
基于意群划分的中文微博情感倾向分析研究
2015-04-21 08:33杨小平朱建林张中夏肖文韬
中文信息学报 2015年3期
桂 斌,杨小平,朱建林,张中夏,肖文韬
(1. 中国人民大学 信息学院, 北京 100872;2. 淮阴师范学院 计算机科学与技术学院,江苏 淮安 223300)
基于意群划分的中文微博情感倾向分析研究
桂 斌1,2,杨小平1,朱建林1,张中夏1,肖文韬1
(1. 中国人民大学 信息学院, 北京 100872;2. 淮阴师范学院 计算机科学与技术学院,江苏 淮安 223300)
微博作为一种新兴的社交网络平台,逐渐成为公众发布个人信息,获取实时信息,表达个人观点的新平台。针对微博情感倾向判断的问题,提出了一种基于意群划分的中文微博情感倾向分析(STDSG)方法。引入意群的概念,提出微博意群划分算法,根据意群间的关系,考虑否定词、程度词及标点符号的对情感倾向分析的影响,提出计算微博意群情感倾向的方法。在给定的数据集上,实验结果准确率达到了80.1%,总体性能优于基于情感词典的方法及基于支持向量机的方法。
微博; 意群; 情感倾向
1 引言
近年来,随着互联网的发展,论坛、博客等网络交流平台相继出现,人们越来越习惯于在网上发表主观性的言论,形成了大量带有情感倾向性的文本。微博作为一种新兴动态交流的多媒体博客,逐渐成为公众发布个人信息,获取实时信息,表达个人观点的新平台。
情感倾向分析是指利用计算机技术自动分析带有观点信息的句子或文档,从而提取出用户感兴趣的主题或特征,并分析其语义极性倾向(褒义、贬义或中性)和强度[1]。情感倾向性涉及人们的观点、看法和评价,包括人类行为相对于社会标准的评价,产品相对于国家和行业强制标准、用户偏好、审美观的评价等。情感倾向包括文本所反映的情感的方向(褒或贬)及其强度。微博的倾向性分析可广泛应用于社会舆情分析、产品在线跟踪与质量评价、影视评价、博客声誉评价、新闻报道评述、事件分析、股票评论、图书推荐、企业情报系统、客户关系管理(CRM)等方面,在社会经济和人民生活方面具有重要意义。
2 相关研究
情感分析是近年来才兴起的一个研究方向,是目前数据挖掘、文本挖掘、自然语言处理等领域的热点研究课题之一,主要研究如何识别、分类、标注和提取主观文本及其所表达的情感、情绪和观点。它也被称为意见挖掘(Opinion Mining)、意见分析 (Opinion Analysis)、情感分类(Sentiment Classification)或者主观性分析(Subjectivity Analysis)[2]。情感分析可分为词语级、句子级、篇章级等几个研究层次。词语级语义倾向计算是句子级和篇章级语义倾向分析的基础。Turney[3]将情感倾向量化为一个实数值测度,单个词或短语的情感倾向可以进一步被用来判断整个句子或篇章的情感倾向,通过机器学习算法把整个文本区分为“赞扬”和“批评”的情感倾向。Hatzivassiloglou[4]用词语间的语义关系判断词语的情感倾向性。Kamps等人利用WordNet提供的词语相似度进行词语语义倾向计算[5],但该方法只针对形容词, 并只考虑了词语间的同义关系。杜伟夫等提出一个可扩展的词汇语义倾向计算框架, 将词语语义倾向计算问题归结为优化问题[6]。Meena[7]等则提出了针对句子的情感分析,不仅考虑单个词语的情感倾向,还结合了句子的结构,语法以及其他语义信息。Wang 等[8]将启发式规则和贝叶斯分类结合,将形容词和副词抽取出来作为特征词来计算句子的情感倾向。王根等[9]将条件随机场应用于句子情感分析,提出基于多重冗余标记的方法。杨超等[10]加入了句子出现的副词的影响因子计算每个网络评论中的每个句子的情感极性。Pang首次在篇章级情感分类任务中引入机器学习的方法[11],他们通过对比NB,ME和SVM三种分类模型,同时使用n-gram词语特征和词性特征,发现unigram特征效果最好。Cui的实验证明,unigram的效果只有在训练语料较少时较好;当训练语料增多时,n-gram(n>3)发挥了更大作用[12]
微博作为一种新兴的网络平台,从一诞生起就吸引了大批学者对其进行研究。对于微博的情感分析的研究目前主要是以Twitter为研究对象,中文微博的情感分析研究正方兴未艾。Davidiv等[13]利用Tweets中的标签中的标签和笑脸符号作为训练标签,训练出一个有监督的类似KNN的分类器,然后应用分类器对Tweets进行情感分类。Barbosa等[14]针对Tweets的情感分类问题,采用了二步法: 他们首先采用抽象特征训练分类进行主客观分类,然后采用相同特征但修改词的情感极性的权重来进行情感极性分类。谢丽星等[15]提出了一种基于层次结构的多策略中文微博情感方法,取得了较好的情感分析效果。
目前关于微博的情感倾向性分析的准确率还比较低,与实际应用的要求相比还有大的差距。我们认为相比于新闻、博客等长文本,微博内容要短小精悍得多,也更加口语化和不规范,包含的信息量少,这些为微博的情感分析增加了难度。因此我们引入了意群的概念,对微博进行意群划分,在意群划分的基础上进行微博情感倾向性分析,总体的分析处理流程如图1所示。

图1 总体分析流程
3 意群的划分
关于意群目前还没有统一的定义,索翠萍[16]认为意群是指复句中由意义和形式关系相对密切的两个以上的分句所组成的结构中心。周昌乐等[17]认为所谓意群,指的是我们的语言所表达的思想都是通过一群相互关联的意义单位体现出来的,而这些意义单元根据其所处语言片段的角色,有大有小,因此意群分割也就有一个多尺度问题。
句子是由词语和短语组成的,是具有一定语调并表达一个完整意思的语言运用单位。按照结构来分,句子通常划分为单句和复句。相对于复句,通常单句表达的结构简单,意思简明。而复句是由两个或以上意义相关,结构上互相不构成句子成分的分句组成的句子。复句相对于单句来说结构更加复杂,句子表达的含义也更多。通常,复句都包含多个分句,每一个分句都表达了独立的含义。我们比较认同文献[17]的观点,为了处理的方便,本文将句子中的分句作为意群,运用逗号和分号作为句子意群的分隔符。
意群的情感倾向主要由带有情感倾向的词语决定,但如果只对情感词进行处理,忽略意群的内部结构以及上下文环境,会降低意群情感倾向分析的准确率。例如,“好看却很难吃”,如果只考虑情感词,最后分析出来的情感倾向就是中性的,而实质上意群所表达的意思是负向的,程度词“很”在这里是加强了“难吃”的程度。为了提高意群情感倾向分析的准确性本文将转折词也作为意群划分的依据。换句话说,意群通常是复句中的分句,或者被转折词隔开的短语。划分意群的算法如下所示。
算法1: 句子意群划分算法
输入: 句子
输出: 意群
Step1 根据逗号和分号将句子划分成一个个意群O
Step2 将意群进行分词,并逐个读取划分后的词语word,若word属于转折词,那么截取该意群
Step3 若所有句子处理完毕,则转入Step4,否则转入Step1
Step4 算法结束
4 微博情感倾向分析
对意群进行情感倾向分析时,情感词是影响意群情感倾向的主要成分,但是仅考虑情感词是不够的。本文除了要考虑意群中出现的情感词以外,还要考虑否定词、程度词及标点符号。否定词的出现能够让情感词的情感倾向性反转,而程度词则会影响情感词表达的情感倾向的程度。一些标点符号也会表现出情感倾向,起到加强意群或否定的作用。
如果在一个意群中,情感词前面存在否定词,那么该情感词的倾向性反转具体的办法是对于一个情感词,检查它前面是否存在否定词,并且两个词语的距离在一定范围内,那么该否定词有效,情感词情感倾向反转,否则否定词无效。这是中文中的“双重否定”的现象。双重否定就是存在两次否定,表达的是肯定的意思。例如,“我不得不说这件事情有问题。”句子里的“不得不”表示的就是双重否定,起到了肯定的作用,因此上句话的意思表达的是“我说这件事情有问题”。对于一个否定词,需要检查它前面一个否定词是否有效并且两个词在一定的距离以内,若满足条件,则可以确定为“双重否定”,两个否定词的效果消失。
程度词对情感倾向性分析有着重要的作用,当一个情感词被程度词修饰时,它的情感倾向强度会被增强或者减弱。例如,“我非常喜欢这双鞋子”和“我喜欢这双鞋子。”表达的情感倾向强度就不一样,虽然句子中同样使用了情感词语“喜欢”,但第一句中“喜欢”被程度词“非常”修饰,“喜欢”所表达的正面情感倾向被加强。为了能够准确的识别程度词,本文对知网提供的程度词进行修正,建立了程度词表。按照程度词表达的强烈程度,将程度词划分为: 最、很、较和弱四个级别。
标点符号不仅能够表达语法信息表示停顿信息以外,还能传达情感信息。不同的标点符号在语法上有不同的功能,在修辞上也表达不同的感情色彩。本文计算情感倾向时,还考虑了标点符号的作用,主要选取了感情色彩比较明显的感叹号“!”和“?”。通常,感叹号能够加强语气,表示对前面所说话语的肯定。问号多代表疑问语句,有怀疑的意思,有一定的否定意义在里面。但是否定的程度没有直接使用否定强烈。本文分别给予感叹号权重1.5,疑问号权重-0.5,其他符号权重1。
每个意群的情感倾向可按公式(1)计算。
(1)
其中n表示情感词的个数,αneg表示情感词的否定权重,βadv表示情感词的程度权重,γpun表示意群的标点符号权重。
意群间通常有一定的关系,主要包括并列关系,递进关系和转折关系。在递进关系中,后面的句子表达的意思比前一句更进一层,表达的情感更强烈。转折关系中,后一句的意思通常不是顺着前一句说的,而是做了转折,表达相反的意思。在转折关系中,通常前面的分句只是为了后面的分句做铺垫,主要是为了突出转折词以后的概念。表示并列关系的词语: 和,跟,同时,同,及,与,并,并且。表示递进关系的词语: 不但……而且……,况且,不仅……并且……;不仅……而且……,而且。表示转折关系的词语: 但,但是,可是,然而,不过,虽然……但是……。根据意群间的关系,句子的情感倾向值计算公式如式(2)。
(2)
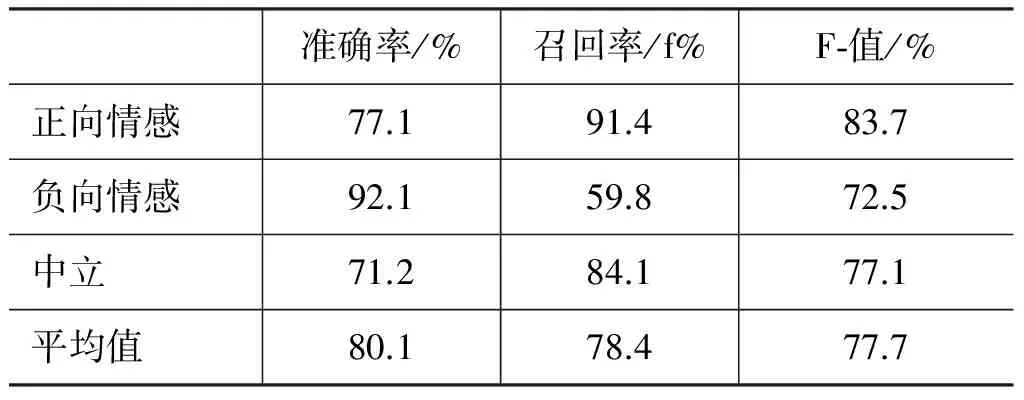
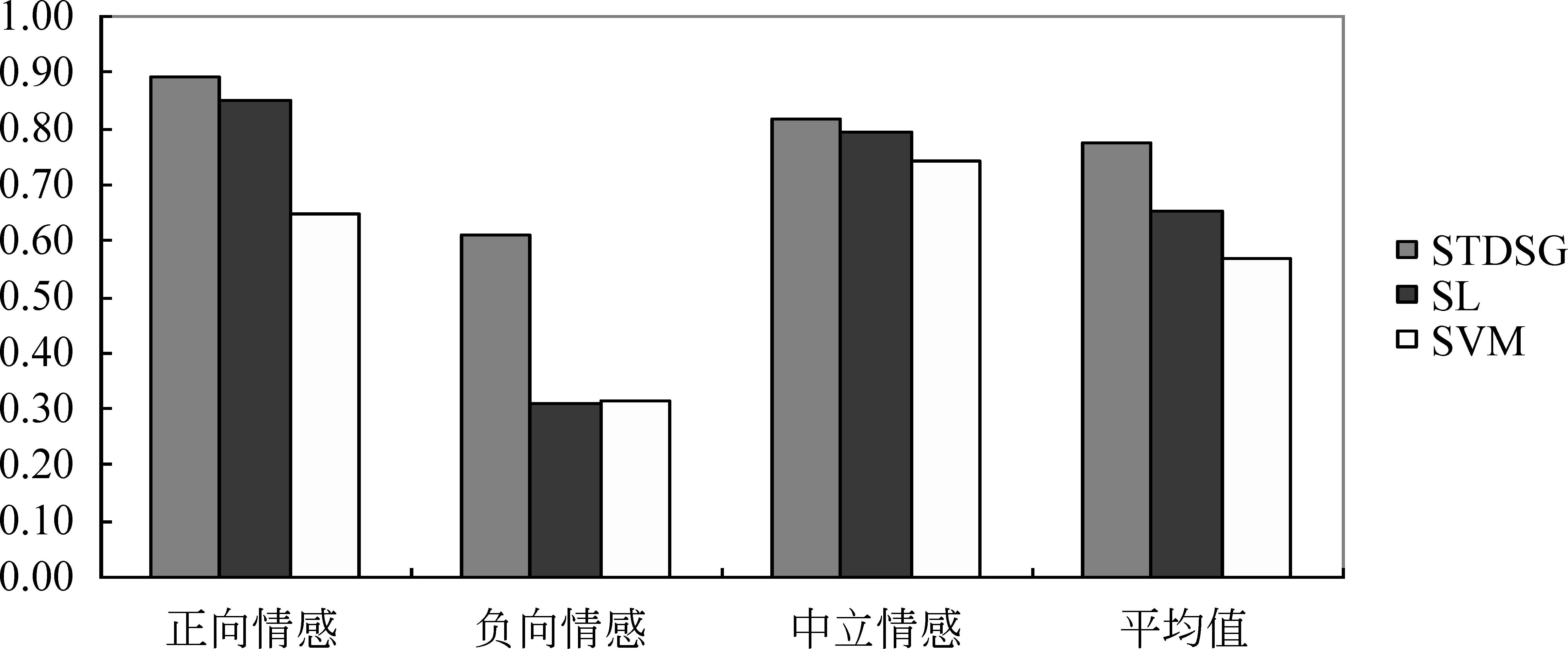
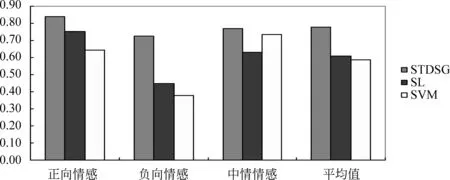
其中sensegroup表示意群,n表示意群的个数,ai表示的是权重。在并列关系中,每个意群占相同的权重。在递进关系的意群中,a1 由于140字的限制,微博一般都比较短小,包含多个句子的微博较少。因此,本文计算微博的情感倾向时不考虑句子之间关系。根据公式(1)、(2),某条原创微博的情感倾向计算公式如式(3)所示。 (3) 根据公式(3)可以判断微博的情感倾向为式(4)。 (4) 5.1 实验数据及平台 通过爬虫程序从新浪微博上抓取了3 000条关于“京沪高铁”事件的微博,人工标注每条微博的情感倾向。为保证微博情感倾向标注的可靠性,由三个标注者分别对数据集进行情感倾向标注,然后应用投票法确定情感的情感倾向。使用中科院分词工具ICTCLAS对微博语料进行分词及词性标注,选用知网提供的情感词典(HowNet)作为情感倾向分析的依据。实现程序使用JAVA语言并在eclipse平台实现,选择的数据库平台是MYSQL5.0。 5.2 实验分析 为了更好地评价本文的实验结果,我们引入了准确率和召回率及F-值作为评价指标。准确率是指算法分析准确的某一倾向性的微博条数与进行该倾向分析时分析到的微博总条数的比率;召回率是指算法分析准确的某一倾向性的微博条数与所有该倾向微博总条数的比率;F-值是准确率与召回率的调和值。在标注的数据集中选取600条微博,其中包括正面微博210条,负面微博210条,中性微博180条。表1给出了本文算法的实验结果。 表1中给出了本文提出的基于微博话题的情感分析算法实验结果,其中正向情感倾向的准确率为77.1%,召回率为91.4%;负向情感倾向的准确率为92.1%,召回率为59.8%;中立情感倾向的准确 表1 本文算法实验结果 率为71.2%,召回率为84.1%。从以上数据可以看出,负向情感倾向存在准确率高,召回率相对较低的情况。负向情感倾向的召回率低,其原因我们分析主要有以下几点: (1)表达负向的情感词不在情感词典中。由于HowNet的并不能将所有的情感词都囊括其中,以目前网络中负面评论占主流的情况来看,负向情感词要比其他情感词要丰富得多。因此,有必要HowNet的情感词典进行扩充,以提高情感分析的召回率;(2)中性词表达负面倾向。中文表达的灵活性,使得许多词义上的中性词可以表达出情感倾向性,这是中文的优越性所在,但也给文本情感倾向分析带来了较大的困难;(3)反讽,人们使用带有正面情感倾向的词语来表示负面的意思。目前后两种情况还比较难以解决,因为牵涉到语义理解的问题。 5.3 实验对比 在标注的数据集中选取2 400条微博,其中包括正面微博840条,负面微博840条,中性微博720条。在相同实验环境下,将本文的算法(STDSG)与基于情感词典的情感倾向分析算法(SL)以及基于支持向量机(SVM)的情感倾向分析算法进行对比分析。基于情感词典的情感倾向分析算法(SL)是仅以HowNet作为微博情感倾向性判断的依据。基于支持向量机(SVM)的情感倾向分析算法,训练集与测试集的比例为4∶1,核函数选用最常用的径向基核函数:K(x,y)=e-‖x-y‖2/2σ2。运用SVM进行模式分类时需要确定两个参数: 惩罚因子C和RBF核函数中的半径参数σ。通过网格搜索法来确定最佳的惩罚因子C和核半径参数σ。图2~4分别给出了不同算法的准确率、召回率以及F-值结果。 从图2~4的对比实验结果来看,本文的算法总体上要优于其他两种算法。 另外也可以看出,使用情感词典的算法对微博进行情感分析的准 确 率要高于使用SVM机器学习 图2 准确率的对比实验结果 图3 召回率的对比实验结果 图4 F-值的对比实验结果 的方法。原因可能是微博中包含的信息量少,因此从微博中提取的特征会非常稀疏,高维的稀疏矩阵影响了机器学习的分类精度,同时机器学习方法比较适用于包含多个特征词语的长文本。在对微博进行情感倾向分析时,添加了否定词,程度副词等上下文信息的分类方法要优于只使用情感词语的方法,显然否定词、程度副词等上下文信息对于微博情感倾向分析具有重要作用,是不可不考虑的语义信息。 本文引入意群的概念,将微博中句子结构不单单是从句法结构上加以划分,而是在语义角度进行划分。将逗号、分号以及转折词均作为意群的分隔符,根据意群间的并列、递进、转折等关系建立了基于意群的情感倾向计算公式。然后考虑否定词、程度词及标点符号的影响,进行微博情感倾向分析,提出了基于意群的微博情感倾向性算法。实验结果表明了该算法相对于基于情感词典(SL)和基于SVM的情感倾向分析算法,具有较高的准确率和召回率,能更加准确地判断出微博用户的情感倾向。算法的不足之处在于,在负向情感的微博的召回率方面相对较低,有必要在意群的语义理解方面进行更深一步的研究。 [1] 娄德成,姚天防.汉语句子语义极性分析和观点抽取方法的研究[J].计算机应用,2006, 26(11): 2622-2625. [2] B Pang, L Lee. Opinion Mining and Sentiment Analysis[J].Foundations and Trends in Information Retrieval, 2008, 2(1-2):1-135. [3] Peter D Turney. Unsupervised Learning of Semantic Orientation from a Hundred-billion-word Corpus. Technical Report [ R ], National Research Council of Canada: M. L. Littman, 2002: 1-9. [4] Hatzivassiloglou,V, McKeown,K Predicting the semantic orientation of adjectives[J].In: ACL.1997:174-181. [5] Kamps J, Marx M, Mok ken R J, et al. Using WordNet to measure semantic orientation of adjectives[C]//Proceedings of LREC-04,4th Int Conf on Language Resources and Evaluation.Lisbon:LREC,2004: 1115-1118. [6] 杜伟夫,谭松波,云晓春,等.一种新的情感词汇语义倾向计算方法[J].计算机研究与发展, 2009, 46(10): 1713-1720. [7] Meena,A,Prabhakar,T V. Sentence level sentiment analysis in the presence of conjuncts using linguistic analysis. In:Amat i,G.,Carp inet o, C.,Romano,G.(eds.)ECIR 2007.LNCS,vol. 4425: 573-580. [8] Wang Chao, Lu Jie, Zhang Guangquan.A semantic classification approach for online product reviews[C]//Proceedings of the 2005 IEEE/WIC/ACM International Conference on Web Intelligence (WI′5), 2005. [9] 王根,赵军.基于多重冗余标记CRF的句子情感分析研究[J].中文信息学报, 2007, 21 (5): 51-55. [10] 杨超, 冯时, 王大玲等. 基于情感词典扩展技术的网络舆情倾向性分析[J]. 小型微型计算机系统, 2010,4:691-695. [11] B Pang,L Lee, S Vaithyanathan.Thumbs up?Sentiment classification using machine learning techniques[C]//Proceeding of the Conference on Empirical Methods in Natural Language Processing(EMNLP),2002: 79-86. [12] Cui H,Mittal VO,Datar M.Comparative experiments on sentiment classification for online product revies[C]//Proceedings of the AAAI2006.2006: 1265-1270. [13] Dmitry Davidiv, Oren Tsur, Ari Rappoport. Enhanced Sentiment Learning Using Twitter Hash-tags and Smileys. In Coling 2010(poster paper), 2010: 241-249. [14] Luciano Barbosa, Junlan Feng. Robust Sentiment Detection on Twitter from Biased and Noisy Data.In Coling 2010(poster paper),2010: 36-44. [15] 谢丽星,周明,孙茂松. 基于层次结构的多策略中文微博情感分析和特征抽取[J].中文信息学报, 2012,26(1):691-695. [16] 索翠萍.意群—一种划分多层复句的好方法[J].职业技术教育,1999,18:25. [17] 周昌乐,丁晓君. 汉语机器理解的困难与对策一种意群动力学的观点[J].现代外语, 2000,23 (2):195-201. Chinese Micro-blog Sentiment Orientation Identification Based on Sense Group Partition GUI Bin1,2, YANG Xiaoping1, ZHU Jianlin1, ZHANG Zhongxia1, XIAO Wentao1 (1. School of Information, Remin University of China, Beijing 100872, China; 2. School of Computer Science and Technology, Huaiyin Normal University, Huaian, Jiangsu 223300, China) Micro-blog as a new interaction social networking is rich in people’s opinions. Aiming at the Microblog sentiment orientation indetification,this paper proposes an algorithm based on the Sense Group partition.After an introduction to the concept of sense group, we propose the algorithm for the sense group partition. Then, together with the negative words, the degree words and punctuation, we establish the formula of sentiment identification based on the relationship between the sense groups. The experiments reveals an accuracy of 80.1%, outperformed the sentiment lexicon based approach and the SVM based method. Micro-blog; sense group; sentiment orientation 桂斌(1977—),博士,讲师,主要研究领域为文本挖掘、智能信息处理。E⁃mail:guibin_163@163.com杨小平(1956—),博士,教授,主要研究领域为信息系统工程。E⁃mail:yang@ruc.edu.cn朱建林(1979—),博士研究生,讲师,主要研究领域为语义分析、机器学习。E⁃mail:linjie_zhu@126.com 1003-0077(2015)03-0100-06 2013-04-08 定稿日期: 2013-07-15 国家自然科学基金项目资助(61203242) TP391 A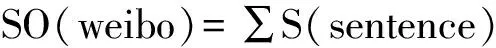

5 实验结果及分析

6 结论

猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
体育科技文献通报(2022年3期)2022-05-23
有色金属(矿山部分)(2021年4期)2021-08-30
考试与评价·八年级版(2021年4期)2021-08-14
天津医科大学学报(2021年2期)2021-03-29
开放教育研究(2020年2期)2020-03-31
中国修辞(2017年0期)2017-01-31
考试周刊(2016年61期)2016-08-16
长江学术(2016年4期)2016-03-11
中央民族大学学报(自然科学版)(2014年3期)2014-06-09
