
基于多核DSP激光成像雷达数据处理系统
2015-03-23 06:07张文广郭裕兰滕书华
激光与红外 2015年11期
张文广,鲁 敏,郭裕兰,滕书华,张 军
(国防科技大学自动目标识别重点实验室,湖南长沙410073)
1 引言
激光雷达以其独特的技术优势,在航天器对接、坦克目标识别、地形地貌分析等应用领域中均有着广阔的前景,被世界各主要科技强国所关注。20世纪70年代以来,激光成像雷达逐步应用于军事、工业控制、地形测绘、宇宙飞船导航、港口交通管理以及水下定位等方面[1]。国内对激光成像雷达的研究始于20世纪90年代,虽然对激光雷达数据处理算法方面的研究较多,但关于激光雷达数据处理系统的文献却依然较少。由于激光雷达既不同于微波雷达也有别于可见光,因此其数据处理系统也有别于现有的雷达信息处理机。基于此,本文设计了一套可靠、高效的激光雷达实时图像处理系统。
2 系统硬件设计
2.1 信息处理机结构
硬件设计是激光雷达图像信息处理系统的基础[2]。根据激光雷达图像系统信息处理的需求,对信息智能处理系统的硬件资源进行分析。整个信息处理系统可分为五个模块:数据接收模块、数据处理模块、接口控制模块、显示模块和通信模块。处理机硬件框图如图1所示。
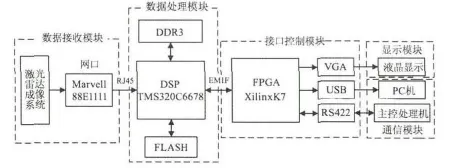
图1 信息处理机硬件框图Fig.1 Block diagram for the signal processing hardware
数据接收模块用于接收激光雷达获取的原始距离图像,在本系统中采用网络接口实现前端与处理模块的通信。网络通信协议分为TCP和UDP两种,为满足较高的实时性要求,系统采用易于实现的UDP协议。UDP协议是面向无连接通信的协议,由于没有TCP中三次握手的需求,网络设备在通信时,UDP数据的优先级高于TCP数据,因此实时性要求高的系统均采用UDP协议。为保证网口数据接收的实时性,以太网PHY芯片选用Marvell公司的88E1111芯片,该芯片接口传输速率理论上可达到千兆每秒。
由于激光雷达图像数据为浮点型的距离图像且处理算法中涉及大量的乘法操作,因此数据处理模块选用一片拥有硬件乘法器的八核DSP浮点型芯片TMS320C6678作为主处理器。TMS320C6678有专用64位DDR3接口,最大外挂存储容量为8G。选用Micron公司的MT41K256M16的DDR3存储芯片用于存储图像数据,该芯片单片位宽为16位,存储容量为2G。选用128M的N25Q128 FLASH芯片用于存储DSP程序。
核心处理单元FPGA主要实现图像数据预处理、接口芯片控制以及与DSP进行SRIO和EMIF通信等功能。因此,FPGA选用性价比较高的XilinxK7系列XC7K70TFBG676芯片。该型芯片包括10250个Slices,135个 36k的 Block RAM,240个 DSP48 Slices,最多400个I/O,8lane GTX。其最高速度可达 12.5Gbps/lane。
对于图像处理系统,传统硬件实现、调试过程中,通常对硬件内部图像处理过程不可知、系统中间状态不能及时反馈,只有系统处理最终结果,用户只能通过经验对系统进行测试、修改,这给系统的实现、维护等带来了极大的不便。为实现在系统实现与维护过程中的实时观测和在线调试,实时获取激光雷达数据处理的中间结果就显得尤为重要。本系统采用FPGA控制各接口与PC及主控机进行数据通信,并将图像处理结果通过VGA接口分屏显示在液晶屏幕上。
综上,本文采用FPGA+DSP的硬件系统框架,通过内部高速互联以及可测可试的内部状态显控方式来满足相应的数据处理需求。
2.2 信息处理机特点
2.2.1 强大的处理能力
DSP处理器选用TI公司新一代KeyStone架构的TMS320C6678芯片。该芯片拥有4M共享内存,以及8个最高可达1.25GHz的DSP内核,每个内核拥有512KB L2内存,可在10W功耗下实现160GFLOP的运算。此外,该芯片外部接口丰富,共包含 4xSRIO、16位 EMIF总线、DDR3总线、2路PCIe接口、1路Heyperlink接口以及1路千兆以太网接口。TI公司提供了强大的与DSP结构相适应的内联函数、汇编指令和大量的开发例程,大大降低了图像处理系统的开发。
2.2.2 FPGA+多核 DSP 的并行架构
由于激光三维成像数据量大、算法复杂度高,为实现高速实时的激光雷达图像信息智能处理,硬件实现中运用了FPGA+多核DSP的并行架构。以FPGA为主要功能芯片的图像预处理子系统,主要实现对高速图像数据的预处理等功能,同时承担总线控制、帧存控制等任务。基于多核DSP并行处理结构的图像信息智能处理子系统主要实现对激光雷达数据处理算法的复杂运算功能。此外,多核DSP的并行处理结构通过总线连接容量较大的DDR3作为全局外部存储器用于存储图像处理过程中的图像数据。FPGA与DSP之间通过高速总线进行数据传输,实现系统的分布式并行运算。
2.2.3 内部状态显控及可扩展性
相比于其他传统的图像处理系统[3],本系统的一大优势在于内部状态显控模块。该模块可将处理的中间结果和最终结果通过分屏方式进行显示,实现了在系统实现与维护过程中的状态实时观测和在线调试,大大缩短了算法调试验证所需的时间,并且能快速直观地得到处理结果。
其次,无论是FPGA模块还是DSP模块,均能反复烧写不同的工程,对软件稍作修改即能用于二维图像处理等其他应用场合,因此本系统可移植性强。
3 系统软件设计
3.1 DSP并行结构设计
在多核DSP开发中,多核并行的架构主要分为主辅拓扑结构(Master Slave)和数据流拓扑结构(Data Flow)两种。本文选用主辅拓扑结构,由此DSP内核将分为主核与辅核两种,主核起到控制作用,由主核向各辅核发送核间中断来控制辅核的状态,而辅核之间没有任何核间通信,只负责计算任务。主核(控制核)与辅核的数据通信则通过EDMA与外部存储器DDR3进行数据交换来完成。
TMS320C6678芯片共有8个内核,不失一般性,本文以4核并行系统设计为例进行分析。以下图表中,若无特别说明,均为4核并行系统。本文核间通信结构如图2所示,核0作为主核,核1至核4作为辅核,主核负责与各种接口进行数据通信以及控制辅核进行并行处理,辅核只负责算法处理,并将计算结果存入DDR3指定的存储段中。
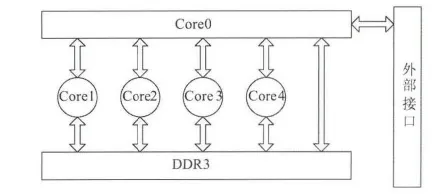
图2 DSP核间数据通信框图Fig.2 Block diagram for the data communication between DSP cores
核间通信主要分为数据通信和状态通信。状态通信主要用于传输状态量和控制信息,因此通信时间短、实时性要求高。相比较而言,数据通信是大量数据的搬移,通信时间长、实时性要求较低。不论哪种数据通信方式,都需要采用相应的状态机制进行管理,状态机制可以由中断或者消息产生。由于本系统涉及到大量的图像处理和数据存储,数据通信的时间在很大程度上决定了系统图像处理的效率。因此,采用何种机制来管理核间通信是本系统设计的关键。
3.2 算法流程分析
目标通常被置于一定的背景环境之中,与背景图像融为一体[4]。因而,若需对目标进行后续处理(如跟踪、分类、识别),则不仅需要能检测到目标,同时还应能感知目标在环境中的相对位置以及目标大小等信息。在激光雷达探测过程中,由于视角、背景等原因,目标时常被遮挡,在距离像中可能难以很好地实现检测与分割[5]。如图3所示,目标部分被树木遮挡,难以完整地将目标与背景分离。

图3 目标被树木遮挡示意图Fig.3 An illustration of a target under trees
此时,通过从距离像中恢复三维点云场景则能较好地实现目标与背景的分割[6]。由于距离像是三维场景在二维平面的投影像,在某一观测视点上目标被物体遮挡,则相应的成像结果中目标也会被遮挡[7]。然而,在真实场景中目标实际与背景是分离的,因此通过三维点云可以从不同的角度进行观测,从而较好地分离背景与目标[8]。
综上,本文检测算法的具体步骤为:首先对距离像进行去噪、分块以及转换成点云等预处理操作,其次进行地面估计,然后进行高程滤波,最后根据目标大小等先验信息分割出目标。算法流程如图4所示。
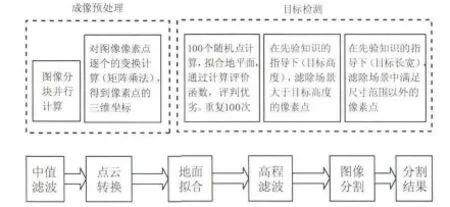
图4 地面目标检测算法流程Fig.4 The flow chart for the ground target detection algorithm
3.3 任务分配及Semaphore硬件仲裁
Semaphore[10]模块是 TI-C6678 的内部硬件模块,完成对共享资源互斥访问的硬件仲裁,保证同时刻片上资源只被一个内核访问。Semaphore模块最多支持64个独立的旗语信号用于表征资源的访问状态。Semaphore模块提供共享资源申请、释放和状态查看等管理操作库函数。资源申请是获取资源访问权的过程,资源被闸式保护以保证互斥访问。资源释放是放弃所有权的过程,状态查看函数提供了确认资源当前状态的功能,内核一旦放弃资源所有权,再次使用仍需重新申请。Semaphore硬件仲裁模块实现了对资源共享的协调化管理,避免多核环境下可能产生多个核同时竞争使用共享资源等错误。其次,该模块和其他功能模块有良好的事件交互,增强了多核开发的灵活性。最后,由于硬件信号量访问时间几近零开销,因而大大减少了多核调用资源的延时等待。
Semaphore模块申请资源分为以下三种方式:
(1)直接申请(Direct request);
(2)间接申请(Indirect request);
(3)合并申请(Combined request)。
本系统采用信号量直接申请的方式进行多核控制。此种方式是获取资源访问权的最简单方法,申请结果只有应允和否决两种。申请被应允,表明资源当前可用,申请内核获得所有权。否决状态说明资源被占用,内核不能获得访问权,硬件模块持续尝试直到被应允。本系统基于信号量多核调度工作流程框图如图5所示。如2.1节所述,本文多核系统采用主辅拓扑结构,其中0核作为主核负责接收数据与任务调度,1~4核作为辅核进行并行处理。
马兰把衣服放在搓衣板上反复地揉搓着,不大会儿洗衣盆里就堆起了五颜六色的泡沫。再过一阵,她的两只手以及小半截手臂也淹没在泡沫里了。好几次我都想提醒她,你不要再搓了小兰,再搓下去会把衣服搓坏的。可我忍住没敢开口。当我给马兰转述那天事情的经过时,她就这样一直低着头搓洗衣服,我说完半天了,她还没有停手的意思。那件衣服被马兰搓得扑哧扑哧响,人一样急促地喘息。
首先各工作核开始进行各自的信号量初始化,释放信号量即释放所占用的资源。主核与辅核不同的是,主核在信号量初始化时占用了辅核在处理时所需的资源并进行了一系列的接口初始化,而后等待网口发数据。辅核在信号量初始化完毕后,开始申请各自的信号量,直到获得该资源的所有权时才开始后续的处理。当从网口接收到一幅激光雷达图像数据时,主核开始释放其所占用的资源,随即进入等待,直到辅核释放各自的资源时再处理下一帧激光雷达图像。而此时,辅核在主核释放了资源后,立即获得各核对应资源的所有权,从而进行检测算法处理。处理完毕后释放各自的资源,并将处理结果存入DDR3内。自此,处理机完成了一帧图像的处理。
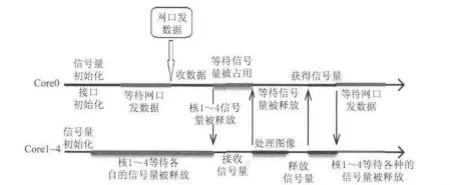
图5 基于信号量的多核交互流程图Fig.5 Diagram of the multi-core scheduling based on Semaphore
多核并行系统的处理效率由各核处理时间的最大值决定[11],也就是说,如何合理的分配任务以使各核承载的运算量处于同一个量级是多核任务分配的关键。以本系统为例,对同一个检测算法,处理所需的计算量与激光雷达图像的大小成正比。要想各辅核的计算量处于同一个量级只需将激光雷达图像合理地分成多份,各个辅核只需对各自对应的图像区间进行处理即可。然而如果目标处于两个或多个图像区间的边界时,目标会被分割开,因而不利于目标检测。本文采用适当扩大各图像区间大小的方法,使得各个区间有一定的重合部分。由于激光雷达图像不同于二维图像,其图像中的每个点之间的距离是物体在真实世界的实际距离,因此,可根据待检测目标的大小等一系列先验知识决定重合部分的大小。
4 实验结果
4.1 系统加速比理论分析
在多核操作系统上进行并行计算的主要目的是减少整个计算过程中所耗费的时间,为此加速比被提出用于衡量并行系统的加速性能。加速比的定义为在某个特定的应用下,并行执行程序相对于串行执行程序在运算速度方面提高的倍数。
随着计算机技术的发展,先后有三个计算并行加速比的定律被提出,即Amdahl定律、Gustafson定律以及Sun和Ni定律。由于本文为激光雷达图像处理系统,对于同一检测算法,计算负载是不变的,所以衡量加速比采用适用于固定计算负载的Amdahl定律。
1967年,IBM公司的计算机结构师Amdahl在其论文中提出了计算机科学中著名的Amdahl定律[12]。Amdahl定律的出发点主要基于以下几点:
(1)对实时性要求很高的处理系统,在计算负载(计算量)不变的情况下,可以通过采用多核处理器,增加并行处理器的数量的方法来提高整体计算速度以达到实时性要求。
(2)计算负载(计算量)是固定不变的,通过增加处理器数目,可以将计算任务均匀地分成几个子任务,然后分配到各个处理器并行执行。由于每个处理器的任务量减小,并行执行时总的时间缩短,从而达到了加速计算的目的。Amdahl推导出的加速公式如下:

式中,p表示处理器个数;f为可串行执行的负载占总负载的比例,加速比用S表示。当p→∞ 时,S→1/f。
上式表明,即使处理器数目无限增大,并行系统所能达到的最大加速比也不超过1/f。以本系统为例,假如串行执行的计算负载占整个负载的1/4,并行执行的计算负载占整个负载的3/4,则1/f。因此,不论增加多少处理器,它所能达到的最大加速比为4倍。这是因为,程序的执行时间等于串行部分执行时间与并行部分执行时间之和。处理器的增加缩短了并行执行的时间,从而减少了整体的执行时间。然而串行执行时间与处理器数目p无关,增加处理器的数量无法加速串行部分,因此,串行部分执行时间过长而导致的处理时间过长问题不能通过增加系统处理器的数量来解决。
4.2 系统加速比性能测试
本系统的DSP编译环境为CCS5.1,每个核均工作在1 GHz频率。本实验采用面阵激光雷达仿真软件获取1500 m外的地面场景距离图像。为仿真场景内包含树木和坦克等目标,图像分辨率分别设置为32×32、64×64、128×128。

图6 系统实物图Fig.6 A photo of the LiADR data processing system
系统实物图如图6所示。图7中的左图为分辨率为128×128以伪灰度形式表示的原始距离图像,图7中的右图为检测到的地面目标(即坦克)。
本文将并行处理系统扩展至双核和六核,利用TI自带的TSCL计时函数分别对三种分辨率下的距离图像进行测试,采用计时函数得到处理一帧图像所用的DSP时钟周期数,并将该时钟周期数除以工作频率(1 GHz)即可得到处理一帧图像所消耗的时间。由于目前国内面阵激光雷达所能达到的分辨率为32×32,处理机四核并行时处理一帧图像需要50 ms左右,因此满足实时性要求。

图7 分辨率为128×128的激光雷达距离图像处理结果Fig.7 The processing results of 128 ×128 LiDAR range image
图8为采用不同的工作核数处理不同分辨率激光雷达图像时的性能。需要注意的是,由于本系统采用的多核模式是主从模式,主核用于和外部接口通信,只有辅核承担算法的运算任务,所以图中的核数表示的是承担算法运算的辅核个数。其次,本文处理的图像数据均存储于DDR3中,因此处理速度比存储于L2或者共享内存中要稍慢。
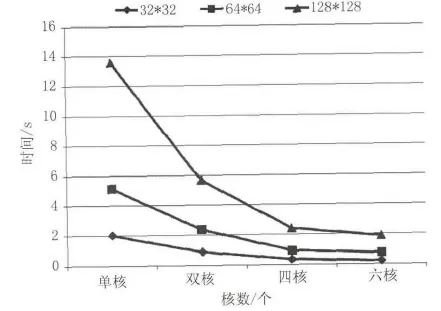
图8 多核的性能比较Fig.8 Performance comparison with multiple cores
从图8可看出,当工作核数较少时,通过增加工作核数(即对图像进行多次分区处理)会大幅减少处理时间。然而当核数较多时,核数增加带来的加速效益逐步下降。本文所设计的处理系统是将图像分区,每个区块交给单独核进行处理,即每一个核对应一个区块的图像,增加的并行工作的DSP核数,也就是增加图像分区后的区块数。由于分区后的相邻的区块之间重叠部分要大于待检测目标,以及每一区块的点数要足够多以保证地面拟合的精确度。因此即使分区的区块数增多,也并不代表每个区块的点云个数成比例减少。因此,每个核分担的计算负载没有成比例的减少。正如图8的时间曲线所示,随着核数的增加,加速效益逐步减小。
4.3 系统可扩展性分析
对本系统稍作修改即可实现可见光图像处理,本系统以对含噪声图像进行平滑及锐化处理为例演示本系统的良好扩展性。测试图像采用含椒盐噪声的lena图像以及原始的lena图像。实验结果如图9所示。
以上处理均是比较经典的滤波处理,图9中的平滑是以3×3的窗口对图像进行中值滤波;锐化则是以拉普拉斯算子对图像进行滤波。以上实验表明,该系统对于可见光图像处理有一定的适应性,为后续实现可见光与激光融合图像处理提供了有效途径。

图9 可见光图像处理结果Fig.9 Processing results for a visible image
5 结论
DSP+FPGA架构已成为大数据高速处理系统的典型构架,本文采用该构架以及DSP多核处理技术,实现了完整的激光成像雷达数据处理系统设计。测试结果表明,本文设计的系统工作稳定、可靠、扩展性强且处理一帧图像仅需50ms,达到了实时性要求。此外,本文还进一步分析了多核系统的并行加速比。理论分析和实验结果均表明,对于固定负载的处理系统,单纯通过增加并行核数来提高加速比的作用是有限的。当增加并行核数已经不能明显提高计算速度时,系统应从减少每个核串行执行的负载着手。即通过算法优化及减少核间通信所需的时间开销来提高总的运算速度。最后,本文还对该处理系统的可扩展性开展了一系列的实验。实验表明,该系统稍作修改同样适用于可见光图像的处理,为激光与红外融合图像处理系统设计与实现提供了重要的参考。
[1] GUO Yulan,LU Min,TAN Zhiguo,et al.Survey of local feature extraction on rang images[J].Pattern Recognition and Artificial Intelligence,2012,25(5):783-791.(in Chinese)郭裕兰,鲁敏,谭志国,等.距离图像局部特征提取方法综述[J].模式识别与人工智能,2012,25(5):783-791.
[2] GUO Fumin,DING Mingyue,ZHANG Xuming.Fast image matching based on multi-core DSP[J].International Conference on Intelligent Computation and Bio-Medical Instrumentat-ion(ICBMI),2011:68-70.
[3] HUANG Zongfu,WANG Weihua,XIONG Yunsheng,et al.Design and implementation of a real-time signal processor for astronomical opto-electronic observation system[J].Infrared and Laser Engineering,2012,41(3):671-675.(in Chinese)黄宗福,王卫华,熊运生,等.天文光电观测系统实时信息处理机的设计与实现[J].红外与激光工程,2012,41(3):671-675.
[4] M Himmelsbach,Felix V Hundelshausen,H-J Wuensche.Fast segmentation of 3D point clouds for ground vehicles[C].IEEE Intelligent Vehicles Symposium(IV),2010.USA:Institute of Electrical and Electronics Engineers Inc,2010,560-565.
[5] Wei Yao,Stefan Hinz,Uwe Stilla.Automa-tic vehicle extraction from airborne LiDAR data of urban areas using Morphological Reconstruction[J].Pattern Recognition Letters,2010,(31):1100-1108.
[6] Matthias R Schmid,Mirko Maehlisch,Juergen Dickmann,et al.Dynamic level of detail 3D occupancy grids for automotive use[C].IEEE Intelligent Vehicles Symposium(IV).USA:Institute of Electrical and Electronics Engineers Inc,2010:269-274.
[7] Wei Yao,Uwe Stilla.Comparison of two methods for vehicle extraction from airbor-ne LiDAR data toward motion analysis[J].IEEE Geoscience and Remote Sensing Letters,2011,(8):607-611.
[8] Yani Ioannou,Babak Taati,Robin Harrap,et al.Difference of Normals as a Multi-scale Operator in Unorganized Point Clouds[J].IEEE Conference on 3D Imaging,Modeling,Processing,Visualization and Transmission(3DIMPVT).USA,2012:501-508.
[9] Wei Yao,Stefan Hinz,Uwe Stilla.3D object-based classification for vehicle extract-ion from airborne LiDAR data by combining point shape information with spatial edge[C].6th IAPR Workshop PRRS.USA:IEEE,2010,1-4.
[10] Texas Instruments.KeyStone Architecture Semaphore2 Hardware Module User Guide[M].USA:Texas,2012:10-20.
[11] Pawel Gepner,Michal F Kowalik.Multi-Core Processors:New Way to Achieve High Systems Performance[C].International Sym-posium on Parallel Computing in Electrical Engineering,2006:9-13.
[12] Gene M Amdahl.Validity of the Single-processor Approach to Achieving Large Scale Computing Capabilities[C].AFIPS Spring Joint Computer Conference,1967:483-485.
猜你喜欢
北京测绘(2022年5期)2022-11-22
汽车观察(2021年8期)2021-09-01
中国交通信息化(2019年1期)2019-03-26
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年18期)2018-11-14
电子制作(2018年16期)2018-09-26
电气化铁道(2016年4期)2016-04-16
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
河南科技(2014年1期)2014-02-27
