
片上光电互连的多核系统仿真方法
2015-07-11 10:09于绩洋华幸成杨建义
浙江大学学报(工学版) 2015年11期
于绩洋,刘 鹏,华幸成,马 骧,杨建义
(浙江大学 信息与电子工程学院,浙江 杭州310027)
随着多核(Multicore)系统处理器数量的增加,网络与互连结构变得越来越重要;对于未来片上多核处理器结构如何选择设计片上网络目前还是未解决的问题.
在多核互连结构中,随着节点数量的增加,传统电互连技术逐渐显示出带宽不足、功耗过大等问题.相比之下,光互连技术具有时延低、传输带宽大、功耗开销少等优点.如何在成熟的电互连技术基础上,配合光互连结构,实现可扩展的片上光电互连拓扑结构,发挥光器件与电器件各自的优势,提高吞吐率,有着重要的研究意义.
在研究片上互连结构时,通常有2种方式,硬件模拟与软件仿真.传统的硬件仿真设计方法,存在着开发周期长、实现成本高、灵活性不够等方面的不足.而软件模拟的方法灵活性好,可以在设计初期对某个结构进行快速评估.在面向多核互连的系统设计时,用软件模拟对系统性能进行快速评估,成为一种有效的解决方案.
目前比较成熟的软件模拟方法已经可以对片上多核网络系统进行较为准确的评估,但是由于光子和电子不同的物理性质,已有的典型网络仿真无法准确的得到片上光电互连的性能特点.例如Chan等[1]提出的PhoenixSim 工具基于器件的物理层特性,提供了硅光器件参数化模型;但PhoenixSim 只对硅光器件建模,忽略了光电转换模块,未对频率响应特性进行建模.Sun等[2]提出的DSENT 工具可以依据光电技术参数,构建片上网络单元的框架结构,实现对光电片上互连网络的面积和功率评估;但是DSENT 不支持处理器的系统仿真,缺少存储器功耗模型.Miller等[3]提出的Graphite工具实现了光电互连的系统级仿真,但由于采用了松同步机制,不能做到周期级的精确仿真,限制了在体系结构探索研究方面的作用.
本文提出了一种面向光电互连系统的仿真方法,通过对光电器件的独立精确建模,使得器件库与功能模型、时序模型和成本模型协同工作;增加对多线程编程的支持,扩展了仿真规模,实现16 至256核光电互连系统的周期级精确仿真.
1 相关工作
学术界对片上互连网络的建模已进行了深入研究,提出了不同的片上网络的时序、功耗和面积模型,开发了模拟仿真工具.Chien等[4]提出了路由元件的时间和面积模型,将该模型曲线匹配到一个特定的过程,但没有证明这个模型随着工艺技术的规模变化是否能继续适用.Orion[5]为电网络中的路由和链路构件提供了参数化的功率和面积模型.但是Orion没有为路由和链接提供参数化的功率和面积模型,缺少路由元件的延迟模型.DSENT[2]在光电片上网络设计中,依据电光技术里的参数,构建片上网络构造单元的框架,可对光电片上联接做跨层次的面积和功率评估.但是DSENT 不支持处理器的系统仿真.
在光电互连仿真方面,PhoenixSim[1]用于协助研究者在考虑器件物理层特性的基础上探索硅光子片上网络.PhoenixSim 提供了光器件细致的参数化模型,并利用模块化、层次性强的NED 语言在基本元件的基础上形成高层网络元件甚至是整个网络.但是PhoenixSim 在处理网络能耗方面并没有把光和电结合起来,它依赖Orion处理所有电路由和链路的能耗,在光电接口电路(如调制器,接收器)中使用固定能耗,无法观测到由晶体管技术、数据速率和调谐情景变化带来的很多动态特性.Graphite[3]是一个并行化、分布式的多核模拟器.仿真模型包括功能模型和性能模型,支持程序级的仿真,对处理器、程序行为、线程、网络层进行建模,集成McPAT[6]和DSENT 接口,评估能耗和面积.Graphite利用C++类的继承调用,实现与光网络的连接,光器件作为网络层模型的子模型,从而实现从顶到底的系统设计空间探索平台.但是Graphite采用的是松同步(LaxP2P)机制,在并行仿真时,Graphite会将存储操作的顺序要求放宽至几千个机器周期,这样做提高了仿真速度,却损失了仿真精度,不能做到周期级精确的仿真.
在光电互连结构的探索方面,Briere等[7]开发出片上光网络的SystemC模型,用SystemC框架对片上光网络进行模拟,解决了设备调速和网络层面功耗的问题.Optisim[8]系统级模型器可对基于板和簇的计算系统中的光互连进行模拟.O'Connor等[9]为异质的光集成电路提出了一个链路层仿真环境.但这些研究工作对于底层细节的仿真不足,无法评估光电互连对于体系结构层次上的影响.Corona[10]采用的是光总线结构,该结构基于光波导的波分复用特性,无需路由无需交换,是一种共享传输通道的结构;ATAC[11]结构也是基于光总线的分层网络;这2项研究工作对光电互连网络进行了结构上的探索.
本文结合光电器件库的精确建模,构造了面向多核的片上光电互连系统的仿真框架;仿真模型包括功能模型、时序模型和成本模型,实现了多核光电互连系统的周期级精确仿真;利用多线程技术对构造的仿真框架进行规模扩展,支持16至256核系统的仿真,探索了多核光电互连系统设计空间,并采用系统仿真框架对ATAC和Corona拓扑结构进行性能评估.
2 系统仿真概述
与硬件设计相比,采用软件的方法对目标结构进行系统建模,具有开发周期短、容易修改、灵活性性高等优点,更适合在较短时间内对大量设计方案进行评估.因此研究人员中通常会借助软件手段对目标系统进行建模,以观察目标应用在模拟环境中执行时的行为特征,并对其硬件设计的正确性和性能进行评估.
模型的思想是用软件模拟器进行体系结构设计的关键,本文对多核互连系统进行了3个方面的建模,以验证目标设计的正确性,并对目标结构进行性能、功耗和面积等评估,如图1所示.
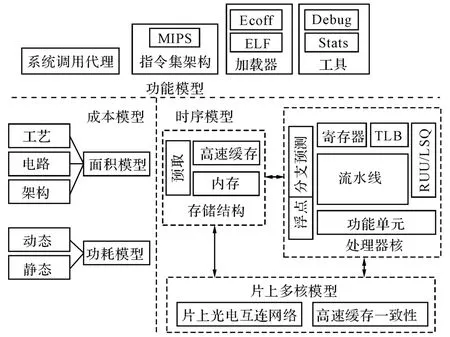
图1 功能模型、时序模型与成本模型Fig.1 Functional model,timing model,and cost model
功能模型主要实现了对目标可执行文件(MIPS体系结构)的加载,对目标指令集的解释执行,以及对MIPS/Linux标准系统调用的代理.
时序模型的功能包括:1)处理器的执行时序特点,如指令调度、指令乱序执行、分支预测等特性,以及流水线中的取指、分发、发射、执行、写回和提交过程;2)存储层次结构,包含片上高速缓存(Cache)和片外存储器模型;3)互连模型,支持片上光电互连网络和高速缓存一致性协议.
成本模型的功能是评估系统的功耗以及面积开销.功耗开销包括动态功耗和静态功耗;面积开销的评估考虑了工艺技术、电路结构和体系架构3个层面.
本文按照层次化、软硬件协同设计与仿真的策略,对多核系统进行了3个方面的建模.这3个模型在功能上相互独立,但又有着内在的联系:功能模型负责系统级建模,使得可执行应用程序与硬件仿真器相兼容;时序模型描述了片上多核系统的执行细节,使得模拟器在目标体系结构建模上与硬件设计保持一致;成本模型通过功耗、面积的准确建模,能够有效地评估设计方案.
3 系统实现
3.1 模拟器
本文在模拟器基础框架的选择和设计过程中,充分考虑了模拟器在精度和速度上的需求,选择了SimpleScalar[12]模拟器工具集为基础框架,对基于SimpleScalar的多核软模拟器[13]进行修改,使其支持MIPS体系结构[14]的建模.在Cache模型方面,采用了基于目录的一致性协议(modified,exclusive,shared,and invalid,MESI)来满足多核共享Cache的一致性需求.在互连方面,用Popnet[15]实现底层结构的片上网络模型,并模拟了核间对有限网络资源的竞争.对于应用程序多线程模型的支持则是通过一组多线程函数库完成,支持对线程的创建、管理、同步和通信.本文使用McPAT[6]作为该多核模拟器的功耗评估工具.网络评估方面,Popnet[15]的作用是为模拟器提供数据传输服务,模拟器自身的消息产生机制及工作过程对Popnet透明,Popnet仅负责提供可靠的数据传输服务.如图2所示为其工作流程.
Popnet与处理器核模拟器通过接口函数相互协作,其工作过程主要有以下几个步骤.1)当访问Cache或进行目录操作时,会产生目录事件.把这些目录事件放入目录队列,同时判断数据包的源节点注入端口的状态,并同时获取注入的虚通道标号.2)处理器核模拟器将数据包注入到Popnet网络中,数据包中包含数据包编号、消息类型、时间信息、地址信息和数据信息等.3)消息会在Popnet网络中传输,传输过程由Popnet完全控制.4)当目的地址的路由器收到数据包后,将目录队列中的事件与该数据包的信息进行对比.5)如果队列中有一个事件与该数据包匹配,则将该事件取出队列放入目录先进先出队列.6)最后网络节点会检查目录先进先出队列.当数据包成功到达目的节点后,Popnet通知模拟器此消息已成功传输.当有数据包产生并被注入到Popnet 中之后,Popnet 会根据数据包的类型(META 型或DATA 型)以及源节点、目标节点的位置,自动安排合适的路由以及相应的光电链路,完成数据包的传输.
3.2 多线程编程
为了方便用户编程,软件模拟器需要提供一套应用程序接口(API),以及部分操作系统的功能(如系统调用),对应用程序提供支持[16].由于不同的多核体系结构(如分布式和共享式)所适用的同步方式、通信模式等不同,需要模拟器提供合适的编程模型,配合物理层硬件结构,使应用程序能够高效地执行.
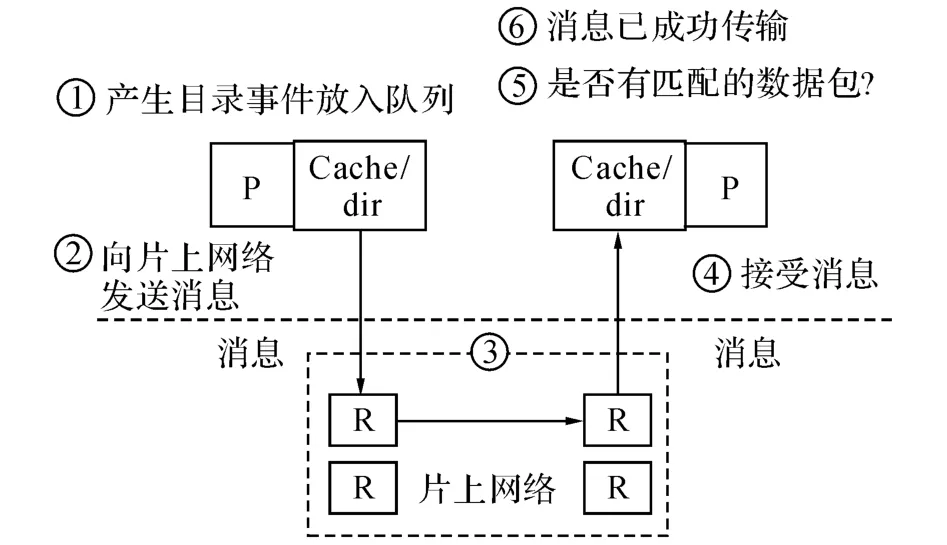
图2 消息传递流程Fig.2 Message passing process
本文设计了一套完整的接口函数,提供对物理层硬件的操作支持;同时采用用户级虚拟化技术,提供多线程编程和系统调用功能的支持.在编程模型方面,本文构造了一套兼容Pthread[17]的应用程序接口.该接口运行于模拟器上,隐藏并行处理器的细节,利用多线程模型进行任务调度,提供给程序员并行表达的方法,是底层体系结构与上层应用程序之间的桥梁.程序员可以利用该应用程序接口中定义的一系列方法,实现创建线程、部署屏障、加解锁互斥量和回收线程等功能,从而实现多线程的任务调度与同步.该应用程序接口中主要的函数名称及其功能描述如表1所示.

表1 主要接口函数Tab.1 API functions
一般来说,应用程序编程需要符合如图3所示的格式.其中计算内核段(Compute kernel)是应用程序的主体计算部分,可以包含互斥锁.在临界区(Critical section)既可以改变局部变量,又可以操作全局变量.编程时,可以将所需执行的代码直接替换到计算内核段.
3.3 器件库

图3 编程示例Fig.3 Example of programming in API functions
片上光电互连网络的构建主要有光器件和电器件2方面,一般来说,建立硅光链路通常包括:1)激光器,用于产生光信号;2)微环谐振腔,常见于调制器、滤波器和光开关之中;3)光波导,用于传输光信号;4)光接收器,即光探测器,用于接收光信号并转换成电信号.
光器件模型仅提供功耗计算方法,不对网络功能实现提供服务.为了使光学器件库具有良好的结构和清晰的派生、继承关系,在LioeSim[18]中提出了的器件建模方法,对光学器件进行分类,并依据光学器件之间关系,规划了光学器件库的代码类.本文采用LioeSim 的器件建模方法,通过分析目标器件的工作原理及其功能特性,明确模型所要输出的各类特征值(例如功耗、面积、损耗等),以及与之相关的工艺参数.如表2所示列举了光学器件库中主要器件类的工艺参数选择以及建模的主要内容[19-21].
3.4 分簇方法
在光电互连的片上系统中,通常会将若干个处理器划分为一个簇,簇内节点之间仍旧采用传统的电互连方式,而簇与簇之间通过环形光网络相连,这样既可以发挥光互连时延低、带宽大、功耗小的优点,又保留了原先电互连的可扩展性.光电互连系统的分簇方法如图4所示,每个簇内有一个中心路由器,当消息的源节点和目的节点在同一个簇内时,消息直接通过簇内的电网络传递;当消息需要从一个簇传到另一个簇时,该消息首先通过电网络传输到中心路由器,再通过光网络传输到另一簇的中心路由器,最后再通过电网络抵达目的节点.

表2 光学器件库建模Tab.2 Modeling for optical devices

图4 分簇方法示意图Fig.4 Clustering method
3.5 功耗计算模型
器件的功耗是一个与运行相关的参数,在不同的负载情况下,光电互连网络的功耗会有所区别,功耗的计算需要器件库与片上网络模拟器(Popnet)交互完成.本文保留了Popnet电功耗计算的功能,同时增加了光器件功耗的计算.对分簇后的电功耗进行重新规划和计算,增加了对中心路由器的电功耗计算;将模拟器的工作频率目标结构的工作频率进行了统一,并建立了光传输带宽、电传输带宽、电光调制器速率与波分复用(wavelength division multiplexing,WDM)通道个数之间的关系.
光器件库提供功耗计算方法,并不对网络功能实现提供服务.如图5所示为功耗计算的模型.在仿真过程中,网络模拟器会根据光电互连网络的运行情况,统计各类器件的使用频率与次数,并将统计结果作为参数传递给器件库;器件库模型会根据这个参数,结合器件的工艺参数,计算出动态功耗;同时,器件库还会根据全局配置参数(如时钟频率、温度等)计算各类器件的静态功耗.最后器件库将这2部分功耗反馈给网络模拟器,完成功耗计算的整个流程.
3.6 仿真规模扩展
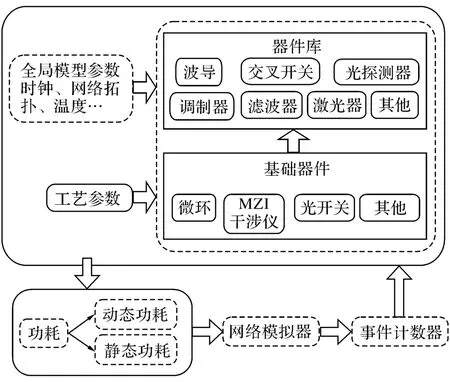
图5 功耗计算模型Fig.5 Power consumption calculation model
为了扩展系统仿真规模,本文利用多线程机制,将每个簇内的仿真交给一个线程来处理.模拟器在完成初始化工作以及相应的快速执行模式之后,进入多线程并行执行.对于每一个目标机器周期,各个时序仿真线程(线程_00,线程_01,…线程_15)并行运行,每个线程对应一个分簇内的处理器核(例如256核16分簇的情况,共有16个线程,每个线程对应16个核).完成一个目标机器周期的时序仿真之后,各线程会进行一次同步,等待片上网络线程完成消息处理.然后由片上网络线程通知各个时序仿真线程,开始下一个机器周期的仿真.如图6所示为该过程的示意图,仿真过程中采用了周期同步机制(即每一个机器周期都进行了同步),因此可以做到周期级的精确仿真.

图6 多线程运行示意图Fig.6 Multi-thread operation
3.7 仿真流程
应用程序在模拟器上运行通常会有以下的流程:1)准备阶段.模拟器读取系统配置文件,对处理器核、存储系统、片上网络等进行配置;读取程序的可执行文件及运行参数.2)快速执行阶段.该阶段的主要功能是完成评测程序自身的一些初始化工作.3)时序仿真阶段.应用程序开始并行运行,这个阶段的模拟是周期精确的,即每个周期内处理器以及片上网络所进行的操作、行为都会被模拟.4)性能统计.当应用程序运行完毕或者仿真到达指定的指令数后,进入性能统计阶段,对运行时的功耗、面积、时延等参数进行统计.
4 实验
4.1 实验方法
基于本文构造的方法进行多核系统仿真,目标系统包含256个MIPS32[14]处理器,频率为1GHz,采用45nm COMS工艺,处理器与总线频率比为5∶1,存储系统的最小访问延迟为105个处理器核周期,多核系统的配置如表3所示.
由于在多核系统中除了处理器节点之外,还需要存储控制器,因此对于256核的系统来说,实际配置的Mesh网络是18×18的规模.Popnet的初始配置参数以及光学器件的主要参数分别如表4和表5所示.本文针对256节点下的不同分簇大小的普通光电互连网络、ATAC[22]结构以及Corona[10]结构进行了仿真对比,并选取了SPLASH-2[23]以及PARSEC[24]中的部分程序作为评测程序,如表6所示.
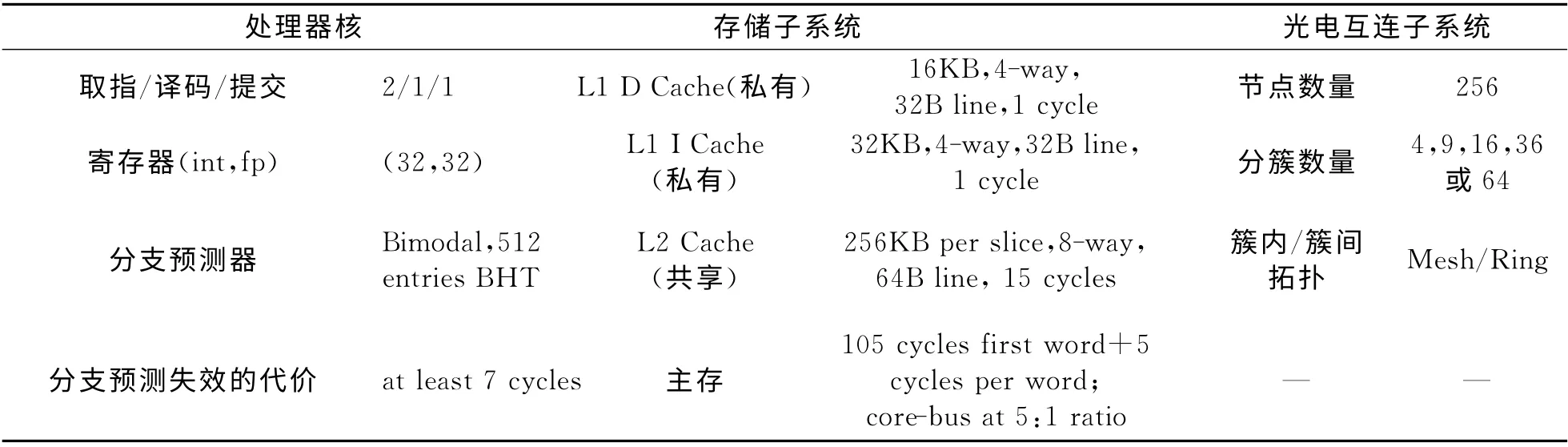
表3 多核系统配置表Tab.3 System configuration

表4 Popnet参数配置Tab.4 Popnet configuration

表6评测程序Tab.6 Benchmarks

表5 光学器件参数Tab.5 Parameters for optical devices
4.2 实验结果分析
4.2.1 分簇大小对网络性能的影响 对于3.4节所述的光电互连网络来说,当分簇的规模比较小,即簇内节点数量较少时,簇内电网络的负载会降低,而簇间光网络会变得更为繁忙;反之,当分簇的规模较大,即簇内节点数量较多时,节点间的通信主要集中在簇内的电网络上,而簇间的光网络会变得相对空闲.为了探究不同分簇对光电互连网络性能的影响,本文将256个节点的系统分别划分为4、9、16、36和64个簇等若干种情况,并对其进行了性能评估.
各种分簇情况下的网络平均时延如图7所示,网络时延N 是指一个数据包从源节点产生开始,通过网络传输到达目的节点的过程中,所使用的时间,由时钟周期的个数表示.平均时延越小,说明数据包在网络上传输得越快.由图7可见,随着分簇个数的增加,网络的平均时延明显减小.这是由于分簇越多,簇内的电网络规模越小,簇间的光网络承担更多传输任务,光网络高带宽、低时延的特性,提升了网络传输速率.
网络的电功耗P1以及光功耗P2分别如图8和9所示.分簇后,网络的电功耗会降低,同时会消耗一部分光功耗.与其他分簇结构相比,64 分簇的电功耗较大,这是由于64 分簇的网络平均时延较小,完成相同的任务所需的时间变短了,因此系统功率会上升.在4分簇和9分簇的网络中,光功耗相较于电功耗非常低,而36和64分簇网络中,光功耗则相对较大,这是由于光网络采用广播形式,光源的输出功率与光网络节点数成平方关系.在评测程序中,cholesky评测所产生的电功耗和光功耗都比较大,这是由程序的行为特性导致的,该评测程序节点之间的数据交换非常频繁,使得光电网络占用率提升,导致功耗增大.相比电器件功耗,光器件的功耗比较小.因此,利用光互连功耗低的特性,可以节省系统的总体功耗.
如图10所示显示了网络中消息传递的平均跳数H,由图可见,分簇越多,消息的平均跳数越小.这是因为分簇越多每个簇的规模就越小,出簇的数据包所占的比例会增大;由于出簇的数据包都是经过光网络传输,且只需要一个机器周期就能送达目的节点所在的分簇,因此分簇越多,相应的平均跳数越小.
从前面的时延和功耗分析可以看出,在提高网络传输速率的同时,通常会带来能耗的上升.为了衡量网络传输的效能,本文对光电互连网络的能量时延积EDP(Energy-delay product)进行了评估,如图11所示.EDP越小,说明网络的效能越高.可见,对于256核光电互连网络,采用36分簇时所获得的效能最好,9 分簇的平均效能与不分簇的情况(EMesh)较为接近,4分簇的网络效能较差.
4.2.2 几种典型网络结构的对比 为了对比相同分簇条件下不同网络结构对网络性能的影响,本文在256节点16分簇和64分簇2种情形下,实现了ATAC[22]网络结构和一种类似于Corona[10]总线机制的crossbar结构.
ATAC的簇内电网络分为EMesh 和BNet 2部分.其中BNet为簇内广播网络,用于从中心节点下行到簇内其余节点.BNet采用奇偶2个小型子网实现,将数据包按照簇内目的地址分为奇偶2组,并使用相对应的BNet网络进行广播.EMesh网络为簇内的电Mesh网络,用于簇内正常的消息传输,及簇内节点将数据包传输至中心节点.
Corona的总线机制可简要描述为竞争机制,即接收端使用固定的波长,发送端通过总线传输数据包时,需要将电信号调制成指定接收端的固定波长的光信号.Corona的竞争机制采用异步、微环令牌的实现方法.本文对此结构进行了一定程度的化简,在原有的光网络基础上将广播机制更改为类似于Corona总线机制的crossbar网络结构,并引入竞争处理机制.
通过对比16分簇时3种不同互连结构(即普通分簇、ATAC以及Corona),可以分析不同结构对系统性能的影响.虽然ATAC 结构时延较普通的16分簇结构小(图7),Corona结构功耗较普通的16分簇结构小(图8、图9),但总的来说,ATAC 结构和Corona结构的效能只是略好于原来的16 分簇(图11).ATAC结构时延小但功耗大;Corona结构时延大但功耗小;普通16分簇结构的时延和功耗性能处于两者之间.这主要是因为,ATAC 结构是广播的,所以时延较小,功耗较大;而Corona结构引入了总线竞争,所以时延较大,而功耗较小.

图7 256核不同分簇的平均时延Fig.7 Average delay for 256-node system
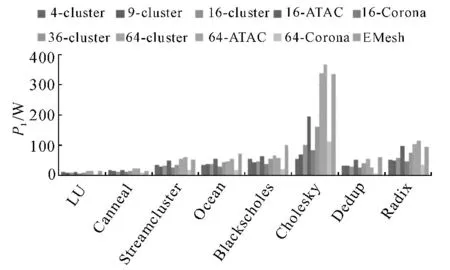
图8 256核不同网络结构的电功耗Fig.8 Electric Power for 256-node system
通过对比64分簇时的3种不同互连结构可以看出,64 分簇的ATAC 在平均时延上有比较明显的优势,同时带来的功耗增长并不显著;而64分簇的Corona可以同时降低电功耗和光功耗,减小了能量时延积.
总体来说,光电互连网络的平均时延会随着分簇个数的增加而减小,但是光电互连网络的效能并不随着分簇个数的增加而一直提高,当分簇个数过多时,网络功耗也会变得较大,引起效能的恶化.对256核来说,采用36分簇的光电互连网络所获得的平均效能最好.在分簇个数相同的条件下,ATAC结构的时延小但功耗大;Corona结构功耗小,但时延大;普通总线结构的时延和功耗性能处于两者之间,3种结构的平均效能差别不大.

图9 256核不同网络结构的光功耗(不包含光源的功耗)Fig.9 Optical power for 256-node system(laser power not included)

图10 256核不同网络结构中消息的平均跳数Fig.10 Average hop count for 256-node system
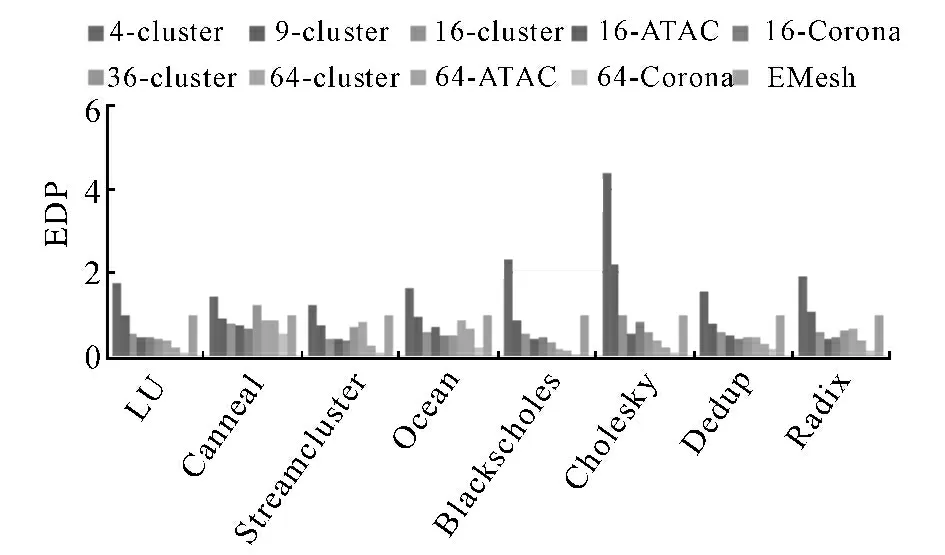
图11 256核不同分簇的能量时延积Fig.11 Energy-delay product for 256-node system
5 结 语
本文提出了一种面向多核的光电互连系统的仿真方法,对光电器件进行了物理层精确建模,实现器件库与功能模型、时序模型和成本模型协同工作;通过周期同步机制和多线程扩展机制,实现了16 至256核光电互连网络的周期级精确仿真.本文提出的光电互连系统仿真方法可探索不同的网络拓扑结构,并评估整体系统性能.
相比于传统的电互连网络,光电互连片上网络具有低功耗、高带宽等特点.如何利用光网络的特性提升片上网络的性能,如何改进存储一致性协议使之适应光电互连网络的特性,是未来研究的重要方向.
(
):
[1]CHAN J,HENDRY G,BIBERMAN A,et al.Phoenixsim:A simulator for physical-layer analysis of chipscale photonic interconnection networks[C]∥Proceedings of the Conference on Design,Automation and Test in Europe.Dresden,Germany:European Design and Automation Association,2010:691-696.
[2]SUN C,CHEN C-H,KURIAN G,et al.DSENT :a tool connecting emerging photonics with electronics for opto-electronic networks-on-chip modeling [C]∥Proceedings of the 6th IEEE/ACM International Symposium on Networks on Chip.Lyngby,Denmark:IEEE,2012:201-210.
[3]MILLER J E,KASTURE H,KURIAN G,et al.Graphite:A distributed parallel simulator for multicores[C]∥Proceedings of the16th International Symposium on High Performance Computer Architecture.Bangalore,India:IEEE,2010:1-12.
[4]CHIEN A A.A cost and speed model for k-ary n-cube wormhole routers[J].Urbana,1993,51:61801.
[5]KAHNG A B,LI B,PEH L-S,et al.Orion 2.0:A fast and accurate noc power and area model for earlystage design space exploration[C]∥Proceedings of the Conference on Design,Automation and Test in Europe.Nice,France:European Design and Automation Association,2009:423-428.
[6]LI S,AHN J H,STRONG R D,et al.McPAT:an integrated power,area,and timing modeling framework for multicore and manycore architectures[C]∥Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture.New York,United State:IEEE,2009:469-480.
[7]BRIERE M,DROUARD E,MIEYEVILLE F,et al.Heterogeneous modelling of an optical network-on-chip with SystemC[C]∥Proceedings of the 16th IEEE International Workshop on Rapid System Prototyping.Montreal,Canada:IEEE,2005:10-16.
[8]KODI A K,LOURI A.Optisim:A system simulation methodology for optically interconnected HPC systems[J].Micro,IEEE,2008,28(5):22-36.
[9]O'CONNOR I,TISSAFI-DRISSI F,GAFFIOT F,et al.Systematic simulation-based predictive synthesis of integrated optical interconnect[J].IEEE Transactions on Very Large Scale Integration(VLSI)Systems,2007,15(8):927-940.
[10]VANTREASE D,SCHREIBER R,MONCHIERO M,et al.Corona:System implications of emerging nanophotonic technology [J].ACM SIGARCH Computer Architecture News,2008,36(3):153-164.
[11]PSOTA J,MILLER J,KURIAN G,et al.ATAC:Improving performance and programmability with onchip optical networks[C]∥Proceedings of 2010IEEE International Symposium on Circuits and Systems.Paris,France:IEEE,2010:3325-3328.
[12]AUSTIN T,LARSON E,ERNST D.SimpleScalar:An infrastructure for computer system modeling[J].Computer,2002,35(2):59-67.
[13]XUE J,GARG A,CIFTCIOGLU B,et al.An intrachip free-space optical interconnect[C]∥Proceedings of the 37th Annual International Symposium on Computer Architecture.Saint-Malo,France:ACM,2010:94-105.
[14]TRAN C,ANYANWU C,BALAKRISHNAN S,et al.The MIPS32 24KE Core Family:High-Performance RISC Cores with DSP Enhancements[R].Sunnyvale,United States:M.Technologies,2005.
[15]SHANG L.POPNET simulator[EB/OL].[2015-08-31].http://www.sanjuansw.com/pub/SJS%20125-300-13%20PopNet2%20Data%20Sheet.pdf.
[16]YU J Y,LIU P,WANG W D,et al.An efficient protocol with synchronization accelerator for multi-processor embedded systems[J].Parallel Computing,2013,39(9):461-474.
[17]BUTENHOF D R.Programming with POSIX threads[M].Indianapolis,United State:Addison-Wesley Professional.1997:35-44.
[18]MA X,YU J,HUA X,et al.LioeSim:a network simulator for hybrid opto-electronic networks-on-chip analysis[J].Journal of Lightwave Technology,2014,32(22):3699-3708.
[19]BARWICZ T,BYUN H,GAN F,et al.Silicon photonics for compact,energy-efficient interconnects[J].Journal of Optical Networking,2007,6(1):63-73.
[20]LI Z,ZHOU L,HU Y,et al.CMOS compatible silicon-based Mach-Zehnder optical modulators with improved extinction ratio[C]∥Proceedings of the International Photonics and Optoelectronics Meetings.Wuhan:International Society for Optics and Photonics,2011:833305-833306.
[21]YANG M,GREEN W M,ASSEFA S,et al.Nonblocking 4x4 electro-optic silicon switch for on-chip photonic networks[J].Optics express,2011,19(1):47-54.
[22]KURIAN G,MILLER J E,PSOTA J,et al.ATAC:a 1000-core cache-coherent processor with on-chip optical network[C]∥Proceedings of the 19th International Conference on Parallel Architectures and Compilation Techniques.Vienna,Austria:ACM,2010:477-488.
[23]WOO S C,OHARA M,TORRIE E,et al.The SPLASH-2programs:Characterization and methodological considerations[C]∥Proceedings of the 22nd annual international symposium on Computer architecture.Santa Margherita Ligure,Italy:ACM,1995:24-36.
[24]BIENIA C,KUMAR S,SINGH J P,et al.The PARSEC benchmark suite:characterization and architectural implications[C]∥Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques.Toronto,Canada:ACM,2008:72-81.
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
小哥白尼(趣味科学)(2021年6期)2021-11-02
故事作文·高年级(2021年4期)2021-05-06
小哥白尼(神奇星球)(2021年11期)2021-03-08
民用飞机设计与研究(2020年4期)2021-01-21
物联网技术(2018年8期)2018-12-06
个人电脑(2016年12期)2017-02-13
电子制作(2016年19期)2016-08-24
空间控制技术与应用(2015年3期)2015-06-05
装备环境工程(2015年5期)2015-02-28
