
基于PAM和簇阈值的改进K-Means聚类算法
2015-12-09 11:33卜旭松刘立波
湖北工程学院学报 2015年3期
关键词:采样
卜旭松,刘立波,石 磊
(1.宁夏大学 数学与计算机学院,宁夏 银川 750021;2. 湖北工程学院 现代教育技术中心,湖北 孝感 432000)
基于PAM和簇阈值的改进K-Means聚类算法
卜旭松1,刘立波1,石磊2
(1.宁夏大学 数学与计算机学院,宁夏 银川 750021;2. 湖北工程学院 现代教育技术中心,湖北 孝感 432000)
摘要:为了弥补K-Means算法对孤立点数据敏感的缺陷,提高K-Means算法对包含孤立点数据集的聚类效果,在深入研究K-Means算法的基础上,提出了基于PAM和簇阈值的改进K-Means聚类算法。该算法首先对待聚类数据进行抽样,然后利用PAM算法获取样本数据的聚类中心,以样本数据的聚类中心作为K-Means算法的初始聚类中心。在聚类迭代过程中动态计算各簇阈值,利用簇阈值准确地过滤孤立点数据。实验结果表明,本文提出的算法不仅聚类时间短,而且具有较高的聚类准确率。
关键词:采样;K-Means聚类;聚类阈值;孤立点
中图分类号:TP18
文献标志码:码:A
文章编号:号:2095-4824(2015)03-0036-04
收稿日期:2015-03-03
作者简介:卜旭松(1988-),男,山东烟台人,宁夏大学数学与计算机学院硕士研究生。
Abstract:In order to overcome the weakness of K-Means algorithm which is sensitive to outliers, and to improve the quality of K-Means clustering algorithm, the paper makes an in-depth study on the traditional K-Means algorithm and proposes an improved clustering algorithm based on the PAM algorithm and the cluster threshold. The proposed method first samples the clustering data and then employs the PAM algorithm to obtain the clustering center of the sample data as the initial center of K-Means algorithm. By calculating the threshold for each cluster dynamically in the iterative process of clustering, the outliers can be excluded from the dataset. Experimental results indicate that the proposed algorithm have been shown lower computational cost and higher clustering accuracy.
刘立波(1974-),女,宁夏银川人,宁夏大学数学与计算机学院教授,博士后。
石磊(1986-),男,内蒙古兴安盟人,湖北工程学院现代教育中心实验师,硕士。
聚类是一种无监督的分类方法[1]。作为一种有效的数据挖掘技术,聚类分析可以发现数据的分布,观察每个簇的特征,便于将进一步分析集中在某个特定的集合上。目前,聚类分析已经广泛地应用于商务智能、图像模式识别、Web搜索[2]、市场营销、生物学[3]和安全等领域。
K-Means算法是一种基于划分的聚类方法,算法以簇内点的均值作为簇的聚类中心[4-7]。孤立点是显著偏离数据集中其他数据的点,不属于任何簇[8]。孤立点的存在,严重影响了簇均值,致使簇的聚类中心显著偏离数据的实际中心,影响了其他对象到簇的分配,导致算法准确率降低。基于密度[9-10]、区域划分[11]等初始聚类中心的优化算法尽管能为算法提供优质的初始聚类中心,但无法处理后继迭代过程中孤立点对簇中心重新计算引起的误差,最终影响聚类的准确性。文献[12]采用邻域密度方法对数据进行预处理,把指定邻域内包含其他对象数量少于Minpts的对象作为孤立点过滤掉。由于处理后的数据集不含孤立点数据,因此算法聚类准确率较高,但单独处理孤立点会增加算法的时间开销,严重影响算法整体执行效率。
本文从初始聚类中心选取和聚类规则两方面对传统K-Means算法进行改进。利用PAM算法获取样本数据的聚类中心作为K-Means算法初始聚类中心,利用阈值系数与簇边距乘积作为簇阈值。在聚类过程中同步过滤孤立点数据,避免单独处理孤立点数据增加额外的时间开销,使算法具有较高准确率的同时保持较高的执行效率。
1 相关理论及定义
1.1 相关定义
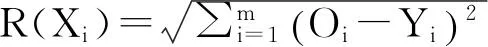
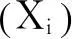
离簇Ci距离最近的簇Cj的质心。
定义3对于一个簇u,如果样本数据集s大小满足:

本文假设各簇数据量为uavg=N/K,N为数据集数据总量,则样本数据量Savg为:

1.2 PAM算法
PAM算法是一种基于代表对象的技术,算法不采用簇均值作为聚类中心,而是选择簇中实际对象作为聚类中心,因而不易受孤立点影响,对小规模数据集合非常有效,但缺点是算法时间复杂度高,当数据量较大时算法执行效率不高。研究表明,在样本数据合适、取样均匀的情况下,抽样数据可以较为真实地反映总体数据集的分布状况[14]。本文利用PAM算法对样本数据进行聚类,获取样本数据的聚类中心作为K-Means算法的初始聚类中心,以样本数据的簇边距作为K-Means算法初次迭代的簇阈值计算参数。PAM算法描述如下:
输入:结果簇的个数k;D:包含n个对象的数据集合。
步骤:
(1) 从D中随机选取k个对象作为初始的代表对象或种子;
(2)repeat;
(3) 将每个剩余的对象分配到最近的代表对象所代表的簇;
(4) 随机地选择一个非代表对象Orandom;
(5) 计算用Orandom代表对象的总代价S;
(6)ifS<0,then用Orandom替换Oj,形成k个新的代表对象集合;
(7) until聚类中心和簇边距不再发生变化。
1.3 簇阈值设置
传统的K-Means算法无法处理孤立点,对包含孤立点的数据集聚类准确率低。本文对K-Means算法的聚类准则进行改进,通过设置阈值方式过滤孤立点,算法以阈值系数ε和各簇的簇边距乘积作为各簇簇阈值。与全局阈值相比,局部簇阈值更能准确地反映各簇的区域范围,具有过滤孤立点数据的能力。由于K-Means算法初次迭代过程中无簇边距信息,利用PAM算法获取样本数据的簇边距与阈值系数ε乘积作为簇阈值,在后继迭代过程中使用上次迭代分配到该簇的对象重新计算簇边距并更新簇阈值,使簇阈值更加准确。使用簇阈值过滤孤立点的步骤如下:

(3) 若不满足步骤(2),则将点X划分到孤立点集中。
2 改进的K-Means算法
算法基本思想如下:依据定义3进行抽样,利用PAM算法获取样本数据的k个聚类中心。对于数据集中每个对象,计算其到各个簇中心的欧式距离dx,若该对象与某簇最相似且dx不大于该簇的簇阈值,则将该对象划分到该簇,否则将该数据对象划分到孤立点数据集。重新计算簇均值和簇阈值,重新分配所有对象,直到分配稳定。改进的K-Means聚类算法描述如下:
输入:ε阈值系数;聚类簇个数k;包含N个对象的数据集D。
输出:k个簇的集合;孤立点集I。
步骤:
(1) 依据定义3所述,从数据集D中抽取样本数据集S;
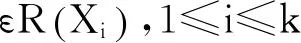
(3)repeat;
(4) 清空孤立点数据集I中的数据;
(7) until簇中心不再发生变化。
改进的K-Means算法流程如图1所示。
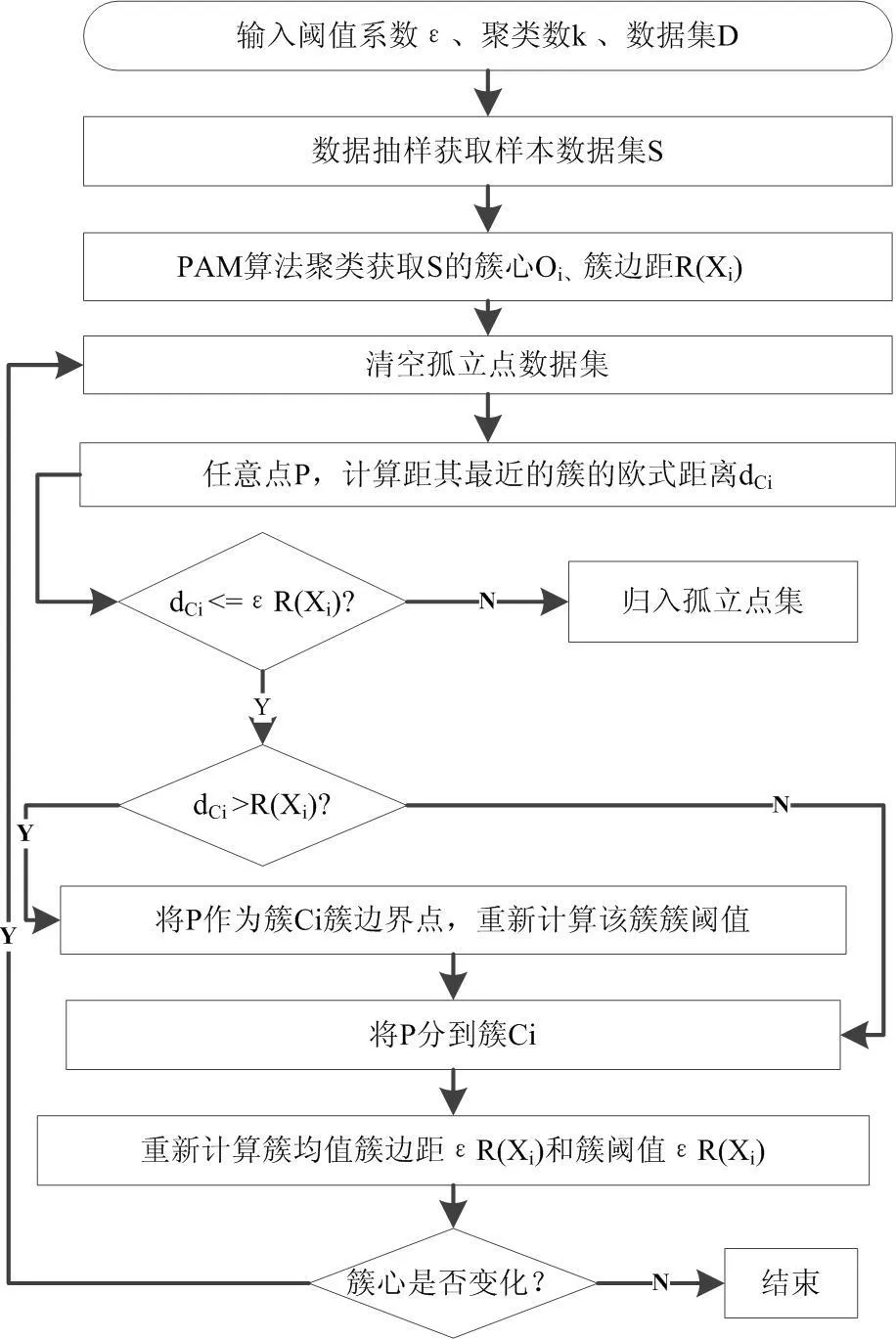
图1 改进K-Means算法流程图
3 实验仿真及分析
实验环境为 Intel(R) Core(TM)i3-3110M CPU @ 2.40GHz,内存 4 GB,Windows 7系统,实验工具为Matlab 7。实验数据为UCI数据库中iris和waveform数据集,各数据集属性见表1。为验证算法处理孤立点的效果,在两个数据集中添加孤立点数据,使孤立点数据比例达到整个数据集的5%。

表1 实验数据集属性
3.1 聚类中心选取验证
iris数据集实际聚类数据中心分别为setosa{5.00,3.41,1.46,0.24}、versicolor{5.93,2.77,4.26,1.32}、virginica{6.58,2.97,5.55,2.02}。依照定义3,利用PAM算法获取的样本数据的聚类中心别为setosa{5.0,3.4,1.5,0.2}、versicolor{5.9,3.0,4.2,1.5}、virginica{6.5,3.0,5.5,1.8}。本文改进的算法获取的聚类中心与iris数据实际聚类中心的误差平方和为0.049 1,说明提出的算法获取的聚类中心与iris数据集真实聚类中心非常接近,能有效代表数据的实际分布。因此,利用本文的算法获取的聚类中心作为K-Means算法初始聚类中心是可行且较优的。
3.2 准确率和效率比较
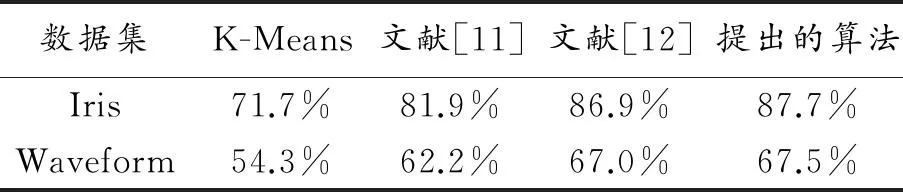
表2是本文提出的算法、传统K-Means算法、文献[11]和文献[12]在iris和waveform数据集上聚类准确率比较结果,其中本文提出的算法的参数设置如下:簇阈值系数 =1.5,聚类数k=3。由于本文提出的算法和文献[12]的方法不仅对初始聚类中心进行优化,而且对孤立点数据进行了处理,聚类准确率明显高于传统K-Means算法和仅对初始聚类中心进行优化的文献[11]的结果。但从图2可以看出,文献[12]需要对孤立点数据进行预处理,因此随着实验数据量的不断增加,算法执行所需要的时间增长趋势明显,呈幂指数增长。相比而言,本文提出的算法在聚类过程中同步处理孤立点数据,算法执行时间增长速度平稳,呈线性增长趋势。综上可知,本文算法在保持高准确率的同时能显著提高算法的执行效率。

图2 算法执行时间比较
4 结束语
数据集中存在的孤立点数据严重影响了K-Means算法聚类准确率。为了消除孤立点对聚类质量的影响,提高K-Means算法聚类效果,本文提出了一种基于PAM和簇阈值的改进K-Means算法。该算法利用PAM获取样本数据聚类中心作为K-Means算法的初始聚类中心,利用簇阈值方式过滤孤立点数据,消除了孤立点对聚类准确率的影响,具有较高的聚类准确率和执行效率。
[参考文献]
[1]赵卫中,马慧芳,李志清,等.一种结合主动学习的半监督文档聚类算法[J].软件学报,2012,23(6):1486-1499.
[2]Lingras P,West C.Interval set clustering of web users with rough K-Means[J].Journals of Intelligent Information Systems,2004,23(1):5-16.
[3]Redmond S J,Heneghan C.A method for initialising the K-Means clustering algorithm using kd-trees[J].Pattern Recognition Letters,2007,28(8):965-973.
[4]Li M J,Ng M K, Cheung Y M.Agglomerative fuzzy K-Means clustering algorithm with selection of number of clusters[J].IEEE Transactions on Knowledge and Data Engineering,2008,20(11):1519-1534.
[5]Zhang Y,Zhou H,Qin S.Decentralized fault diagnosis of large-scale processes using multiblock kernel principal component analysis[J].Acta Automatic Sinica,2010,36(4):593-597.
[6]Likas A,Vlassis M,Verbeek J.The global K-Means clustering algorithm[J].Pattern Recognition,2003,36 (2):451-461.
[7]Seinley D,Brusco M J.Initializing K-Means batch clustering:a critical evaluation of several techniques[J].Journal of Classification,2007,24(1):99-121.
[8]侯晓晶,王会青.基于最近邻距离差的改进孤立点检测算法[J].计算机工程与设计,2013,34(4):1265-1269
[9]郑丹,王潜平.K-Means初始聚类中心的选择算法[J].计算机应用,2012,32 (8):2186-2188,2192.
[10]周董,刘鹏.VDBSCAN:变密度聚类算法[J].计算机工程与应用,2009,45(11):137-153.
[11]苏锦旗,薛惠锋,詹海亮.基于划分的K-均值初始聚类中心优化算法[J].微电子学与计算机,2009,26(1):8-11.
[12]王赛芳,戴芳.基于初始聚类中心优化的K-均值算法[J].计算机工程与科学,2010,44(23):166-168.
[13]雷小锋,谢昆青,林帆,等.一种基于K-Means局部最优性的高效聚类算法[J].软件学报,2008,19(7):1683-1692.
[14]毕方明,王为奎,陈龙.基于空间密度的群以噪声发现聚类算法研究[J].南京大学学报:自然科学版,2012,48(4):491-498.
An Improved K-Means Algorithm Based on PAM Algorithm and Cluster Threshold
Bu Xusong1,Liu Libo1, Shi Lei2
(1.SchoolofMathematicsandComputer,NingxiaUniversity,Yinchuan,Ningxia750021,China;
2.TechniqueCenterofModernEducation,HubeiEngineeringUniversity,Xiaogan,Hubei432000,China)
Key Words:sampling;K-Means cluster; cluster threshold; outlier
(责任编辑:张凯兵)
猜你喜欢
中国科技纵横(2017年10期)2017-06-30
环球人文地理·评论版(2017年3期)2017-06-14
中国新技术新产品(2017年12期)2017-06-08
电子技术与软件工程(2017年8期)2017-05-10
祖国(2017年5期)2017-03-22
湖北畜牧兽医(2016年10期)2017-03-20
环球人文地理·评论版(2016年9期)2017-03-15
科技视界(2016年22期)2016-10-18
中国高新技术企业(2015年22期)2015-06-15
物联网技术(2014年7期)2014-09-24
