
面向GPU异构集群的自学习负载均衡调度算法
2015-04-28 06:49王继刚葛铮铮杜军朝
西安石油大学学报(自然科学版) 2015年3期
刘 惠,王继刚,葛铮铮,顾 群,陈 倩,杜军朝
(1.西安电子科技大学 软件学院,陕西 西安 710071; 2 中兴通讯股份有限公司,四川 成都 610041)
面向GPU异构集群的自学习负载均衡调度算法
刘 惠1,王继刚2,葛铮铮1,顾 群1,陈 倩1,杜军朝1
(1.西安电子科技大学 软件学院,陕西 西安 710071; 2 中兴通讯股份有限公司,四川 成都 610041)
由于GPU的高性能计算能力,越来越多地被用于集群系统中,但同时也给集群带来节点级的异构问题,使原来适用于同构集群的调度算法在异构集群中性能大大降低。为使异构节点间的负载均衡,降低总的作业执行时间,提出了一个面向GPU异构集群的自学习负载均衡调度算法。首先对Torque调度器进行扩展,使其支持GPU作业调度,然后将提出的自学习调度算法在Rocks操作系统及Torque调度器软件中实现。真实物理集群上的实验结果表明,扩展后的Torque调度器很好地支持GPU任务的调度,自学习调度算法较原来的Torque调度算法能达到更好的负载均衡。
异构集群; GPU;自学习调度算法;负载均衡
任务调度是集群系统的核心,它能大大提高资源利用率,提高集群总体性能。文献[1]提出了一个基于熵的变化趋势的负载均衡算法,文献[2]提出了一个基于集群的动态负载均衡算法,文献[3]提出了一种面向集群系统的两阶段节能调度算法,文献[4]提出了一个基于集群的能量有效性调度算法,但它们都是针对同构集群提出的算法。文献[5]提出了异构集群环境下的作业调度方法,文献[6]提出一个基于异构集群的折衷能耗有效性和负载均衡的调度算法,文献[7-8]提出一个异构集群的基于历史任务运行时间的调度算法,文献[9-13]提出基于负载均衡的调度算法。但这些算法或是基于同构集群,或者基于的异构集群只是各个节点的计算能力不同,并没有考虑差异很大的GPU[14-15]所构成的异构集群。本文研究由CPU和GPU计算节点所构成的异构集群的调度问题,提出一个自学习负载均衡调度算法,并且在Torque集群平台上用H.264软件进行了实验。
1 面向GPU的Torque集群平台扩展
Torque是一个开源的集群资源管理软件,被广泛地应用于高校和其他研究机构的高性能计算集群中。Torque在资源管理方面功能强大,支持超过1 500个计算节点,支持几乎全部UNIX/Linux系的操作系统,并且在不断更新中。但是在实际使用过程中发现,Torque调度性能差,集群的负载严重不平衡,并且无法识别和调度GPU作业。所以,现有Torque集群平台不支持有GPU计算节点的异构集群,GPU可以提供数十倍乃至于上百倍于CPU的性能,在大数据时代,支持GPU成为技术发展的必然。
本文对Torque上万行源码进行分析,对Torque源码进行了扩展和实现,使其支持对GPU作业的调度。具体对Torque调度器的调度和资源获取2个模块进行了改进。首先,针对GPU资源的获取和保存进行改进,使得Torque调度器能够解析并获取计算节点的GPU资源信息并且保存下来;其次,在作业请求GPU资源的解析这个关键技术点上进行改进,使得调度器能够解析出哪些作业请求GPU资源,从而在调度的时候将请求GPU计算资源的作业分配到配置有GPU的计算节点上。这部分扩展工作涉及到大量数据结构和源代码剖析,在此不作深入阐述。本文重点论述面向GPU异构集群基于历史信息的自学习动态负载均衡调度算法的设计与实现。
2 问题定义
本文提出了一个面向GPU异构集群的基于历史信息的自学习动态负载均衡调度算法,本章阐述集群平台架构模型、性能指标和作业模型及问题定义。
异构集群架构模型:集群由若干服务器组成,包含1个主节点和m个计算节点。主节点主要负责集群上作业的调度和资源管理等工作,计算节点则负责具体的计算任务。节点间通过高速局域网互连,计算节点和主节点间通过高速网络进行通信,计算节点间不发生数据交换。集群中的节点是异构的,有些节点配置有GPU+CPU,可以针对CUDA和OpenCL程序进行并行计算;而有些节点则仅包含CPU。
符号定义:设m个计算节点为SNODE={N1,N2,…,Nm},对于任意一个计算节点Ni,关注其4个实际性能参数,即CPU频率、内存大小、GPU频率、GPU_MEM大小,分别用rate_cpui、memi、rate_gpui、mem_gpuiCPU来表示。基于此,再定义出计算节点Ni的4个负载参数:CPU利用率、内存利用率、GPU利用率、GPU内存利用率,分别用utlz_cpui、utlz_memi、utlz_gpui、utlz_gpumemi表示。
作业模型:多用户可以在集群上提交多个作业,用户提交的n个作业记为集合SJOB={J1,J2,…,Jn},设各个作业之间没有依赖关系,相同类型的作业可以反复多次提交(比如反复进行的科学计算,程序执行过程都相同,只不过输入数据不同)。
问题描述:基于以上GPU异构集群架构模型和作业模型,给定SJOB和SNODE两个集合,找到集合SJOB到集合SNODE的一个映射,满足以下2个条件:①若作业需求GPU资源,则作业被映射到GPU+CPU节点上,反之则可以被映射到CPU节点上,也可以被映射到GPU+CPU节点上;②最终映射使得集群所有节点之间达到负载均衡,减少作业总的执行时间。
3 算法概述
3.1 最大剩余能力算法
本文所提出的面向GPU异构集群的自学习调度算法主要思想是根据每个节点的相对性能值以及实时负载信息估算出节点的剩余计算能力,从而将作业发送到剩余计算能力最强的节点执行,以达到集群负载均衡。算法伪代码见算法3.1。

算法3.1GPUCluster-SCHEDULINGInput:作业集SJOB={Ji,i=1,2,3,…,n},资源集SNODE={Ni,i=1,2,3,…,m}Output:调度结果O={O1,O2,O3,…,;Ok=
算法第1步从异构集群的主节点获取所有计算节点的信息,即rate_cpu、mem、rate_gpu、mem_gpu、utlz_cpu、utlz_mem、utlz_gpu、utlz_gpumem这几个参数及当前正在运行的作业数目。在设计动态负载均衡调度算法时,负载信息的实时获取是重点,需协调“获取方式”和“获取间隔”这2个参数间的关系。本算法采取集中式调度思想,选取PUSH机制作为获取方式,即在集群的每个计算节点部署一个“心跳程序”,该程序定期收集每个计算节点的状态信息,并将信息发送给主节点。在设置“获取间隔”参数时,若太大则导致负载信息陈旧调度不准确,若太小又会给主节点带来太多额外通信与计算开销。根据集群实测出的经验值,本算法将心跳频率设置为每300s1次。在这300s内,若某计算节点上的某作业执行完成,则该计算节点会向主节点报告作业执行完毕,同时将该节点的当前负载信息捎带上报。这样,当主节点调度算法调度新作业时,能够根据作业执行的历史信息对负载进行估计。
算法第2步获取所有在队列中等待调度的作业信息,包括每个作业请求的资源特征,其是否需GPU资源等。算法第3步对计算节点的负载信息表tab_node进行初始化。算法第4步读取历史作业信息表tab_job,该表主要记录了历史作业在哪个计算节点上运行、运行的总时间以及其平均的CPU、GPU和内存使用率等数据。特别说明的是,要获得程序运行期间的CPU、GPU和内存的平均利用率,需要对作业整个运行期间的CPU、GPU利用率和内存利用率进行采样记录。系统采样的时间间隔选取很关键,本文选取的采样间隔为10s。
算法第6步到第17步是主调度循环,第6步更新所有计算节点的剩余计算能力,任意一个节点Ni剩余计算能力的计算式为
VALUEi=k2Q1+k2Q2-k3Q3+k4Q4,
(1)
(2)
(3)
(4)

(5)
式(1)中,VALUEi的值代表节点Ni的剩余计算能力,VALUEi的值越大,该节点就越可能成为作业的执行节点,k1、k2、k3、k4是用来调节CPU、内存、GPU、GPU内存4者对节点剩余计算能力影响程度比重的权值,它们的和为1。
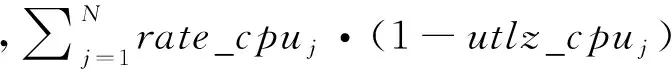
算法第7步根据改进的FCFS策略选取一个作业j。算法第8步到第11步用于检查选定的作业是否可以运行,这个阶段的检查主要是看作业请求的资源是否超过了系统规定的限制,或者是否超过了用户的资源使用限制等。如果超过了,则重新选择一个作业;如果没有超过,则根据作业请求的资源信息匹配所有计算节点,筛选出备选节点集Sn。算法第13步,若备选节点集Sn不为空,则选择其中能提供最大计算能力的节点作为运行节点。算法15步启用负载预测机制来预估作业给节点带来的负载变化μ。算法16步根据预测值来更新节点负载信息表。接着,算法继续选择下一个作业进行调度并重复上述过程。
3.2 基于历史信息的自学习负载更新算法
由前所述,算法第15步对被调度节点的负载增值进行预测,本文提出了基于历史信息自学习的负载变化估计,用来修正作业调度后带来的负载变化。算法3.2给出了负载估计函数伪代码,其算法原理是根据同一类作业运行的历史信息来推断本次作业运行所带来的负载变化,因为作业的资源使用量是由自身的属性决定的,在不同节点上虽然带来的负载不同,但使用的资源总量是一定的,如总的CPU时间和物理内存。前文中对作业的跟踪记录所形成的已运行作业负载信息表,是本负载变化估计算法的输入。
下面分3种情况说明预测算法的执行过程,其中前2种情况对应于算法3.2的第1、2步,最后一种情况对应于算法3.2的剩余部分。

算法3.2 PRIDICTION(tab_job,j,n)1.IF(MATCH(tab_job,j)=TRUE) //有作业历史信息2.μ←GETLOAD(tab_job,j)//从表中直接获取负载3. ELSE//没有作业历史信息4. L←用户设定一个值5. N←TOTALJOBNUM(tab_job)//作业总数6. IF(N=0)7. μ←total_loadn/job_numn//节点总负载与任务数的比值8. ELSEIF(N=1)9. μ←GETLOAD(tab_job,1)10. ELSE IF(N>1)11. IF(L>N) L←N12. μi←GETLOAD(tab_job,L)//最近L个作业的负载信息13. L1←[0.2L]14. μ←FORECAST(μi)15. RETURNμ
(1)若作业在表中出现一次,则根据历史作业信息即可求得新节点负载变化的估计值。
(2)若作业在表中出现多次,则根据这n次历史作业的信息分别求得新节点负载变化的估计值,然后将这些估计值的平均值作为新节点负载变化的估计值。
(3)如果同类任务没有出现过,那么需要预测任务的负载。本文的策略是,根据局部性原理,利用已经存在的其他作业历史信息做出预测。假设目前任务负载表中总共有N条记录:
①若N为0,则将节点当前的负载除以当前任务数,算得任务负载的平均值,作为负载变化的预测值。在“心跳程序”中,可以同时向主节点发送本地正在运行的任务数目信息。
②若N为1,则以唯一的作业负载作为预测负载。仅以一个作业负载历史信息来预测是很不准确的,但是本文设计的是一个自学习的过程,随着时间的推移,已完成的任务会越来越多,预测也会越来越准确。
③若N>1,考虑最近的L个作业,L由用户设定,若L>N,则令L等于N。将L分为L1和L2两部分来计算平均负载,其中L1部分时间更近。根据局部性原则,设置L1部分的权值大于L2部分。据此算出L个节点的加权平均值作为新节点的负载估计值。
由于本文提出的预测算法是基于自学习的,随着执行任务的增加,任务负载信息表中的记录不断增多,从而任务负载的预测精度也随之提高。准确的预测对保持负载信息的实时性具有至关重要的作用。
4 实验与分析
本文实验硬件平台是基于CPU+GPU异构集群,共有4个节点,具体参数见表1。其中,cluster是集群的主节点,它也可同时作为一个计算节点使用;compute-0-0是一个性能较弱的计算节点;compute-0-1是一个配置了Tesla系列GPU的计算节点,性能

表1 集群节点的性能参数
最强;compute-0-2是一个配置了Quadro系列GPU 的计算节点,性能较弱。软件方面,作为主节点,cluster安装的操作系统是Rocks的管理节点版本FrontEnd,FrontEnd可以让主节点轻松地管理计算节点;计算节点安装的是Rocks的计算节点版本Compute。另外,主节点cluster上还安装了集群管理软件Torque的全部组件,包括服务器组件pbs_server、作业执行组件pbs_mom以及调度器组件pbs_sched;compute-0-0、compute-0-1、compute-0-2计算节点则安装了作业执行组件pbs_mom。
本文选取图像卷积算法和H.264视频编码作为应用实例。在实验中,将作业乱序地、反复地提交到集群。为了能更方便地观测集群各个节点的负载变化,利用集群监控工具Ganglia观察集群的实时负载并作记录。首先采用Torque原有的调度器进行实验,接着将本文提出的算法部署到扩展后的Torque调度器中进行实验,得到如图1—图4的实验结果。
从图1和图2可以看出,使用Torque原有的调度算法集群的负载严重不平衡。集群中第1个节点迅速地到达约70%的负载水平之后,第2个节点的
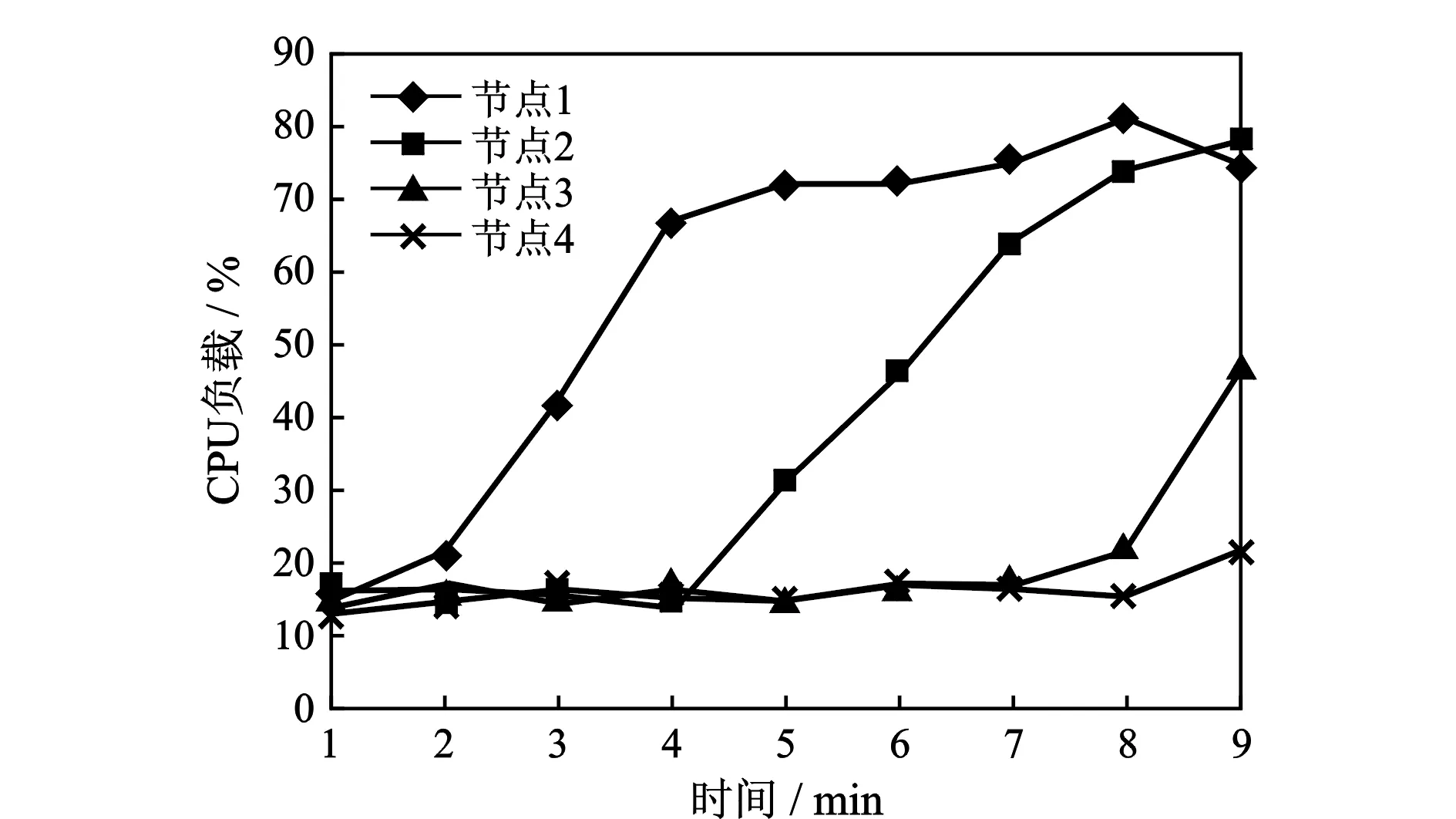
图1 采用Torque原有调度算法的CPU负载变化

图2 采用Torque原有调度算法的内存负载变化
负载才开始增加。此外还发现,在第1个和第2个节点接近满载时,后2个节点还没什么变化。由此可以证明Torque原有调度算法的性能很差。
通过对图3和图4的观察,发现4个节点的CPU和内存负载大体上一致增长,达到了近似的负载均衡。因此,本文设计的算法可行、有效,成功地对Torque进行了扩展,不但使其增加了对GPU作业的支持,而且实现了一种效果良好的负载均衡调度。
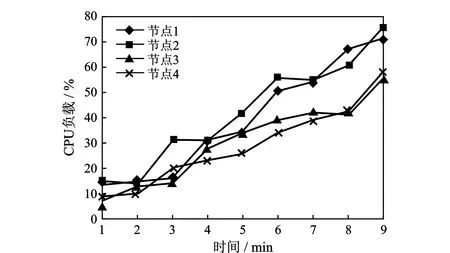
图3 采用本文调度算法的CPU负载变化

图4 采用本文调度算法的内存负载变化
5 结 语
本文研究了由CPU和GPU计算节点所构成的异构集群的调度问题,提出一个自学习负载均衡调度算法,并且在Torque集群平台上用H.264应用软件进行了实验。本文的主要贡献有:①研究同时包含CPU和GPU节点的异构集群的调度问题,提出了一种面向GPU异构集群的基于历史信息自学习的动态负载均衡调度算法。②与模拟数据算法仿真验证不同,本文在真实物理Torque集群环境中实现了所提调度算法,实现部署、编写、运行H.264应用程序和视频数据,得出实验结果。③由于传统Torque集群平台不支持GPU计算节点,且其调度算法非常简单。因此,本文研究了Torque上万行源码,发现了Torque在作业调度方面存在的缺陷和不足,对Torque集群平台进行扩展,使其能够识别、管理、调度GPU资源。然后提出一种面向GPU异构集群的基于历史信息自学习的动态负载均衡调度算法,并且算法在现有Torque平台中实现、部署和运行。
[1] Wu Kehe,Chen Long,Ye Shichao,et al.A load balancing algorithm based on the variation trend of entropy in homogeneous cluster[J].International Journal of Grid and Distributed Computing,2014,7(2):11-20.
[2] Patil S,Gopal A.Cluster performance evaluation using load balancing algorithm[C].International Conference on Information Communication and Embedded Systems.Piscataway:IEEE,2013:104-108
[3] 刘伟,尹行,段玉光,等.同构DVS集群中基于自适应阈值的并行任务节能调度算法[J].计算机学报,2013,36(2):393-407. LIU Wei,YIN-Hang,DUAN Yu-Guang,et al.Adaptive threshold-based energy-efficient scheduling algorithm for parallel tasks on homogeneous DVS-enabled clusters[J].Chinese Journal of Computers,2013,36(2):393-407.
[4] Liu Wei,Li Hongfeng,Shi Feiyan.Energy-efficient task clustering scheduling on homogeneous clusters[C].Proceedings 201011th International Conference on Parallel and Distributed Computing,Applications and Technologies(PDCAT 2010).Los Alamitos:IEEE Computer Society,2010:382-385.
[5] 刘莉,姜明华.异构集群下的任务调度算法研究[J].计算机应用研究,2014,31(1):80-84. LIU Li,JIANG Ming-hua.Research of task scheduling algorithm on heterogeneous cluster[J].Application Research of Computers,2014,31(1):80-84.
[6] Terzopoulos G,Karatza H.Power-aware load balancing in heterogeneous clusters[C].Proceedings of the 2013 International Symposium on Performance Evaluation of Computer and Telecommunication Systems.Toronto:IEEE,2013:148-154.
[7] Ye Bin,Dong Xiaoshe,Zheng Pengfei,et al.A delay scheduling algorithm based on history time in heterogeneous environments[C].ChinaGrid Annual Conference.Piscataway:IEEE,2013:86-91.
[8] Gregg C,Boyer M,Hazelwood K,et al.Dynamic heterogeneous scheduling decisions using historical runtime data[C/OL].[2014-05-03].http://www.cs.virginia.edu/~skadron/Papers/gregg_a4mmc11.pdf.
[9] 史琰,刘增基,盛敏.一种保证负载均衡的网络资源分配算法[J].西安电子科技大学学报,2005,32(6):885-889. SHI Yan,LIU Zeng-ji,SHENG Min.A novel network resource allocation algorithm with load balance guarantees[J].Journal of Xidian University,2005,32(6):885-889.
[10] Zhang Keliang,Wu Baifeng.Task scheduling for GPU Heterogeneous cluster[C].Cluster Computing Workshops(Cluster Workshops),2012 IEEE International Conference.Beijing:IEEE,2012:161-169.
[11] Payli RU,Erciyes K,Dagdeviren O.Cluster-based loadbalancing algorithms for grids[J].International Journal of ComputerNetworks & Communications(IJCNC),2011,3(5):253-269.
[12] Youn Cand,Chung L.An efficient load balancing algorithm for clustersystem[C].IFIP International Conference on Network and Parallel Computing.Berlin:Springer Berlin Heidelberg,2005:176-179.
[13] Terzopoulos G,Karatza H.Power-aware Load Balancing in Heterogeneous Clusters[C].Performance Evaluation of Computer and Telecommunication Systems(SPECTS).Toronto:IEEE,2013:148-154.
[14] Kindratenko V V,Enos J J,Guochun Shi,et al.GPU clusters for high-performance computing[C].Workshop on Parallel Programming on Accelerator Clusters(PPAC).New Orleans:IEEE,2009:1-8.
[15] Showerman M,Enos J,Steffen C,et al.A power-efficient GPU cluster architecture for scientificcomputing[J].Computing in Science Engineering,2011,13(2):83-87.
责任编辑:张新宝
2014-12-15
国家自然科学基金项目(编号:61100075、61272456);高等院校基本科研业务费项目(编号:K5051323005,BDY041409)
刘惠(1976-),女,副教授,博士,主要从事大数据、并行计算、移动计算等研究。E-mail:liuhui@xidian.edu.cn
1673-064X(2015)03-0105-06
TP393
A
猜你喜欢
小学教学研究(2022年5期)2022-04-28
军事运筹与系统工程(2019年4期)2019-09-11
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
商周刊(2019年1期)2019-01-31
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
中国洗涤用品工业(2017年2期)2017-04-16
知识就是力量(2017年2期)2017-01-21
通信电源技术(2016年6期)2016-04-20
