
大数据分析的无限深度神经网络方法
2016-04-28 08:36张蕾章毅
计算机研究与发展 2016年1期
关键词:大数据
张 蕾 章 毅
(四川大学计算机学院机器智能实验室 成都 610065)
(leizhang@scu.edu.cn)
大数据分析的无限深度神经网络方法
张蕾章毅
(四川大学计算机学院机器智能实验室成都610065)
(leizhang@scu.edu.cn)
Big Data Analysis by Infinite Deep Neural Networks
Zhang Lei and Zhang Yi
(MachineIntelligenceLaboratory,CollegeofComputerScience,SichuanUniversity,Chengdu610065)
AbstractDeep neural networks (DNNs) and their learning algorithms are well known in the academic community and industry as the most successful methods for big data analysis. Compared with traditional methods, deep learning methods use data-driven and can extract features (knowledge) automatically from data. Deep learning methods have significant advantages in analyzing unstructured, unknown and varied model and cross field big data. At present, the most widely used deep neural networks in big data analysis are feedforward neural networks (FNNs). They work well in extracting the correlation from static data and suiting for data application scenarios based on classification. But limited by its intrinsic structure, the ability of feedforward neural networks to extract time sequence features is weak. Infinite deep neural networks, i.e. recurrent neural networks (RNNs) are dynamical systems essentially. Their essential character is that the states of the networks change with time and couple the time parameter. Hence they are very suit for extracting time sequence features. It means that infinite deep neural networks can perform the prediction of big data. If extending recurrent structure of recurrent neural networks in the time dimension, the depth of networks can be infinite with time running, so they are called infinite deep neural networks. In this paper, we focus on the topology and some learning algorithms of infinite deep neural networks, and introduce some successful applications in speech recognition and image understanding.
Key wordsdeep neural networks (DNNs); infinite deep neural networks; feedforward neural networks (FNNs); recurrent neural networks (RNNs); big data
摘要深度神经网络(deep neural networks, DNNs)及其学习算法,作为成功的大数据分析方法,已为学术界和工业界所熟知.与传统方法相比,深度学习方法以数据驱动、能自动地从数据中提取特征(知识),对于分析非结构化、模式不明多变、跨领域的大数据具有显著优势.目前,在大数据分析中使用的深度神经网络主要是前馈神经网络(feedforward neural networks, FNNs),这种网络擅长提取静态数据的相关关系,适用于基于分类的数据应用场景.但是受到自身结构本质的限制,它提取数据时序特征的能力有限.无限深度神经网络(infinite deep neural networks)是一种具有反馈连接的回复式神经网络(recurrent neural networks, RNNs),本质上是一个动力学系统,网络状态随时间演化是这种网络的本质属性,它耦合了“时间参数”,更加适用于提取数据的时序特征,从而进行大数据的预测.将这种网络的反馈结构在时间维度展开,随着时间的运行,这种网络可以“无限深”,故称之为无限深度神经网络.重点介绍这种网络的拓扑结构和若干学习算法及其在语音识别和图像理解领域的成功实例.
关键词深度神经网络;无限深度神经网络;前馈神经网络;回复式神经网络;大数据
自步入大数据时代伊始,大数据分析也应运而生.从数据源头到最终获得价值,大数据在信息系统中的生命周期一般经过“数据准备、数据存储与管理、计算处理、数据分析和知识展现[1]”5个主要环节,其中数据分析环节需要从“体量巨大(volume)、增长迅速(velocity)、类型多样(variety)”的大数据中发现规律、提取知识.只有经过了“数据分析”环节,才能获得深入的、有价值的信息,大数据的第4V特性,也是它的最重要特性——价值(value)才能够真正得以体现.因此大数据分析在大数据领域显得尤为重要,是“从数据到信息”的决定性因素.
大数据的4V特性也给大数据分析带来新的挑战.全球数字数据量以每2年翻番的速度增长,今年内将达到8ZB,相当于1800万个美国国会图书馆[2].从人手一部的智能手机到视频监控摄像头等传感设备,时时刻刻都在不断生成复杂的结构化数据和非结构化数据,且非结构化数据的增长速率比结构化数据更快.IDC2011年的调查中指出,在未来10年产生的数据中非结构化数据将占到90%.在人类全部数字化数据中,仅有一小部分数值型结构化数据得到了深入分析和挖掘,也就是传统的数据挖掘领域.网页索引、社交数据等半结构化数据在Google,Facebook等大型互联网企业得到了一些浅层分析(如排序等).而占数据总量75%以上的文本、语音、图片、视频、社交网络交互数据等非结构化数据还难以进行有效的分析[2].
传统的数据分析方法,根据随机采样的先验知识预先人工建立模型,然后依据既定模型进行分析.这种方法曾经有效,因为当时它的处理对象多是结构化、单一对象的小数据集[1].但在大数据环境中,它的固有弊端:依赖专家知识、无法迁移、精确性差等,已经凸显到无法忽视的地步了.因为占大数据主要部分的非结构化数据,往往模式不明且多变,无法获得先验知识,很难建立显式的数学模型,这就需要发展更加智能的数据挖掘技术.因此,大数据分析技术亟待在对非结构化数据分析方面取得突破,从海量、复杂、多源数据中提取有用的知识,这就是以深度学习、神经计算为代表的结合智能计算的大数据分析方法.
2006年,深度学习领域学术奠基人之一——加拿大多伦多大学Hinton教授,根据人脑认知过程的分层特性,提出增加人工神经网络的层数和神经元数量,构建深度神经网络(deep neural networks, DNNs),可获得优异的特征学习能力,并在后续一系列的试验中得以证实[3].这一事件引起学术界和工业界的高度关注,从此开启了深度学习研究和大数据应用的浪潮.今天,这股浪潮已席卷全球,而且还在持续升温.2014年12月在北京举行的2014中国大数据技术大会(BDTC 2014)暨第二届CCF大数据学术会议上,由中国计算机学会(CCF)大数据专家委员会和中关村大数据产业联盟主编的《中国大数据技术与产业发展白皮书(2014)》中,对2015年度大数据发展进行了十大预测,其中,“结合智能计算的大数据分析成为热点”位列十大预测之首.文中明确指出“大数据与神经计算、深度学习、语义计算以及人工智能其他相关技术结合,成为大数据分析领域的热点”.
以深度学习为代表的神经计算方法,以数据驱动、能自动地从数据中提取特征(知识)[4],对于分析非结构化、模式不明多变、跨领域的大数据具有显著优势.深度学习的实质是通过构建具有很多隐层的机器学习模型和海量的训练数据,学习更精准的特征,从而最终提高分类或预测的准确性.由于大数据的信息维度极为丰富,只有像深度神经计算模型这样更复杂、表达力更强的模型,才能够发掘数据中丰富的内在信息.因此,大数据分析需要深度学习.
1深度神经网络
神经网络隶属于人工智能领域的连接主义学派,是一种应用类似于大脑神经突触连接的结构进行信息处理的数学模型.20世纪50年代,第一代神经网络——感知机诞生[5],能够实现线性分类、联想记忆等;20世纪80年代,多层感知机及其训练算法——反向传播算法(backpropagation, BP)[6],因为能够解决线性不可分问题被广泛研究和应用.但是当时较为低下的硬件计算能力和网络训练算法易陷入局部极小等问题,成为制约神经计算方法发展的瓶颈,直到2006年Hinton教授开创的“多层结构、逐层学习”的深度学习方法[3],才使得神经网络的强大计算能力真正发挥出来,并在大数据的时代背景下成为大数据分析领域的一颗璀璨的明星.这种方法在语音识别、图像识别、自然语言处理等方面,已经取得了突破性的成功,以惊人的速度和结果,不断刷新着这些应用领域内的各种标志性纪录[4].
目前,在大数据分析中使用的深度神经网络主要是前馈神经网络(feedforward neural networks, FNNs).顾名思义,数据在这种网络中的流向是单向的:由第一层(输入层)流入,通过逐层(隐层)传递和映射,从最后一层(输出层)流出.网络的深度,即神经网络中神经元层次的数量.通过增加隐层的数量,各层以接力的方式进行原始数据的特征学习,本质上是在逼近原始数据与其特征之间非线性极强的映射关系.根据神经网络的一致逼近原理(universal approximation theory)[7],对于任意一个非线性映射,一定能找到一个浅层网络和一个深度网络以任意精度逼近它,只要浅层网络的隐层神经元个数足够多或者深度网络足够深.但通常,较浅层网络而言,深度网络只需要少得多的参数就可以达到与之相同的逼近效果.
一般的深度FNNs的拓扑结构如图1所示.当下应用最广泛的自编码网络(autoencoder)和卷积神经网络(convolution neural networks, CNNs)都属于前馈网络[8-9].
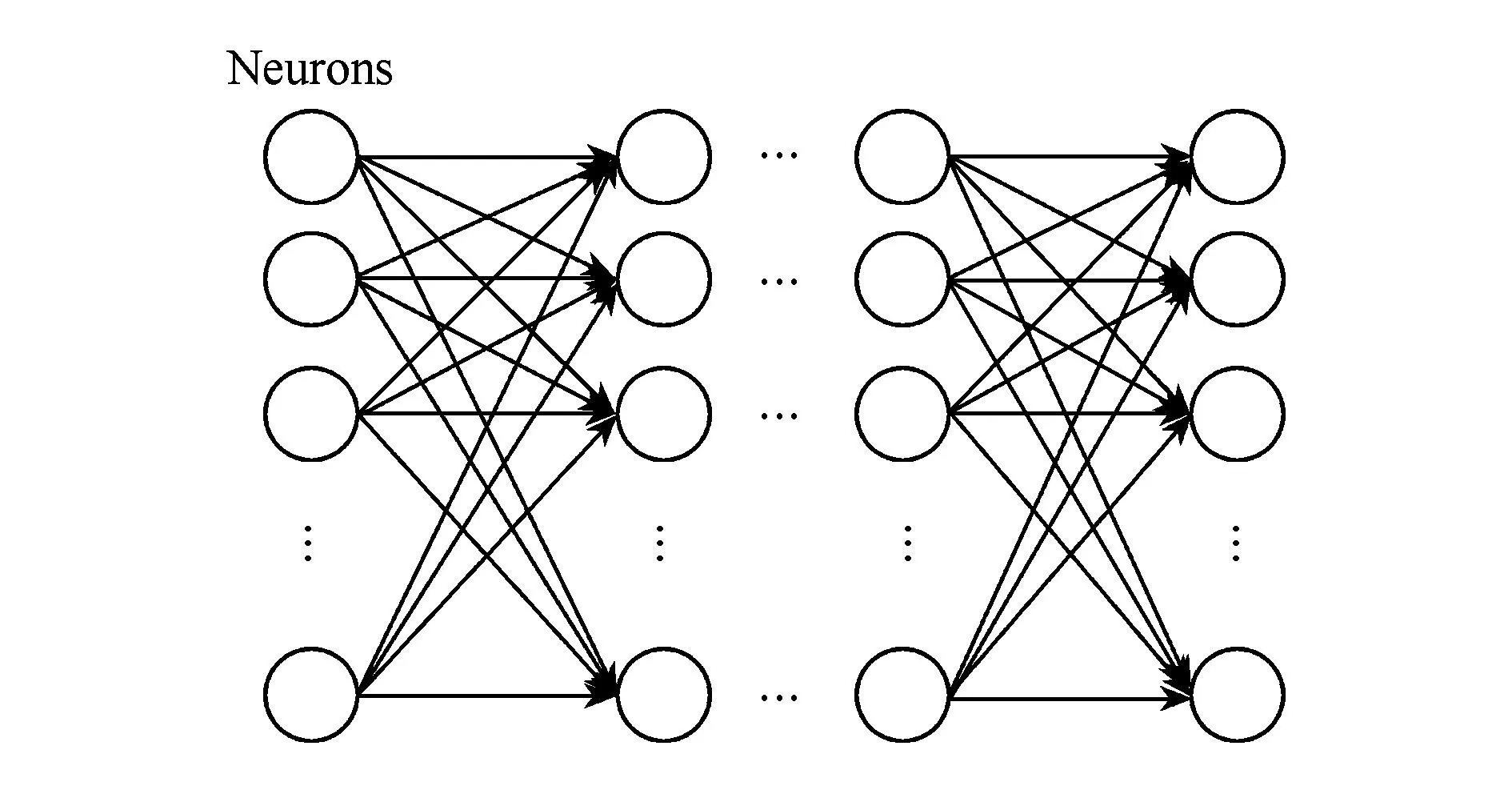
Fig. 1 The topology of deep feedforward neural network.图1 深度前馈神经网络拓扑结构图
2无限深度神经网络
目前,学术界和工业界所指的“深度神经网络”,通常指具有一定深度的前馈网络,前馈网络的特点是同层神经元之间没有反馈连接,没有“时间参数”属性,所以深度神经网络擅长处理静态数据.而“无限深度神经网络(infinite deep neural networks, infinite DNNs)”,是一种全互连的回复式神经网络(recurrent neural networks, RNNs),神经元之间存在反馈连接.将这种反馈结构在时间维度展开,随着时间的不断运行,网络可以“无限深”,在这个意义下,我们称回复式神经网络为“无限深度网络”.“无限深度神经网络”和“回复式神经网络”分别从2个不同的角度看待具有全互连结构的神经网络模型.使用“无限深度神经网络”名称时,表明我们是从网络计算的角度出发,着重研究网络的学习和训练方法;而采用“回复神经网络”时,我们意在强调网络中存在“反馈连接”,与不具有反馈连接的“前馈式网络”有明显区别.无限深度神经网络本质上是一个动力学系统,能够处理动态数据,即与时间相关的数据.
2.1网络拓扑结构
对无限深度神经网络中的每一个神经元而言,它的连接有3种:该神经元与所有的外部输入的连接、与其他所有神经元的连接,以及该神经元与自身的反馈连接.图2所示是一个具有3个神经元、2个外部输入的无限深度神经网络.

Fig. 2 Two structures of the completely connected RNN having three neurons and two inputs.图2 具有3个神经元和2个外部输入的无限深度神经网络拓扑结构图
一般地,假设一个无限深度网络有m个外部输入、n个神经元.令x(t)=(x1(t),x2(t),…,xm(t))T为网络在时刻t的外部输入,y(t)=(y1(t),y2(t),…,yn(t))T为时刻t的n个神经元的输出.显然,任意神经元k在时刻t+1获得的总输入sk(t+1)由x(t)和y(t)两部分加权组成.设w为网络的连接权值,是一个n×(n+m)的矩阵.不失一般性,可令w=[wU,wI],其中wU表示神经元之间的连接权值,wI表示神经元与网络外部之间的连接权值,则时刻t+1网络神经元获得的总输入为
(1)
其中,s(t+1)=(s1(t+1),s2(t+1),…,sn(t+1))T.而时刻t+1神经元k的输出为
(2)
其中,fk是神经元k的激活函数.

Fig. 3 Unroll a recurrent neural network and get infinite deep neural network.图3 将回复式神经网络在时间维度展开形成“无限深度网络”
为了便于分析,可以将无限深度网络的反馈结构在时间维度展开.假设一个无限深度网络N从时刻t0开始运行,每一个时间步网络N被展开成一个前馈式网络Ν*中的一层,网络Ν*中的每一层都有n个神经元,且与这一时间步的网络Ν具有完全相同的活动值.任一τ≥t0,网络Ν中神经元(或外部输入)j与神经元i之间的连接wi j被复制成网络Ν*中τ层神经元(或外部输入)j与τ+1层神经元i之间的连接wi j(τ+1),如图3所示.随着时间的不断运行,Ν*的深度可以“无限深”,在这个意义下我们称回复式神经网络为“无限深度网络”.
2.2与深度神经网络的区别
深度神经网络突出的特征学习能力使其特别擅长解决基于分类的各种识别问题,如语音识别、图像识别等.近年来,深度学习方法获得的各种标志性记录,多是在这些方面.分类是大数据分析的其中一个目标,而另一个核心任务是对数据未来变化的预测,换句话说,就是提取数据的时序特征.但是由于深度神经网络拓扑结构本身的限制,它提取动态数据时序特征的能力有限,可以通过“Bus Driver”问题为例说明这一点.
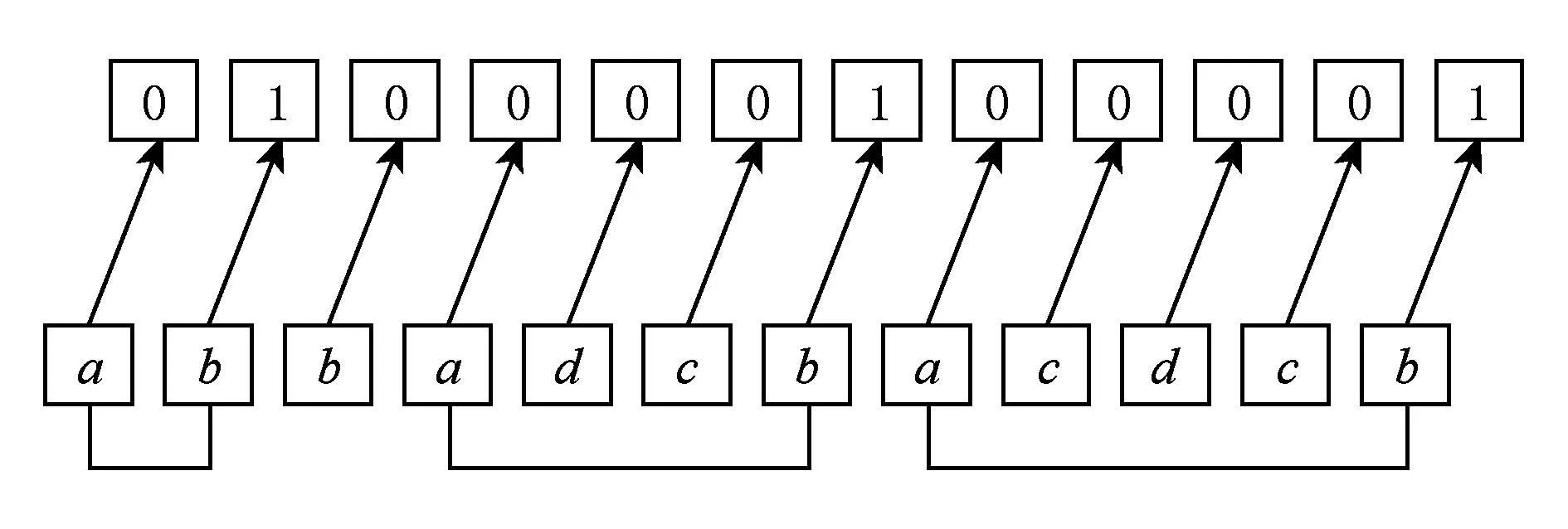
Fig. 4 Description of Bus Driver problem.图4 Bus Driver问题描述
“Bus Driver”是一个序列识别问题.它要求网络能够识别按照特定顺序发生的2个事件,无论中间的干扰事件有多少个.假设有a,b,c和d四个事件,一次输入一个事件,如果事件a之后出现了第一个事件b,网络就输出1,否则就输出0,如图4所示.这个任务的难点在于事件a和a之后出现的第1个事件b之间的干扰事件的个数是不确定的,因此网络必须要记住所有已经发生的事件.
前馈神经网络解决这个问题时,一般采用输入端引入抽头延迟线的方式,如图5所示,抽头延迟线以固定的窗口划分输入,当输入包含指定的序列时就输出1,否则输出0,但是因为延迟线的长度是有限且固定的,而事件a和a之后的第1个事件b它们之间的延迟是不确定的.因此,对于干扰事件的个数大于延迟线长度的序列模式,网络将无法正确识别,如图6所示.

Fig. 5 Using a sliding window to determine the input.图5 以固定的窗口划分输入序列
如本文前面所述,前馈网络不能完成Bus Driver这个序列识别任务,但是使用仅有2个神经元的无限深度网络却可以很好地解决这个问题.网络结构如图7所示,其中一个神经元可作触发器,另一个神经元的输出作为网络输出.网络有4个输入,在每一个时刻随机选取其中一个输入的值为1,其他输入的值为0,这就对应于a,b,c和d中的某一个字母,即一个时刻输入一个字母,输出规则为:如果a之后(可能经过多个干扰事件)出现了第1个b,网络就输出1,否则就输出0.
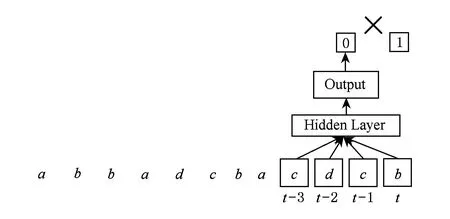
Fig. 6 FNN cannot solve Bus Driver problem.图6 前馈神经网络无法完成Bus Driver问题
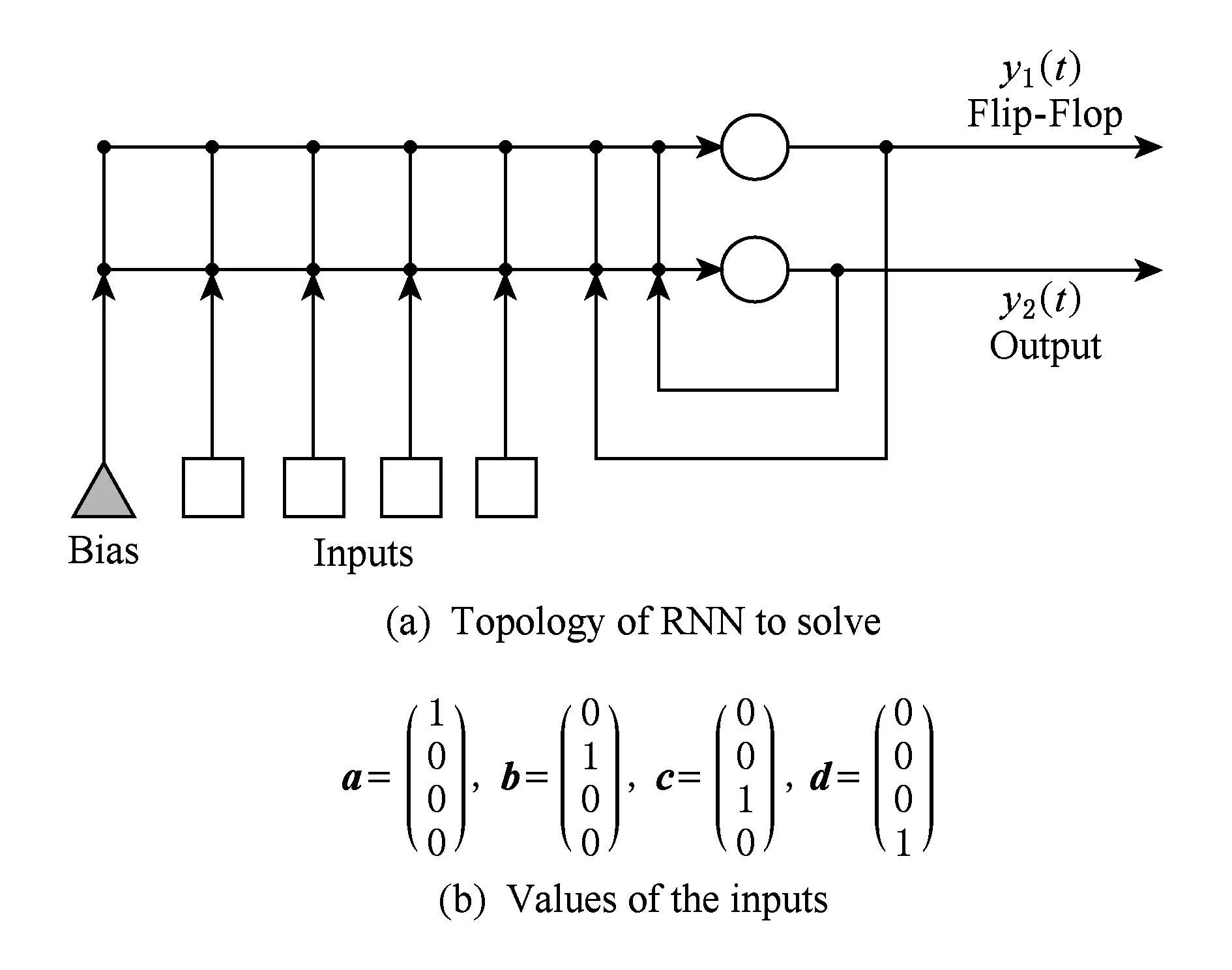
Fig. 7 Topology of RNN to solve Bus Driver problem and the values of the inputs.图7 解决Bus Driver问题的无限深度神经网络结构图和输入的值
“Bus Driver”问题的解决显示了无限深度神经网络的优势:
1)学习并记忆以往模式;
2)利用记忆对
当前事件作出判断;
3)在时间维度,自组织产生深度网络.
2.3学习算法
神经网络的计算能力,或者说“存储的知识”,是体现在神经元之间的连接权值上.因此,学习算法就是调节网络权值的方法,即:
(3)
权值调节的目标是使得网络学习到某种知识,完成某一计算任务.网络的计算任务通常量化为某种性能函数J(w)的优化.因此:
(4)

1) 性能函数
一般地,以一个有监督的序列学习任务为例,在任意时刻t,网络均有外部输入x(t)和目标输出d(t).用T(t)表示目标输出为dk(t)的神经元k的集合.那么,时刻t网络中神经元k的输出与目标输出之间的误差可表示为
(5)
网络在时刻t的性能函数可表示为
(6)
若假设网络运行的起止时间是t0和t1,则在时间段[t0,t1]内,网络总的性能函数为
(7)
事实上,这2种性能函数对应于2种训练方式:连续训练(continual training)和阶段性训练(epochwise training),2种不同的训练方式所具有的特点如表1所示:

Table 1 Difference Between Continual Training and Epoch-wise Training
虽然无限深度神经网络早在20世纪80年代就被提出,但因为它本质上是一种动力学系统,所以其训练比前馈网络更复杂,存在更大的困难.下文我们将介绍3种具有代表性的无限深度网络训练方法,它们各有特色.
2) BPTT学习算法
BP算法是训练前馈网络最经典的算法,也取得了巨大的成功.基于BP算法的思想,美国Northeastern University大学的Williams R J教授在1990年提出了能够训练无限深度网络的反向传递算法——BPTT (back-propagation through time)算法[10].
BPTT算法是经典BP算法的扩展,它首先按照2.1节所述的无限深度神经网络按时间步展开的方法变换为一个前馈网络,展开后的前馈网络每层具有相同的权值,且与原来的回复式网络权值相同,即对任意τ∈(t0,t],均有w(τ)=w.
根据阶段性训练和连续训练2种不同的训练方式,形成了Epoch-wiseBPTT和Real-timeBPTT两种算法,如下所述:
①Epoch-wiseBPTT
Epoch-wiseBPTT采用阶段性训练方式调整网络权值.采用该方式进行网络训练时,将用于无限深度神经网络训练的数据集分割成多个独立的“段”,每一段表示一个感兴趣的时序模式.假设某一个阶段的开始时刻是t0,结束时刻是t1.由表1可知,在该阶段的开始时刻t0,网络状态被重新初始化;在该阶段的结束时刻t1,网络权值进行更新;在[t0,t1]阶段内,网络的性能函数为
Epoch-wise BPTT算法的具体过程如下:
Ⅰ. 在时间阶段[t0,t1]内,对网络进行前向计算.
Ⅱ. 网络运行到该阶段的结束时刻t1时,通过性能函数对展开后的前馈神经网络中每一层权值wi j(τ)的偏导叠加,计算性能函数Jtotal(t0,t1)对权值wi j的偏导,其中τ∈[t0+1,t1],即:
(8)
运用链式法则可知:
(9)
使用Epoch-wise BPTT算法训练网络时,定义网络性能函数对神经元k的总输入sk的敏感度δk=∂Jtotal(t0,t1)∂sk,网络在某时刻τ对神经元k的注入误差定义为
易知,网络的性能函数Jtotal(t0,t1)与[t0+1,t]阶段内的输出y均有关.t0→t1前向计算的过程中,由于时刻τ网络的输出y(τ)=(y1(τ),y2(τ),…,yn(τ))T只对[τ,t1]的输出y产生影响,因此在误差回传的过程中,神经元k的误差δk(τ)只与由时刻t1传至时刻τ+1的误差δ(τ+1)=(δ1(τ+1),δ2(τ+1),…,δn(τ+1))T及时刻τ神经元k的注入错误ek(τ)相关.如图8所示,δk(τ)由时刻τ+1的误差δ(τ+1)和ek(τ)两部分组成.因此
(10)
网络性能函数在权值空间内的梯度为
(11)
Ⅲ. 误差反向传播到时刻t0+1时,更新网络的权值.
(12)

Fig. 8 Illustration of Epoch-wise BPTT.图8 Epoch-wise BPTT示意图
② Real-time BPTT
Real-time BPTT采用实时(连续)方式调整网络权值.假设网络运行起始时刻是t0,当前时刻是t.由表1可知,与Epoch-wise BPTT不同,Real-time BPTT没有阶段的概念存在,网络状态只有在运行起始时刻t0被重新初始化,且网络的权值不需要等到某一特定的时刻t1而是在运行中的每一时刻t都会被更新,网络的性能函数为时刻t的性能函数J(t).
Real-time BPTT算法的具体过程如下:
Ⅰ. 使用时刻t-1更新后的权值w,前向计算时刻t网络的输出y(t)=(y1(t),y2(t),…,yn(t))T.对展开后的前馈神经网络有wi j(τ)=wi j,其中τ∈[t0+1,t].
Ⅱ. 通过反向传播算法,计算性能函数J(t)对权值wi j的偏导,可以通过性能函数对展开后的前馈神经网络中每一层权重wi j(τ)的偏导叠加得到,其中τ∈[t0+1,t],即:
(13)
通过链式法则可知:
(14)

Fig. 9 Illustration of Real-time BPTT图9 Real-time BPTT示意图

与Epoch-wise BPTT不同,Real-time BPTT网络的性能函数J(t)只与时刻t的输出y(t)=(y1(t),y2(t),…,yn(t))T有关.t0→t前向计算的过程中,使用的是时刻t-1更新之后的权值w,由于时刻τ网络的输出y(τ)只对[τ+1,t]的输出y产生影响,因此在误差回传的过程中,δk(τ)只与由时刻t传至时刻τ+1的误差δ(τ+1)=(δ1(τ+1),δ2(τ+1),…,δn(τ+1))T有关,如图9所示.因此:
(15)
网络性能函数在权值空间内的梯度为
(16)
Ⅲ. 更新网络的权值:
(17)
3) RTRL学习算法
BPTT算法是基于反向传播算法的扩展,误差是从后向前传播的.与BPTT不同,RTRL(real-time recurrent learning)是一种前向传播“活动性”信息的算法.RTRL算法在20世纪80年代末被提出,该算法有多种不同的变形,分别由Robinson&Fallside[11],Bachrach[12],Mozer[13],Williams&Zipser[14]提出,本文针对Williams&Zipser提出的RTRL算法[15]进行讨论.
(18)
同样采用实时(连续)训练方式,网络在时刻t的性能函数为J(t),网络的权值在每一时刻都会进行更新.假设网络运行起始时刻是t0,当前时刻是t.由于yk(t)=f(sk(t)),因此网络的活动性信息由t0→t递归传递为
(19)
其中,如果j∈U,则z(t-1)=yj(t-1);如果j∈I,则z(t-1)=xj(t-1).
网络性能函数在权值空间内的梯度为
即:
(20)
同样,更新网络权值:
(21)
4) 传统无限深度神经网络的梯度问题

(22)
令uq=l,u0=k,可知:
(23)
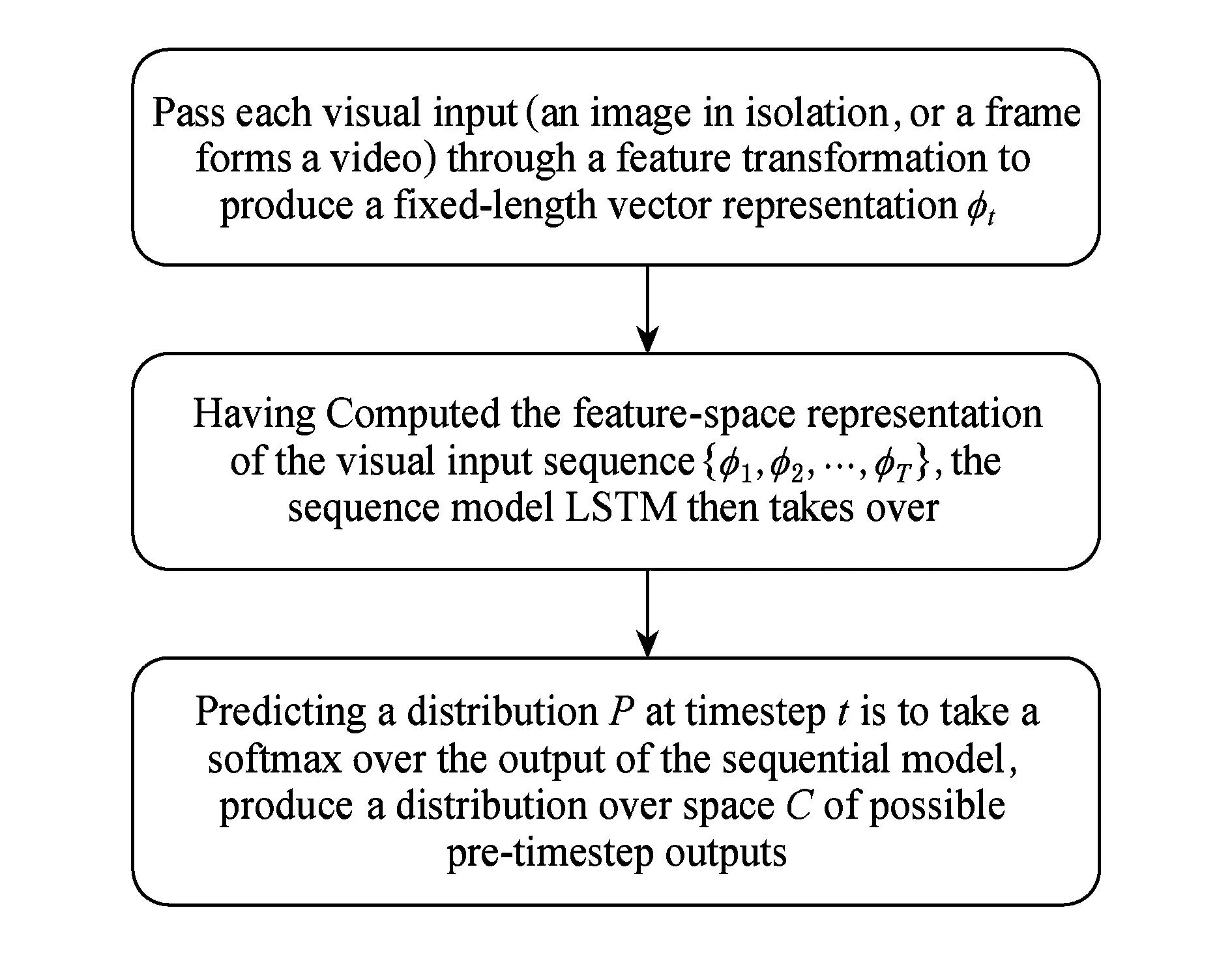
由于网络的激活函数是非线性函数(一般为S型函数),则0 5) LSTM学习算法 为了解决无限深度神经网络的“梯度消失”和“梯度爆炸”问题,瑞士人工智能实验室的Schmidhuber教授于1997年提出了“长短时记忆”(long short-term memory, LSTM)网络[16].之后又出现了LSTM的不同变形[17-18],本文主要介绍2000年Gers提出的改进LSTM算法[17]. Fig. 10 Illustration of LSTM.图10 LSTM示意图 由式(23)可知,如果网络的激活函数是非线性函数,随着q的增加网络均会出现“梯度消失”或者“梯度爆炸”问题,一种有效的解决办法是使用线性函数.图10(a)所示的网络结构可以解决传统无限深度神经网络梯度问题,称该神经元为CEC(constant error carrousel).但是由于其激活函数是线性的,因此学习能力有限,并且存在“输入输出冲突问题”,输入输出问题在Schmidhuber教授的论文“Long Short-Term Memory”中给出了详细的描述. Schmidhuber教授于1997年提出了“长短时记忆”(LSTM)网络很好地解决了这一问题.之后其学生Graves在此基础上对其进行发展,加上了Forget Gate.如图10(b)所示是LSTM的一个Memory Block,其中包括多个Memory Cell,多个Memory Cell由一组Gate(Input Gate, Output Gate, Forget Gate)控制.一个LSTM网络中可以包含多个Memory Block,不同的Memory Block由不同的Gate控制,同一个Memory Block的多个Memory Cell由同一组Gate共同控制.网络由:输入层、隐藏层、输出层3部分组成,其中隐藏层除了Memory Block外也可以包含传统无限深度神经网络中的神经元,隐藏层采用全连接的方式. 网络的训练采用BPTT和RTRL相结合的方式:输出层和Output Gate部分权值的训练采用BPTT的方式进行,Forget Gate,Input Gate及网络输入部分的权值采用RTRL算法进行更新.同时,为了减少网络学习的复杂度,采用了截断(Truncate)的方式进行,即时刻t的Memory Cell和Gate的输入{netc(t),netin(t),netout(t),netφ(t)}对时刻t-1网络隐层的所有输出不再敏感. 2.4在语音识别和图像理解的应用实例 2.3节中介绍的这些经典学习算法,虽然大多发明于20世纪90年代,但随着大数据浪潮的席卷而来,GPU等各种更加强大的计算设备的发展以及训练深层网络的新思路的提出[19-22],由于数据的极大丰富,这些无限深度学习的方法在实际应用中得到了飞跃性的发展.无限深度学习可以充分利用各种海量数据(标注数据、弱标注数据或者仅仅数据本身),完全自动地从海量数据中学习到数据中蕴含的抽象的知识表达,即把原始数据浓缩成某种知识.由于无限深度学习能够大大提高任务的准确度,在短短的几年时间里,无限深度学习已经颠覆了语义理解、图像理解、文本理解等众多领域的算法设计思路,渐渐形成了一种从训练数据出发,经过一个端到端(end-to-end)的模型,然后直接输出得到最终结果的一种新模式[23-29].本文中的无限深度神经网络具有提取时序数据的时空特征等重要特性,虽然其优化过程相对于深度神经网络更加困难,但是目前已经出现了BPTT,LSTM等很多解决方案和相关工作.另外,相较于基于前馈网络结构的普通深度神经网络而言,无限深度神经网络也因此在时序数据处理任务中展现出了更强大的计算能力和优势[23,30-31]. 以LSTM模型为例.在行为识别领域,基于LSTM的网络模型能够处理复杂的视频序列,并能够从传统的视觉特征或深度特征中学习动态的时序信息,进而对视频序列中的行为进行识别.在图像理解领域,LSTM模型能够在没有任何明确的语言建模和语法结构定义的情况下,学习将单张图像的像素强度映射成一个语法正确的自然语句,该语句能够正确地描述该图像.在视频理解领域,LSTM能够生成一个不定长的语句来正确地描述视频内容.通过实验验证该模型在序列学习以及时空特征的提取上都展现出较强的处理能力. Fig. 11 Task-specific instantiations for activity recognition, image understanding, and video understanding.图11 行为识别、图像理解,视频理解实例[31] Fig. 12 The flow chart of task-specific instantiations for activity recognition, image understanding, and video understanding.图12 行为识别、图像理解、视频理解3个应用的处理流程 文献[31]采用LRCN(long-term recurrent con-volutional network)模型在行为识别、图像理解、视频理解领域进行了研究并取得了较好的结果,如图11所示.利用该方法,该文作者首先利用卷积神经网络(CNN)提取静态图像的特征,但是对于行为识别、图像理解、视频理解等问题,更为复杂的任务是如何处理动态数据,然而类似于CNN,Autoencoder等前馈网络无法提取数据中包含的时序特征,仅仅依靠这类前馈网络无法实现该类复杂任务.因此,该文作者在利用卷积神经网络(CNN)提取图像静态特征之后,用长短时记忆网络(LSTM)提取时序特征.具体的处理过程如图12所示:1)将一张图像或者视频中的一帧输入到卷积网络中得到一个固定长度的特征向量;2)将经过卷积网络得到的特征序列输入到LSTM中学习数据的时序特征;3)预测出在每个时间步词表空间的概率分布,进而得到行为识别、图像理解、视频理解中每一帧图像的识别结果或内容.以图像理解为例具体阐述.该文作者在Flickr30K和COCO2014两个数据集上展开了图像理解研究,其中COCO2014包括有82 783张训练集图像、40 504张验证集图像及40 775张测试集图像.在图像理解任务中涉及的网络架构包括:1个卷积神经网络CNN(特征提取模块)和4个长短时记忆网络LSTM(序列学习模块),在第4个长短时记忆网络LSTM之后连接一个分类器.该实例中图像理解具体的过程如下:在时刻t,特征提取模块的输入是待处理的图像,序列学习模块的输入由卷积神经网络提取出的特征φt及时刻t-1得到的单词w(t-1)两个部分组成.对于序列学习模块,底层的长短时记忆网络LSTM的输入是时刻t-1得到的单词w(t-1);第2个长短时记忆网络LSTM的输入包含第1个LSTM的输出和卷积神经网络CNN提取的特征φt,其输出是得到两者的级联表达(joint representation);最后2个长短时记忆网络LSTM的作用均是对第2个LSTM的结果进行更高层次的表达.分类器的输入是第4个LSTM的输出,即产生词表空间中每个单词可能是当前时刻目标单词的概率P(wt|w1:t-1,φt),进而得到当前时刻的单词w(t).GoogleDeepMind团队成员Graves进一步发展了LSTM,并将其应用到了语音识别、人脸表情识别、手写体识别、序列标注、序列生成等方面[27-29,32-34].在语音识别任务中,由于无限深度神经网络能够记住上下文,而前馈网络只能处理当前帧,因此,无限深度神经网络的识别精度相对于多层感知机(multi-layerperceptron,MLP)等前馈网络更高,而且无限深度网络的抗噪性能更强.文献[35]将LSTM模型进行改进,更进一步将其用于并行处理大规模的语音序列.另外,在大词汇量的语音识别任务(例如Google英语语音搜索任务)中,LSTM的识别精度明显高于前馈网络.在更具挑战性的语义理解任务中,文献[36]利用LSTM模型直接翻译输入语句,以实现将英语语句翻译为法语语句的任务,并用实验表明LSTM相比其他语义理解算法能够取得更高的分数,其优势尤其体现在短句的理解与翻译.2009年基于LSTM模型构建的学习系统获得了未切分草书的手写体识别和语音识别任务的冠军,这是第1个无限深度学习系统赢得官方的国际比赛[37].在文本理解领域,无限深度网络能够按顺序处理一段话中的每个单词,在处理后面的内容时,无限深度网络的参数里还保留了前文信息的“抽象和整合”.由于其独特的记忆功能,无限深度神经网络已经被应用于文本理解领域[38-39]. 3总结与展望 近年来,基于回复式网络结构的无限深度神经网络计算方法得到了越来越广泛的关注,并迅速成为了研究的热点.2014年,谷歌的Sak等人利用无限深度神经网络解决了大规模词汇的语音识别问题[35],Sutskever等人将无限深度神经网络方法用于机器翻译上[36].今年,微软雷德蒙研究院的Mesnil等人将无限深度神经网络应用于口语理解问题[40];加州大学洛杉矶分校的Mao教授等人成功地利用无限深度神经网络方法产生图像标题[41];加州大学伯克利分校的Venugopalan教授等人将无限深度神经网络方法应用到了视频理解上面[42].百度的Deep Speech系统[43]也是基于无限深度神经网络的方法建立的,其在公开数据集Switchboard Hub5’00上的正确率达到了84.0%.由此可见,无限深度神经网络在处理时序数据方面具有巨大的潜力,在大数据分析预测任务中的强大计算能力日益显现.随着“结合智能计算的大数据分析”成为大数据时代的研究热点,无限深度神经网络计算领域更多新的理论和方法将被提出,其应用效果也必将不断被刷新,推动大数据分析技术的发展和革新. 参考文献 [1]White Paper on Big Data of the Telecommunications Research Institute of the Ministry of industry and Telecommunications(2014)[M]. Beijing: Telecommunications Research Institute of the Ministry of Industry and Information Technology, 2014 (in Chinese) (工信部电信研究院大数据白皮书(2014)[M].北京: 工业和信息化部电信研究院, 2014) [2]Intel IT Center. Big Data 101: Unstructured Data Analysis[MOL]. [2015-07-01]. http:www.intel.cncontentdamwwwpubliccnzhpdfsBig-data-101-Unstructured-data-Analytics.pdf, 2012 (in Chinese)(Intel IT Center. 大数据101:非结构化数据分析[MOL]. [2015-07-01]. http:www.intel.cncontentdamwwwpubliccnzhpdfsBig-data-101-Unstructured-data-Analytics.pdf, 2012) [3]Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507 [4] Yu Kai, Jia Lei, Chen Yuqiang, et al. Yesterday, today and tomorrow of deep learning[J]. Journal of Computer research and development, 2013, 50(9): 1799-1804 (in Chinese)(余凯, 贾磊, 陈雨强, 等. 深度学习的昨天、今天和明天[J]. 计算机研究与发展, 2013, 50(9): 1799-1804) [5]Rosenblatt F. The perceptron: A probabilistic model for information storage and organization in the brain.[J]. Psychological Review, 1958, 65(6): 386-408 [6]Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors[J]. Nature, 1986, 323(6088): 533-536 [7]Huang G B, Chen L, Siew C K. Universal approximation using incremental constructive feedforward networks with random hidden nodes[J]. IEEE Trans on Neural Networks, 2006, 17(4): 879-892 [8]Vincent P, Larochelle H, Lajoie I, et al. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion[J]. Journal of Machine Learning Research, 2010, 11: 3371-3408 [9]LeCun Y, Bottou L, Bengio Y. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324 [10]Williams R J, Zipser D. Gradient-based learning algorithms for recurrent connectionist networks, NU-CCS-90-9[R]. Boston, MA: Northeastern University, 1990 [11]Robinson A J, Fallside F. The utility driven dynamic error propagation network[R]. Cambridge, UK: Department of Engineering, University of Cambridge, 1987 [12]Bachrach J. Learning to represent state[D]. Amherst, MA: University of Massachusetts Amherst, 1988 [13]Mozer M C. A focused back-propagation algorithm for temporal pattern recognition[J]. Complex Systems, 1989, 3(4): 349-381 [14]Williams R J, Zipser D. A learning algorithm for continually running fully recurrent neural networks[J]. Neural Computation, 1989, 1(2): 270-280 [15]Williams R J, Zipser D. Experimental analysis of the real-time recurrent learning algorithm[J]. Connection Science, 1989, 1(1): 87-111 [16]Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780 [17]Gers F A, Schmidhuber J, et al. Learning to forget: Continual prediction with LSTM[J]. Neural Computation, 2000, 12(10): 2451-2471 [18]Gers F A, Schmidhuber J. Recurrent nets that time and count[C]Proc of the 2000 IEEE-INNS-ENNS Int Joint Conf on Neural Networks (IJCNN 2000). Piscataway, NJ: IEEE, 2000: 189-194 [19]Krizhevsky A. Convolutional deep belief networks on cifar-10[R]. Toronto, Ontario, Canada: University of Toronto, 2010 [20]Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]Proc of Advances in Neural Information Processing Systems 25 (NIPS 2012). 2012: 1097-1105. [2015-11-17]. http:papers.nips.ccpaper4824-imagenet-classification-w [21]Kustikova V D, Druzhkov P N. A survey of deep learning methods and software for image classification and object detection[C]Proc of OGRW2014. 2014 [2015-11-17]. https:kola.opus.hbz-nrw.de [22]Jia Y, Shelhamer E, Donahue J, et al. Caffe: Convolutional architecture for fast feature embedding[C]Proc of the ACM Int Conf on Multimedia. New York: ACM, 2014: 675-678 [23]Mnih V, Heess N, Graves A. Recurrent models of visual attention[C]Proc of Advances in Neural Information Processing Systems 27 (NIPS 2014). 2014: 2204-2212.[2015-07-01]. http:papers.nips.ccpaper5542-recurrent-models-of-visual-attention [24]Vinyals O, Kaiser L, Koo T, et al. Grammar as a foreign language[J]. eprint arXiv:1412.7449, 2014 [25]Meng F, Lu Z, Tu Z, et al. Neural transformation machine: A new architecture for sequence-to-sequence learning[J]. eprint arXiv:1506.06442, 2015 [26]Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks[J]. eprint arXiv:1503.00075, 2015 [27]Graves A, Mohamed A, Hinton G. Speech recognition with deep recurrent neural networks[C]Proc of 2013 IEEE Int Conf on Acoustics, Speech and Signal Processing (ICASSP). Piscataway, NJ: IEEE, 2013: 6645-6649 [28]Graves A. Generating sequences with recurrent neural networks[J]. arXiv preprint arXiv:1308.0850, 2013 [29]Graves A, Jaitly N, Mohamed A. Hybrid speech recognition with deep bidirectional LSTM[C]Proc of 2013 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU). Piscataway, NJ: IEEE, 2013: 273-278 [30]Weber M, Liwicki M, Stricker D, et al. LSTM-based early recognition of motion patterns[C]Proc of the 22nd Int Conf on Pattern Recognition (ICPR2014). Piscataway, NJ: IEEE, 2014: 3552-3557 [31]Donahue J, Hendricks L A, Guadarrama S, et al. Long-term recurrent convolutional networks for visual recognition and description[J]. arXiv preprint arXiv:1411.4389, 2014 [32]Graves A. Supervised Sequence Labelling with Recurrent Neural networks[M]. Berlin: Springer, 2012 [33]Liwicki M, Graves A, Bunke H. Neural Networks for Handwriting Recognition[G]Computational Intelligence Paradigms in Advanced Pattern Classification. Berlin: Springer, 2012: 5-24 [34]Graves A. Generating sequences with recurrent neural networks[J]. arXiv preprint arXiv:1308.0850, 2013 [35]Sak H, Senior A, Beaufays F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition[J]. arXiv preprint arXiv:1402.1128, 2014 [36]Sutskever I, Vinyals O, Le QVV. Sequence to sequence learning with neural networks[C]Proc of Advances in Neural Information Processing Systems 27 (NIPS 2014). 2014: 3104-3112. [2015-07-01]. http:papers.nips.ccpaper5346-information-based-learning-by-agents-in-unbounded-state-spaces [37]Graves A, Liwicki M, Fernandez S, et al. A novel connectionist system for improved unconstrained handwriting recognition[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2009, 31(5): 855-868 [38]Eugene L, Caswell I. Making a manageable email experience with deep learning[R]. Palo Alto: Stanford University, 2015 [2015-07-01]. http:cs224d.stanford.edureportsEugeneLouis.pdf [39]Graves A. Offline Arabic Handwriting Recognition with Multidimensional Recurrent Neural Networks[G]Guide to OCR for Arabic Scripts. Berlin: Springer, 2012: 297-313 [40]Mesnil G, Dauphin Y, Yao K, et al. Using recurrent neural networks for slot filling in spoken language understanding[J]. IEEEACM Trans on Audio, Speech, and Language Processing, 2015, 23(3): 530-539 [41]Mao J, Xu W, Yang Y, et al. Deep captioning with multimodal recurrent neural networks[J]. eprint arXiv: 1412.6632, 2014 [42]Venugopalan S, Rohrbach M, Donahue J, et al. Sequence to sequence-video to text[J]. arXiv preprint arXiv:1505.00487, 2015 [43]Hannun A, Case C, Casper J, et al. DeepSpeech: Scaling up end-to-end speech recognition[J]. arXiv preprint arXiv: 1412.5567, 2014 Zhang Lei, born in 1980. Professor and PhD supervisor. Member of China Computer Federation. Her main research interests include big data, recurrent neural networks, deep learning and machine intelligence. Zhang Yi, born in 1963. Professor and PhD supervisor. His main research interests include big data, neural networks theory and its applications, deep learning and machine learning. 中图法分类号TP183 基金项目:国家自然科学基金项目(61322203,61332002,61432012) 收稿日期:2015-07-16;修回日期:2015-11-18 This work was supported by the National Natural Science Foundation of China (61322203,61332002,61432012).




猜你喜欢
中国市场(2016年36期)2016-10-19
中国市场(2016年36期)2016-10-19
商(2016年27期)2016-10-17
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
