
面向电力虚拟社区的隐性知识收集方法
2014-02-19 07:28王耀辉
东北电力大学学报 2014年4期
王耀辉,杨 帆,陈 帅
(1.东北电力大学 媒体系,吉林 吉林132012;2.东北电力大学 信息工程学院,吉林 吉林132012)
电力隐性知识泛指存在于电力相关从业人员头脑中的,不易显性化的解决问题的方法、诀窍等个性化知识,甚至有时电力隐性知识的拥有者都没有意识到自己具有某种隐性知识。传统的师傅带徒弟、干中学等隐性知识学习方式,由于员工的流动性,容易造成知识未经传承即消亡的现象,而组会讨论等隐性知识共享方式又存在耗时耗物、灵活性差等劣势。电力虚拟社区的发展为解决隐性知识共享提供了新途径,电力相关从业人员可以在虚拟社区[1-2]中发布问题,而隐性知识的拥有者则可以采取回答问题的方式将自己的隐性知识共享,通过这种形式,电力虚拟社区中积累了大量的电力隐性知识。
在实际的电力虚拟社区中,开放性的交流方式是十分自由的,对隐性知识质量有着非常重要影响的评论信息良莠不齐,并且充斥着相当数量的商业广告。这些因素使电力隐性知识淹没于大量的无用信息中,快速获得适用性好的隐性知识面临严重问题。所以过滤电力虚拟社区中的无效信息,从中提取出有价值的隐性知识,对电力隐性知识的挖掘、检索以及共享有着重要的意义。
针对上述情况,本文深入研究了电力虚拟社区中问答模式的特点,提出一种面向电力虚拟社区的隐性知识收集方法。该方法以向量空间模型[3-4]为基础,根据问答模式的特点,以社区中的讨论主题为基本单位,将主题内的讨论内容表示成主题描述、应用情景描述、专业性描述和评价描述四维向量形式,以此完成主题文本的量化,使电力隐性知识收集转化为文本向量二分类问题。然后采用遗传支持向量机(GASVM)对数量化的主题文本进行分类,得到的正类主题文本即为电力隐性知识,从而完成隐性知识的收集。最后,在捕获的1980个电力虚拟社区主题文本(进行了人工标记)中进行实验,实验结果表明,本文提出的方法获得了较好的正确率。
1 基于向量空间模型的电力主题文本表示
向量空间模型中,使用TF/IDF作为词权重的计算方法,根据文本集的特征向量空间,将文本表示成空间向量形式,从而完成文本的量化。然而虚拟社区中的主题文本属性分类问题(内部是否含有解决问题的隐性知识)与一般意义上的文本分类不同。主题文本是否包含隐性知识和全部文档集合无关,主要与其内部的主题-答案匹配情况、答案质量、主题-答案专业性,以及评论信息这四个因素有关。换言之,以这四个指标为元素构建的新向量可以表示主题文本的特性。因此将这四个指标数量化,即完成了一个主题文本的量化表示,从而完成了机器学习方法的原始数据准备,以使用机器学习方法挖掘出其中的模式,完成有效主题文本的甄别。
1.1 主题描述
本文中的主题描述是指在电力虚拟社区的一个主题文本中,问题的关键词在回答中的出现情况,也可以视为答案与问题的契合程度。本文采用变形的ITC方法计算主题描述的权重。记主题描述的权重为Wt,则其计算公式如下:

式(1)中,fik表示第k条答案中与主题中同时出现的第i个关键词的词频,l表示关键词总个数,λk表示第k条答案的文本长度。公式中的F(k)=k/k+(1),因为答案的数量越多,对解决主题中的问题就越有帮助,所以使用收敛函数F(k)控制答案数目对主题描述的影响。为弱化词频、文本长度以及答案条数对主题描述权重的影响,公式中使用常用对数形式来弱化词频差异以及文本长度差异的影响。
1.2 应用情景描述
应用情景描述主要表示答案的质量。一个好的答案通常包含一定数量的词频大于1的关键词。记应用情景描述的权重为WS,WS的计算公式与Wt的计算公式相同,只是公式中的参数fik含义为答案内的关键词词频,显然fik>1。
1.3 专业性描述
在专业领域问题中,领域词汇的含量对于衡量问答的专业性具有重要意义,电力虚拟社区主题文本中,尤其在文本较短,关键词重复率极低的情况下,电力专业词汇的种类对机器隐性知识分类的准确率具有关键性作用。记专业性描述的权重为Wm,影响主题文本专业性的因素包括专业词汇的种类和文本的长度,Wm的计算公式如下:
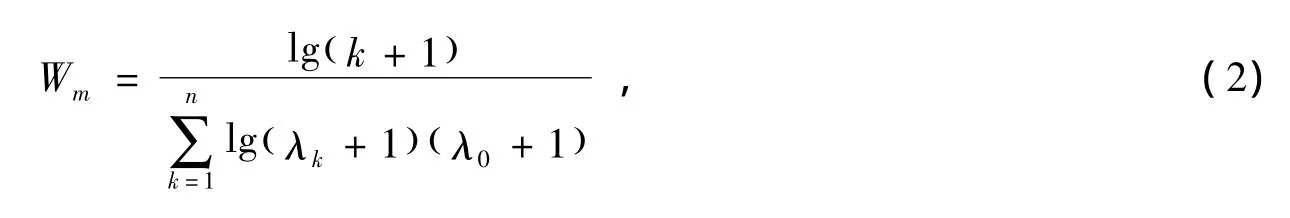
式中,k表示主题文本中出现的专业词汇种类的数目,λk表示第k条答案的文本长度,λ0表示问题的文本长度。
1.4 评论描述
在评判答案的质量时,评论信息十分重要,通常一个好的问答模式都会有一些诸如“谢谢了”、“顶”、“学习了”、“受教”等字眼的积极评论,所以评论描述对隐性知识的分类也具有重要的影响。记评论描述的权重为Wc,Wc的计算同样使用1.3中的公式,区别在于k表示的是主题文本中的积极评论数目。
2 基于滑动窗口的关键词抽取算法
由于电力隐性知识是属于特定领域的知识,其内包含了大量的领域词汇,使用传统的分词软件进行文本分词效果十分不理想,因此本文根据滑动窗口的思想设计了一种可以不分词的关键词抽取算法[5-7]。在本算法中,使用了电力专业词汇表和汉语停用词表。
图1是一个比较典型的电力虚拟社区主题文本,展示了其主要的特性,我们的关键词抽取算法、主题文本向量表示以及后期的分类都是建立在对这种类型的文本处理基础之上的。我们将整个电力隐性知识主题文本记为topic,图中虚线间隔的为不同帖子,所以将 topic 表示为 topic={T,A1,A2,…,An},其中T表示标题与标题中的问题的并集,即为文本讨论的主题帖子,A1到An统一表示不同的帖子(在处理之前我们将这些帖子暂视为答案)。
为了提高算法的运行效率,降低问题处理的复杂度,在进行关键词抽取核心算法之前,先进行下列预处理步骤:

图1 电力虚拟社区主题文本
(1)在捕获的电力虚拟社区主题文本的帖子中,依据文本长度和积极评论字眼,分离出积极评论帖子,记录其总数,作为Wc的计算依据;
(2)如果T中没有出现任何疑问词或者问号,则将标题作为问题,将T中的问题部分划入A中;(这种情况下,T可能为作者的知识分享)
(3)比较Ai和Ai+1是否相同,如果相同则去除其中的一个。(去除冗余的重复帖子)
在本文中,滑动窗口的初始值为2,下面给出关键词抽取核心算法:
将问题(主题帖子)记为字符串Q,答案记为字符串A,A=A1∪A2∪…∪An(n为字符串A中答案个数,即为回帖数),具体算法描述如下:
算法1:主题描述关键词抽取算法
输入:问题Q,答案A
输出:关键词序列 key_list[k]
1)key_list[k]=NULL,buffer=NULL;
2)对所有的Ak进行如下操作;
3)window1指向Q的起始位置;window2指向Ak的起始位置;两个窗口的大小都设为s=2;
4)ifwindow1=window2 thenbuffer={window1,1};key_list[k]=key_list[k]∪ buffer;window2 向后滑动s个字符,如果未滑动越界,则转4,若越界,则转6;
elsewindow2向后滑动1个字符,未滑动越界,则转4;若越界,则转5;
5)window1和window2大小都置为s=2;window2置回Ai的起始位置;window1向后滑动一个字符,如果滑动越界,转7,扫描key_list[k],如果window1中字符串出现在key_list[k]中,则window1向后滑动一个字符,如果滑动越界,转7,否则转4;
6)window1和window2的大小同时增加1,如果窗口越界,则转5;window2置回Ai的起始位置,转4;
7)if key_list[k]!=NULL then扫描key_list[k],去除包含停用词的关键词;统计相同关键词词频;关键词 key[i]的词频 fik=fik-fxk;//其中 key[x]为真包含 key[i]最小词,fxk为 key[x]的词频;如果key[i]的 fik=0,则删除 key[i];
8.key_list[k]中的关键词及其词频即为我们要抽取的主题描述关键词信息。
算法2:应用情景描述关键词抽取算法
输入:答案A
输出:关键词序列 key_list[k]
算法2中的主要过程与算法1类似,主要区别在于,算法2中window2初始时指向window1的结束位置,置回时也指向window1的结束位置。同样的在key_list[k]中的关键词及其词频即为我们要抽取的应用情景描述关键词信息。
算法3:电力专业词汇提取算法
输入:问题Q,答案A
输出:主题文本中的电力专业词汇种类sum
此算法只需取出电力专业词汇表中的词汇,在主题文本中进行查找,不计重复,算出种类sum即可。同时,我们在算法3中完成各帖子文本长度的计算。
至此,上节公式中出现的参数我们都可以由本节中的算法计算出具体值,带入相应公式中,就可以求出Wt、WS、Wm、Wc的值,从而完成了电力虚拟社区中主题文本的量化表示。
3 基于GASVM的电力主题文本分类
本文将GASVM作为分类工具,一方面,SVM在文本分类中具有良好的性能,尤其适用于二分类,另一方面,使用遗传算法寻优,可以提升分类的准确率。
SVM中,优化目标和约束项表示为:

其中C为惩罚因子。
最优分类函数为:
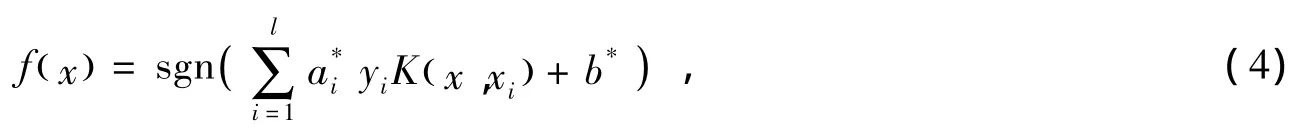
其中 K(x,xi)为核函数,RBF是最经常使用的核函数,关于两个样本x,xi,它们的RBF核可表示为某“输入空间”的特征向量,定义如下:可看做两个特征向量的平方欧几里得距离。σ是自由参数。一种等价定义是设一个新的参数γ,其表达式为则


由上述分析可知,优化SVM分类性能的关键在于C和γ的寻优,在本文的分类算法中,选取了遗传算法来完成C与γ的寻优工作。
4 实 验
实验数据集为使用火车采集器从北极星电力虚拟社区论坛中捕获的1980个电力主题文本,通过人工完成这些问题的标记,标记的方式为主题文本是否包含解决主题问题的隐性知识,包含则标记为1,否则标记为0。由于没有公认的数据集,所以实验建立在假设这些人工标记的文本全部被正确标记基础上。
选取数据集中的1000个文本作为训练集,980个文本为测试集,本文采用的平衡数据集差异的方法是5倍交叉验证。文中使用正确率作为性能度量指标。
本文实验中SVM的核函数分别采用了线性核函数、多项式核函数、RBF核函数和Sigmoid核函数进行实验对比,表1显示了SVM中不同核函数用于电力虚拟社区主题文本的平均正确率。

表1 SVM不同核函数分类的正确率
由实验结果可以看出,SVM中选用RBF核函数在正确率上性能较好。我们使用遗传算法对其进行优化,将RBF核函数进行训练后得到的正确率作为遗传算法的适应度函数,并将遗传算法的最大遗传代数设置为20。遗传支持向量机的进化过程如图2所示。
从图2中可以看出,采用RBF核函数的SVM在遗传算法的优化下,正确率提升到了将近90%,此时C=4.875 239e+02,γ =7.992 195e+00。

图2 GASVM的进化过程
5 结 论
随着网络技术的发展,尤其是当前移动互联网技术的蓬勃发展,如电力虚拟社区这样的知识交流平台必将面临数据量的急剧增长,这将直接导致电力隐性知识向虚拟社区汇集,从而使虚拟社区成为挖掘电力隐性知识的天然平台。本文针对此趋势,根据电力虚拟社区中隐性知识性质难辨、无用信息多等问题,提出了面向电力虚拟社区的隐性知识收集方法,设计了主题文本的向量空间表示方法和基于滑动窗口的关键词抽取方法,完成了电力主题文本的量化表示,最后采用遗传支持向量机完成了主题文本(即隐性知识)的分类。实验结果表明,本文提出的方法能够完成电力虚拟社区中的隐性知识收集,过滤了大量无效信息,并取得了良好的正确率性能。
[1]赵捧未,马琳,秦春秀.虚拟社区研究综述[J].情报理论与实践,2013,36(7):119-123.
[2]郑雪丽.虚拟社区国外研究综述[J].图书馆学研究,2012(18):2-5.
[3]陆玉昌,鲁明羽,李凡,等.向量空间法中单词权重函数的分析和构造[J].计算机研究与发展,2002,39(10):1205-1209.
[4]刘少辉,董明楷,张海俊,等.一种基于向量空间模型的多层次文本分类方法[J].中文信息学报,2002,16(3):8-14,26.
[5]王素格,宋晓雷,李红霞.基于领域知识的问答对自动提取方法[J].计算机工程与应用,2010,46(19):214-216,223.
[6]江华,苏晓光.无词典中文高频词快速抽取算法[J].知识组织与知识管理,2012,(3):50-53.
[7]黄九鸣,吴泉源,刘春阳,等.短文本信息流的无监督会话抽取技术[J].软件学报,2012,23(4):735-747.
猜你喜欢
甘肃教育(2020年2期)2020-09-11
新闻传播(2018年21期)2019-01-31
中国修辞(2017年0期)2017-01-31
新高考·高一数学(2016年3期)2016-05-19
现代情报(2015年8期)2015-07-20
新闻传播(2015年14期)2015-07-18
新闻传播(2015年5期)2015-07-18
新闻传播(2015年8期)2015-07-18
读者·校园版(2015年7期)2015-05-14
图书馆论坛(2014年8期)2014-03-11
