
基于PrefixSpan序列模式挖掘的改进算法
2016-03-08 07:08黄晓芳
西南科技大学学报 2016年4期
王 斌 黄晓芳 袁 平
(西南科技大学计算机学院 四川绵阳 621000)
基于PrefixSpan序列模式挖掘的改进算法
王 斌 黄晓芳 袁 平
(西南科技大学计算机学院 四川绵阳 621000)
针对PrefixSpan算法在构建投影数据库时时间开销过多和随着支持度增加效率下降的问题,提出了一种基于PrefixSpan算法的改进算法AP(AprioriAll-PrefixSpan),该算法可以减少构建投影数据库的时间开销和降低支持度增加对算法效率的影响。改进思想是在第一次划分生成投影数据库时,按投影数据库中项集的个数从小到大排序,在第二次划分的时候 ,从已挖掘序列模式中直接生成所需序列模式,从而减少数据库的构建。实验结果显示AP 算法效率高于PrefixSpan算法。
PrefixSpan 序列模式 投影数据库 生成序列 二次划分
序列模式挖掘是挖掘频繁出现的有序事件或子序列[1]。由于序列模式挖掘对先验知识的依赖较少,可以发现未知的规律,所以得到了广泛的应用。比如:网络安全中的异常行为发现[2]、生物工程[3]、DNA序列分析[4]、网络访问模式分析[5]、用户社交行为分析[6]等。
序列模式挖掘最先由Agrawal和Srikant在文献[7]中提出,论文主要介绍了3种基于Apriori算法框架的AprioriAll,AprioriSome和DynamicSome算法,随后提出了一种基于泛化GSP[8]算法。文献[9]提出了一种基于垂直数据格式的SPADE 算法。以上算法都会产生大量的候选集。而文献[10]提出的FreeSpan算法,是基于序列模式的增长,不产生候选集。文献[11]的PrefixsSpan算法是对FreeSpan算法的改进,减少了投影数据库和子序列连接次数,数据库收敛更快,算法效率比之前的算法效率都高。
PrefixSpan算法[11]是根据前缀生成对应的投影数据库,然后对投影数据库进行扫描,避免了对整个数据库进行扫描,从而减少了扫描时间。算法的主要时间开销在构建投影数据库,且在随着支持度增加的时候,效率会降低。由于支持度的提高,导致投影数据库的收敛度减少。文献[12]对构建数据库改进,但对数据形式要求过高。文献[13]对内存存储改进,当支持度增加时,效率下降。本文基于PrefixSpan算法提出了一种AP(ApriopriAll-PreFixSpan)算法。算法思想是直接从已挖掘序列模式中生成所需序列模式,减少投影数据库的构建。随着已挖掘序列越多,挖掘的速度会越快,且对数据形式没特别要求。算法结合了AprioriAll算法[2]的优点,减少了支持度增加对效率的影响。
1 AP算法研究与实现
1.1 相关概念
设length-1表示数据库S中第一次扫描数据库,得到序列模式,Length-2表示扫描以length-1中任一序列模式划分的投影数据库,得到序列模式。如length-2 可以是扫描第一次以为前缀划分的投影数据库,产生的序列模式,也可以是扫描第一次以

表1 数据库Table 1 Database
定理1 设数据库S中有序列模式,以length-1为前缀划分产生的序列模式集设为β,以length-2为前缀划分得到的序列模式集设为a,那么有a⊆β。
证明:由于数据库S中以length-1为前缀的投影数据库是第一次扫描数据库所得,即数据库S中所有包含的序列组成的序列数据库,为含有项的最大序列数据库集。而length-2中以为前缀的投影数据库是第一次划分后的投影数据库的投影数据库,所以是包含于S数据库中最大序列数据库中的。数据库决定了序列模式集,所以有a⊆β。以表1为数据库,描述一个例子如表2。

表2 投影数据库Table 2 Projection database
从表2可知投影数据库是包含于的投影数据库。
本文基于AprioriAll算法中验证候选集,并结合PrefixSpan算法产生序列的特点,提出了一种YZ方法。该方法思路:如果已知以一个序列模式为前缀的序列模式集为β以及对应投影数据库S|a, 以序列模式集β中的序列模式为候选集,扫描投影数据库S|a,验证候选集中各序列模式的个数是否大于支持度来产生序列模式的序列模式集。由PrefixSpan产生序列模式的特点可以知道,如果一个序列不满足支持度,则以该序列为前缀的序列都不满足。所以在验证候选集时, 如果一个序列不满足支持度,那么以该序列为前缀的序列就不用验证。
定理2 设数据库S中有一个序列模式和对应投影数据库S|a,以为前缀的序列模式集为β。如果已知序列模式集β,从投影数据库S|a中采用YZ方法得到β的时间是小于用PrefixSpan算法在数据库S|a得到序列模式集β。PrefixSpan算法开销在于构造投影数据库,而YZ方法不需要构建投影数据库,所以效率比PrefixSpan高。且降低了支持度增加对算法效率的影响,由于YZ方法对数据库的收敛依赖没有PrefixSpan高。实验 1证明了这个结论。
1.2 AP算法描述
(1) 同PrefixSpan算法,扫描数据库得到长度为1的序列模式,然后分别以length-1为前缀划分,再以length-1得到的投影数据库排序,按投影数据库中项集的个数,从小到大排序。
(2) 从最小的投影数据库开始挖掘,扫描投影数据库得到对应length-2 序列模式,后以length-2为前缀划分,此时扫描结果数据集,判断以该序列为前缀的length-1是否挖掘,如果已挖掘直接从length-1序列集用YZ方法产生所需序列模式。如果没有同PrefixSpan算法。求以length-2为前缀的序列模式集时,由定理1知道length-2 为前缀的序列模式集是包含于length-1为前缀的序列模式集,所以可以直接从length-1采用YZ方法中产生。由定理2知,从length-1中生成序列的时间少于用PrefixSpan算法。由于PrefixSpan产生的序列模式是根据序列递增的,如
算法伪代码:
输入:序列数据库S和最小支持度min_sup;
输出:所有序列模式;
函数:AP(<>,S);
功能:第一次扫描数据库S,产生length-1序列模式和对应投影数据库。
函数:AP(a,S|a);
功能:l(l≥2)次以上扫描数据库,产生length-l序列模式和对应投影数据库。
函数:AP(b,β,S|b);
功能:从序列模式集β中,采用YZ方法,生成以为划分的序列模式集。
参数:a为一个序列模式,L为序列模式的长度,如果L长度为1,数据库为S,否则为S|a,b为一序列模式,S|b为以 为前缀的投影数据库,β为以length-1为前缀的序列模式集。
(1)调用AP(<>,S|a),得到length-1序列模式,对投影数据库按项集个数从小到大排序。
(2)调用AP(a,S|a)生成对应的length-2序列模式。
(3)判断以length-2为前缀是否已经挖掘,如果没有挖掘,循环调用AP(a,S|a)挖掘,直到没有频繁项,如果已挖掘,调用AP(b,β,S|b),从已挖掘的序列模式中产生所需模式。
(4)转到第2步。
1.3 以表1为数据库,描述算法过程
(1)扫描数据库S,得到length-1的序列模式,分别是:4,:4,
(2)以第一步的序列模式为前缀划分得到6个投影数据库,分别是,,
(3)从小的投影数据库开始挖掘。当挖掘以为前缀时,扫描的投影数据库得到频繁项有:2,:4,
2 实验分析
2.1 实验一 对定理2的分析
该实验采用CPU为2.1 GHZ,4 G内存,window7操作系统,算法代码采用java编写,实验测试数据采用 IBM Quest Synthetic Data Generator 生成(产生数据同文献[7]),对数据集C10T3S4I1.25进行测试,测试数据集的有关参数:|D|表示顾客数设为100;|N|表示总项数,设为3 000;其他的按默认设置。分别取支持度为3%,4%,5%,6%,7%,8%,9%,10%,11%,测试YZ方法和PrefixSpan方法。
图1 表示PrefixSpan所用时间比YZ方法所用时间随支持度变化, 从图1知PrefixSpan方法所用时间与YZ算法所用时间之比随支持度增加而增加。在10%后曲线下降,序列模式的数量减少了,虽然单个模式时间提高更多,但是整体时间提高减慢。
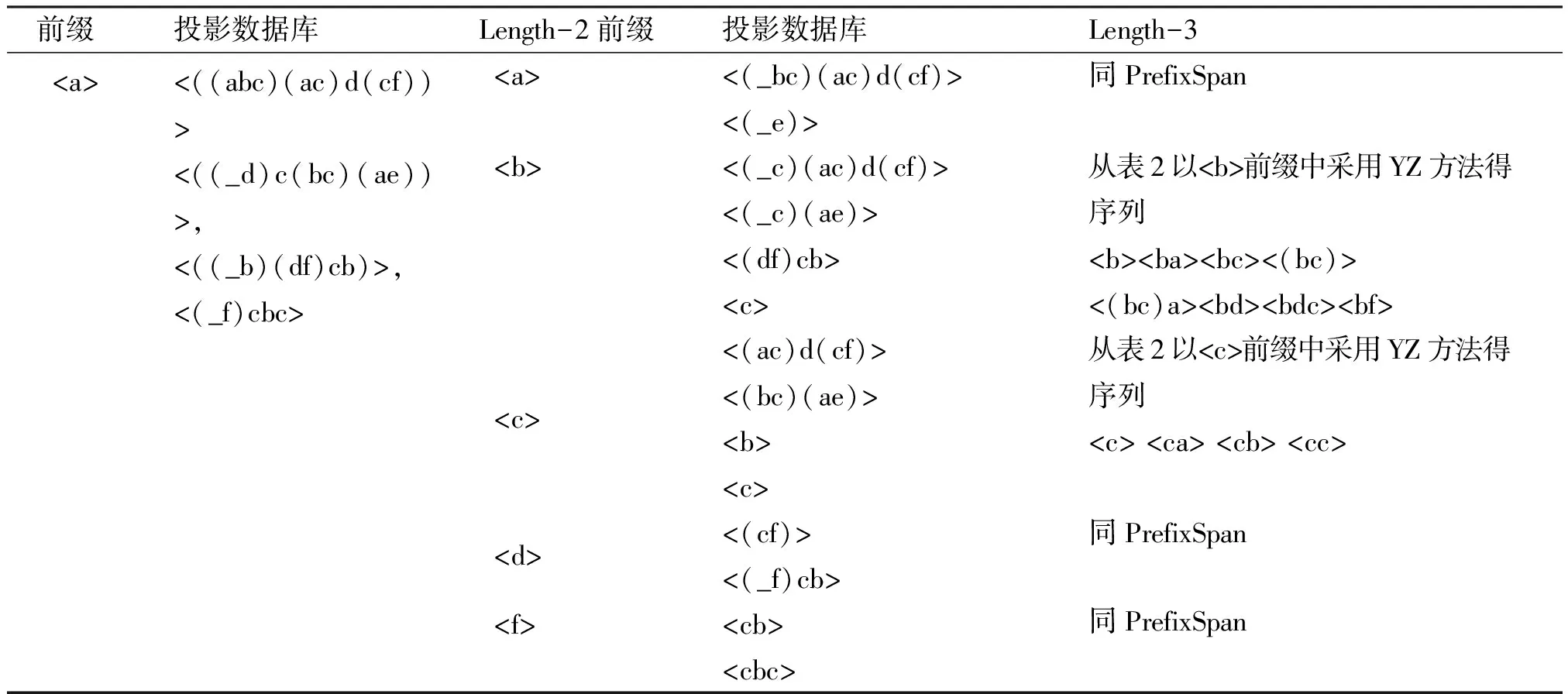
表3 二次投影数据库Table 3 Two-time projection database
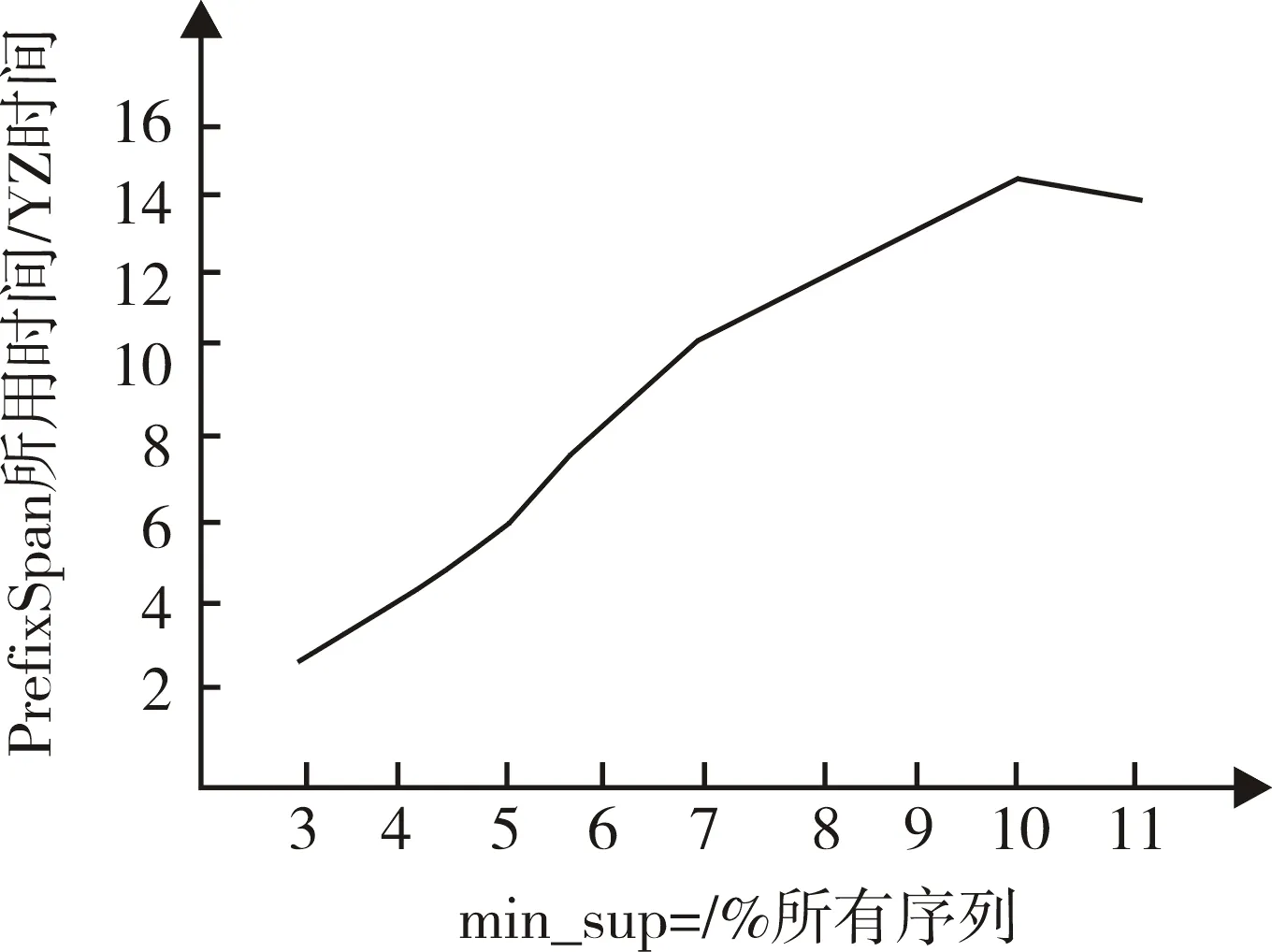
图1 时间比随支持度变化Fig.1 Time ratio diagram with change of support
图2表示PrefixSpan所用时间比YZ所用时间随所占该项序列的变化,从图2可以看到对于单个模式,随占该序列总数比例增加,PrefixSpan所用时间与YZ所用时间比增加。
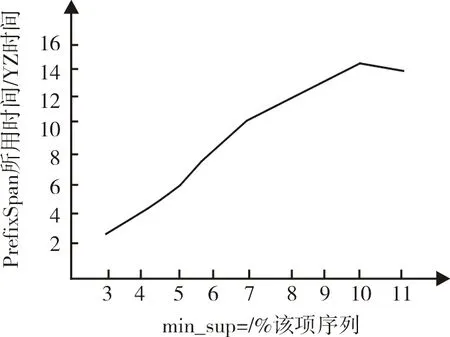
图2 时间比随所占比例变化Fig.2 Time ratio diagram with change of occupation
实验结果显示YZ方法优于PrefixSpan方法,定理2是成立的。
2.2 实验二 AP算法和PrefixSpan算法对比
实验环境和测试数据集同实验一,在对测试数据集分别取支持度为3%,4%,5%,6%,7%,8%,9%,10%,11%。实验结果如图3,从图3可以看出支持度在4%到8%之间的时候AP算法明显优于PrefixSpan算法。实验一显示随支持度增加,YZ方法所用时间与PrefixSpan所用时间之比是越来越小,而图3显示在支持度超过8%以后,PrefixSpan算法和AP算法所用时间差距在减少。主要由于随支持度的增加,序列模式的数量减少,算法所用的总时间在减少,两个算法之间的时间差距相应的就变小了。由实验结果知,YZ方法明显优于PrefixSpan算法。

图3 所用时间对比Fig.3 Comparison of time consumed
3 结束语
本文在研究PrefixSpan算法的基础上,研究了PrefixSpan算法的开销主要在于构建子数据库,同时也研究了AprioriAll算法思想,AprioriAll算法在验证候选集是高效的。本文基于PrefixSpan算法生成的序列自身特点改进了该验证方法,提高了PrefixSpan算法,也降低了随支持度增加对算法效率的影响。AP算法对顾客数量过大的网络数据挖掘效率不高。下一步主要研究PrefixSpan算法在网络安全中的具体应用,期望PrefixSpan算法能够自动发现网络攻击。
[1] HAN J,KAMBER M. 数据挖掘概念与技术[M]. 北京: 机械工业出版社,2012.
[2] 李锦玲,汪斌强.基于最大频繁序列模式挖掘的App-DDoS攻击的异常检测[J]. 电子与信息学报, 2013,35(7):1739-1745.
[3] 朱扬勇,熊赞. DNA序列数据挖掘技术[J]. 软件学报,2007,18(11):2767-2781.
[4] 杨恒宇.生物序列数据挖掘技术研究[J]. 合肥工业大学学报(自然科学版),2012,35(9):1212-1216.
[5] 龚卫华,郭伟鹏,杨良怀. 信任网络中多维信任序列模式挖掘方法研究[J].电子与信息学报,2014,36(8):1810-1816.
[6] 丁振国,宋薇,李婧. 基于序列模式挖掘的社交网络用户行为分析[J]. 现代情报, 2013,33(3):56-65.
[7] AGRAWAL R,SRIKANT R. Mining sequential patterns [C].Proceedings of the 11thInternational Conference on DataEngineering. CA: Los Alamitos,IEEE Computer Society,1995: 3-14
[8] SRIKANT R,AGRAWAL R.Mining sequential pattems: generali-zations and performance improvements [C]. EDBT 96:Proceedings of the 5th International Conference on Exten-ding Database Technology: Advances in Database Technol-ogy. UK,London: Springer-Verlag, 1996: 3-17.
[9] ZAKI M. SPADE: An efficient algorithm for mining fre-quent sequences[J]. Macheine Learning,2001,42(1): 31-60.
[10] HAN J,PEI J,MORTAZAVIASL B,et al. FreeSpan: Frequentpattern-projected sequential pattern mining [C]. Proceed-ings of the 6thACM SIGKDD International Conference on,Knowledge Discovery and Data Mining. USA,New York:ACM,2000: 355-359.
[11] PEI J,HAN J,MORTAZAVIASL B,et al. Mining sequentialpatterns by pattern-growth: the prefixspan approach[J].IEEE Transactions on Knowledge and Data Engineering,2004,16( 11) : 1424-1440.
[12] 公伟,刘培玉,贾娴.基于改进 Prefixspan的序列模式挖掘算法[J].计算机应用,2011,31 (9) : 2405-2407.
[13] 张巍,刘峰,滕少华.改进的 PrefixSpan算法及其在序列模式挖掘中的应用[J].广东工业大学学报,2013 ,30(4):49-54.
Improved Algorithm Based on PrefixSpan Sequence Pattern
WANG Bin, HUANG Xiaofang, YUAN Pin
(SchoolofComputerScienceandTechnology,SouthwestUniversityofScienceandTechnology,Mianyang621010,Sichuan,China)
In the construction of projection database, the time consumed is too much and the efficiency of the PrefixSpan algorithm is decreased with the degree of support reduced. An improved AP (AprioriAll-PrefixSpan) algorithm based on PrefixSpan algorithm is proposed in this paper. This new algorithm can reduce the impact caused by the time consumed for building the projection database and the reduced degree of support. During the first time of dividing the projection database, the item sets were ranked in an ascending order. During the second time of dividing the projection database, the sequence pattern was generated automatically from the already obtained database, so as to reduce the database construction. Experimental results show that the efficiency of AP algorithm is higher than that of PrefixSpan algorithm.
PrefixSpan; Sequence pattern; Projection database; Sequence generation; Two-time division
2016-09-05
国家自然科学基金资助项目(61303230)。
王斌(1989—),男,硕士研究生,研究方向为网络安全中数据挖掘,E-mail:2781993753@qq.com
TP311.13
A
1671-8755(2016)04-0068-05
猜你喜欢
数学物理学报(2021年1期)2021-03-29
甘肃教育(2020年14期)2020-09-11
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
时代英语·高二(2015年1期)2015-03-16
