
农作物种质资源本体构建研究
2016-03-03 09:02陈丽娜司海平曹永生中国农业科学院作物科学研究所北京0008商丘师范学院计算机与信息技术学院河南商丘476000河南农业大学信息与管理科学学院河南郑州45000
作物学报 2016年3期
关键词:本体
陈丽娜 方 沩 司海平 曹永生,*中国农业科学院作物科学研究所, 北京 0008;商丘师范学院计算机与信息技术学院, 河南商丘 476000;河南农业大学信息与管理科学学院, 河南郑州 45000
农作物种质资源本体构建研究
陈丽娜1,2方沩1司海平3曹永生1,*
1中国农业科学院作物科学研究所, 北京 100081;2商丘师范学院计算机与信息技术学院, 河南商丘 476000;3河南农业大学信息与管理科学学院, 河南郑州 450002
摘要:本体是一种能够有效提高农作物种质资源整合、共享和利用效率的组织方式。在分析传统本体构建方法的基础上, 结合中国农作物种质资源自身的特点, 提出结构化数据与非结构化数据相结合的半自动化本体构建方法。该方法首先基于面向对象的思想从关系数据库中抽取概念及其关系建立初始本体; 然后从非结构化的网站数据中提取概念, 并利用在线字典WordNet和网络百科全书Wikipedia丰富概念的语义, 完善初始本体。使用本体构建工具Protégé构建了农作物种质资源本体模型。实验表明, 该方法既充分利用了数据库中的资源, 又考虑了非结构化数据的补充作用, 减少了构建成本, 本体更加完善。探讨了本体进化的途径, 指出了本研究的优点和局限性。
关键词:农作物种质资源; 本体; 结构化数据; 非结构化数据
本研究由国家农作物种质资源平台(2005DKA21001)和国家星火计划项目(2014GA750011)资助。
This study was supported by the National Infrastructure for Crop Germplasm Resources (2005DKA21001) and China Spark Program (2014GA750011).*通讯作者(Corresponding author): 曹永生, E-mail: caoyongsheng@caas.cn, Tel: 010-62186693
第一作者联系方式: E-mail: chenlina@cgris.org
农作物种质资源是人类生存和社会发展的基础,是培育作物新品种、发展生物技术、促进农业发展的基本条件, 是国民经济可持续发展的重要战略资源[1]。农作物种质资源的拥有和开发利用程度已成为衡量一个国家综合国力和可持续发展能力的重要指标之一。随着国家农作物种质资源平台的建立、运行, 并对外提供服务, 原有的基于传统关系数据库的资源信息组织方式不能很好地描述种质资源概念及概念间的关系。因此迫切需要新的组织方式,实现对资源的进一步规范化描述, 提高资源信息共享水平, 满足用户对种质资源信息日益增长的需求。本体可以更好地描述资源及其之间的关系, 它
为解决资源的组织方式提供了新途径。
本体起源于哲学领域, 是研究“存在”的科学,后来逐渐被引入到人工智能、信息科学等领域。目前, 在许多领域都进行了有关本体的研究。在国外, 3种模式(果蝇、小鼠和酵母)基因研究小组于1998年建立了基因本体, 它是生物信息学领域使用最广泛的本体, 其目的是希望提供一个具有代表性的规范化的基因和基因产物特性的术语描绘或词义解释的工作平台, 使生物信息学研究者对基因和基因产物的数据能统一归纳、处理、解释和共享[2]。联合国粮农组织(FAO)的农业本体服务(AOS)项目组也于2001年之后着手构建渔业本体、作物野生近缘植物本体、食物安全本体等[3-4], 并取得了良好的效果。美国的一些科研机构在国家科学基金会(NSF)的支持下, 构建了植物本体(PO)[5]。国际生物多样性研究中心也进行了有关作物本体的研究, 建立了作物相关的概念词汇[6]。在我国, 中国农业科学院农业信息研究所进行了本体在农业方面的应用研究, 构建了花卉学领域本体模型和实验型的智能检索系统, 为本体在图书情报领域的应用提供了范例[7]。大连海洋大学进行了渔业本体方面的相关研究工作, 研究了对渔业知识库更新的自动化半自动化方法[8]。四川大学进行了农作物栽培领域本体的构建[9], 探讨了农作物栽培领域本体构建的过程和步骤。南京农业大学也进行了基于本体的作物系统模拟框架的构建研究, 将本体技术应用于作物模拟模型领域, 为设计可重用的作物模型软件提供指导[10]。目前, 国外已经有一些很成熟的农业本体, 并得到了实际应用, 而国内的本体研究大都是尝试性的实验, 很少能真正达到成熟的阶段应用。在我国, 农作物种质资源本体还没有建立, 因此, 有必要尝试构建本体来描述种质资源概念及其关系。
在本体构建方面, 国外有很多典型方法, 包括骨架法、七步法、TOVE法、IDEF5法等[11], 它们为本体构建提供了很好的方法论基础。但由于本体的构建是面向特定的应用目的, 基于一定的专业领域和学科背景, 因此, 不可能照搬某一种方法, 通常是根据具体的应用对某种方法改进或将几种方法结合。国内也有一些学者进行了有关本体构建方法的研究[12-14], 这些方法大多是在领域专家参与下手工构建的, 工作量大, 费时费力。也有一些半自动化的构建方法[15-16], 但由于针对具体领域, 不适合种质资源的特点。我国农作物种质资源已经整合了包括粮、棉、油、蔬菜、果树等200多种作物, 40余万份种质, 建立了近700个数据库, 建成了中国作物种质资源信息网(CGRIS, http://www.cgris.net/)。这些海量数据, 如果依赖领域专家手工构建, 工作量将很大。
因此, 在借鉴不同领域本体研究的基础上, 分析不同的本体构建方法, 结合我国农作物种质资源的特点, 提出结构化数据与非结构化数据相结合的半自动化本体构建方法, 并尝试构建农作物种质资源本体, 期望通过本体来提高资源信息共享水平,从而提高种质资源的利用效率。
1 材料与方法
1.1试验材料
采用中国农作物种质资源相关数据, 包括结构化的数据库和非结构化网站的数据。相关的数据库包括国家作物种质库管理、青海复份库管理、国家种质圃管理、中期库管理、农作物特性评价鉴定、优异资源综合评价和国内外种质交换等9个子系统的相关数据库, 数据量超过340 GB[17]。涉及农作物种质资源普查数据、调查数据、引种数据、监测数据、保存数据、鉴定数据、分子数据、图像数据、利用数据等。相关的网站有国家植物种质资源平台、中国作物种质资源信息网、农作物种植论坛、中国蔬菜网和中国种业信息网等。其中国家植物种质资源平台又分为农作物种质资源、多年生与无性繁殖作物种质资源、热带作物种质资源、林木(竹藤花卉)种质资源、药用植物种质资源、牧草种质资源和野生植物种质资源6个子平台, 涵盖了作物种质资源领域包括文本、图像和视频等多种类型数据。对于非结构化的网站数据, 还需要利用在线词典WordNet和网络百科全书Wikipidia中丰富的资源,进行概念语义的映射。
1.2试验方法
针对本研究提出的方法, 将构建过程分为两步。针对结构化数据, 采用面向对象的方法构建初始本体; 然后半自动提取非结构化网站数据, 并利用在线词典WordNet和网络百科全书Wikipidia进行语义映射, 对初始本体进行完善。
1.2.1以结构化数据构建初始本体该步骤针对数据库中的结构化数据, 利用面向对象方法来构建初始本体。面向对象的方法最初是一种与结构化程序设计相对的编程方法, 后来不仅被用在程序设计方面, 也常被用在信息系统软件开发过程中。它将
现实世界的客观事物用对象抽象表示, 使用抽象、类、继承、封装等概念来构造系统。分析我国农作物种质资源相关数据库, 把每个数据库看作一个对象, 从中抽象出类、子类和元素。分析发现, 类、子类和元素之间存在明显的层次关系, 这种关系呈现出对象的“聚合”特征。数据库中对象的属性表示了作物的静态特征, 方法反映了作物的动态特征, 属性和方法结合为独立的个体, 体现了对象的“封装”特性。每个子类都继承了其父类的特征, 体现了对象的“继承”特性。因此, 采用面向对象的方法从数据库中抽取概念及关系来构建农作物种质资源初始本体, 是一种简单有效的方法。
构建初始本体的面向对象的方法是, 首先从数据库中抽象出类; 然后将类的概念映射成本体的概念, 将类的属性映射成与本体概念对应的概念的属性, 将类和子类的关系映射成本体概念间的关系,并根据类的约束规则建立本体概念间的约束关系;最后使用本体建模工具进行本体的形式化表达(图1)。

图1 面向对象的本体构建过程Fig. 1 Process of ontology construction based on object-oriented
1.2.2以非结构化数据完善初始本体初始本体是从关系数据库中抽取而建立的, 它基本上涵盖了农作物种质资源的重要内容, 反映了农作物种质资源的主要概念及概念间的关系, 但是仅仅依靠数据库所构建的本体还不够全面。在农作物种质资源领域的相关网站上, 还存在一些数据库中没有的其他重要信息资源, 因此, 参考这些网站的资源(尤其是CGRIS的资源)扩充初始本体, 可对种质资源生命周期的全部研究对象建立关系, 可使得构建的本体更加完善, 便于资源本体最大效能地发挥作用。
(1)概念的提取及分类: 网站涉及的数据量很大,抽取网站数据的方法很多, 可以对网页文档通过DOM解析进行抽取, 也可以使用正则表达式进行抽取[18-19]。本研究是希望获取网站的信息资源的概念来丰富初始本体, 因此, 希望抽取能代表网站内容和主题的概念数据。首先在Visual C++6.0环境下编写代码, 实现网站文本数据的自动提取(图2)。
通过该方法可以自动获取网页上的文本内容,为了获取文本中所包含的概念, 还需要对数据进行以下处理, 即对中文文本进行分词处理; 然后描述所获取文本的特征, 根据文本特征构建向量空间模型, 计算权值, 建立文本的初始特征向量; 再进行特征选择, 获得最终的特征词向量; 最后提取特征,进行文本的分类。有关网页文本数据的提取分类的算法很多, 本文不做重点阐述, 只是根据自动抽取的网页内容判断概念集并分类, 得到网站数据的初始概念集。
图2 获取网站文本的C++代码Fig. 2 C++ code of getting web text
(2)语义映射: 通过网站抽取的概念不涉及语义,但对本体概念及其关系的描述, 需要恰当的语义。本体中概念的语义可以由初始概念集关联在线词典WordNet和网络百科全书Wikipedia而得到。WordNet是普林斯顿大学认知科学实验室开发的一部在线英语词典, 它将单词按照意义组成一个单词的网络,具有强大的表达词汇关系的能力[20]。虽然我国已经开发了WordNet中文版本, 但还没到实用阶段, 所以概念关联的时候需要借助于中英文转换。Wikipedia是基于维基技术用不同语言写成的网络百科全书,其中DBpedia可以自维基百科提取数据, 借由资源
描述框架技术创建可供查询的语义网计划, 强化维基百科的搜寻功能, 并将其他资料集连结至维基百科[21]。
语义映射的具体实现步骤为, 将集合中的概念与初始本体中的概念比对, 若初始本体中不存在此概念, 将其映射到WordNet中, 通过WordNet的词表语义功能为每一个概念界定可能的意义。概念相似度, 其中Ci、Cj为任意2个概念, LCA(Ci, Cj)为Ci、Cj最近的共同祖先, depth(Ci)表示概念Ci在本体树中的深度, 根据计算结果选取相似度最高的概念, 得到带有初步语义的概念集。再通过Wikipedia确定与这些概念相关的页面集, 根据页面集中出现最频繁的术语确定与概念最相似的Wikipedia页面, 通过该页面找到与之对应的概念, 使用维基的词条进一步丰富概念的语义。另外, 还可以借助Google矫正拼写错误等。通过该步骤可以给初始概念集中的概念赋以恰当的语义。非结构化数据的概念抽取及语义映射过程如图3所示。
得到含有语义的网站概念集之后, 可根据集合中概念与概念、概念与属性、概念与资源的关系确定本体中概念间的关系。其对应关系如表1所示。

图3 概念抽取及语义映射过程示意图Fig. 3 Diagram of concept extract and semantic mapping process

表1 网站概念和本体概念的对应关系Table 1 Relationship between web concept and ontology concept
2 结果与分析
2.1初始本体的构建
由于本体构建是一项复杂的工程, 面对农作物种质资源的海量数据, 需要较多的人力物力长时间才能完成。因此, 本研究只进行本体模型的构建, 来验证本方法的有效性。
本体的构成要素包括概念、属性、关系、公理和约束等。根据面向对象的方法, 首先需要从数据库中抽象出类, 并映射成本体的概念; 然后定义概念的属性; 明确概念间的关系; 再定义概念的公理
和约束规则; 最后形式化表达, 可得到初始本体。
(1)自上而下抽取出基本的类, 并映射成本体的概念。基于农作物种质资源相关数据库, 分析农作物种质资源特征及整个生命周期的活动, 可将种质资源本体的研究对象分为种质收集、种质保存、种质分发、种质类型和种质属性几大类, 每一大类又可细分为小类。种质资源按其类别不同又可分为粮食作物、油料作物、纤维作物、蔬菜、果树及其他类型, 粮食作物又可细分为水稻、玉米、小麦、黍稷、大麦、谷子、高粱等, 其中小麦又可按其属名细分为小麦属、山羊草属、冰草属、偃麦草属、大麦属等[22]。对这些类及子类进行综合分析, 映射成本体的概念。
(2)对于每一类, 根据该类的属性, 将其映射成本体中概念的属性。分析数据库, 可得到作物的属性包括基本信息、形态特征和生物学性状、品质特性、抗逆性状、抗病性状等。基本信息又包括名称、原产地、保存单位、属名、科名、库编号、经度和纬度等。形态特征和生物学性状包括壳色、株高、穗型、粒度等。品质特性包括蛋白质、淀粉、赖氨酸含量等。对不同作物所关注的农艺性状有所不同,比如对玉米会关注穗型, 而对水稻则会考虑黏糯性。同样, 对不同作物可能会产生的病虫害类型也是不同的。
(3)抽取类的关系, 并将数据库中类的关系映射成本体中概念的关系。根据类的关系定义概念的上下位关系、成员关系、同义关系等。根据上述分析,类与子类存在上下位的层次关系; 不同种类的作物也可能存在成员关系, 比如作物按属来分, 绿豆、小豆、豇豆、饭豆等都属于豇豆属; 另外, 作物的品种名称和译名之间存在同义关系。
(4)根据数据库中类的约束关系定义本体概念的约束关系。对本体的概念建立约束, 可以保证本体概念的语法一致性、语义一致性及用户自定义的一致性。比如作物的株高、硬度、千粒重、耐涝性、抗寒性等都约束在一定的范围内, 这些作物的特性不会随着对象表达方式的不同而变化。同时, 约束关系的建立也有助于本体推理的实现。
(5)本体的形式化表达。这是利用本体建模工具建立本体的过程。本体的建模工具很多, 包括Oiled、WebOnto、OntoEdit、Protégé等[23]。其中Protégé是由斯坦福大学基于Java语言开发的一款开源的本体开发工具, 使用频率较高。
综合以上步骤, 使用Protégé4.3构建了农作物种质资源初始本体模型, 如图4所示(只显示部分模型)。
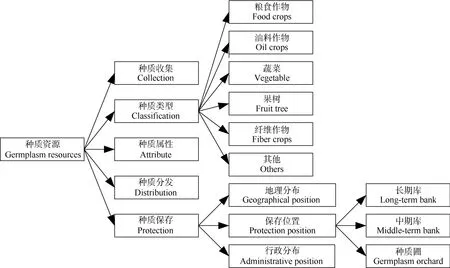
图4 初始本体模型Fig. 4 Initial ontology model
该本体模型由结构化数据库数据抽取而得到,涉及种质资源收集、保存、分发、种质分类及属性等方面。种质资源的分类和数据库中基本保持一致。将属性单独列出来, 是考虑到种质资源属性包括共性和特性, 对于共性描述部分, 可以统一描述, 便于建立不同种质资源之间的关系。对于种质保存部分, 除了描述某种质资源当前的保存位置之外, 还
增加了种质资源的地理和行政分布, 这便于和种质收集中的收集地点等建立联系。以本体的方式重新组织资源, 可将原有各相对独立数据库中的数据统一组织, 便于建立资源概念间的关系, 有利于提高资源信息共享的水平。
2.2本体的完善
从农作物种质资源相关网站自动提取网站概念,并对概念分类, 映射成本体的概念。比如对CGRIS网站进行概念抽取, 可以抽取出种业信息、农业知识、信息交流、优异种质、作物新品种、农业百科知识、作物病虫害知识、作物转基因科普、作物资
源照片等概念。对这些概念归纳综合, 可以提取本体的概念, 这些概念可以分为种业信息、农业知识、专业名词、信息交流等大类, 种业信息又可分为优异种质、作物新品种和种子法规子类, 农业知识又可分为转基因科普、植物遗传资源科普、病虫害知识、百科知识等子类。此外, 还可以提取农作物种质资源的查询数据、图片数据和信息规范数据等。对概念提取分类后, 进行语义映射, 给概念赋以语义, 将得到的概念、关系及语义加入到初始本体中,并更新概念间的关系, 最后进行形式化表达。完善后的农作物种质资源本体模型如图5所示。

图5 完善后的本体模型Fig. 5 Improved ontology model
非结构化的网站数据是动态数据, 包含了原有数据库中没有的信息, 其中会涉及到一些新的概念。将这些新概念补充到本体中, 可完善初始本体,使本体的体系结构更加完整。比如种业信息中包含育种得到的新品种, 其新特性涉及的一些新概念需要加入到本体中, 可以对资源进行更深层次的描述。
3 讨论
3.1农作物种质资源本体的进化
通过以上方法, 构建了农作物种质资源本体模型, 但随着农作物种质资源工作的进展, 种质资源概念的内容、结构、存在形式也在不断变化, 某些术语的含义也会随之变化。农作物种质资源本体与变化的信息资源之间的一致性就有可能遭到破坏,所以需要农作物种质资源本体概念的结构、关系不断调整、完善、改进和更新, 实现本体的进化[24]。种质资源本体的进化主要体现在以下几方面。
(1)学科自身发展的需要。由于种质资源学科自身的发展, 应用领域不断延伸, 产生新的学科生长点, 学科的知识结构发生变化, 因此需要根据学科发展需要对本体进行扩充, 使本体能体现学科发展过程中形成的新概念。另外, 本体进化并不意味着
本体概念数量的积累, 更在于本体概念质的提升,所以也要删除过时的、失效的概念[24]。
(2)新技术发展的需要。随着分子生物学和基因组学等新技术的发展, 种质资源鉴定工作过程中会出现一些概念的新特性, 需要对其不断丰富, 使其更加完整。
(3)新资源包含的新多样性特性。随着种质资源收集工作的推进, 尤其是从国外引进的一些新种质,可能会含有新的资源多样性特性。另外, 通过分子标记等新技术进行种质创新, 会产生新作物、新品种、新类型和新材料, 这些新概念包含了新特性, 需要将这些新概念特性及时地补充到本体中, 对本体进行更新。
3.2本构建方法的优点
传统的本体构建方法, 为农作物种质资源本体构建提供了借鉴, 但不适合农作物种质资源的特点。结构化数据和非结构化数据相结合的本体构建方法与传统的本体构建方法比较, 有以下优点。
(1)从关系数据库中抽取数据建立初始本体, 准确高效。充分利用了农作物种质资源已有数据库数据, 减少了本体构建的工作量。利用面向对象的方法可简单高效地从数据库中抽取概念, 并建立概念间的关系。
(2)网站中非结构化数据的应用对初始本体起到补充作用。概念的提取采用半自动化方法, 更加高效。利用在线词典WordNet和网络语义资源Wikipedia进行语义映射, 使本体的概念和语义更加完整。
3.3本研究的局限性
本研究只构建了种质资源本体模型, 种质资源领域涉及的概念非常多, 后期需要完善该模型, 使概念更加丰富。由于种质资源的特殊性, 它大部分集中在国家及地方种质库中, 获取种质资源信息的渠道非常有限, 有关种质资源信息的个人或者商业网站很少, 所以本研究采用的非结构化数据来源于农作物种质资源专业网站, 期待能有多样的种质资源网站数据。另外, 本研究探讨了本体进化的途径,并没有真正在模型中体现出来, 希望随着研究工作的推进, 将本体进化的内容增加进去, 并研究合适的本体进化机制。
4 结论
根据农作物种质资源的特点, 提出了一种半自动化的本体构建方法, 构建了农作物种质资源本体模型, 探讨了本体进化的途径。农作物种质资源本体的构建为种质资源的组织提供了新方式, 本体中丰富的语义便于知识发现, 从而提高资源的利用效率。
本体与传统数据库相比, 有很强的表达概念语义和获取知识的能力, 可以实现一致性检查、逻辑推理等, 利用本体可以在差异很大的系统之间实现交互, 实现的资源的集成共享。基于本体的数据库访问, 能够使用户基于统一的视图查询底层数据,实现大规模数据的集成和访问。但目前真正能达到本体和数据库高效互访的系统还很少, 这也将是我们下一步研究的内容。
References
[1] 卢新雄, 曹永生. 作物种质资源保存现状与展望. 中国农业科技导报, 2001, 3(3): 43–47
Lu X X, Cao Y S. Current status and prospect of crop germplasm resources for ex situ conservation. Rev China Agric Sci Technol, 2001, 3(3): 43–47 (in Chinese with English abstract)
[2] Ashburner M, Ball C A, Blake J A, Botstein D, Butler H, Cherry J M, Davis A P, Dolinski K, Dwight S S, Eppig J T, Harris M A, Hil D P, Issel-Tarver L, Kasarskis A, Lewis S, Matese J C, Richardson J E, Ringwald M, Rubin G M, Sherlock G. Gene Ontology: tool for the unification of biology. Nat Genet, 2000, 25: 25–29
[3] Kawtrakul A. Ontology engineering and knowledge services for agriculture domain. J Integr Agric, 2012, 11: 741–751
[4] 常春. 联合国粮食与农业组织AOS项目. 农业图书情报学刊, 2003, (2): 14–15
Chang C. AOS Project of Food and Agricultural Organization of the United Nation. J Lib Inform Sci Agric, 2003, (2): 14–15 (in Chinese with English abstract)
[5] Cooper L, Walls R L, Elser J, Gandolfo M A, Stevenson D W, Smith B, Preece J, Athreya B, Mungall C J, Rensing S, Hiss M, Lang D, Reski R, Berardini T Z, Li D H, Huala E, Schaeffer M, Menda N, Arnaud E, Shrestha R, Yamazaki Y, Jaiswal P. The plant ontology as a tool for comparative plant anatomy and genomic analyses. Plant Cell Physiol, 2013, 54(2): e1
[6] Matteis L, Chibon P Y, Espinosa H, Skofic M, Finkers R, Bruskiewich R, Hyman G, Arnaud E. Crop ontology: vocabulary for crop-related concepts. Semant Biodiversity (S4BioDiv 2013), 2013, 979: 37–45
[7] 李景. 本体理论及在农业文献检索系统中的应用研究——以花卉学本体建模为例. 中国科学院博士学位论文, 北京, 2004
Li J. Study on the Theory and Practice of Ontology and Ontology-Based Agricultural Document Retrieval System-Floricultural Ontology Modeling. PhD Dissertation of Chinese Academy of Sciences, Beijing, China, 2004 (in Chinese with English abstract)
[8] 于红, 刘溪婧. 基于知识库的渔业领域本体学习算法. 大连海洋大学学报, 2011, 26(2): 168–172
Yu H, Liu X J. Knowledge base based fisheries ontology learning algorithm. J Dalian Ocean Univ, 2011, 26(2): 168–172 (in Chi-
nese with English abstract)
[9] 张柳, 黄春毅. “农作物栽培” 领域本体的构建. 农业图书情报学刊, 2009, 21(1): 68–72
Zhang L, Huang C Y. Establishment of ontology on crops cultivation domain. J Lib Inform Sci Agric, 2009, 21(1): 68–72 (in Chinese with English abstract)
[10] 姜海燕, 朱艳, 汤亮, 花登峰, 曹卫星. 基于本体的作物系统模拟框架构建研究. 中国农业科学, 2009, 42: 1207–1214
Jiang H Y, Zhu Y, Tang L, Hua D F, Cao W X. Study on ontology-based framework of crop system simulation. Sci Agric Sin, 2009, 42: 1207–1214 (in Chinese with English abstract)
[11] Uschold M, Gruninger M. Ontologies: Principles, methods and applications. Knowledge Eng Rev, 1996, 11: 93–136
[12] 张文秀, 朱庆华. 领域本体的构建方法研究. 图书与情报, 2011, 155(1): 16–19
Zhang W X, Zhu Q X. Research on construction methods of domain ontology. Library and Information, 2011, 155(1): 16–19 (in Chinese with English abstract)
[13] 陈琨, 张蕾. 基于知识图的领域本体构建方法. 计算机应用, 2011, 31: 1664–1666
Chen K, Zhang L. Domain ontology construction method based on knowledge graphs. J Comput Appl, 2011, 31: 1664–1666 (in Chinese with English abstract)
[14] 张云中. 一种基于FCA和Folksonomy的本体构建方法. 现代图书情报技术, 2011, 27(12): 15–23
Zhang Y Z. A new ontology construction method based on FCA and Folksonomy. New Technol Lib Inform Serv, 2011, 27(12): 15–23 (in Chinese with English abstract)
[15] 丁晟春, 傅柱. 基于航天叙词表的领域本体半自动化构建研究. 情报理论与实践, 2011, 34(11): 113–116
Ding C C, Fu Z. Research on domain ontology semi-automated construction based on aerospace thesaurus. Inform Studies: Theor Appl, 2011, 34(11): 113–116 (in Chinese with English abstract)
[16] 李亢, 李新明, 刘东. 面向数据语义集成的装备领域本体构建研究. 系统仿真学报, 2015, 27: 1071–1080
Li K, Li X M, Liu D. Study on equipment domain ontology construction for integration of data semantics. J Syst Simul, 2015, 27: 1071–1080 (in Chinese with English abstract)
[17] 曹永生, 方沩. 国家农作物种质资源平台的建立和应用. 生物多样性, 2010, 18: 454–460
Cao Y S, Fang W. Establishment and application of national crop germplasm resources infrastructure in China. Biodiversity Sci, 2010, 18: 454–460 (in Chinese with English abstract)
[18] 胡军伟, 秦奕青, 张伟. 正则表达式在Web信息抽取中的应用.北京信息科技大学学报, 2011, 26(6): 86–89
Hu J W, Qin Y Q, Zhang W. Regular expression and its applications to web information extraction. J Beijing Inform Sci Technol Univ, 2011, 26(6): 86–89 (in Chinese with English abstract)
[19] 李朝, 彭宏, 叶苏南, 张欢, 杨亲遥. 基于DOM树的可适应性Web信息抽取. 计算机科学, 2009, 36(7): 202–203
Li C, Peng H, Ye S N, Zhang H, Yang Q Y. Adaptive web information extraction based on DOM tree. Comput Sci, 2009, 36(7): 202–203 (in Chinese with English abstract)
[20] Miller G A. WordNet: a lexical database for English. Commun ACM, 1995, 38(11): 39–41
[21] Lehmann J, Isele R, Jakob M, Jentzsch A, Kontokostas D, Mendesf P N, Hellmann S, Morsey M, Kleef P V, Auer S, Bizer C. DBpedia-a large-scale, multilingual knowledge base extracted from wikipedia. Semant Web J, 2014, 5: 1–29
[22] Abburu S, Babu G S. Survey on Ontology Construction Tools. Int J Sci Eng Res, 2013, 4: 1748–1752
[23] 李立会, 杨欣明. 小麦野生近缘植物种质资源描述规范和数据标准. 北京: 中国农业出版社, 2006
Li L H, Yang X M. Descriptors and Data Standard for Wild Relatives of Wheat (Wild Species of Triticeae). Beijing: China Agriculture Press, 2006
[24] 马文峰, 杜小勇. 领域本体进化研究. 图书情报工作, 2006, 50(6): 71–75
Ma W F, Du X Y. A study on domain ontology evolution. Lib Inform Ser, 2006, 50(6): 71–75 (in Chinese with English abstract)
URL: http://www.cnki.net/kcms/detail/11.1809.S.20151218.0915.010.html
Ontology Construction of Crop Germplasm Resources
CHEN Li-Na1,2, FANG Wei1, SI Hai-Ping3, and CAO Yong-Sheng1,*
1Institute of Crop Science, Chinese Academy of Agricultural Sciences, Beijing 100081, China;2Department of Computer and Information Technology, Shangqiu Normal College, Shangqiu 476000, China;3College of Information and Management Science, Henan Agricultural University, Zhengzhou 450002, China
Abstract:Ontology is an efficient organization for improving integration, sharing and use efficiency of crop germplasm resources. On the basis of analyzing traditional ontology construction methods and characteristics of national crop germplasm resources, a semi-automated ontology construction method combining structured data and unstructured data was proposed. The method established initial ontology by extracting concepts and their relationship from relational database based on object-oriented approach, then, extracted concepts from unstructured web data, and enriched the semantic of these concepts using online dictionaries such as WordNet and online encyclopedia Wikipedia, so as to improve the initial ontology. Crop germplasm resources ontology model was constructed using Protégé, an ontology construction tool. The experimental results showed that the method made the database resources fully utilized, the complementary role of unstructured data considered, the cost of ontology construction reduced, and the ontology more perfected. The paper discussed ontology evolution way, and pointed out the advantages and disadvantages of the study.
Keywords:Crop germplasm resources; Ontology; Structured data; Unstructured data
收稿日期Received(): 2015-08-09; Accepted(接受日期): 2015-11-20; Published online(网络出版日期): 2015-12-18.
DOI:10.3724/SP.J.1006.2016.00407
猜你喜欢
吉林大学学报(信息科学版)(2021年5期)2021-10-26
哈哈画报(2021年10期)2021-02-28
云南师范大学学报(自然科学版)(2020年3期)2020-05-29
山东冶金(2019年3期)2019-07-10
中小企业管理与科技(2019年12期)2019-06-12
小型微型计算机系统(2019年6期)2019-06-06
制造业自动化(2017年2期)2017-03-20
现代工业经济和信息化(2016年6期)2016-05-17
电子设计工程(2015年5期)2015-02-27
中国音乐教育(2014年3期)2014-05-16
