
基于因子分析和聚类分析的情感维度提取*
2016-04-15 05:10刘征宏潘伟杰
组合机床与自动化加工技术 2016年3期
刘征宏,潘伟杰,吕 健,林 丽
(贵州大学 a.现代制造技术教育部重点实验室;b.机械工程学院,贵阳 550025)
基于因子分析和聚类分析的情感维度提取*
刘征宏a,潘伟杰a,吕健a,林丽b
(贵州大学 a.现代制造技术教育部重点实验室;b.机械工程学院,贵阳550025)
摘要:为从大量用户情感维度(感性词对)中提取少量具有代表性情感维度(感性词对),文章提出结合因子分析(factor analysis, FA)和聚类分析(cluster analysis, CA)的情感维度提取方法。首先通过语义差分(semantic differential, SD)实验获取用户对少量具有代表性样品的情感认知;然后使用FA对SD结果进行分析,获得初始情感维度的潜在因子及因子载荷矩阵;最后根据FA结果进行聚类分析,对初始情感维度到每个聚类几何中心的距离进行排序,距离最近的感性词对即为所提取的情感维度。以数控机床造型设计为研究案例,对该方法进行描述,结果表明,该方法能有效提取情感维度,并保留了初始情感维度的整体结构。
关键词:因子分析;聚类分析;情感维度;感性词对
0引言
产品造型是决定消费者购买的最重要因素之一,因此对消费者主观认知也就是用户感性需求的研究是产品设计领域研究的热点与重点。只有获取用户真实的情感意象,设计师才能将其赋予在产品的结构、形态、材质、色彩上,从而满足用户的感性需求。
感性工学(kansei engineering, KE)将用户感性需求进行定量化描述,通过构建用户感性需求和产品造型的关系指导设计师进行产品设计,日本著名学者Nagamachi[1]将感性工学分为以下几个主要步骤:①选择样品;②收集初始情感维度;③提取代表性情感维度;④对产品进行形态分析;⑤用户感性评估;⑥利用智能计算技术(如神经网络、遗传算法、模糊逻辑等)探索用户偏好与设计元素之间的关系;⑦构建感性工学推论模型或专家系统,进行新产品设计或开发。无论是国外还是国内的研究都是集中在步骤⑥、⑦[2-5],而在步骤③提取代表性情感维度的研究非常少,其中具有代表性的有:Huang等人[6]结合设计结构矩阵对感性词进行聚类分析,首先将初始情感维度分成少量子集,然后计算子集之间的相关系数,再合并完全相关的子集,最终得到聚类结果;Wang等人[7]结合模糊层次分析法和模糊kano模型对用户感性需求进行了分析;Shi等人[8]运用粗糙集、关联规则对感性需求知识进行了挖掘。这些方法虽然都具有创新性,但没有对用户情感维度进行筛选,因此在处理用户情感维度时会造型信息冗余,从而导致计算量过大且结果不准确。
KE中的每一步都至关重要,而前期用户感性需求的获取更是整个KE模型构建成功的关键。FA作为特征提取工具是最常用的分析SD数据的方法,然而,FA并没有提供选择代表性感性维度的直接标准。因此本文通过FA结合CA对用户初始情感维度进行定量化处理,首先通过SD实验获得SD数据,然后对SD数据进行因子分析获得因子载荷矩阵,最后通过聚类分析获得代表性情感维度。实验结果表明该方法能很好地保留初始情感维度的完整性,即本方法所提取的情感维度包含了初始情感维度的所有信息。
1SD数据获取
1.1具有代表性的设计样品提取
从市场上选择不同款式的产品或者三维模型作为样品,然后排除那些特定用途或造型奇特的产品。为了减少受测者的心理负荷和简化实验过程,邀请设计专家组对剩下的样品使用KJ方法[9]进行分组。为了方便,使用样品照片进行操作,照片须表现产品的三维造型特征,每个测试者须具有从照片识别产品三维造型特征的能力。使用KJ法使所有的样品被分成合适的聚类群组。然后根据获得的分组结果构建相似度矩阵,再进行多维尺度分析(multidimensional scaling, MDS),通过应力系数确定维数,应力系数越小,拟合越好(一般小于0.05)。然后对MDS结果进行聚类分析,获得聚类树图。最后使用k-均值聚类法从分别从每个群组中选择一个代表性样品,本方法计算每个样品到其所属组几何中心的距离,距离最小的样品为这组的代表样品。
1.2准备最初的情感维度
在KE中,通常使用SD进行情感评估实验从而得到用户对产品的心理情感[10]。在人体工程学和心理学评估中通常使用意象或感性词汇对来描述用户对产品的情感[11]。因此,为了描述用户对产品的情感,需要收集大量的感性词,其步骤如下:
Step1:从杂志、产品目录、报纸等收集大量的感性词对,首先收集了超过100个感性词对来描述该产品。
Step2:通过专家组两轮的讨论,合并相近的感性词对选择其中更合适的,然后得到30组左右的感性词对。
1.3SD评估实验
为了获得关于产品造型设计的SD数据,让受测者对所提取的样品在5分量表下使用初始感性词进行评估。然后计算所有人对每个样品的感性评价平均值获得最终评价值。为了更有效收集评估数据,设计了一个友好的评估交互界面,如图1所示,使调查者的评估数据直接记录下来,简化了后续的处理过程。

图1 感性评估界面
2对初始情感维度进行因子分析
在传统SD研究中,根据个人、概念、尺度三种模式对用户响应进行分类。相似地,在KE研究中,SD实验结果可表示为三维数据矩阵m×n×r,其中m表示消费者数量(个人),n表示评估的产品样品数量(概念),r表示形容词数量(规模)。因为每个消费者评估相同的产品样品,所以本文只考虑n×r的二维数据矩阵,这个二维数据矩阵表示m个消费者的n×r矩阵的平均值。Coxhead等[12]指出为了对SD数据进行因子分析,概念和尺度必须尽可能数量多且种类多,因此,产品样品和最初情感维度的选择应该遵循这个原则。FA在SD数据中的应用是为了获取输入情感维度的潜在因子和因子载荷。因子载荷用于确定情感维度对潜在因子的影响程度。为了构建新的意象认知系统,须对提取的因子进行命名,并指定合适的意义。比如,Osgood[10]提出了三个著名的内涵维度,即评价(Evaluation)、潜在(Potency)、活动(Activity)(EPA),能解释广泛的尺度和概念,并且被频繁使用。Hsiao等[13]根据三个不同的目录从SD实验中提取了四个基本的情感维度,即趋势、情感、复杂、效能。
每一个情感维度可用少数潜在因子的线性组合加上每个情感维度的特殊因子表示。因子分析模型描述如下:
y1=λ11X1+…+λ1nXn+θ1
y2=λ21X1+…+λ2nXn+θ2
……………
ym=λm1X1+…+λmnXn+θm
(1)
在公式(1)中,n为潜在因子数量,通常小于m。X1,…,Xp为潜在因子。λij为Xj的相关系数,也就是第i个潜在因子的载荷,因子载荷用于解释情感维度对潜在因子的依赖程度。θ1,…,θp为每个相关情感维度的特殊因子。因子载荷结果λij构成因子载荷矩阵L如下:
(2)
在SPSS中使用FA对实验获得的SD数据进行分析。FA使用的一个关键问题是必须确定因子数量。载荷因子数量不同对所选择的情感维度影响也不同。选择主成分分析(principal components analysis, PCA)中的最大方差正交旋转法来测试因子数量从3到7的变化。通常根据所提因子的特征值和方差百分比确定因子数量,首先保留特征值大于1的提取因子,然后,根据所有因子的累积方差百分比选择合适的因子数。一般来说,所选因子数应该包括总方差的60%以上[14]。
在同一个因子下正载荷因子和负因子载荷的混合可能会造成主成分分析的解释问题并影响潜在因子的命名。为了简化感性词选择过程,必须对FA结果进行调整,因此,如果感性词主成分中具有负载荷因子,那么将其方向改变,不改变其因子载荷值。感性词主成分是指所有因子中载荷绝对值最高的。这种调整既保证了感性词方向的一致性,使它更符合人们的认知,又减少了感性词在因子空间分布的复杂性。
3对因子载荷进行聚类分析
通过FA获得了因子载荷矩阵,但FA并没有提供选择代表性感性维度的直接标准,一个简单直观的提取具有代表性感性词的方法是选择每个因子中因子载荷绝对值较高的,然而这个方法既忽略了感性词的全局结构,又忽略了其局部关系,因为被选中的感性词都是位于每个因子轴的极端。因此,为了提取代表性感性词对并尽可能保证其结构完整,须对FA结果进行聚类分析。
使用结合层次和非层次聚类方法的两阶段聚类分析FA结果。尽管聚类分析可使用很多算法如k-均值聚类、自组织地图、模糊聚类等,但都没有提供直接确定聚类数量的方法。为了确定合适的聚类数量,使用层次聚类和离差平方和法(ward法)。然后根据情感维度的因子载荷,使用标准k-均值聚类法构建同质群组。选择每个聚类中最接近中心位置的感性词对作为具有代表性的情感维度,因此,具有代表性的感性词对数量等于聚类数量,且由层次聚类决定。
4实例研究
以某企业某类型数控机床造型设计为研究实例,对本文所提方法进行验证。
4.1选择代表性样品
首先收集100多个数控机床样品,通过初步评估删除相似的和不适合的样本,然后邀请5个具有5年以上设计经验的专业设计师进行KJ方法实验,最终剩下40个设计样品被分成6组。为了确定最合适的维数,使用MDS将维数设置2-10,分别求其应力系数,当维数=6时,应力系数=0.03572为最小,故确定维数为6。基于MDS结果的40个数控机床产品Ward聚类树图如图2所示。为了选择每个聚类中最具代表性样品,进行K-means聚类,结果如表1所示。表1显示样品26 、23、38、27、5、6分别为每群组中最具代表性样品(加粗行)。

图2 40个数控机床产品的聚类树图

聚类样品距离聚类样品距离1260.9454270.943361.136251.032291.155301.109311.533331.150371.572550.844402.04180.9912231.015131.059161.03131.313171.054101.330351.62041.6063380.885111.690280.88991.794191.047660.793341.15020.795……71.449
4.2准备初始情感维度
经过初步筛选获得如表2所示的初始情感维度。

表2 初始情感维度
4.3因子分析结果
首先通过图1所示界面进行SD实验,然后根据前文所描述方法对SD结果进行因子分析,使用三个因子的因子载荷结果如表4所示。结果显示,提取的三个因子解释方差分别为72.4%、13.42%、7.6%,因子1的方差百分比超过了50%,总的累计方差百分比为93.76%,表明使用三个因子的FA结果是非常可信的。
使用Osgood提出的EPA三因子结构[14],根据感性词的解释能力对FA结果进行检验。日本学者在相关研究中,确定了一系列色彩意象词汇如色彩的美/丑、雅/俗等属于色彩的评价因子;色彩的动/静、明/暗、引人注目/不引人注目等属于色彩的活动因子;而色的强/弱、轻/重、男性化/女性化等则是色彩的潜在因子。借助此方法获得如表3所示的结果,因子1中有7个评价因子、2个潜在因子,其中感性词1既属于评价因子又属于潜在因子;因子2中2个评价因子、2个潜在因子、3个活动因子;因子3中有2个潜在因子。因此,总的来说,本文提取的三个因子具有典型的EPA三因子结构,使用这三个因子的因子载荷提取具有代表性感性词是可靠的。
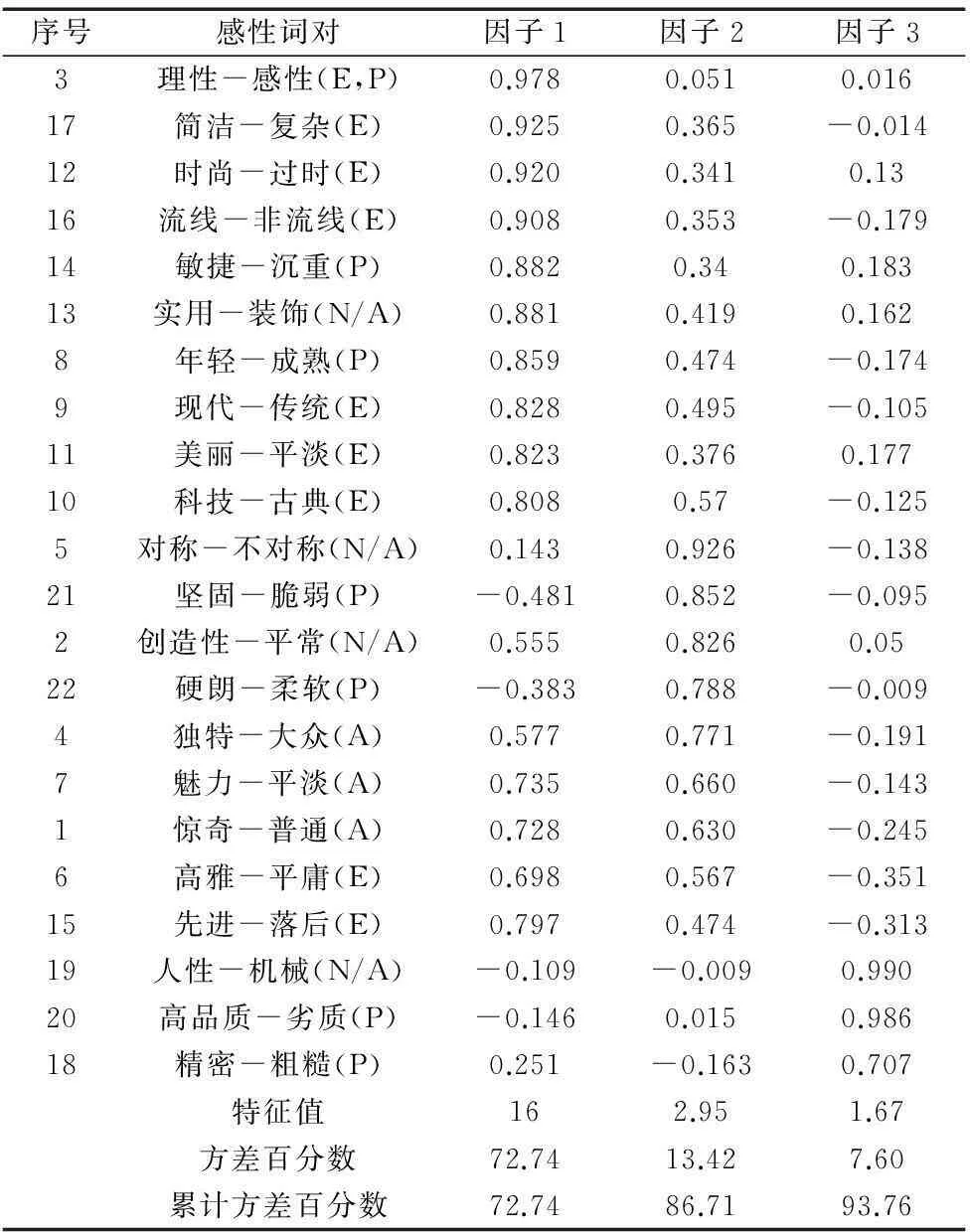
表3 22组感性词对的因子分析结果
4.4聚类分析结果
对初始情感维度因子载荷进行聚类分析,首先使用层次聚类的Ward连接方法确定聚类数量为4,然后使用K-means聚类把感性词分成4个聚类,使用平方欧式距离计算每个聚类的几何中心,并获得感性词与聚类中心的距离,结果如表4所示,结果显示,与每个聚类几何中心距离最小的分别是感性词22、19、17、4。图3更加直观地显示聚类分析结果,图3a为因子1-因子2空间的感性词聚类,图3b为因子2-因子3空间的感性词聚类,其中,○代表感性词,实心○为离聚类几何中心最近感性词,+代表每个聚类的几何中心。最终提取的四个情感维度分别为独特-大众(A)、简洁-复杂(E)、人性-机械(N/A)、硬朗-柔软(P),包含了EPA三因子的完整结构,为感性工学的下一步操作提供了可靠的基础。

表4 感性词对到每个聚类几何中心的距离


图3 Factor1-Factor2空间及Factor2-Factor3空间的
5结论
实验表明此方法能有效提取代表性情感维度,并保证了初始情感维度的完整性,为感性工学的下一步处理提供了可靠的基础。然而,如果聚类结果中同时存在两个或两个以上感性词到聚类中心距离相同或相近时,就很难确定此聚类的代表性感性词,因此,如何解决此问题是下一步研究的方向之一。另外,扩展本方法的应用对象也是下一步研究的重要方向。
[参考文献]
[1] Nagamachi M. Kansei engineering as a powerful consumer-oriented technology for product development[J]. Applied Ergonomics, 2002, 33 (3): 289-294.
[2] 石夫乾, 孙守迁, 徐江. 产品感性评价系统的模糊D-S推理建模方法与应用[J]. 计算机辅助设计与图形学学报, 2008, 20(3): 361-365.
[3] 傅业焘, 罗仕鉴. 面向风格意象的产品族外形基因设计[J]. 计算机集成制造系统, 2012, 18(3): 449-457.
[4] 苏建宁, 范跃飞, 张书涛,等. 基于感性工学和神经网络的产品造型设计[J]. 兰州理工大学学报, 2011, 37(4): 47-50.
[5] 苏建宁,王瑞红,赵慧娟,等. 基于感性意象的产品造型优化设计[J]. 工程设计学报,2015,22(1):35-41.
[6] Huang Y, C Chen,L P Khoo. Kansei clustering for emotional design using a combined design structure matrix[J]. International Journal of Industrial Ergonomics, 2012, 42(5): 416-427.
[7] Wang C,J Wang. Combining fuzzy AHP and fuzzy Kano to optimize product varieties for smart cameras: A zero-one integer programming perspective[J]. Applied Soft Computing, 2014, 22: 410-416.
[8] Shi F, S Sun,J Xu. Employing rough sets and association rule mining in KANSEI knowledge extraction[J]. Information Sciences, 2012,196: 118-128.
[9] Kawakita J. KJ Method[M]. Tokyo:Chuokoron-Sha, 1986.
[10] Osgood C E,SuciCJ. The measurement of meaning[M]. Urbana: University of Illinois Press, 1957.
[11] Nagamachi M. Kansei Engineering: a new ergonomics consumeroriented technology for product development[J].International Journal of Industrial Ergonomics, 1995, 15: 3-10.
[12] Coxhead P, Bynner J M. Factor analysis of semantic differential data[J]. Quality & Quantity, 1981,15: 553-567.
[13] Hsiao K A, Chen L L .Fundamental dimensions of affective responses to product shapes[J]. International Journal of Industrial Ergonomics, 2006, 36: 553-564.
[14] Kim J O, Mueller C W . Factor Analysis: Statistical Methods and Practical Issues[M]. Sage Publication, Newbury Park, 1978.
(编辑李秀敏)
Affective Dimensions Selection Based on Factor Analysis and Cluster Analysis
LIU Zheng-honga, PAN Wei-jiea, LV Jiana, LIN Lib
(a. Key Laboratory of Advanced Manufacturing Technology, Ministry of Education; b.School of Mechanical Engineering, Guizhou University, Guiyang 550025, China)
Abstract:To extract the representative affective dimensions from a wide range of affective dimensions, an approach for selecting the representative image word pairs based on factor analysis (FA) and cluster analysis (CA) was proposed. Firstly, consumer’s perceptions toward a small number of representative product samples were obtained using semantic differential (SD) method. Secondly, the latent factors and the factor loading matrix of the initial affective dimensions were extracted using FA according the SD results. At last, ranking the distance of the initial affective dimensions to the center of gravity of each cluster group based on the results of CA. The image word pair with the shortest distance to the centroid was selected as the representative of the cluster. Application process and procedure of the proposed method were described by a case of CNC machine tools design. The case study results revealed that the representative affective dimensions were selected effectively and the overall structure was preserved using the proposed approach.
Key words:factor analysis; cluster analysis; affective dimensions; image word pair
中图分类号:TH166 ;TG506
文献标识码:A
作者简介:刘征宏(1987—),男,湖南邵阳人,贵州大学博士研究生,研究方向为先进制造模式及制造信息系统、数字化设计与制造,(E-mail) zehoo_liu@163.com。
*基金项目:国家自然科学基金(51475097);国家自然科学基金(51465007);国家科技支撑计划(2014BAH05F01);贵州省科技计划(黔科合Z字[2013]4005,黔科合J字[2013]2108,黔科合LH字[2014]7644);黔发改投资([2012]2484);贵州大学基金项目(贵大人基合字[2012]009)
收稿日期:2015-12-03;修回日期:2015-12-08
文章编号:1001-2265(2016)03-0004-05
DOI:10.13462/j.cnki.mmtamt.2016.03.002
猜你喜欢
大经贸(2016年9期)2016-11-16
中国市场(2016年38期)2016-11-15
企业导报(2016年20期)2016-11-05
中国市场(2016年33期)2016-10-18
商(2016年27期)2016-10-17
商(2016年27期)2016-10-17
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
企业导报(2016年9期)2016-05-26
