
一种新的基于MapReduce的并行关联规则算法
2015-05-10 07:42潘燕燕
重庆科技学院学报(自然科学版) 2015年3期
潘燕燕
(福建船政交通职业学院信息工程系,福州 350007)
关联规则挖掘是数据挖掘中的重要研究方法之一。关联规则是通过对数据库里面的数据进行分析,找出数据项之间的相关信息,它的核心是通过数据项统计计算频繁项目集。Apriori算法是传统的关联规则算法,缺点是要多次扫描数据库,同时产生的候选项很多。基于这些缺点已经有很多种改进算法,罗可等人[1]提出了一种基于2次扫描数据库的改进算法,陈自力[2]提出了一种基于幂集的改进算法,这些算法都是基于单机的。随着数据集的迅速增长,传统的算法已经无法满足数据增长的需要。
同时随着云计算的发展,MapReduce模型已经应用于关联规则挖掘,学者们提出了很多新的高效率的算法[3]。其中张圣[4]提出利用云计算来实现的关联规则 Apriori算法,提高了效率;陈方健等人[5]提出布尔矩阵的MapReduce并行化算法,将数据库转化为布尔矩阵进行分布式处理。本次研究笔者提出一种新的基于MapReduce的关联规则挖掘算法,该算法经过2次扫描数据库,就能得到相应的频繁集,从而提高挖掘效率。
1 Map Reduce编程模型
MapReduce编程模型是用来简化分布式系统的编程,主要处理大数据集[3]。MapReduce编程模型提供2个接口函数Map和Reduce,可以利用这2个函数实现对大量数据进行并行处理。MapReduce编程模型首先将大数据分割,分割好的数据块交给节点的Map函数进行处理,Map函数接收<key,value>形式的输入,得到中间 <key,list(value)>,Reduce函数接收中间值作为输入进行处理,得到新的<key,value>,最终得到结果。
2 基于Map Reduce的改进算法
2.1 Apriori的改进算法
Apriori算法是传统的关联规则挖掘算法。首先通过扫描一次数据库得到频繁1——项集L1,L1进行自连接得到候选集C2,再次扫描数据库得到L2,L2进行自连接得到C3,以此类推直到不再产生新的频繁项目集[6]。Apriori算法要多次扫描数据库,在时间和空间上面开销大。可以采用一种只要对数据库进行2次扫描,就得到所有的频繁项目集的方法[1]。首先扫描一次数据库,得到频繁1—— 项集L1,然后根据 L1产生所有的候选集(从2项到 k项),第二次扫描数据库,得到各项候选集的支持度,删除低于最小支持度的候选集,最终得到频繁项目集(从2项到k项)。
2.2 基于MapReduce的改进算法
MapReduce可以实现分布式处理大型数据,根据这个特点笔者提出一种新的基于MapReduce的关联规则挖掘算法。
基本思路:把事务数据库D分成独立的数据子集,交由集群中的节点处理。节点扫描一遍数据,得到局部候选1—— 项集C1,然后根据C1得到所有的局部候选集(从2项到k项),k≤数据子集中记录的最大项目数,设置k可以在一定程度上减少候选集的数量;第二次扫描数据库计算出所有局部候选集的支持度,最后发送给Reduce函数进行处理,最终得到全局频繁项目集。具体步骤如下所示。
(1)生成数据子集:就是利用MapReduce库将事务数据库分割,形成多个独立的子集合。
(2)Map函数的任务是对输入的<tid,list>数据进行扫描,list表示各个事务的数据项,tid表示事务编号,扫描得到局部候选集C1,生成<key1,value1>,这里记为 <itemSet1,1>,itemSet1表示 C1中的候选1项集,每个支持度为1。现在的事务数据库都很大,有可能产生很多相同的<itemSet1,1>,要对其进行合并,得到<itemSet1,n>。
(3)根据C1生成所有的候选集(从2项到k项),第二次扫描数据子集,得到 <key2,value2>,这里记为<itemSetk,n>,itemSetk表示候选k项集,n为itemSetk在数据子集的支持度,删除 n为0的记录。
Map函数伪代码如下:
input:<tid,list>
output:<itemSetk,n >
int maxLength=0,j=0
for each list do begin
for list里面的每个元素tido begin/*第一遍扫描数据库*/
emit(<itemSet1=ti,1 >)
j++
end
if(maxLength<j)
maxLength=j/*获得数据子集里面记录的最大长度*/
end
combine(ti,list(1))/*对相同的1项集进行合并*/
int n=0
for each list(1)do
n=n+1
end
C1=∪ti
emit(<itemSet1=ti,n>)/* 得到局部候选集C1*/
for(k=2;k≤maxLength;k++)/*maxLength为数据子集里记录的最大长度*/
get all<itemSetk,n=0>/*获得2项到K项的候选集,支持度初始为0*/
for each list do begin/*扫描数据子集获得item-Setk的支持度*/
for(k=2;k<=maxLength;k++)
if itemSetk∈list
n=n+1
end
(4)对于 <itemSetk,n >,利用哈希函数[7]进行分区,分配到P个不同的分区,在每个分区执行Reduce函数。

其中 r1,r2,r3,…,rk为 k项集里面的项在事务数据库项集中的序数。根据Apriori的假定,项集或者事务里的项是按照字典排序的。
(5)执行Reduce任务的站点,接收< itemSetk,n>数据,把同一个候选集的支持度相加起来,就得到候选k项集的全局支持度。经过和最小支持度进行比较,就可以得到全局的频繁项目集Lk(从1项到k项)。Reduce函数伪代码如下:
input:< itemSetk,n >
output:全局频繁项目集
compare itemSetkfor all < itemSetk,n>/* 按itemSetk分组*/
sum_n=count(itemSetk,n)/* 计算 itemSetk的支持度n之和*/
for(k=1;k<=maxLength;k++)
begin
if(sum_n>=min_sup)/*如果支持度之和大于最小支持度,将itemSetk放入到Lk中*/
insert(Lk,itemSetk)
end
return∪Lk
3 算法实现过程
假设有事务数据库S,如表1所示。

表1 事务数据库S
假设最小支持度为2,M=2,P=2。
(1)将数据库 S 分成2 个子集,S1(t1,t2,t3),S2(t4,t5,t6)。
(2)将子集S1,S2分别发送给2个站点,执行Map函数,得到 <key1,value1>。
站点1:
<t1,{A,B}>→ <{A},1 >,<{B},1 >;<t2,{A,D}>→(<{A},1>,<{D},1> ;
<t3,{A,B,D}>→ <{A},1>,<{B},1>,<{D},1>;
对数据进行合并得到<{A},3>,<{B},2>,<{D},2>。得到局部候选集{{A},{B},{D}}。
站点2:
<t4,{B,C}>→ <{B},1>,<{C},1>;<t5,{C,D}>→ <{C},1>,<{D},1> ;
<t6,{A,B,D}>→ <{A},1>,<{B},1>,<{D},1>;
同时对数据进行合并得到<{A},1>,<{B},2>,<{C},2>,<{D},2>。得到局部候选集{{A},{B},{C},{D}}。
(3)通过局部候选集生成所有的候选集(2项到k项),并扫描数据库,得到 < key2,value2>,这里记为 <itemSetk,n>,k≤数据记录的最大项目数。
站点1得到的所有候选集和支持度:
<{A,B},2 >,<{A,D},2 >,<{B,D},1 >,<{A,B,D},1 > ;
站点2得到的所有候选集和支持度:
<{A,B},2 >,< {A,C},0 > < {A,D},1 >,<{B,C},1 >,< {B,D},1 >,< {C,D},1 >,<{A,B,C},0 >,< {A,B,D},1 >,< {A,C,D},0>,<{B,C,D},0>;删除 n为0的记录。
(4)对<itemSetk,n>(包含候选1项集)利用哈希函数进行分区Hash(key)Mod 2,分成2个不同的分区。例如{A}分到1区,{B}分到0区。
Hash({A})Mod 2=1 Mod 2=1
Hash({B})Mod 2=0 Mod 2=0
分到站点1 的候选集有:{A},{C},{A,B},{A,D},{B,D};
分到站点 0的候选集有:{B},{D},{B,C},{C,D},{A,B,D}。
(5)进行Reduce任务对候选集的支持度进行累加。
站点1的候选集和相应支持度如表2所示。

表2 站点1的候选集和相应支持度
站点0的候选集和相应支持度如表3所示。根据最小支持度为2,站点0去掉{B,C},{C,

表3 站点0的候选集和相应支持度
D}2项。最后把2个站的满足最小支持度的项目集结合,得到最终的频繁项目集{{A},{B},{C},
{D},{A,B},{A,D},{B,D},{A,B,D}}。
4 实验分析
使用仿真实验检测算法性能,在局域网内配置8个站点的环境,每个站点的硬件配置一样,2 G内存,CPU是Intel i5系列;每个站点使用千兆以太网卡和交换机连接;操作系统采用Linux,Hadoop版本是2.2.0,Java 版本1.7。实验数据采用 IBM 数据生成器生成。根据新算法,编写Map函数和Reduce函数。
第一组实验分别用100 000,200 000和500 000条记录在8个站点的环境下进行测试。实验结果如表4所示。
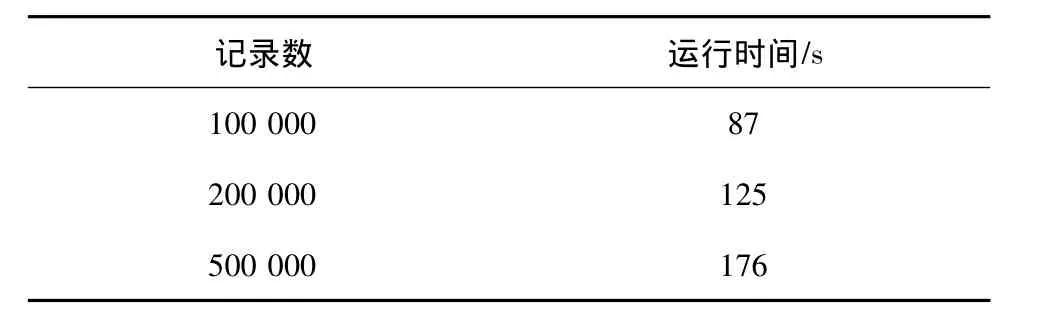
表4 不同记录数运行时间
第二组实验采用500 000记录,分别在2,4,6,8个站点下面进行测试。实验结果如表5所示。

表5 不同站点数运行时间
从表4可以看出,随着数据的增加,运行时间是线性增加的。从表5可以看出,随着节点数的增加,算法效率也随之提高。从2个站点到4个站点的运行时间迅速下降,当到8个站点的时候运行时间下降幅度减少。
5 结语
本次研究分析了传统的关联规则算法Apriori及其改进算法的优劣,使用 MapReduce模型对Apriori算法进行并行优化,提出一种新的基于MapReduce的关联规则挖掘算法,改进后的算法只需对数据库进行2次扫描。实验结果表明该算法能有效提高数据挖掘效率。
[1]罗可,吴杰.一种基于Apriori的改进算法[J].计算机工程与应用,2001(2):20-22.
[2]陈自力.一种新的基于幂集的数据挖掘算法[J].甘肃联合大学学报(自然科学版),2011,25(6):66-68.
[3]陈康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009(5):1337-1348.
[4]张圣.一种基于云计算的管理规则 Apriori算法[J].通信技术,2011,44(6):141-143.
[5]陈方健,张明新,杨昆.布尔矩阵Apriori算法的MapReduce并行化实现[J].常熟理工学院学报(自然科学版),2014,28(2):98-101.
[6]毛国君,段立娟,王室,等.数据挖掘原理与算法[M].北京:清华大学出版社,2005:64-72.
[7]李玲娟,张敏.云计算环境下关联规则挖掘算法的研究[J].计算机技术与发展,2011,21(2):43-46.
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
河南水利年鉴(2020年0期)2020-06-09
南京大学学报(数学半年刊)(2020年1期)2020-03-19
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
吉林大学学报(理学版)(2018年4期)2018-07-19
都市丽人(2015年4期)2015-03-20
中南民族大学学报(自然科学版)(2014年1期)2014-08-06
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
制造业自动化(2010年13期)2010-11-25
