
一种改进的基于社团发现的贝叶斯众包模型*
2015-05-29 08:23吴昌钱
湘潭大学自然科学学报 2015年4期
吴昌钱, 洪 欣
(1.泉州信息工程学院 计算机科学与技术系,福建 泉州362000;2.华侨大学 计算机科学与技术学院,福建 泉州362000)
众包是基于人工计算的智能计算的重要研究内容,目前已有的众包平台包括Turk,Crouw-Flower和Clickworker等.这些众包平台通过人工方式对图片或者文档等内容进行标记,然后利用标记的数据对机器学习的算法进行训练,从而进行图片或者文档的分类或者排名[1].对群体标签进行聚集的最简单的方法是采用多数投票等启发式方法,然而启发式方法没有对每个工人标记数据的可靠性进行差别对待.为了解决上述问题,研究人员在对群体标签进行聚集时考虑了每个工人的可靠性不同,提出了相应的概率模型.概率模型可以对每个工人的准确性进行建模,但是仍然忽略了工人的评价偏好或者倾向.对于每一个工人,对应着一个融合矩阵,该融合矩阵中的每一行表达了用户将某个真实标签标记为不同标签的概率.在众包中,工人的评价倾向可以通过融合矩阵得到,将融合矩阵融入到标签聚集过程的模型有[2],这些模型与启发式模型相比具有更高的准确性.基于融合矩阵的众包模型将每个工人的融合矩阵视为潜在变量,用融合矩阵作为用户的画像.
在基于融合矩阵的众包模型中,由于标签数量众多,使得融合矩阵非常大.同时,工人的标记往往服从幂率分布[3],即仅仅以小部分工人标记了大量数据,而大量的工人往往只标记了少量数据,这使得融合矩阵的数据是稀疏的.此外,众多的工人使得大量的融合矩阵计算耗时耗力.在基于融合矩阵的众包模型中,BCC(Bayesian Classification Combination)模型[2]是目前性能最好的模型,但是仍面临上述问题.
1 贝叶斯众包模型

在众包模型中,假设K个工人将N个对象划分为S个可能的类别.令ti为对象i的真实类别,用c,j≤S)表示工人k将真实类别为c的对象标记为j的概率,表示工人k对对象i进行的标记,C为所有观测到的标签集合.BCC模型[2]的因子图如图1所示,下面具体阐述该模型的含义.
BCC模型假设对象i的真实类别ti通过参数为p的分类分布中产生,即

其中p为所有对象中每个类别的比例向量,Cat(·)为分类分布.工人k对对象i进行的标记是通过参数为的分类分布产生的,即
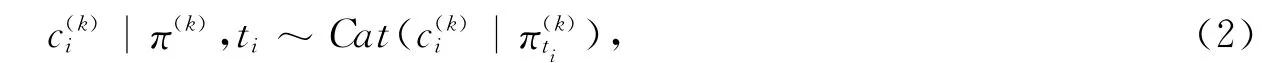


假设参数p和π符合共轭Dirichlet先验分布p~Dir(p|α)和,那么公式(4)可转化为如下公式:

2 基于社团的贝叶斯众包模型
2.1 模型的描述
本文通过引入工人社团对BCC模型[2]进行了扩展,基于社团的贝叶斯众包模型的因子图如图2所示.
本文将K个工人划分为M 个社团,每个社团m包含一个潜在的融合矩阵π(m).用m(k)表示工人k所属的社团,那么m(k)通过参数为h的分类分布中产生,即

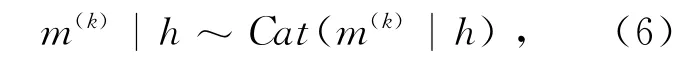
其中h为所有工人中每个社团的工人数量比例.对于社团m,其融合矩阵π(m)的第c行的对数概率向量为.对于所有的类别c,对应用sofamax操作符进行标准化得到相应的指数表达式,那么和满足如下关系:
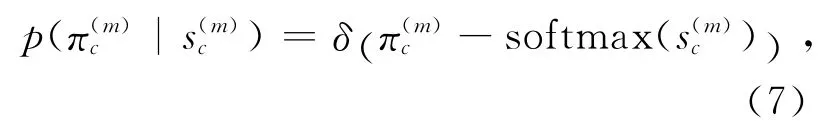
该模型与BCC模型的区别在于:BCC模型中,每个用户有一个融合矩阵,且不同用户的融合矩阵是相互独立的,而本文的社团模型强制每个社团中的用户的融合矩阵是相同的.当指定类别c时,用户k的评价向量s(k)c与k所属社团m(k)的评价值向量相关,其关系为多元高斯分布:

其中超参数ν为社团融合矩阵的等方逆方差.根据公式(8),可以从s(k)c推导出相应的标准化指数表达π(k)c,即
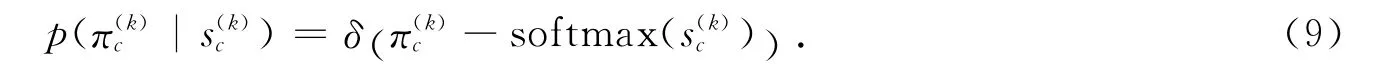
2.2 模型的推导
下面描述如何应用基于社团的贝叶斯模型进行众包模型的推导.假设所有工人对于所有对象的标签集合C是已知的,众包模型的目的是推导出模型中参数θ= {s(m),π(m),s(k),π(k),t,p}的后验分布.为了实现上述目的,本文在给定C的条件下,应用贝叶斯规则计算参数θ的联合后验分布:


在(11)中,参数h的先验分布为参数为α的Dirichlet分布,的先验分布为均值为μ逆方差为θ的多元高斯分布.如果假设C中的标签是独立产生的,那么公式(5)所示的参数的联合后验分布模型可改写为:

为了计算每个参数的近似间隔分布,本文应用[3]提出的消息传递算法.为了发现工人中的最优社团个数,本文应用最大间隔似然模型选择标准,该方法的描述公式如下:

对于(13)所示的最大间隔似然优化,可以在包含M个值的离散集合上采用简单的线搜索方法进行.
3 实验结果与分析
3.1 数据集与评价指标
本文采用两个公开的众包数据集CF①https://sites.google.com/site/crowdscale2013/shared-task.和ARJ[4].CF数据集是CrowdFlower在2013年开放任务挑战中的一部分.CF包含1 960个工人对98 980个问题的569 375个情感分析判断.其中问题通过Tweets的形式提出,工人对问题的判断反应了用户在讨论天气时的情感,判断的类别为5类.此外,该数据集包含了300个问题以及相应的1 720个正确的情感判断,这些正确的判断涉及461个用户.在ARJ数据集中,工人通过人工方式判断给定的查询/应答集合中是否涉及成人信息,判断结果为2分类.ARJ数据集包含了148个工人对307个问题的24 704个判断.
本实验通过准确性和NLPD两个指标对算法的性能进行评估.准确性为结果中正确结果的数量与所有正确结果的比例.NLPD(Negative Log Probability Density)考虑了预测标签的分布的不确定性,令qi= {qi,1,…,qi,j}为对象i的预测类别分布,那么 NLPD的计算公式如下:

3.2 对比算法
将本文提出的基于社团的贝叶斯众包模型记为CBCC,与如下算法进行实验对比:
(1)BCC(Bayesian Classifier Combination)[2]:BCC算法的具体描述见第2小节.
(2)EM(Expectation Maximization)[5]:EM 算法认为对象的标签与工人的融合矩阵是一个联合分布,通过期望最大化算法对预测值进行估计.
(3)MV(Majority Voting)[6]:MV方法是在群体中达成一致的一种启发式方法,认为每个对象的标签为所有工人的投票的加权和的最大值.MV方法的假设是所有的工人都是可靠的.
3.3 实验与结果分析
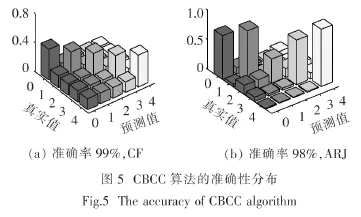
首先,实验通过CF和ARJ两个数据集对比了4种算法的准确性,实验结果分别如图3和4所示.图中的横轴为预测结果中返回的标记个数,纵轴为算法的准确性.在CF数据集中,当标记数量小于100时,BCC算法的准确性最低,EM和MV算法的准确性相近并且优于BCC算法,本文提出的CBCC算法的准确性是最高的;当标记数量大于100时,BCC算法的准确性优于EM和MV算法,但是仍低于CBCC算法.然后,实验分析了CBCC算法在返回的结果个数为900个的情况下的结果分布.从图5中可以看出,CBCC算法在CF算法下的准确率为99%,在ARJ算法下的准确率为98%.此外,在这两个数据集中,预测结果集中分布在对角线上,这表明大多数的预测是准确的,而错误预测的分布是比较均匀的.

最后,实验对比了4种算法在两个数据集下的准确性和NLPD,实验结果如表1所示.在准确性对比中,CBCC算法在两个数据集下的准确性都是最好的,而BCC算法次之.在NLPD的对比中,CBCC算法的值都是最小的,BCC算法次之.这表明CBCC算法的性能是最优的.
4 结束语
本文将所有的工人按照相似性划分为若干社团,每个社团中的所有工人采用相同的融合矩阵.在众包模型参数的计算中,采用贝叶斯后验分布方法进行推导,应用消息传递算法计算每个参数的近似间隔分布,并且应用最大间隔似然模型选择工人集合中的最优社团数量.实验表明,本文提出的基于社团的贝叶斯众包模型与其他相关研究相比在降低了算法的复杂度同时也提高了算法的准确性.

表1 算法在不同数据集下的性能对比Tab.1 performance comparison of different data sets
[1]丁宇,车万翔,刘挺,等.基于众包的词汇联想网络的获取和分析[J].中文信息学报,2013,27(3):100-106.
[2]KIM H C,GHAHRAMANI Z.Bayesian classifier combination[C]//International Conference on Artificial Intelligence and Statistics,2012:619-627.
[3]WELINDER P,BRANSON S,PERONA P,et al.The multidimensional wisdom of crowds[C]//Advances in Neural Information Processing Systems,2010:2 424-2 432.
[4]KRISTAN J,SUFFOLETTO B.Using online crowdsourcing to understand young adult attitudes toward expert-authored messages aimed at reducing hazardous alcohol consumption and to collect peer-authored messages[J].Translational Behavioral Medicine,2013,11(2):1-8.
[5]GAO X A,BACHRACH Y,KEY P,et al.Quality expectation-variance tradeoffs in crowdsourcing contests[C].AAAI,2012:38-44.
[6]TRAN-THANH L,VENANZI M,ROGERS A,et al.Efficient budget allocation with accuracy guarantees for crowdsourcing classification tasks[C]//Proceedings of the 2013International Conference on Autonomous Agents and Multi-Agent Systems,2013:901-908.
[7]周俊梅,蒋文江.基于单方程计量经济模型的贝叶斯分析[J].湘潭大学自然科学学版,2013,35(2):119-122.
猜你喜欢
建材发展导向(2021年10期)2021-07-16
法律方法(2021年4期)2021-03-16
新世纪智能(语文备考)(2021年11期)2021-03-08
中国公路(2017年11期)2017-07-31
铁道通信信号(2016年6期)2016-06-01
电子制作(2016年21期)2016-05-17
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
中国火炬(2015年11期)2015-07-31
中国火炬(2014年3期)2014-07-24
郑州大学学报(理学版)(2014年2期)2014-03-01
