
基于项目属性和局部优化的协同过滤推荐算法
2014-12-05 04:09刘慧婷吴共庆
安徽大学学报(自然科学版) 2014年6期
刘慧婷,陈 超,吴共庆,赵 鹏
(1.安徽大学 计算机科学与技术学院,安徽 合肥 230601;2.合肥工业大学 计算机与信息学院,安徽 合肥 230009)
随着Web 2.0技术的成熟,推荐作为一种独立的概念被提出来并得到了深入的研究.推荐技术包括协同过滤推荐、基于内容的推荐、组合推荐等.其中协同过滤技术是至今为止最成功的个性化推荐技术之一[1],被广泛地应用于电子商务的各个领域.协同过滤技术又可以分为基于项目的协同过滤和基于用户的协同过滤.基于项目的协同过滤的基本思想是首先为目标项目寻找兴趣最相似的k个邻居项目,然后计算当前用户对其邻居的兴趣程度,预测对目标项目的感兴趣程度.
然而随着电子商务站点用户和商品的数量不断增加,协同过滤面临着严峻的数据稀疏性和实时性的挑战,导致推荐系统质量迅速下降.许多研究者提出了一些新的方法来改进协同过滤技术的不足.Crmonesi等[2]提出一种基于内容的评分预测来填充伪评分项目,从而有效缓解数据稀疏性问题.Ma和黄等[3-4]利用项目的协同过滤和用户的协同过滤线性组合方式预测评分进行推荐.Choi等[5]提出一种新的相似度计算方法,针对不同的目标项目选择不同的邻居.Jamali等[6]提出将用户之间的信任关系进行深度搜索,寻找更深层次的相似性用户来进行推荐,同时能够解决冷启动的问题.
围绕着解决数据稀疏性问题,并在已有的研究基础上,作者的主要贡献是:引入改进jaccard的自适应系数来调节项目间的相似性值,获得更加准确的项目相似性;利用拉普拉斯平滑方法对项目属性的相似性进行优化,在项目属性特征很少时,能够获得较为准确的项目相似性;利用局部相似性有效地降低整体的预测误差,并使误差在一定程度上收敛于某一固定值.实验结果表明:基于项目属性和局部优化选择的协同过滤推荐算法CUCF对比用户间多相似度推荐算法UMCF[7](collaborative filtering recommendation algorithm based on user's multi-similarity,简称 UMCF)、基于项目属性和云填充的协同过滤推荐算法IACF[8](collaborative filtering recommendation algorithm based on item attribute and cloud model filling,简称IACF)和考虑项目属性推荐模型(Sim1和Sim2)[9],CUCF的预测准确率较高,有效地减小了数据稀疏性对推荐质量的影响,提高了推荐系统的预测准确率.
1 问题描述与基本方法
推荐系统中用户对项目的评分数据集中包含m个用户的集合U和n个项目的集合I,其中用户Um对项目In的评分为Rm,n,该评分体现了用户Um对项目In的兴趣程度.
1.1 传统的相似性度量方法
相似性度量是协同过滤推荐模型中评分预测的基础,其质量直接影响着预测的准确率.传统的相似性度量方法有以下2种:余弦相似性和Pearson相关相似性.
(1)余弦相似性:设项目i和项目j在m维对象空间上的评分表示为向量i,j,则项目i和项目j之间的相似性通过余弦相似性度量如公式(1)所示

(2)Pearson相关相似性:设项目i和项目j被共同评分的用户集合用Uij表示,则Pearson相关相似性度量如公式(2)所示

文献[10]中提出基于用户的协同过滤的推荐算法中,Pearson相似性度量方法比其他用户的协同方法更胜一筹,而基于项目的协同过滤推荐技术中,余弦相似度方法比Pearson相关性度量表现更好.所以论文后期实验中均采用余弦相似性方法计算项目之间的相似性.
1.2 协同过滤的评分预测过程
在计算项目之间的相似性后,为用户对于未评分的项目i寻找最相似的k个近邻项目S(i),最后预测该用户对项目i的评分,计算公式如(3)所示

其中:sim(i,n)表示目标项目i与最近邻居n之间的相似性,Ru,n表示用户u对项目n的评分.和分别表示项目i和项目n的平均评分.通过公式(3)来预测用户对所有未评分的项目的评分,最后选择预测评分高的若干项目反馈给当前用户.
2 CUCF算法
论文提出了CUCF方法,首先改进了项目之间相似性的计算;然后利用拉普拉斯平滑方法优化了在项目属性中计算项目间相似性,并线性结合两方面相似性结果;最后利用局部优化选择方法选择目标的近邻对象作为推荐群.
2.1 基于评分的项目相似性改进
由于数据的稀疏性,利用余弦相似性公式计算时存在公共项目数量很少而相似度值很高的不合理现象.为了降低这种影响,考虑了公共评价项目的数量对项目之间相似性的作用,根据文献[9],选择一种jaccard系数来自适应调节项目间的相似性值.如公式(4)所示

其中:ri和rj分别表示项目i、j被评分的用户集合,||表示集合中用户的数量.jaccard系数能够较好地反映用户在评价方面的重叠情况,但是在实际中两个项目被共同评分的用户数量很少,设置为0,导致相似度值很低.提出一种新的改进公式,如公式(5)、(6)所示

可以看出,上式中Jaccard(i,j)的取值范围为[0,1],当两个项目完全被相同的用户评分时,值为1;相反,当完全被不同的用户评分,值为0.它反映了两个项目在获得用户评价方面的相对差异程度,同时对比jaccard(i,j)提高了相似度计算的值,更好地反映了用户评分的重叠情况,修正了余弦相似性公式,最终获得更加准确的项目相似性.
2.2 拉普拉斯平滑改进项目属性中项目相似性
在可以得到任意两个不同项目的属性特征向量时,利用公式(1)余弦相似性公式计算出两个项目的相似性.该方法在预测过程中时间复杂度很低,但是预测精度大大降低,这是由于特征属性的数量较少和仅为0、1权重的限制.文献[10]也提出基于项目属性的推荐必须使用相对较大的特征集合才能提高预测准确率.
拉普拉斯平滑又被称为加1平滑,主要为了解决零概率问题.针对论文中零概率问题就是由于项目的属性特征分类数目较少,在利用项目特征矩阵计算两个项目的相似性时会产生大量的零值,这时候得出这两个项目之间无相关性,这显然是不合理的,因为不能因为特征分类少,两个项目之间没有共同的属性特征就判断相似性为零.
使用拉普拉斯平滑后,项目属性的相似性计算公式如(7)所示

即在分子上加上1、分母加上相关联项目的个数K,其取值范围为{1,2,…,K}.其中:ti和tj分别表示项目i、j相应的属性特征向量.拉普拉斯平滑方法并不需要处理原始的项目属性矩阵,时间复杂度较低,可以快速准确地计算项目相似性.
2.3 组合项目相似性
根据文献[11],利用simr(i,j)和simt(i,j)从不同的两个角度度量了项目相似性,再进行线性组合,就可以获得更为全面的项目相似性度量方法Sim(i,j),如公式(8)所示
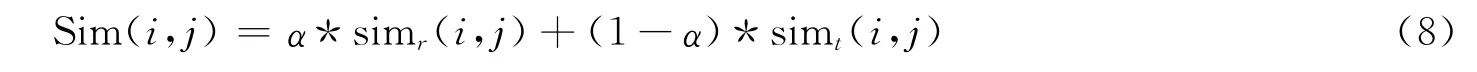
其中:参数α为平衡因子,调节两个方面的相似性对于Sim(i,j)的影响,取值范围为[0,1].
2.4 局部优化选择预测目标的近邻对象
传统的协同过滤方法在寻找相似性最大的k个邻居后,当设置近邻个数k太高时,而实际相似邻居个数不够,需要补充额外噪音,导致推荐结果准确性大大降低.论文采用局部优化方法选择预测目标,设置最小阈值参数μ,降低近邻集合的规模,获得最优近邻集合Su(i).局部优化选择相似近邻的计算方式sgi,j*Sim(i,j)>μ,其中:阈值μ为常量,μ不能设置过大,否则容易导致相似近邻数目少,覆盖率过低.sgij为重要性权重因子[10],sgij倾向于有更多评分物品的对等者[11].该方法利用局部的相似性有效地降低整体的预测误差,当近邻个数k设置较大时,可使得评分预测的误差在一定程度上收敛于某一固定值,增强了推荐系统的稳定性.
3 实验评估与分析
3.1 数据集及评价标准
论文实验数据集取自MovieLens站点,从用户评分数据库中选择100 000条评分数据作为实验数据集,实验数据集中共包含943个用户和1 682部电影,其中每个用户至少对20部电影进行评分.整个实验数据集需要进一步划分为训练集和测试集,整个数据集的80%作为训练集,20%作为测试集.除此之外,数据集中还包含了电影的属性特征如动作、喜剧、犯罪、动画等18种.
为了度量整个数据的稀疏性,引入稀疏等级的概念,其定义为用户评分数据矩阵中未评分的条目所占的百分比.现在的电影数据集的稀疏度等级为:1-100 000/(943*1 682)=0.937 95.
统计精度度量方法中的平均绝对误差(mean absolute error,简称MAE)法被广泛用于评价协同过滤推荐系统的推荐质量.MAE是对比预测值和实际值之间偏差来预测准确性的,其定义为MAE=,其中:pi为预测的用户评分,ri为实际的用户评分,N是测试集中的项目数.
3.2 评分的相似性计算改进效果实验
该实验是一组对比实验,从预测准确度MAE方面,对3.1阐述的评分的相似性计算公式改进效果,分别在基于项目的协同过滤方法和局部优化的协同过滤方法中进行验证,结果如图1所示.

图1 LCF与jaccardCF及JaccardCF对比Fig.1 Comparison of LCF,jaccardCF with JaccardCF
图1中,LCF为传统的基于项目的协同过滤的方法,jaccardCF为利用jaccard系数改进了相似性度量的协同过滤方法,该方法避免了一些公共项目数目少而相似度值高的不合理现象,降低评分预测的误差.JaccardCF方法是在基于项目的协同过滤方法中对jaccard系数的改进,进一步降低预测的误差.
3.3 拉普拉斯平滑改进相似性的实验
该实验是对文中3.1提出的拉普拉斯平滑改进的有效性验证,结果如图2所示.
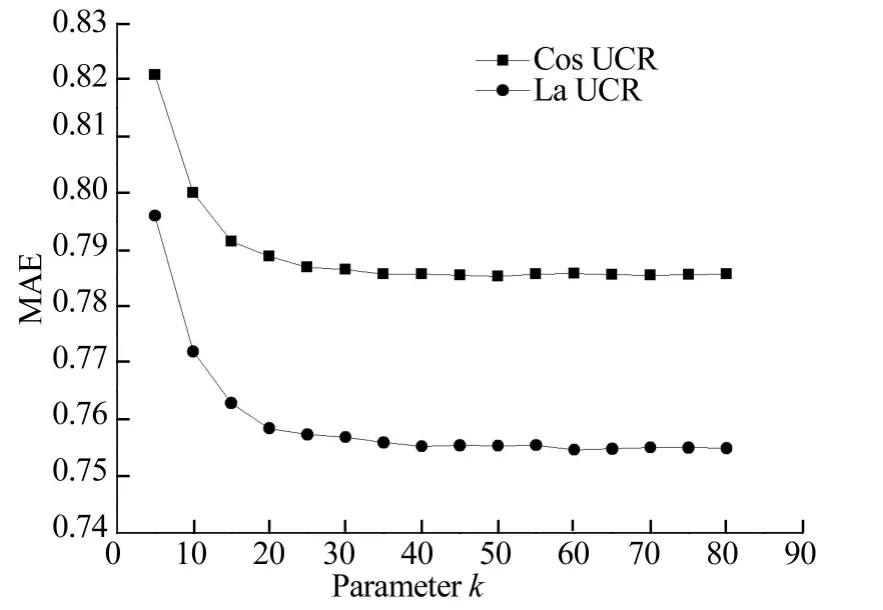
图2 LaUCR方法与CosUCR方法的对比Fig.2 Comparison of LaUCR with CosUCR
图2中,CosUCR是利用余弦相似性,在项目属性关系中进行局部优化选择方法.LaUCR是论文提出的利用拉普拉斯平滑方法,在同一条件下,对项目属性中项目相似性的改进.实验结果表明,拉普拉斯平滑方法大大降低了预测的误差,在项目属性关系中利用拉普拉斯平滑方法可以快速高效地计算项目相似性.同时利用局部优化的方法,当k趋于一定数值时,MAE收敛于一个固定值.
3.4 结合项目相似性的局部优化CUCF方法效果实验
3.4.1 参数α的最优取值
论文中线性组合Jaccard系数改进和拉普拉斯平滑两个角度度量的项目相似性.在MovieLens100k数据集中,调节参数α的最优值,α的取值范围[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95,1.0],并选择k=20进行对比实验.实验结果如图3所示.
从图3可知,当α取0.9时,CUCF算法能够获得最优的准确率,使得整体的预测误差最小.当然,参数对于不同的数据集设置有所不同.

图3 k=20时调节参数α的对比实验Fig.3 MAE of prediction rating withα when k=20
3.4.2 CUCF方法与JaccardUCF及LaUCR方法的比较
该实验验证了线性结合项目相似性的局部优化方法CUCF对于片面的JaccardUCF方法和LaUCR方法的有效性,结果如图4所示.

图4 CUCF与LaUCR和JaccardUCF对比实验Fig.4 Comparison of LaUCR,jaccardUCF with CUCF
由图4可以看出,当k太小,预测质量将会受到影响.文献[10]指出,对于MovieLens数据集,在大多数实际情况下,选取20~50个近邻比较合理.线性组合的项目相似性CUCF方法比从两个不同的角度度量了项目相似性即LaUCR方法和JaccardUCF方法,更能提高整体预测的准确率.
3.4.3 CUCF方法与其他方法的比较
为了验证推荐算法在不同项目近邻数目下的具体性能,该实验将从MAE方面,选择UMCF[7]、IACF[8]和考虑项目属性推荐方法(Sim1和Sim2)[9]与论文提出的CUCF方法作对比,比较结果如表1和图5所示.

表1 不同算法在k取值不同时的MAE值Tab.1 Comparison of MAE in five algorithms

图5 CUCF与其他4种推荐方法对比实验Fig.5 Comparison of CUCF with other four algorithms
在表1和图5中可以看出,CUCF方法当k取20时获得最优预测准确率.论文提出的CUCF方法对比其他4种方法,在预测准确率方面可以达到较好的效果,有效地减小了数据稀疏性对推荐质量的影响.对比UMCF方法准确率提高15.5%,对比效果较好的Sim2方法准确率提高7.1%.同时,当邻居个数k逐渐增大时,CUCF方法的预测准确率会小幅度下降并趋于稳定值.
4 结束语
论文分析了传统协同过滤方法面临数据高度稀疏的问题,提出一种基于项目属性和局部优化选择的协同过滤推荐算法CUCF.首先改进基于评分的项目相似性,然后深入分析项目属性的关系,通过拉普拉斯平滑方法计算项目属性中项目相似性.最后线性结合两方面的项目相似性结果,并利用局部优化方法选择目标的近邻对象作为推荐群,有效地降低整体的预测误差,使预测误差在一定程度上收敛于某一固定值.实验结果表明,与现有的基于用户、基于项目和考虑项目属性的改进协同过滤方法相比,CUCF方法对推荐系统的预测准确率方面具有优越性.下一步的研究工作是利用爬虫技术获取更多的相关电影的属性特征来提高系统的推荐质量.此外,还可以将社交网络加入到推荐系统中,通过分析获得更加完善且精确的用户或项目之间的相关性,同样是一个很有前景的研究方向,这样不仅可以提供推荐的高质量性,还能有效避免推荐系统的冷启动问题.
[1]Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:a survey of the state-of-theart and possible extensions[J].Knowledge and Data Engineering,IEEE Transactions,2005,17(6):734-749.
[2]Cremonesi P,Turrin R,Airoldi F.Hybrid algorithms for recommending new items[C]//Proceedings of the 2nd International Workshop on Information Heterogeneity and Fusion in Recommender Systems,ACM,2011:33-40.
[3]Ma H,King I,Lyu M R.Effective missing data prediction for collaborative filtering[C]//Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,ACM,2007:39-46.
[4]黄创光,印鉴,汪静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
[5]Choi K,Suh Y.A new similarity function for selecting neighbors for each target item in collaborative filtering[J].Knowledge-Based Systems,2013,37:146-153.
[6]Jamali M,Ester M.Trustwalker:a random walk model for combining trust-based and item-based recommendation[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data mining,ACM,2009:397-406.
[7]范波,程久军.用户间多相似度协同过滤推荐算法[J].计算机科学,2012,39(1):23-26.
[8]孙金刚,艾丽蓉.基于项目属性和云填充的协同过滤推荐算法[J].计算机应用,2012,32(3):658-660.
[9]杨兴耀,于炯,吐尔根丒依布拉音,等.考虑项目属性的协同过滤推荐模型[J].计算机应用,2013,33(11):3062-3066.
[10]Dietmar J.推荐系统[M].蒋凡,译.北京:人民邮电出版社,2013.
[11]项亮.推荐系统实践[M].北京:人民邮电出版社,2013.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
河北画报(2020年8期)2020-10-27
汽车观察(2019年2期)2019-03-15
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
中国卫生(2016年5期)2016-11-12
