
一种基于加权海明距离的自适应遗传算法
2015-12-14 06:10徐承爱
华南师范大学学报(自然科学版) 2015年6期
徐承爱,林 伟 ,肖 红
(广东工业大学计算机学院,广州510006)
遗传算法(Genetic Algorithms,GA)是一种模仿自然界生物进化机制的随机全局搜索和优化方法.它借鉴了达尔文的进化论和孟德尔的遗传学说,能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最优解.广泛应用于组合优化、模式识别、自动控制、图像处理和人工生命等众多领域[1].
标准遗传算法通过选择、交叉和变异等3 种基本操作算子实现种群的进化,搜索问题最优解,但其存在着早熟收敛和搜索效率低等问题. Srinivas 和Patnaik[2]提出基于个体适应度的遗传算法,使得交叉率和变异率随着种群的进化而自适应改变;任子武和伞冶[3]在Srinivas 的基础上提出一种改进的自适应遗传算法,该算法使群体中最大适应度的个体交叉率和变异率不为零,有效跳出局部最优解;王杰等[4]提出一种双变异率的改进遗传算法,并使用海明距离控制交叉操作,提高了群体的多样性;田丰等[5]提出一种基于个体相似度的双种群遗传算法,加入内部竞争和种群交流策略,有效抑制早熟现象.研究发现,上述改进算法的全局搜索能力和效率有了一定的提高,但早熟收敛和效率低等问题仍然严峻.针对该问题,本文从交叉率和变异率自适应调整入手,提出一种基于加权海明距离的自适应遗传算法(HAGA),运用6个经典测试函数对算法进行了仿真实验.结果表明,该算法可以显著提高遗传优化的全局搜索能力,加快遗传算法的收敛速度.
1 传统自适应遗传算法
遗传算法参数中交叉率Pc和变异率Pm的选择是影响算法性能的关键.交叉率Pc越大,新个体产生的速度就越快,然而Pc过大时遗传模式被破坏的可能性增加;Pc过小,使得搜索过程缓慢.对于变异概率Pm,Pm过小,不容易产生新的个体模式;Pm取值过大,GA 就变成了纯粹的随机搜索算法[1].针对不同的优化问题,需通过反复实验来确定Pc和Pm,很难找到适应于每个问题的最佳值. 自适应遗传算法(AGA)[2]中Pc和Pm能够随适应度函数大小自适应调整,在保持群体多样性的同时保证遗传算法的收敛性.该算法中Pc和Pm调整公式如下:
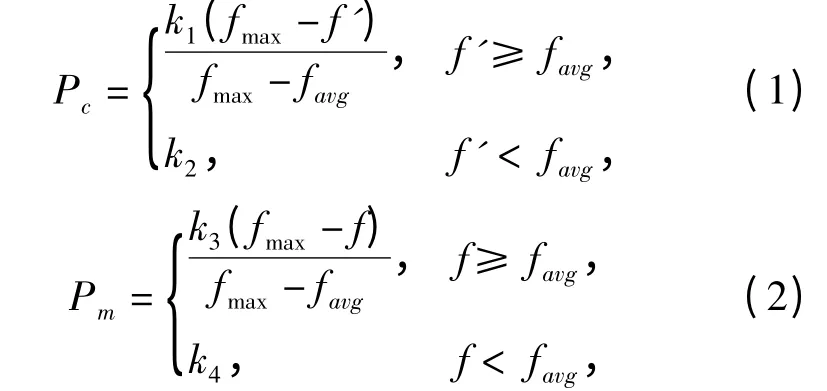
其中,fmax为群体中最大的适应度值,favg为每代群体的平均适应度值,f'为要交叉的2个个体中较大的适应度值,f 为要变异个体的适应度值. k1,k2,k3,k4为(0,1)区间常数. 这种调整方法对于群体处于进化后期比较合适,但对于进化初期不利.由于在进化初期,群体中的较优个体几乎处于一种不发生变化的状态,而此时的优良个体不一定是优化的全局最优解,容易使算法陷入早熟收敛.
2 基于加权海明距离的自适应遗传算法
2.1 加权海明距离
度量个体相似度的传统方法主要有海明距离和加权海明距离.海明距离指2 条染色体间相同基因座上不同基因的数量;而加权海明距离指按照基因座位置和作用不同在海明距离基础上添加合适的权值,然后对不同基因的权值进行求和计算[6]. 采用海明距离度量父个体的相似度[7-8],虽然对群体的多样性判断有一定贡献,但不能充分说明个体间的差异程度.在编码中,基因座所在的地位和作用往往是不同的,即使个体间的海明距离相同,他们的亲属关系仍有差异.因而本文考虑到各染色体基因座重要性的不同,使用加权海明距离判别个体间的相似度.加权海明距离计算公式:

其中,Hij为个体i 与个体j 的加权海明距离,Havg每代种群中个体间的平均加权海明距离,aim与ajm为染色体上的基因,w(xm)为染色体各个基因座的加权值,本文使用指数函数计算其加权值.为了说明海明距离与加权海明距离的量度差异,举一实例.如个体A:,个体B:和个体C:
同为30 位长度的二进制基因串,个体A 与个体B、个体A 与个体C 间的海明距离均为3,加权海明距离HAB=24+217+228=2.69 ×108、HAC=24+217+224=1.69 ×107.通过演算可知,虽然个体间海明距离相同,但加权海明距离存在较大差异,即其表现型在实际地理位置上却相距很远. 因此相对于海明距离,加权海明距离可以较好地度量个体间的相似度.在进行交叉率调整时,增大低相似度个体间的交叉率,减小高相似度个体间的交叉率,进而提高种群的多样性,避免局部收敛.
2.2 选择算子
在遗传算法中,传统的选择策略包括轮盘赌选择策略和锦标赛选择策略. 轮盘赌选择法模拟轮盘赌过程,维护适应度较大者入选概率较高的原则;而锦标赛选择法学习锦标赛竞争的方法,通过随机选取候选者,并在候选者中择优录取的方式实现选择操作.张琛和詹志辉[9]对轮盘赌选择策略和锦标赛选择策略进行了深入的研究,发现锦标赛选择策略在求解精度和求解速度上要优于轮盘赌选择策略.本文算法使用锦标赛选择策略挑选优秀个体.
具体操作步骤为:(1)设定每次选择的个体数量N;(2)从种群中随机选择N个个体构成一组;(3)根据每个个体的适应度值,选择其中适应度值最好的个体进入子代种群;(4)重复步骤(2)、(3),直到新一代种群生成为止.
2.3 交叉算子和变异算子
经研究发现,针对交叉率和变异率的自适应调整,研究者主要集中在研究适应度对其的影响[2-4,10-12],缺乏考虑种群的多样性. 本文在文献[3]、文献[13]的基础上添加相似度判断以及相似度调整因子,综合考虑加权海明距离指标和适应度指标,提出自适应调整交叉率和变异率的计算公式:

其中,Hbest为要变异的个体与最优个体间的加权海明距离,Pc1、Pc2分别是最大和最小交叉概率,Pm1、Pm2分别是最大和最小变异概率,α 为最大加权海明距离,K 为调节交叉率、变异率的权值.
对于交叉率Pc,计算公式中引入相似度调节因子.综合个体间的相似度以及适应度值,自适应调整Pc.调整过程为:(1)当个体适应度f'大于等于平均适应度favg,并且加权海明距离Hij小于平均加权海明距离Havg时,表明配对个体性能好且相似度高,根据计算公式,给予配对个体较小的交叉率;(2)当f'小于favg,并且Hij大于等于Havg时,表明配对个体性能差并且相似度低,根据计算公式,给予配对个体较大的交叉率;(3)当Hij、f'处于其他范围时,表明配对个体性能和相似度中等,根据计算公式,给予配对个体中等大小的交叉率. 对于变异率Pm,计算公式中引入相似度调节因子,综合个体间的相似度以及适应度值,自适应调整Pm,其调整过程与交叉率Pc相似.通过上述调节公式,可以减少高相似度、高适应度个体进行交叉、变异的概率,增加低相似度、低适应度个体交叉、变异的可能性,进而提高算法的搜索性能.
2.4 精英保留策略
遗传算法运行过程中,虽然随群体的进化过程会产生越来越多的优良个体,但由于交叉、变异等遗传操作的随机性,有可能破坏当前群体中适应度最好的个体,影响遗传算法的运行效率和收敛性. De Jong[14]首次提出一种精英保留策略. 该策略的实施可保证最优个体不会被交叉、变异等遗传运算所破坏,提高遗传算法的全局收敛性能.
精英保留策略的主要步骤是:(1)计算当代群体中各个体的适应值,找出适应值最好的个体;(2)比较当代最好个体与上一代最好个体(精英个体)的适应值,较大者作为新的精英个体;(3)将上一步中的精英个体存放到子代群体结构的第一位. 经过上述操作,保护了最好的个体模式,使算法朝着最优解的方向搜索.
2.5 双重停机准则
在设计遗传算法的终止条件时,传统的方法是采用总的进化代数T 为终止依据,如果进化代数达到T,则结束程序运行[1].但是,若初始群体以及参数选取非常理想,遗传算法可以很快搜寻到最优解.此时再采用该停机准则,便会增加不必要的搜索时间.
因此,在算法执行过程中,采用双重停机判断准则:进化代数达到总的进化代数T;连续多次进化的优化结果不变,或优化结果达到某一精度.在遗传进化过程中,满足上述2个条件中的任何一个,都视为满足终止条件.这种双重停机准则可以减少不必要的计算时间,提高收敛效率.该算法流程图见图1.
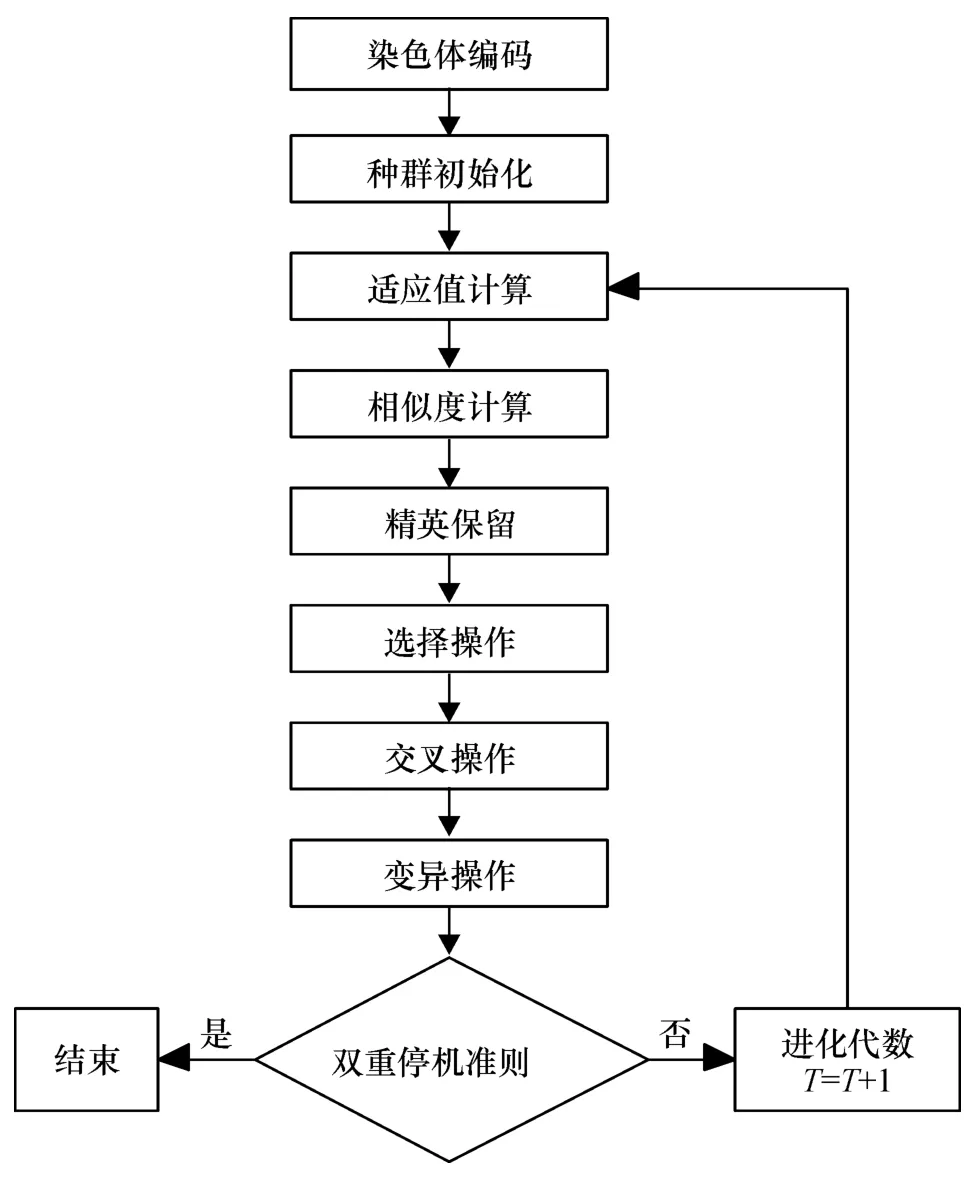
图1 算法流程图Figure 1 Flow chart of the algorithm
3 仿真测试
运用6个经典测试函数[1]在MATLAB 平台上进行仿真实验,并与标准遗传算法(GA)和传统自适应遗传算法(AGA)进行了对比测试.
3.1 测试用例
实验1:函数f1(图2A)的理论最大值比3.85略大,收敛值为3.850.
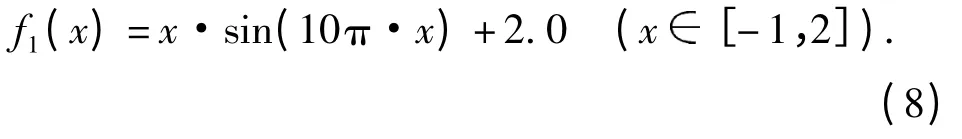
实验2:函数f2(图2B)的理论最小值为-1.031 628,收敛值为-1.031 60.
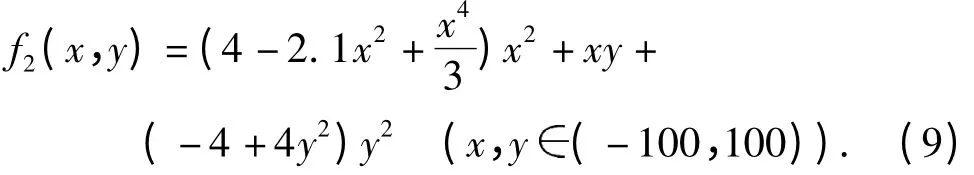
实验3:函数f3(图2C)的理论最小值为-186.730 9,收敛值为-186.730.
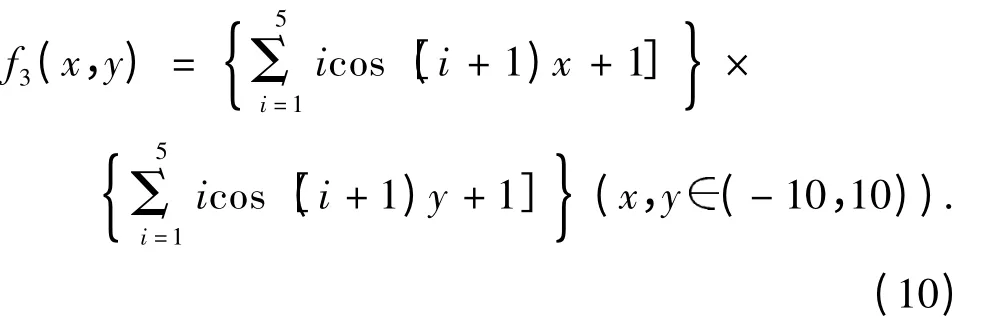
实验4:函数f4(图2D)的全局极小值f(0,0)=0,收敛值为0.007.
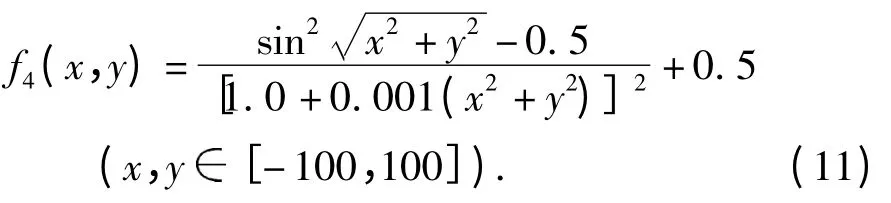
实验5:函数f5(图2E)的最大值为3 600,收敛值为3 600.00.

实验6:函数f6(图2F)具有一个全局极小值,收敛值为0.001.
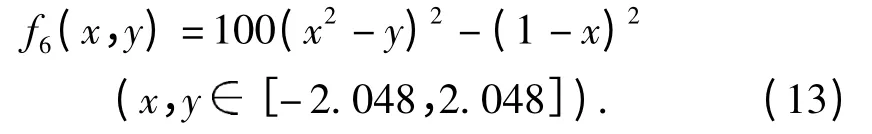
3.2 参数设置
算法均采用二进制编码,单点交叉,求解精度δ=1e-6,收敛准则设为种群适应度与全局最大适应度的差,其绝对值小于等于0.001.根据函数的复杂程度设定最大进化代数f1为100 代,f2、f6为300代,f3、f4、f5为500 代,3 种算法针对6个函数各自运行100 次.记录收敛次数、平均收敛代数、平均收敛值等指标.精度δ 计算公式为:
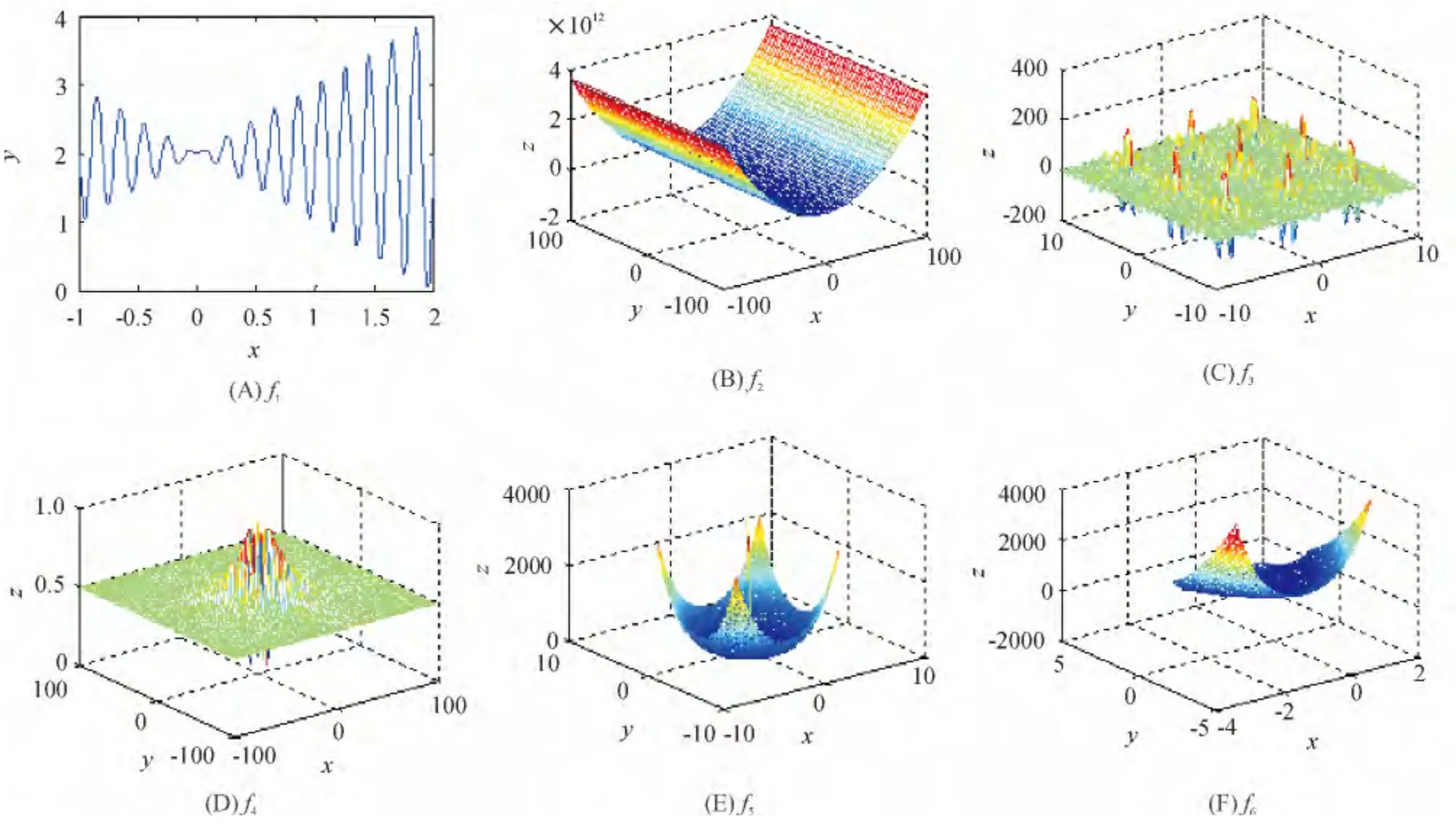
图2 测试函数Figure 2 Test functions

其中,δ 为编码精度,L 为编码长度,xmax、xmin分别为变量最大及最小取值.根据公式及精度要求计算f1、f2、f3、f4、f5、f6的编码长度,其值分别为22、28、25、28、24、22.
(1)标准遗传算法(GA). 采用轮盘赌选择策略,交叉概率Pc=0.85,变异概率Pm=0.05.
(2)传统自适应遗传算法(AGA). 采用轮盘赌选择策略,自适应的交叉概率k1=0.65、k2=0.9,自适应的变异概率k3=0.01、k4=0.1.
(3)基于加权海明距离的自适应遗传算法(HAGA).采用锦标赛选择策略,每次选择的个体数量N=10. 最大和最小交叉率分别为Pc1=0.9、Pc2=0.4,最大和最小变异率分别为Pm1= 0.2、Pm2=0.001,参数K=2,权值ω=(20,21,…,2L-1).
3.3 结果与分析
系统环境为:(1)处理器:Intel(R)Core(TM)i5-3210M CPU;(2)操作系统:Windows 7 Ultimate,32-bit;(3)仿真平台:Matlab,R2012a(7.14.0.739),32-bit.
性能指标为:(1)种群规模:种群中个体的数量;(2)收敛次数:运行100 次算法,全局收敛的次数;(3)平均收敛代数:运行100 次算法,种群收敛代数的算术平均值;(4)平均收敛值:运行100 次算法,收敛结果的算术平均值.其中,收敛次数、平均收敛值指标用于评价算法的全局搜索性能,平均收敛代数用于评价算法的搜索效率.
仿真测试见表1 ~表3,比较其中实验数据,针对各项指标,得出以下结论:
(1)收敛次数:针对简单的测试函数f1、f2、f6,3种算法收敛次数均较多,全局收敛性能较好,本文提出的HAGA 算法收敛次数多于GA 和AGA,说明HAGA 的全局收敛性能要好于GA 和AGA;针对较复杂的测试函数f3、f5,HAGA 具有明显的优势,收敛次数均在85 次以上,AGA 分别为82 次、62 次,GA 分别为71 次、58 次;针对函数f4,HAGA 的收敛次数不够理想,仅为74 次,但仍然高于AGA 的66次和GA 的60 次.
(2)平均收敛代数:对于测试函数f2,由于函数表达式极其复杂并且变量范围较大,导致收敛代数较多,HAGA、AGA 和GA 算法平均收敛代数分别为97、119 和136.对于其他测试函数,3 种算法在平均收敛代数上比较接近,但HAGA 算法平均收敛代数仍然要少于AGA 和GA,说明HAGA 在使用改进的交叉算子、变异算子、精英保留策略和双重停机准则后,在搜索效率上有一定提升.
(3)平均收敛值:3 种算法的平均收敛值均与测试函数理论收敛值接近,进一步说明本文提出的HAGA 算法的全局搜索性能和稳定性能较好.
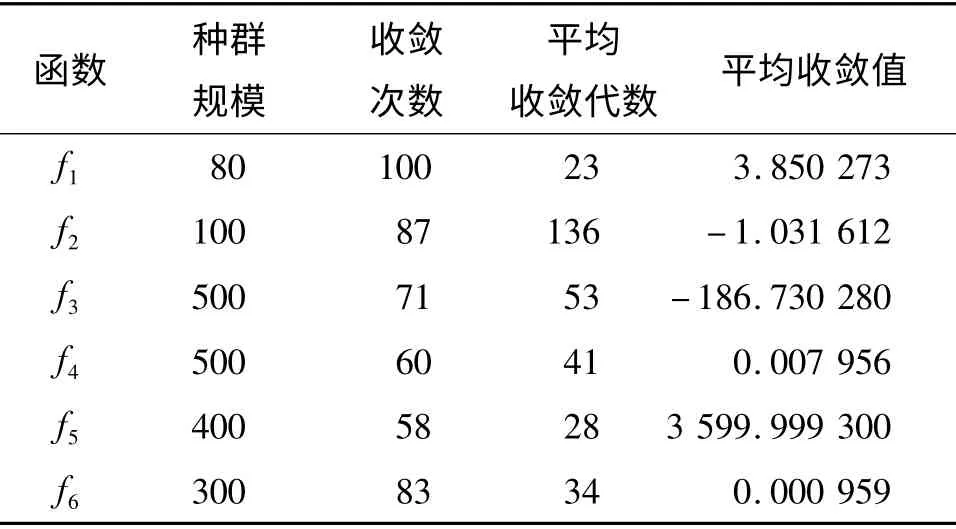
表1 标准遗传算法收敛性能Table 1 The convergence performance of standard genetic algorithm
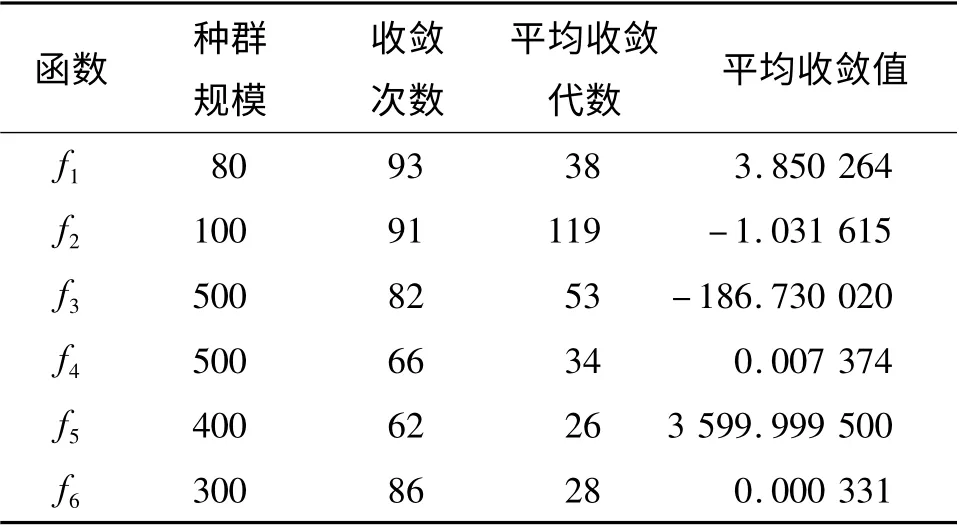
表2 传统自适应遗传算法收敛性能Table 2 The convergence performance of traditional adaptive genetic algorithm

表3 基于加权海明距离的自适应遗传算法收敛性能Table 3 The convergence performance of adaptive genetic algorithm based on weighted hamming distance
6 种测试函数在GA、AGA、HAGA 等3 种算法下进行搜索寻优性能比较(图3),发现:(1)对于函数f1、f3,HAGA 表现出了良好的搜索性能,在全局搜索能力和搜索效率上均要优于GA 和AGA;(2)对于函数f5和f6,在进化初期,GA 和AGA 在适应值的变化率上优于HAGA,但是随着进化代数的增长,种群相似度降低,GA 与AGA个体的质量改善非常缓慢. 而HAGA 使用适应度和相似度双重调节机制,自适应调整交叉率、变异率,可迅速改善个体适应度值;(3)对于函数f2和f4,在进化初期,HAGA与AGA 进化速率相似,均要快于GA. 在进化后期,AGA 与GA 陷入局部收敛,经过多次进化才跳出局部值,而HAGA 以较快的速率收敛到最优值.
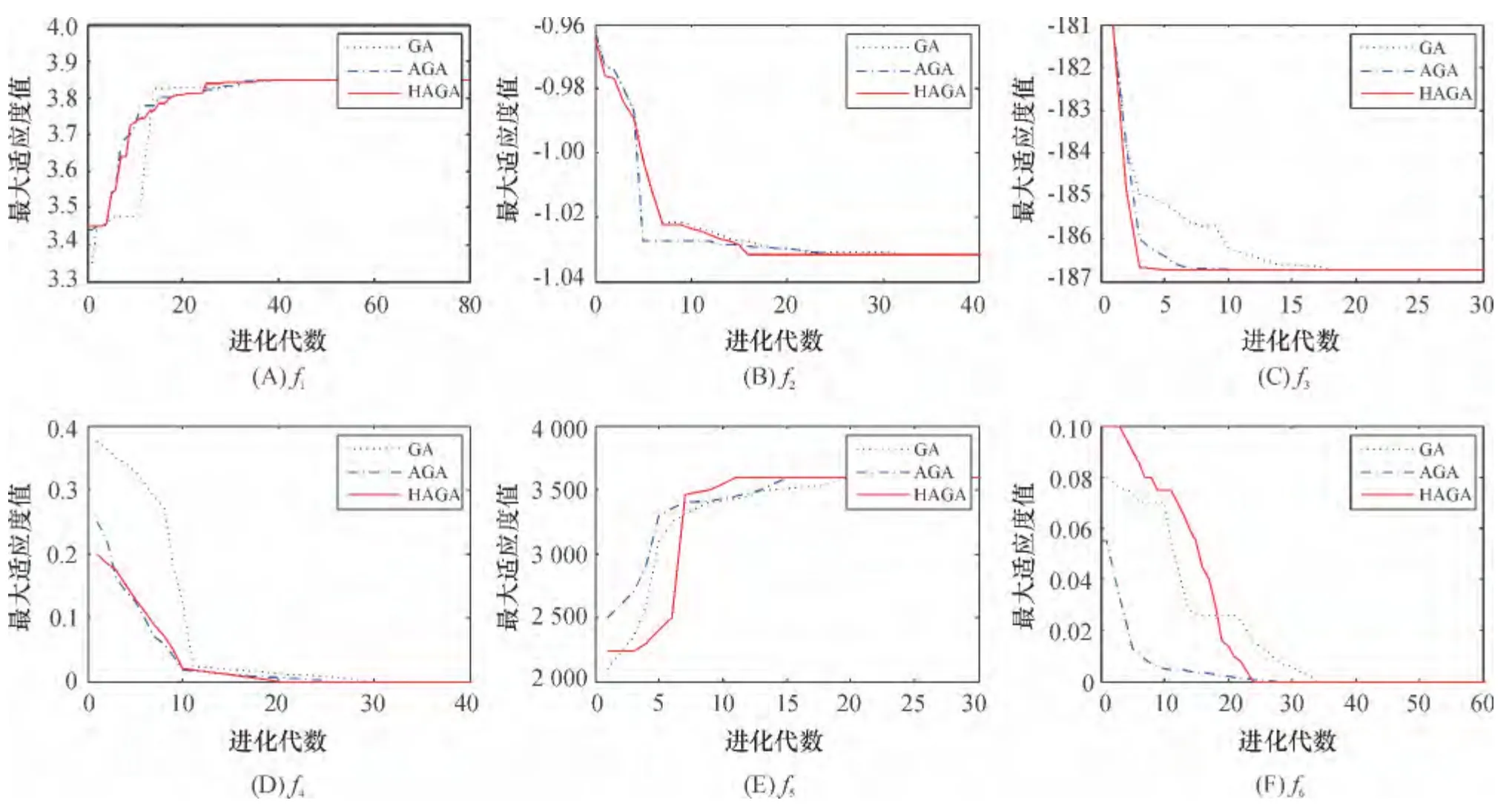
图3 函数最大适应值随进化代数的变化曲线Figure 3 The curves of the largest fitness value change during the evolution
4 结论
本文提出的基于加权海明距离的自适应遗传算法(HAGA),综合考虑个体间加权海明距离和适应度值,自适应调整交叉率和变异率;采用精英保留法,保证最优个体不被破坏;使用双重停机准则,提高遗传搜索效率.仿真测试表明,HAGA 算法在全局搜索能力和搜索效率上,明显优于GA 和AGA 算法.但是,针对某些特别复杂的函数,HAGA 仍然存在着早熟收敛的挑战. 下一步将尝试引入具有较强局部搜索能力的位爬山算法,改善HAGA 进化后期的搜索效率,并尝试运用HAGA 算法解决多目标优化问题.
[1]王小平,曹立明. 遗传算法-理论、应用与软件实现[M]. 西安:西安交通大学出版社,2002.
[2]Srinivas M,Patnaik L M. Adaptive probabilities of crossover and mutation in genetic algorithms[J].IEEE Transactions on Systems,Man and Cybernetics,1994,24(4):656-667.
[3]任子武,伞冶. 自适应遗传算法的改进及在系统辨识中应用研究[J]. 系统仿真学报,2006,18(1):41-43.Ren Z W,San Y. Improved adaptive genetic algorithm and its application research in parameter identification[J].Journal of System Simulation,2006,18(1):41-43.
[4]王杰,马雁,王非. 一种双变异率的改进遗传算法及其仿真研究[J]. 计算机工程与应用,2008,44(3):57-59.Wang J,Ma Y,Wang F. Study of improved genetic algorithm based on dual mutation and its simulation[J].Computer Engineering and Applications,2008,44(3):57-59.
[5]田丰,姚爱民,孙小平,等. 基于个体相似度的双种群遗传算法[J]. 计算机工程与应用,2011,32(5):1789-1791.Tian F,Yao A M,Sun X P,et al. Dual population genetic algorithm based onindividual similarity[J]. Computer Engineering and Applications,2011,32(5):1789-1791.
[6]李军华,黎明,袁丽华. 基于个体相似度交叉率自适应的遗传算法[J]. 系统工程,2006,24(9):108-111.Li J H,Li M,Yuan L H. The genetic algorithms with adaptive crossover rate based on individuals'similarity[J].Systems Engineering,2006,24(9):108-111.
[7]田小梅,郑金华,李合军. 基于父个体相似度的自适应遗传算法[J]. 计算机工程与应用,2005(18):61-63.Tian X M,Zheng J H,Li H J.Adaptive genetic algorithm based on parents' similarity[J]. Computer Engineering and Applications,2005(18):61-63.
[8]巩固,郝国生,王文虎. 基于海明距离改进的自适应遗传算法[J]. 江苏师范大学学报:自然科学版,2014,32(4):51-54.Gong G,Hao G S,Wang W H. Improved adaptive genetic algorithm based on Hamming distance[J]. Journal of Jiangsu Normal University:Natural Science Edition,2014,32(4):51-54.
[9]张琛,詹志辉. 遗传算法选择策略比较[J]. 计算机工程与设计,2009,30(23):5471-5474.Zhang C,Zhan Z H. Comparisons of selection strategy in genetic algorithm[J].Computer Engineering and Design,2009,30(23):5471-5474.
[10]金晶,苏勇. 一种改进的自适应遗传算法[J]. 计算机工程与应用,2005,41(18):64-69.Jin J,Su Y. An improved adaptive genetic algorithm[J].Computer Engineering and Applications,2005,41(18):64-69.
[11]梁兴建,詹志辉,谭伟,等. 基于最优保留策略的改进遗传算法[J]. 计算机工程与设计,2014,35(11):3985-3990.Liang X J,Zhan Z H,Tan W,et al.Improved genetic algorithm based on elitist reserved strategy[J]. Computer Engineering and Design,2014,35(11):3985-3990.
[12]李绍新,张延娇. 改进的遗传算法在蛋白质结构预测中的应用[J]. 华南师范大学学报:自然科学版,2009,25(1):56-60.Li S X,Zhang Y J. The application of improved genetic algorithms for predicting protein structures[J]. Journal of South China Normal University:Natural Science Edition,2009,25(1):56-60.
[13]Ho S L,Xu G Z,Fu W N.Optimization of array magnetic coil design for functional magneticstimulation based on improved genetic algorithm[J]. IEEE Transactions on Magnetics,2009,45(10):4849-4852
[14]De Jong K A. An analysis of the behavior of a class of generic adaptive systems[D]. Michigan:University of Michigan,1975.
猜你喜欢
计算机仿真(2022年8期)2022-09-28
河北理科教学研究(2021年4期)2021-04-19
数学年刊A辑(中文版)(2021年4期)2021-02-12
科学(2020年1期)2020-08-24
初中生世界·八年级(2019年6期)2019-08-13
郑州大学学报(工学版)(2018年2期)2018-04-13
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
中国塑料(2016年11期)2016-04-16
应用数学与计算数学学报(2015年1期)2015-07-20
