
用回溯算法诊断数据库性能故障
2015-01-04 11:16程香
长春师范大学学报 2015年12期
程 香
(安徽经济管理学院,安徽合肥 230059)
用回溯算法诊断数据库性能故障
程 香
(安徽经济管理学院,安徽合肥 230059)
数据库性能诊断至关重要,本文针对目前数据库性能诊断过程依赖于经验的状况,研究了一种基于回溯算法的数据库性能诊断方法,提出了数据库性能诊断过程的解空间树构造方法,以及诊断过程详细的形式化算法,最后给出该方法的使用实例。该方法能够避免数据库性能诊断的盲目性,也可为其他系统性能诊断提供参考。
性能诊断;回溯算法;数据库性能;自底向上
1 研究背景
数据库出现性能故障,往往严重影响系统的运行效率,甚至引发系统崩溃,造成巨大的损失,因此数据库设计及其运行过程中的性能故障诊断和优化都具有重要意义。为了对数据库进行诊断和优化,文献[1]开发了一个最大数目为60维的搜索应用程序,帮助用户鉴别自己偏好查询。文献[2]分析了初始化参数选择对数据库效率和处理时间的影响,分析得出Oracle数据库调优在一个纯粹自动化的方式下是不可能的。文献[3]设计了一个名为CUDADB的内存数据库,以扩展带CUDA的GPU数据库系统性能。文献[4]讨论了属性分配和聚集元组的组合问题,通过应用遗传算法反复归因分区和集群元组子问题,为混合碎片问题提出了一个新方法,实验分析了不同遗传参数的效果。
现有的数据库优化方法主要从产品设计开发阶段着手[5-9],但在设计开发阶段对数据库的性能管理有多全面,在实际的数据库应用中不可避免地出现运行速度慢、客户端卡死等故障。因此,数据库的性能优化应该历经软件系统的设计、开发、上线整个生命周期。系统上线后数据库性能的诊断是进行数据库性能优化的前提。目前,对数据库性能的诊断主要依赖各种性能分析和调优工具[10-13]。而数据库性能故障可能由多种软硬件原因引起,故障的诊断过程和结果分析,不仅依赖于辅助工具,还要一个有效的测试过程[14]。数据库诊断过程基本凭借测试人员的经验执行。为了优化数据库性能诊断过程,本文基于数据库性能表现特征,将数据库性能诊断问题转换成解空间树,更加清晰地描述和分析整个问题。引入相关经验数据,避免了数据库性能诊断盲目性。对性能诊断过程的形式化定义,为与其他自动化化测试工具集成提供可能。
2 数据库性能诊断及研究思路
精准有效的数据库性能诊断主要取决于科学的诊断过程及诊断报告,其中科学的诊断报告主要依赖于测试工具度量的数据。性能测试工具种类繁多,且功能又交叉重叠,有IIS服务器工具IISTrace、微软WinDbag、CLR内存分析软件CLRProfiler、并发工具LoadRunner、Linux性能监控工具linux:nmon等。这些工具多数是将监控和测试数据直观地呈现出来,可以基本满足对数据库各个层面和各种负载下的诊断。数据库的性能诊断是一项十分复杂的工程,从数据库性能表现来看,不论是软件或者硬件出现性能问题,都会导致硬件负载异常,而且内存、CPU或者I/O等也会相互影响,数据库的性能诊断过程要诊断出其影响性能的真正原因,需要层层剥离表象找出真正的问题。因此,一套有效的诊断方案对数据库的性能故障诊断和优化至关重要。
回溯算法是一种系统地从问题的解空间中搜索得到问题的可行解或者最优解的算法。该算法通过对部分解进行增量构建式搜索得到可行解,在构建过程中采用一种试探性的法则。在数据库性能诊断时,性能诊断人员利用经验知识对某性能表现分析得出的种种可能原因就是一个解空间,之后对性能问题的探查过程也正是一个推测与验证的试探过程。回溯算法搜索过程符合数据库性能诊断的规律,并且一个可行解向量的反序可为性能优化路径提供思路,即沿着可行解向量中最后一个元素向第一个向量方向出发,即可进行自底向上的性能优化。下文探讨如何改进回溯算法以适合诊断数据库性能问题。
3 基于回溯算法的数据库性能故障诊断
3.1 回溯算法设计
3.1.1 解定义
图1是数据库性能诊断问题的解空间树表示。

图1 数据库性能诊断解空间树结构
本文使用向量V=(v0,v1,…,vh)来表示一个性能诊断的过程。
(1)v0:初始节点,为性能问题的初始表现;(2)vi:中间节点,表示经由v0,v1,…,vi-1(0≤i≤h)层层深入推测出可能存在性能问题的软硬件检查点,其中vi∈(0,1)表示第i个检查点存在性能问题的概率;(3)vh:叶子节点,表示经由v0,v1,…,vh-1层层深入搜索到并且可度量性能值的检查点,vh∈{0,1}表示第h个检查点是否存在性能问题,vh=1表示第h个检查点存在性能问题,vh=0表示第h个检查点不存在性能问题。
为了描述性能诊断求解过程和性能诊断结果中相关元素,进行如下定义:
定义1 在解空间树构建过程中,称那些未构建完全的解V=(v0,v1,…,vj)(j 定义2 在解空间树构建过程中,称构建完全的解V=(v0,v1,…,vj)(j=h)为一个候选解,其中v0至vj均为其父节点未舍充的孩子中权值最大的节点,vj为叶子节点。 定义3 对于一个候选解,如果vj经验证有性能问题,那么该候选解被定义为一个可行解。其中V=(v0,v1,…,vj)(j=h)为一个诊断出性能问题的过程,vj处验证出某种性能问题表明对该过程中推测是正确的。此时vj是一个确定的故障点,可作为性能优化和调整的对象。 数据库性能诊断问题的目标是找到一个或所有的可行解,即诊断出某个或多个性能故障。在解空间树中,从根节点到叶子节点的一条路径即为该问题的一个候选解,该路径中,第i层节点到第i+1层节点之间边的权值表示第i+1个节点存在性能故障的可能性大小,即某个候选解向量中vi+1的值。 3.1.2 叶子节点及其验证 在解空间树的构建过程中,叶子节点的确定与验证方法如下: (1)验证方法。目前有许多进行性能分析的工具可以实现日志跟踪、服务器进程分析等功能,也有很多数据库专门的性能调优工具,如SQL提供的DMV,可以方便地通过查询语句、等待与阻塞、索引、I/O操作等的统计信息来确定性能故障。故如果某个节点可由性能测试工具明确度量出性能参数(称可验证),则记录具体性能测试数值,与事先确定的性能基数对比,由此确定叶子节点是否存在性能问题。 (2)确定方法。某个节点可验证,就被确定叶子节点。性能诊断的解向量V=(v0,v1,…,vh)中h的数值也由此动态生成,其实质为性能诊断的深度。 3.1.3 剪枝函数 为了避免探测那些不可能产生性能问题的软硬件,需要利用剪枝函数来去掉那些节点及其子孙分支,以减少搜索和验证的工作量。在解向量的构造过程中,为当前推测有性能问题的节点的每个子节点定义一个权值,权值由当前节点的性能表现来确定,表示出现概率的大小,并且对该节点的所有子节点根据权值降序排序,每次搜索某节点的子树时,选择其权值最大的节点作为下一个搜索节点。诊断时定义一个上界约束upbound(0 3.2 基于回溯算法的数据库性能诊断 图2为数据库性能诊断方案框图。构建数据库性能故障的解空间树,可以明确勾勒出某性能问题通常涉及的异常表现范围,对性能故障产生的原因作出更细致的分析。性能子问题搜索与性能子问题验证是一个推测与验证的过程。(1)性能子问题搜索,在求解搜索过程中通过归约和修剪,提高性能诊断的效率。(2)性能子问题验证,定义性能基数并利用辅助工具对当前的推测进行验证。下面将针对数据库系统给出基于回溯算法的性能诊断方法,将解空间树的构建与搜索分开讨论。 图2 数据库性能诊断方案框图 3.2.1 数据库性能诊断解空间树构建 构建数据库性能诊断解空间树的目的是限制数据库性能故障诊断的范围,同时将数据库性能故障分解成若干个可能问题,进而作出更深层次的诊断。图3为一个SQL Server数据库性能诊断解空间树的部分图。 图3 性能问题诊断解空间树 解空间树构建过程分解如下: (1)针对数据库性能问题的表现,根据数据库优化工程师的经验,推测出现该异常表现可能的软硬件原因,并分别估计它们的概率,再进行降序排序,即生成解空间树根节点及其子节点,且对这些子节点进行降序排序;(2)选择权值最大的子节点为当前节点,如果该节点是叶子节点,经验证有性能问题,则一个可行解构建完成,停止构建;否则执行下一步;(3)针对当前节点,分析该节点性能特征的软硬件原因及其存在概率,即生成某个节点的子节点,并分配权值后降序排序;(4)重复(2)和(3)过程。如果根据经验估计的概率能较准确反应某个节点与其子节点之间的性能表现与产生原因的关联程度,则在可能没有发生回溯时就已找到了一个可行解。如果没有找到可行解,则根据回溯算法向上回溯至某一节点继续构造。 3.2.2 数据库性能诊断求解过程描述 采用回溯算法动态查找数据库性能问题,首先将解向量V设置成Ф,并将当前访问节点设置为根节点v0。接着沿着根节点向下搜索,选择解空间树中第1层权值最大的节点v1作为解向量的第一个元素。如果v1不是一个叶子节点,那么当前解V=(v0)是一个部分解。此时,v1是一个活节点,下一步搜索以v1为根的子树,选择v1的权值最大的孩子v2作为解向量的第二个元素,如果v2仍然是一个活节点,继续向v2的下一层节点进行搜索。反之,如果v2是一个死节点,则从v2回溯至其父节点v1。当得到了一个问题的部分解V=(v0,v1,…,vi),需要vi+1把添加到解向量末尾时,其详细操作情况如下: (1)如果vi+1是一个中间节点,那么当前解是一个部分解,该部分解存在被构建为可行解的可能性,因此对其孩子中权值最大的节点vi+2进行搜索。 (2)如果vi+1是一个叶子节点,此时,若vi+1经验证有性能问题,那么当前解是一个完全解,该完全解是一个可行解;若vi+1经验证无性能问题,则沿着解空间树回溯至节点vi+1的父节点vi,并对其剩余孩子中权值最大的节点进行搜索,如果节点v1的所有孩子节点都已经被搜索完毕,则回溯至节点vi的父节点vi-1。 不断重复步骤(1)和(2),直到找到一个可行解,或者根节点变为死节点。若根节点变为死节点时,仍没有找到一个可行解,则表示利用该解空间树中无法诊断出性能问题。 3.2.3 算法分析 本算法在找到一个可行解时即终止算法,因此每次搜索只能定位一个性能问题故障点,搜索过程属于找出局部最优解,因此不一定能找到最主要故障点,而可能存在其他性能故障点。因此,若要诊断某个异常表现的所有其他故障点,只有在回溯至解空间树的根节点v0且v0的所有孩子节点都已经搜索完毕时才可终止算法,此时整个解空间树已经被搜索完毕。 基于回溯算法的数据库性能诊断是一种图的深度优先搜索,算法的时间复杂度由权值排序的时间复杂度和图搜索的复杂度决定,如果要找到一个可行解,其最坏的情况是遍历完整棵解空间树,其复杂度为O(m+n+nlogn),但在实际求解过程中,由于对性能问题分配的权值有上界约束,找到可行解的迭代次数远小于这个值。 实例是用户使用一个信息管理系统的报表查询功能,查询速度非常慢,其它功能正常。根据经验构建的解空间树如图3所示。图中各分支即为测试人员对该性能问题的原因分析,各节点连接线上的权值即为对各原因存在的概率估计。根据上节所述搜索解空间树的方法,由性能问题描述首先判断可能是内存问题,再使用性能计数器对运行中的服务器做日志跟踪,检查发现内存设置没有问题,回溯至其父节点,选择剩余未访问的子节点中权值最大的进行访问,即对SQL查询语句进行诊断,通过监控内存和Dump内存来分析,发现在代码中有一方法长时间执行致使堆栈中局部大量变量无法释放。图3中若要显性地对SQL语句效率作更具体的形式化分析,则继续对效率低的原因进行多维度推测并验证。 本文的目的是要从内存、CPU、磁盘、网络等性能表现来逐步深入地探测数据库软、硬件性能故障,甚至探查出数据库的设计、开发阶段的问题,作为对系统性能优化和调整的依据。本文的主要工作是给出了一种数据库性能诊断过程的解空间树的构建方法,以及以自然语言描述了基于回溯算法的数据库性能诊断的求解过程,为数据库性能诊断提供一个形式化方法,实践案例表明该方法对性能诊断过程具有指导作用。下一步工作考虑如何将该方法与性能测试工具集成,以及如何减少经验数据的主观性,更好地指导性能问题的搜索过程。 [1]Alwana A A,Ibrahima H,Yipa T C,et al.A performance evaluation of preference evaluation techniques in real high dimensional database[J].Procedia Computer Science,2012(10):894-901. [2]Kacerka W,Kacerka J.Beyond databases,architectures and structures:Analysis of the effect of chosen initialization parameters on database performance[J].Communications in Computer and Information Science,2015(521):60-68. [3]Chang Yue-shan,Sheu R K,YUAN Shyan-Ming, et al.Scaling database performance on GPUs[J]. Information Systems Frontiers,2012,14(4):909-924. [4]Gorla N,Vincent N,Law D M.Improving database performance with a mixed fragmentation design[J].Journal of Intelligent Information Systems,2012,39(3):559-576. [5]Osman R,Knottenbelt W J.Database system performance evaluation models-A survey[J].Performance Evaluation,2012(69):471-493. [6]Mrozek D,Paliga A,Mrozek M B,et al.Beyond databases,architectures and structures:database under pressurescaling database performance tests in microsoft azure public cloud[J].Communications in Computer and Information Science,2015(521):69-81. [7]Ou Y,Harder T.Database systems for advanced applications lecture notes:Improving database performance using a flash-based write cache[J].Computer Science,2012,7240:2-13. [8]李艳丽,张兴忠.云环境下基于LQNM的数据库性能建模研究[J].计算机应用与软件,2015(1):55-58. [9]肖盼,黄萍.基于SQL语言执行效能的关系数据库性能测试研究[J].计算机与数字工程,2012(2):127-129. [10]Clarke J.Oracle exadata recipes:Host and database performance monitoring[M].Apress,2013:411-444. [11]Sileika R.Pro python system administration:Automatic MySQL database performance tuning[M].Apress, 2014:349-366. [12]赵吉志.数据库服务器性能测试方法的研究和实现[J].计算机研究与发展,2012,49(Suppl):352-356. [13]徐增敏,张昆,丁勇,等.基于动态视图的数据库性能调[J].计算机应用与软件,2012,29(12):58-60. [14]FritcheyY G. SQL server query performance tuning:Data-base performance testing[M].Apress,2014:505-513. Application of Backtracking Algorithm in Database Performance Diagnosis CHENG Xiang (Anhui Institute of Economic and Management, Hefei Anhui 230059, China) Database performance diagnosis is essential for database systems. For the current situation that the process of database performance diagnosis depends on the experience of testers, this paper studied a database performance diagnosis method based on backtracking algorithm. It gives a way to construct the solution space tree of database performance diagnosis process, and a detailed formalized algorithm of diagnosis process. The paper also presents a concise use case of this method. The method can avoid blindness during the process of database performance diagnosis, and can also be used as a reference of other system performance diagnosis. performance diagnosis; backtracking algorithm; database performance; bottom-up 2015-07-13 程 香(1982- ),女,安徽合肥人,安徽经济管理学院讲师,硕士,从事算法设计、软件性能分析研究。 TP3 A 2095-7602(2015)12-0030-05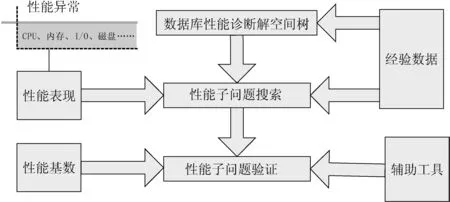
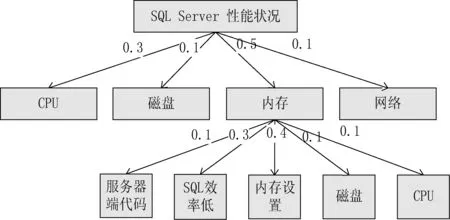
4 诊断实例
5 结语
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21新高考·高一数学(2022年3期)2022-04-28中学生数理化(高中版.高考数学)(2021年1期)2021-03-19沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01自动化学报(2017年7期)2017-04-18财经(2017年2期)2017-03-10现代电子技术(2016年15期)2016-12-01财经(2016年15期)2016-06-03高中生学习·高三版(2016年9期)2016-05-14财经(2016年3期)2016-03-07
