
领域相关的汉语情感词典扩展
2015-04-14 07:50宋佳颖贺宇付国宏
中文信息学报 2015年6期
宋佳颖,贺宇,付国宏
(黑龙江大学计算机科学技术学院,黑龙江哈尔滨150080)
1 引言
随着Web2.0的兴起和社会媒体的迅速发展,情感分析(亦称意见挖掘)已成为自然语言处理研究的一个热点,并在近年得到快速的发展,出现不同的情感分析系统。但这些系统在大规模开放应用时依然面临情感词典覆盖度[1-2]、动态极性识别[3-6]和领域适应性[7-11]等挑战。一方面,词语极性是句子情感分类的基础。因此,大多数句子情感分类系统一般都带有一个情感词典以帮助确定词语极性[12]。但事先构造的情感词典很难覆盖开放意见文本中的所有情感词语。另一方面,许多情感词语或短语在不同的上下文或领域中呈现不同的极性。例如,在分属汽车和手机两个不同领域的评价“油耗高”和“屏幕分辨率高”中,情感词“高”分别表达负向和正向情感极性;而在“噪音大”和“驾驶空间大”两个例子中,它们虽同属汽车领域且使用同一个情感词“大”,但因其修饰不同的汽车属性而表达了不同的情感倾向性。因此,情感词典扩展,特别是领域和上下文相关的动态极性词语的识别和扩展近年来开始引起人们的广泛关注[1-11]。
本文在前人工作基础上,融合意见要素正规化信息,改进PolarityRank算法,提出一种面向产品评价文本的领域相关的汉语情感词典扩展方法。为此,我们首先采用条件随机场[13](conditional random fields,CRFs)序列标注方法识别意见句中的产品属性和评价等意见要素。而后综合考虑共现词频和词间距离等特征从意见句中进一步抽取属性-评价对。为了减少词典扩展的复杂性和噪声,我们还分别采用Jaccard系数以及修饰词、否定词缩减规则对抽取的属性及其评价进行了正规化。最后,改进基于连接图的PolarityRank算法扩展极性词典,使其适用于中文产品评论,从而提升词典扩展效果。
本文的组织结构如下:第二节是相关研究的总结;第三节详细介绍领域相关的情感词典扩展方法;第四节给出本文的实验结果及分析;最后一节是结论和展望。
2 相关研究
意见要素抽取往往作为情感词典构造和扩展的预处理,其主要任务是从给定的意见文本中抽取组成意见的要素,包括评价对象及其属性、评价词等。典型的意见要素抽取方法主要有规则方法[14]、基于依存知识的方法[14-15]和机器学习方法[3-4]。Hu和Liu[11]首先利用关联规则挖掘的方法从产品评论中抽取高频的名词及短语作为属性,扩展已有属性周边名词作为低频属性,这种方法由于规则限定,结果的召回率不佳。Zhang等[14]以属性词典和评价词词典为基础,利用依存关系匹配抽取属性-评价对。Jakob和Gurevych[16]在CRFs框架下探讨了领域内和跨领域产品属性抽取。此外,Wang等[17]以评价词词典为基础,采用自举迭代策略,依据上下文关联度获取属性及其评价词。
情感词典自动扩展研究目前主要围绕词典覆盖度和动态情感极性获取两个问题展开,并形成各具特色的扩展方法[16,18]。Kanayama和Nasukawa[1]将句内同现信息和跨句子的同现信息结合来学习词和短语的极性,从而构造领域相关的词典。这种方法强烈依赖于已知的种子情感词,对于种子词典不包含的未知情感词,缺少抽取能力。Qiu等[2]采用双重繁殖算法利用属性-情感词关系来扩展情感词典。为了获取上下文相关的动态极性知识,Esuli和Sebastiani[3]利用词典中词语的解释来确定词语的关联关系,并以此构建词语网络,进而通过连线权重来确定词语的极性。Wilson等[5]深入分析了影响词语动态极性的各种因素,并尝试在短语层面融合各种特征解决词语动态极性问题。此外,Wu和Wen等[6]研究了汉语形容词的极性消歧问题。虽然这些方法主要关注动态极性词所在的局部上下文,忽视了相关的领域,因而不能识别领域相关的情感极性词。领域相关的动态极性词识别对意见挖掘系统的领域移植至关重要。为此,Andreevskaia和Bergler[7]、Tan等[8]和吕韶华等人[9]分别从不同角度探讨了情感分类系统跨领域移植问题。Klebanov[19]将复述技术应用于词典扩展,采用了早期的一种基于枢轴的复述生成技术,对英法双语平行语料经过翻译得到对应短语作为复述资源完成词典扩展,通过文本的极性分类对词典进行了评估,但由于缺乏领域针对性,该词典无法发挥最大效用。Yu[20]对已知情感极性的文本进行分析,并不构建初步的种子情感词典,而是通过统计的方法抽取出一些词语作为情感特征词,此工作对文本的质量要求较高。此外,为了领域动态极性词的极性判定问题,Cruz等人[21]以属性-评价对为单位,提出基于PageRank[22]的随机游走排列算法PolarityRank,并用连词结构作为桥梁从未加工的意见语料对种子词典进行扩展。本文以PolarityRank算法为基础,面向产品评价文本展开汉语领域动态极性词典扩展研究。与Cruz等人[21]的研究不同,本文改进PolarityRank算法连接图构图方式以适应汉语的特点,同时融合产品属性及其评价的正规化信息,以减少词典扩展的噪声,进而提高词典扩展质量。
3 情感词典扩展方法
3.1 情感词典扩展任务
在本文研究中,情感词典扩展的任务是在种子词典基础上,从特定领域的产品评价文本中自动抽取未知情感词语及其属性,并根据改进的PolarityRank算法确定相应的情感极性,从而完成相应词条的构造。如图1所示,本文的情感词典扩展系统主要包括以下四个模块。
(1)预处理模块的主要任务是对给定的产品评价文本进行分词和词性标注,为后续的意见要素识别和抽取做准备。为了提高词法分析的可靠性,本文采用基于语素的分词和词性标注一体化的系统[23]完成预处理任务。
(2)意见要素识别模块的主要任务是在词法分析基础上识别产品属性及其评价等产品意见的主要要素。本文将这一问题视作序列标注问题,并采用条件随机域方法完成这一任务。
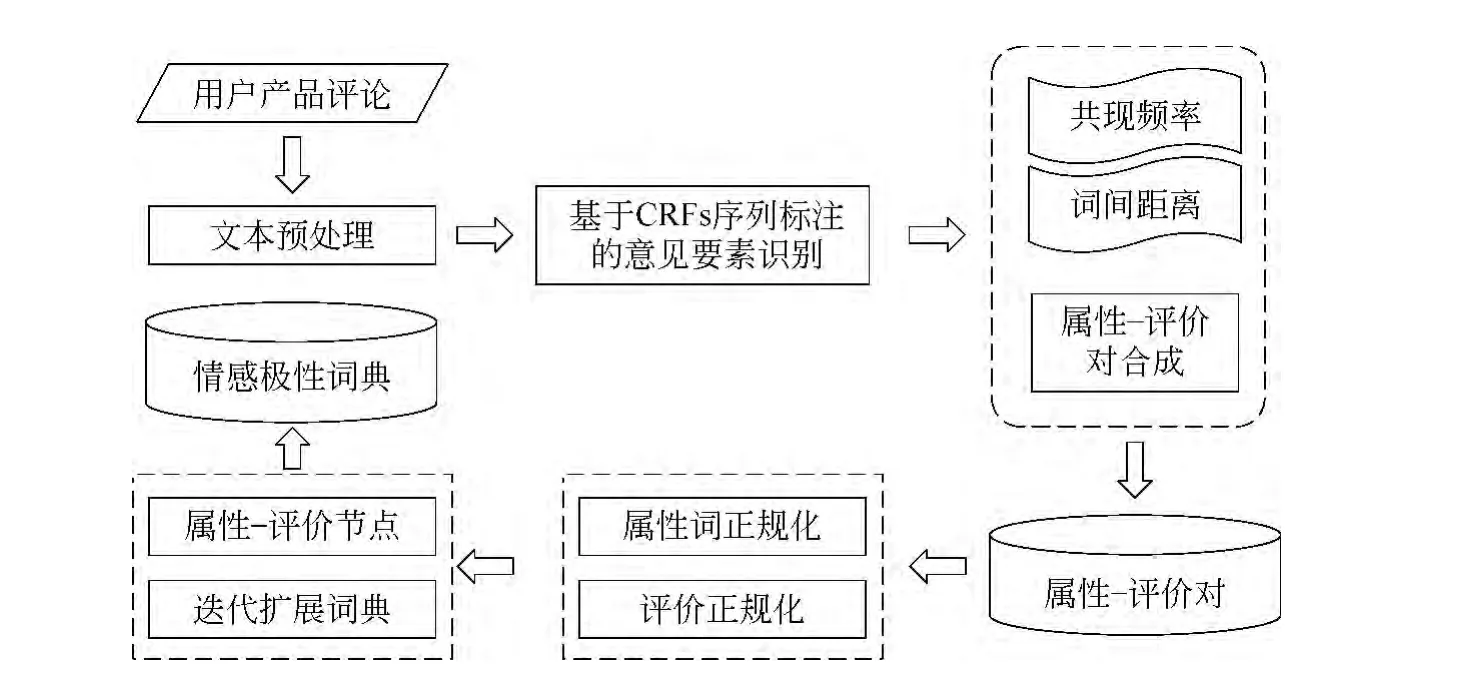
图1 词典扩展流程图
(3)属性-评价对匹配/合成模块的任务是从抽取的属性和评价中根据其在意见句中的共现关系判断他们是否形成修饰关系。存在修饰关系的属性-评价对实际上是情感词典潜在的一个扩展词条。
(4)属性-评价对正规化模块的任务是对属性-评价对中存在的大量互为复述关系的属性词及其评价分别进行正规化处理,为同一词意的词确定一致化标准,从而获取更多的属性-评价对情感极性,降低词典扩展的难度。
(5)基于PolarityRank的情感词典扩展模块的任务是将步骤(4)正规化后的属性评价对作为候选词条,构造相应的无向连接图,并通过迭代确定相应的情感极性。
值得注意的是动态极性词在不同的领域或不同的上下文中可能呈现不同的情感极性。例如,词典词语“高”是一个典型的汉语动态极性词语,在“配置-高”中,“配置”表示手机产品的一个属性,“高”是关于该属性的一个评价词,表示正向情感极性;而在“油耗-高”中,“油耗”是汽车产品的一个属性,此处的“高”具有负向情感极性。为了确定地描述情感词语的动态极性,本文情感词典的词条结构为<eval,attr,polar,domain>。其中,eval代表评价词,attr代表产品属性,polar代表情感极性,domain代表所在领域标记。产品属性attr可以是相应产品的某一部分、组件或性能指标。情感极性polar∈{-1,1},其中,-1表示负面(negative)极性,1表示正面(positive)极性。
下文3.2~3.6节将分别介绍图1所示的词典扩展各模块的基本原理。
3.2 意见要素识别
在词典扩展中,意见要素识别的主要任务是识别给定意见句子中的属性及相应的评价。本文把意见要素识别看作是一个序列标注问题,鉴于条件随机场模型在解决序列标注问题时的良好表现,我们以词作为序列标注的基本单位,应用条件随机场框架完成属性、评价词的识别。
如图2所示,每个意见要素在标注中获得一个形如x-y的标记。其中,x代表相应词语在所在意见要素的位置标记,y代表意见要素类别标记。考虑到词典扩展的实际,本文定义三种意见要素类别标记,即{A,E,O},分别用来表示产品属性、评价和非意见要素词语。至于位置标记,本文采用常见的四标记体系,即{S,B,M,E},分别表示单个词语构成的意见要素和意见要素首词、中间词和尾词。此外,在四标记SBME基础上,本文还引入一个标记I表示意见要素首个中间词,形成五标记体系SBIME,以提高意见要素标注性能。

图2 意见要素标注样例
考虑到属性及其评价的长度,在意见要素序列标注中我们选取当前词语前后五个词语窗口内词形和词性以及相应的一元、二元和三元上下文特征来构造特征模板。
3.3 属性-评价对合成
给定一个意见句,它可能蕴含多条意见信息,即一个意见句子可能有多个属性-评价对。属性-评价对合成的任务是从意见句子潜在的多个属性和评价组合中抽取合适的属性-评价对。如式(1)所示,为了简化问题,本文在意见要素标注基础上,考虑属性和评价的共现频度及其距离来确定属性attr和评价eval匹配的可能性。
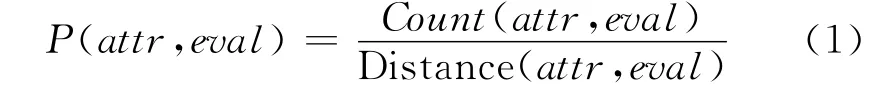
其中,Count(attr,eval)表示属性attr和评价词eval在所有产品评论中的共现频率,Distance(attr,eval)表示在对应句中的属性和评价词之间的字数,实际应用时为防止分母为0,对Distance进行了加0.05的调整,对于中间含有标点符号的情况做了加4的调整。P(attr,eval)实际上反映了当前的属性和评价词匹配成对的可能性。对于同一属性的每个候选属性-评价对,我们选取其中P值最大的作为正确的属性-评价匹配对。
3.4 属性-评价对正规化
由于用户生成的意见文本行文比较自由,属性共指和评价复述现象比较普遍。加之,在分词和意见要素标注时,评价词语边界确定存在不一致的现象。因此,在情感词典扩展前有必要对属性和评价进行正规化,以进一步提高词典扩展的质量。为了简化问题,本文分别采用Jaccard系数和规则方法来分别进行属性和评价的正规化。
(1)属性正规化
由于存在多个属性词表示相同意见对象的情况,例如,“屏幕分辨率”和“分辨率”,“油耗”、“耗油”和“耗油量”等,如果这些属性词搭配了相同的评价词,则可以看作是同意的属性评价对,我们可将其进行一致化处理,从而降低词典扩展的难度,减少未知极性词条的数量。因此我们用式(2)所示的Jaccard系数计算属性词间的相似度,以获取产品属性的同意属性词簇,为属性词生成互为复述的属性词集合,选择集合中在评价文本中出现频率最高的属性词作为标准,对其他属性词进行一致化处理。
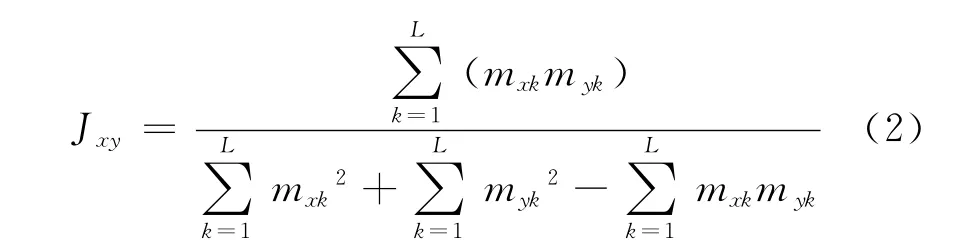
其中,mxk表示字符k在短语x中出现的总次数,myk则表示字符k在短语y中出现的总次数。通过多组实验为相似度判定确定阈值。
(2)评价正规化
针对抽取得到评价词切分不规范及含有冗余信息的现象,我们采用下面规则处理评价信息。
Rule 1 由于抽取得到的一些极性词前面还含有修饰词,这为后续的词典扩展带来不利的影响,例如,非常硬→硬,有点高→高,这两个词对的左右两边实际表示了相同的评价意义。在词典扩展阶段,由于抽取得到的很多评价短语含有冗余的修饰部分,会造成连接图中大量的同类节点无法合并,这将直接影响情感预测结果。因此,我们在扩展前先对所有极性词进行修饰词的过滤,以达到正规化的效果。本文过滤的修饰词包含收集所得的程度副词、肯定副词和少量语气副词共76个。因而实验阶段构建连接图时,可以有效地减少边数,从而提高极性预测精度。
Rule 2 由于抽取得到的极性词有些还被否定词所修饰,这种情况也会对极性判定和词典扩展产生干扰,我们又用八个否定前缀依次对极性词进行过滤,对去除否定修饰的极性词再次查找已知词典,从而获得更多的已知极性的属性-评价对,减小词典扩展的任务难度。
3.5 种子词典
我们根据训练部分的极性信息,得到初始的种子情感词典,即其中的属性-评价对词条都含有对应的情感极性,本节任务是完成对测试语料中的词条的极性预测,从而实现情感词典的扩展。从训练语料中抽取得到领域内动态情感词,汽车领域22个,手机领域20个,在词典扩展时要对两类极性词分别考虑。
3.6 PolarityRank
Cruz等人[21]所提出的PolarityRank算法主要用连词结构作为桥梁来进行情感词典扩展。然而,汉语产品评价文本中连词结构并不多见,通常有关联关系的特征就会出现在同一个短句中。为此,我们对PolarityRank算法进行了改进,通过词语共现关系及词频构建无向连接图,以适合汉语特性。情感词典扩展步骤具体如下:
· 根据训练语料和测试语料中的属性-评价对在评论语句中的共现关系,构建无向图,出现在同一句评价中的两个属性-评价对可以连接成一条边,属性-评价对为节点。构建初始图时,静态评价词和动态评价词没有区别,在简化图阶段,节点合并时两者的判定会有差别。静态评价词节点只要评价词相同就算作相同节点,动态评价词节点需要对应评价和属性都完全相同才可以看作是相同节点。共现频率作为边的权重,节点合并后边的权重也会有相应增加。
·未知极性节点初始极性为0,根据对每个点计算得到的PR值为节点更新极性,从而完成对无向图的节点极性更新。
·迭代计算每个点的PR值直到没有新的节点极性值产生,完成词典扩展。这里,节点vi的PR+(vi)和PR-(vi)值可分别采用式(3)和式(4)计算。
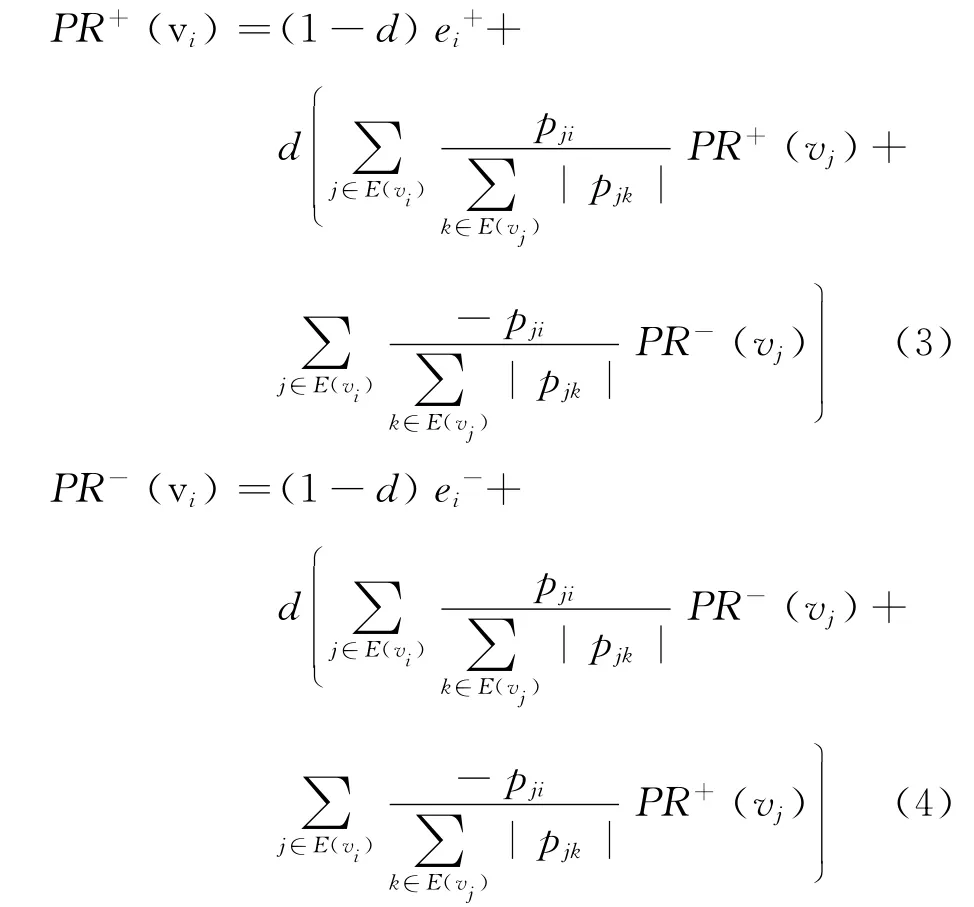
式中,d是一个自定参数,本文采用PageR-ank[22]推荐的0.85。e+i代表与当前节点vi关联的极性为正的节点个数,e-i代表与vi关联的极性为负的节点个数,E(vi)表示与vi相连的边集,pji表示节点vi和节点vj形成的边的权重。
PR+(vi)和PR-(vi)值可分别作为vi所代表的评价词为正向极性词、负向极性词的可能性概率值。由式(3)、式(4)可以看出,每个节点的极性计算都会考察关联的所有节点的极性,这也是共现策略的重要应用。节点vi的极性Polarity(vi)可由以下三条规则确定。
(1)若PR+>PR-,Polarity(vi)=1;
(2)若PR+<PR-,Polarity(vi)=-1;
(3)若PR+=PR-,Polarity(vi)=0。
图3给出词典扩展算法的伪码描述。该算法的基本思想为:每次迭代将新得到极性的属性评价对作为已知词条,继续下一轮计算,直到获得极性的属性-评价对不再增加为止。

图3 词典扩展算法
4 实验结果与分析
为了验证上述方法的有效性,我们构建一个领域相关的情感词典扩展系统,并分别应用于汽车和手机两种产品评论的情感极性分析。本节将给出相应的实验结果及其分析。
4.1 实验数据
如表1所示,本文实验所用语料来自汽车、手机两个领域的网络用户评价并进行了意见要素的标注,标注内容包括意见对象、产品属性、评价和属性-评价对对应的情感极性。意见要素标注形式如图4所示。
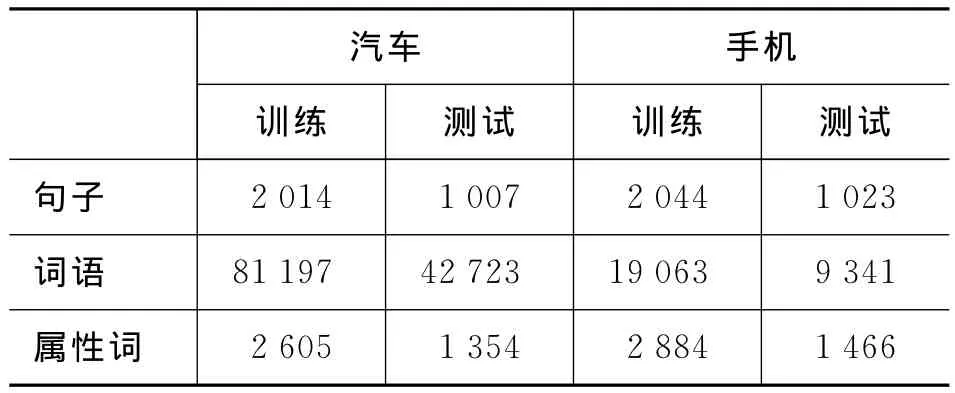
表1 实验语料统计信息

图4 实验语料标注样例
表2给出了测试语料中未知极性词语的统计信息。
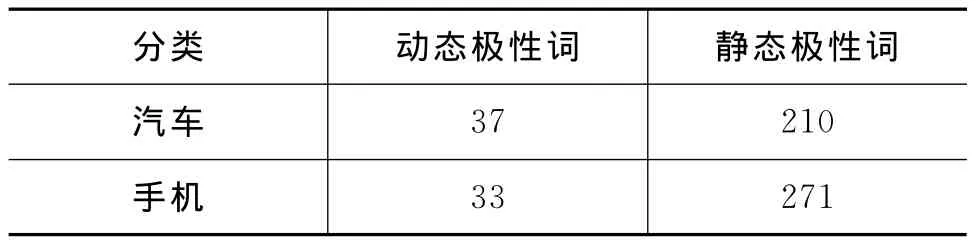
表2 测试语料中未知极性词语统计
4.2 属性评价词抽取结果
为了验证意见要素标注性能对词典扩展质量可能产生的影响,我们测试了不同标记下不同领域的意见要素标注效果。本实验的测试指标为精确率(Precision,P)、召回率(Recall,R)和F-测度(F)。结果如表3所示。
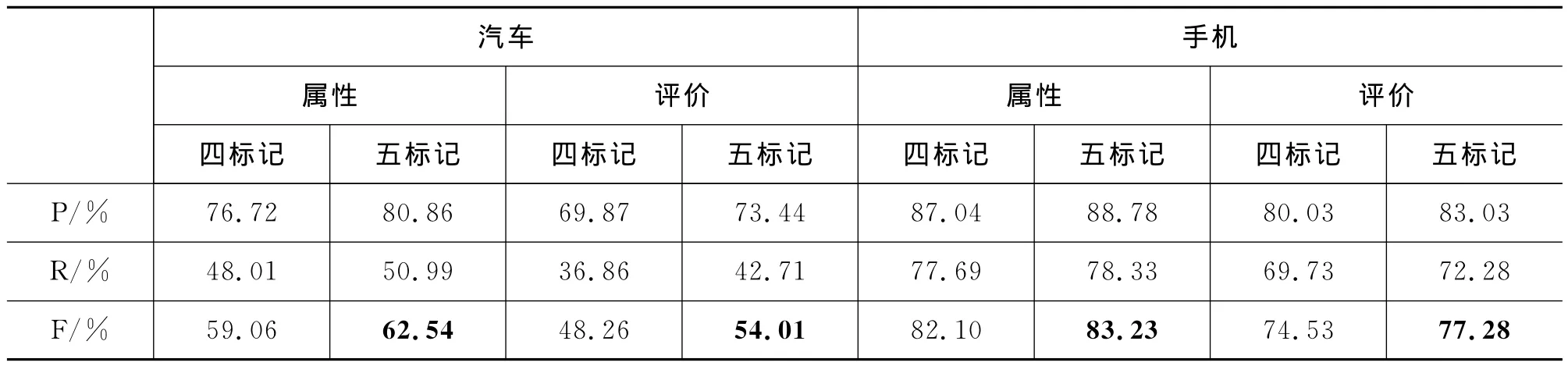
表3 意见要素标注结果
从表3的结果可以看出:五标记系统在两个领域的抽取结果都明显优于相应的四标记系统。因此,后续的实验均采用五标记系统抽取所得的属性和评价词。对汽车和手机两个领域测试语料中所识别的属性和评价进一步采用3.3节的匹配原则,分别得到687和1 135个属性-评价对。
4.3 情感词典扩展结果
为了考察不同因素对情感词典扩展的影响,我们在实际情感词典扩展测试中设计了以下五组实验。
实验1 应用3.6节的词典扩展算法直接预测测试语料中未知极性词的极性;
实验2 针对人工标注的测试语料中的各个属性-评价对(金标数据),应用3.6节的词典扩展算法判定属性-评价对极性;
实验3 先用3.4节的属性正规化方法对所有属性进行标准化处理,再用3.6节词典扩展算法预测测试语料中未知极性词的极性;
实验4 先用3.4节的属性正规化方法对所有属性进行标准化处理以及评价正规化规则1过滤修饰词,再应用3.6节词典扩展算法预测测试语料中未知词极性;
实验5 先通过3.4节的属性正规化方法标准化属性词,再用评价正规化规则1为极性词过滤修饰词,用规则2过滤否定词,最后应用3.6节算法扩展词典。
词典扩展的构图阶段在实验1时共得到汽车领域属性-评价对节点3 292个,边数为2 417条。手机领域节点4 019个,边数为1 414条,而经过正规化后实验5的汽车领域边数减少为2 213条,手机领域的边数减少为1 279条,有效合并了相同意见节点。属性一致化时本着使尽可能多的有共指关系的属性能被识别的原则,确定3.4节的相似度计算阈值为0.5。评测部分采用常用指标准确率(P)、召回率(R)和F-测度(F),为了考察对两类极性词词典的扩展效果,首先对动态极性和静态极性词进行了分别评测,然后对合并的极性词典完成评测。实验结果如表4和表5所示。
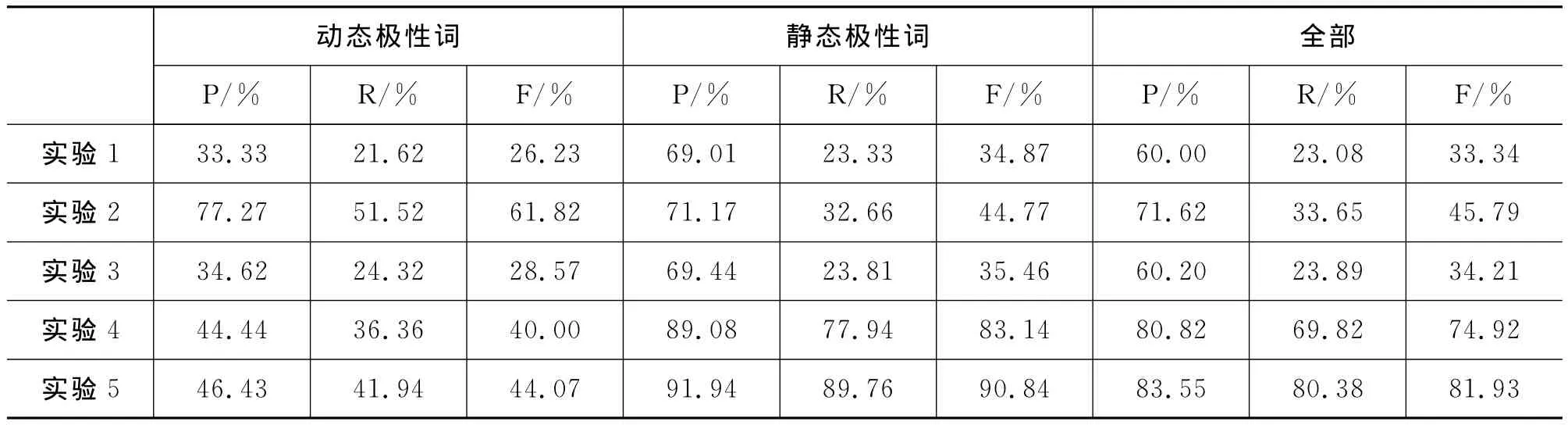
表4 汽车领域词典扩展结果

表5 手机领域词典扩展结果
从表4和表5的实验结果可以看出:(1)对比实验1、3、4和5的结果,经过正规化处理后,两个领域的极性词典扩展性能均得到较大提高;(2)同等条件下,实验2的扩展性能优于相应的实验1的结果,这说明意见要素识别以及属性-评价对匹配性能直接影响到词典扩展性能。此外,同等条件下,手机领域的词典扩展结果优于汽车领域,其原因可能是汽车评价文本质量本身较差,相应的意见要素识别性能较低(表3),从而导致最后的词典扩展性能不佳。
4.4 扩展的情感词典对情感极性分类的影响
为了进一步说明领域词典扩展对情感分析的影响,我们从上述两个领域的语料中随机抽取1 000句,并采用以下三组不同的词典进行句子级情感极性分类测试。
词典一 知网(HowNet)+台湾大学(NTUSD)+ 清华大学(汉语情感词极值表);
词典二 词典一+本文构建的静态情感词典(4.3节实验5);
词典三 词典二+本文构建的动态情感词典(4.3节实验5)。
注意:本实验的情感极性分类采用简单的基于词袋模型的分类方法,通过词典中的情感词给各句打分,完成极性判定。实验结果如表6所示。
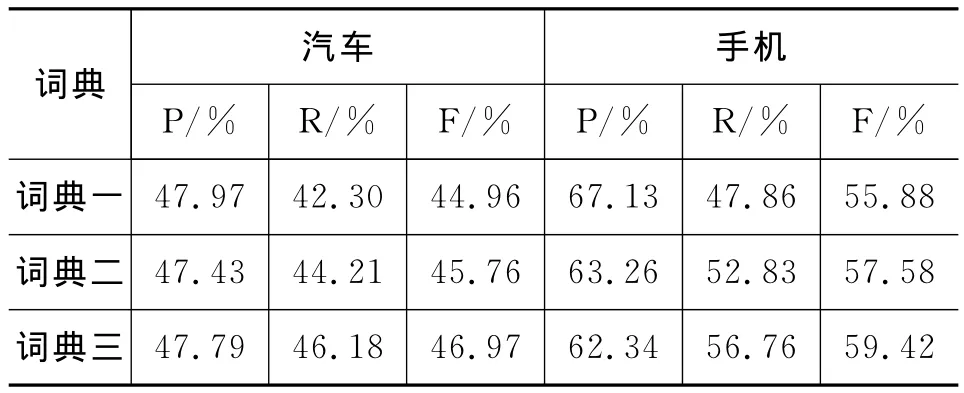
表6 采用不同词典时的情感极性分类结果
表6的实验结果显示:加入扩展的领域静态情感词语后,虽然极性分类的精确度稍有下降,但在召回率和F值方面都有显著的提高,这从侧面说明增加情感词典的覆盖度有助于提高情感极性分类的召回率和整体性能。相比于加入扩展的领域静态词语,在加入扩展的动态情感词语后,情感极性分类的召回率和F-值提升幅度更为明显,这进一步验证了领域情感词典对于领域相关的情感分析和意见挖掘的重要意义。
5 结论与展望
针对汉语产品评论的特点,本文融合意见要素正规化信息,提出一种面向汉语产品评价的基于PolarityRank的领域相关的情感词典扩展方法。在汽车和手机两个领域的产品评价语料上的实验结果表明意见要素标注以及正规化直接影响到情感词典的质量。相应的句子情感极性分类实验表明引入扩展的领域相关的情感词语可以有效提高情感分类性能。
虽然本文实验取得预期结果,证明了领域相关的情感词典对于汉语情感分析的意义。但由于本文研究的重点限制,所采取的意见要素正规化、属性-评价对抽取和情感极性分类方法均比较简单,不够系统,可能影响到情感词典扩展性能。在将来的研究中,我们将系统探索上述这些问题,同时扩大语料规模和领域范围,以进一步提高领域相关的情感词典扩展性能。
[1] H Kanayama,T Nasukawa.Fully automatic lexicon expansion for domain-oriented sentiment analysis[C]//Proceedings of EMNLP'06,2006:355-363.
[2] G Qiu,B Liu,J Bu,C Chen.Opinion word expansion and target extraction through double propagation[J].Computational Linguistics,2011,37(1):9-27.
[3] A Esuli,F Sebastiani.Determining the semantic orientation of terms through gloss classification[C]//Proceedings of the CIKM'05,2005:617-624.
[4] 王荣洋,鞠久鹏,李寿山,周国栋.基于CRFs的评价对象抽取特征研究[J].中文信息学报,2012,26(2):56-61.
[5] T Wilson,J Wiebe,P Hoffmann.Recognizing contextual polarity:An exploration of features for phraselevel sentiment analysis[J].Computational Linguistics,2009,35(3):399-434.
[6] Y Wu,M Wen.Disambiguating dynamic sentiment ambiguous adjectives[C]//Proceedings of COLING'10,2010:1191-1199.
[7] A Andreevskaia,S Bergler.When specialists and generalists work together:Overcoming domain dependence in sentiment tagging[C]//Proceedings of ACL '08,2008:290-298.
[8] S Tan,G Wu,H Tang and X Cheng.A novel scheme for domain-transfer problem in the context of sentiment analysis[C]//Proceedings of CIKM'07,2007:979-982.
[9] 吕韶华,杨亮,林鸿飞.基于SimRank的跨领域情感倾向性分析算法研究[J].中文信息学报,2012,26(6):38-44.
[10] A Ismail,S Manandhar.Bilingual lexicon extraction from comparable corpora using in-domain terms[C]//Proceedings of COLING'10,2010:481-489.
[11] M Hu,B Liu.Mining opinion features in customer reviews[C]//Proceedings of AAAI'04,2004:755-760.
[12] 傅向华,刘国,郭岩岩,郭武彪.中文博客多方面话题情感分析研究[J].中文信息学报,2013,27(1):47-55.
[13] J Lafferty,A McCallum,F Pereira.Conditional random fields:Probabilistic models for segmenting and labeling sequence data[C]//Proceedings of ICML'01,2001:282-289.
[14] L Zhang,F Jing,X Zhu.Movie review mining and summarization[C]//Proceedings of CIKM'06.2006:43-50.
[15] 刘鸿宇,赵妍妍,秦兵,刘挺.评价对象抽取及其倾向性分析[J].中文信息学报,2010,24(1):84-88.
[16] N Jakob,I Gurevych.Using anaphora resolution to improve opinion target identification in movie reviews[C]//Proceedings of ACL'10,2010:263-268.
[17] B Wang,H Wang.Bootstrapping both product features and opinion words from Chinese customer reviews with cross-inducing[C]//Proceedings of IJCNLP'08,2008:289-295.
[18] 李寿山,李逸薇,黄居仁,苏艳.基于双语信息和标签传播算法的中文情感词典构建方法[J].中文信息学报,2013,27(6):75-81.
[19] B Klebanov,N Madnani,J Burstein.Using Pivot-Based Paraphrasing and Sentiment Profiles to Improve a Subjectivity Lexicon for Essay Data[J].TACL,2013,1:99-110.
[20] H Yu,Z Deng,S Li.Identifying Sentiment Words Using an Optimization-based Model without Seed Words[C]//Proceedings of ACL'13.2013:855-859.
[21] F Cruz,J Troyano,F Ortega,et al.Automatic expansion of feature-level opinion lexicons[C]//Proceedings of the 2nd Workshop on Computational Approaches to Subjectivity and Sentiment Analysis,2011:125-131.
[22] L Page,S Brin,R Motwani,et al.The PageRank citation ranking:bringing order to the web[J].1999-66:Stanford Digital Library Technologies Project.
[23] G Fu,C Kit,J Webster.Chinese word segmentation as morpheme-based lexical chunking[J].Information Sciences,2008,178(9):2282-2296.
猜你喜欢
通信技术(2021年12期)2022-01-25
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
时代英语·高一(2019年5期)2019-09-03
英语文摘(2019年5期)2019-07-13
天然产物研究与开发(2018年9期)2018-10-08
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
航天返回与遥感(2014年1期)2014-07-31
外语教学理论与实践(2014年2期)2014-06-21
中关村(2014年5期)2014-05-15
