法模型,以达到对决策树的优化。第一阶段:先用GMDH特征提取方法对原有属性进行筛选,从中抽取对结果影响较大的属性;第二阶段:用提取出的属性建立决策树模型,具体操作步骤如下:

(2)用K-G多项式建立因变量(输出)和自变量(输入)之间的一般关系,例如对于三输入单输出系统,可采取二次K-G多项式


(3)从具有外补充性质的选择准则中选出一个(或若干个)作为目标函数(体系),或称为外准则(体系),产生第一层中间模型。同时在训练集A上估计参数,对第一层中间模型进行筛选。根据外准则,在检测集B上对第一层中间模型进行筛选,选出的中间模型作为网络第二层的输入变量;
(4)形成最优复杂度模型网络结构。重复步骤3,可依次产生第二、第三…层中间模型,最终形成可用于分析的显式最优复杂度模型。即得出与输出变量最相关的几个输入变量,假设为xi,xj,…xn;
(5)计算xi,xj,…,xn的信息增益率,以信息增益率最大的属性作为根节点的测试属性,对属性的值创建分支,据此划分样本;
(6)在各节点内计算剩余属性的信息增益率,选择信息增益率最大的属性作为此分支的下一个测试属性,重复此步骤直到结点属性各分支下的训练样本属于同一类或者所有属性都已被用过为止生成决策树。
四、实证研究
1.样本及变量选择
为了验证本文所提方法的效果,本文采用了澳大利亚一家银行的信贷数据作为初始建模样本,共690条数据(已做预处理)。我们选取了14个类属性,1个决策属性,并对其做了相应的调整,例如A4最初有三个标签属性p、g、gg,这些标签被改为1、2、3。各类属性的详细信息如表1所示:
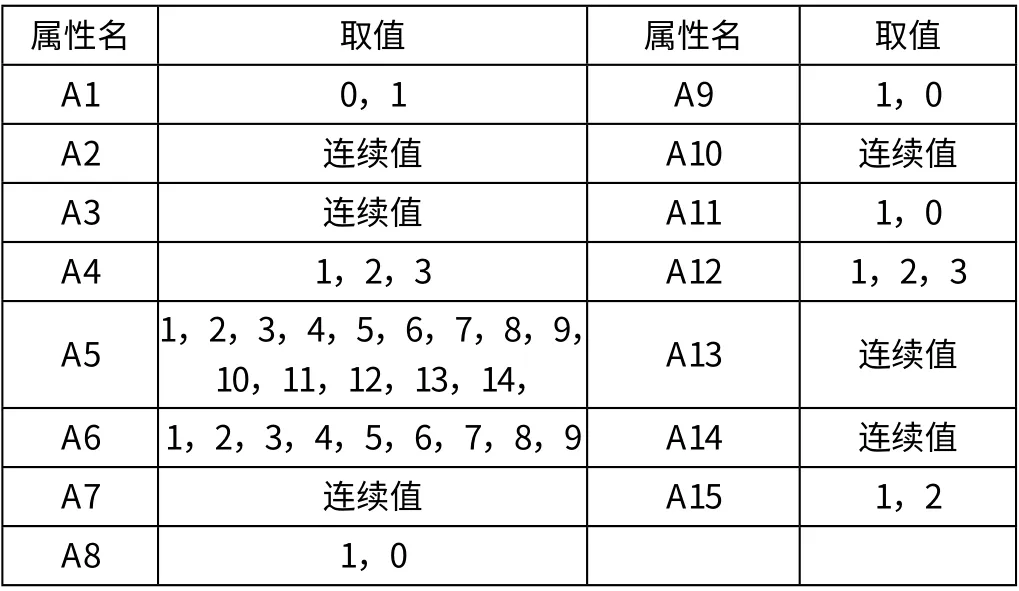
表1
2.实证结果分析
用GMDH输入输出模型对原有属性进行提取之后还剩下属性A5,A8,A9。在此基础上运用C4.5算法得到最优树如图1所示:

同时本文也将使用特征提取前C4.5算法的精确度与使用特征提取后C4.5算法的精确度进行了对比,如表2所示。

表2
在信用评估这一实际问题中,银行误贷款给信用不好的客户给企业带来的损失远远大于拒绝贷款给信用好的客户所带来的损失。因此我们可以从两方面来评价算法的准确度,一是总的错判率,二是把不好的客户误判为好客户的错判率,从表2可以看出,在这两方面,GMDH输入输出模型与决策树相结合的算法比单独使用决策树算法的错判率都低,即前者具有更高的预测精确度。
五、结论
本文采用的GMDH输入输出模型对客户的属性进行了筛选,选出了对客户分类结果影响较大的属性,达到了对决策树优化的效果,有效的降低了算法的复杂度,简化了整个决策树的构造。
[1] Xu Peng,Lin Shen.Internet traffic classification using C4.5 decision tree.Journal of Software,2009,20(10):2692-2704.
[2]黄颖,周云轩,吴稳.基于决策树模型的上海城市湿地遥感提取与分类[J].吉林大学学报,2009,39(6):1156-1162.
[3]黄爱辉.决策树C4.5算法的改进及应用[J].科学技术与工程,2009,9(1):34-36.
[4]崔健.商业银行个人信用风险评价[D]天津:天津大学管理学院,2005.06.
[5]Pan-ning Tan.Michael Steinbach.Vipin Kumar.数据挖掘导论[M].人民邮电出社.2006:181.
猜你喜欢
装备制造技术(2019年12期)2019-12-25
成都信息工程大学学报(2019年3期)2019-09-25
铁道通信信号(2019年3期)2019-04-25
中国惯性技术学报(2019年6期)2019-03-04
电子制作(2018年16期)2018-09-26
校园英语·中旬(2017年10期)2017-11-20
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
吉林省教育学院学报(2017年3期)2017-05-31
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
火控雷达技术(2016年3期)2016-02-06
