
短时间序列集的一种预测调和方法
2016-07-28 05:55伍仕屹
贵州科学 2016年3期
伍仕屹
(贵州大学理学院,贵州 贵阳 550025)
短时间序列集的一种预测调和方法
伍仕屹
(贵州大学理学院,贵州贵阳550025)
摘要:由于互联网以及大数据产业的高速发展,各行业产生了大量的短时间序列数据。因此,对这些数据进行分析进而预测其未来趋势成为了重要的生产和管理的手段。短时间序列以单个序列的观测数量少为特征,是时间序列分析的一个难点。如果预测对象是短时间序列数据集,就可以利用其总量的预测值去调节各分量的预测值。文章提出了一种时间序列的预测调和方法,并通过此方法去调节ARIMA模型对一个短时间序列数据集的建模预测结果,与ARIMA的预测结果相比,调和后的预测精度得到了提高。
关键词:时间序列,ARIMA,预测,调和方法
0引言
近年来,随着互联网的频繁使用和大数据产业的快速发展,新技术与新产品层出不穷,这使得许多企业在生产中产生了大量时间长度较短的数据,如何利用这些短时间序列数据产生价值就成了推进各行业发展的重要手段。经典时间序列分析方法是建立在数理统计的基础之上的方法体系,这就隐含了一个条件,即样本量是充分的。ARIMA模型[1]使用在很多历史数据充分的时间序列上都有很好的预测效果,在Engle、Granger、汤家豪等学者的完善下,时间序列的分析方法发展到了一个成熟的阶段。但在短时间序列分析方法的研究上的文献却很少,这也是因为短时间序列的特点造成了很难捕捉其规律性,在时间序列分析中数据信息的不足或缺失都一直是预测的一个难点。
而在现实生活中,特别是在企业的生产管理中,短时间序列的产生要比序列较长的时间序列普遍。一方面,在互联网高速发展下的信息时代,企业产品的生命周期缩短,这也促使生产和管理的周期被压缩;另一方面,收集长期且完整的时间序列数据要花费更多的人力资源和投入更多的技术以支撑,这增加了企业的成本。还有就是在预测对象更新换代较快的情况下,离现在时间较远的历史数据,其所含信息对现在的影响相对较小,利用价值不大,如果利用甚至还会造成错误的规律导向。因此,尽可能地挖掘出短时间序列的价值就成了各行业的一个迫切需求。
在实际生产中,短时间序列一般会大量出现,形成短时间数据集。比如,一家企业上市了一年的新产品,新产品的种类有几十种,产品的销量数据就会形成几十个短时间序列数据集;一个商家有几千个客户,每个客户在短期内的购买数据就会形成大量的短时间数据集。很多个短时间序列收集在一起,在一定程度上就弥补了单个短时间序列信息量少的缺点,在进行时间序列预测时我们就能通过数据集的形式对单个序列进行调和。
1经典时间序列分析理论
常用的随机时序分析方法分为平稳时间序列分析和非平稳时间序列分析,而平稳的时间序列模型包括自回归(AR)模型、移动平均(MA)模型和自回归移动平均(ARMA)模型;非平稳时间序列模型为求和自回归移动平均(ARIMA)模型,实际上ARIMA模型整合了平稳时间序列模型的特性,可以将平稳时间序列的三类模型看成是ARIMA模型的特例[2]。
1.1自回归AR模型
模型的结构如下:

(1)
称为P阶自回归模型,简记AR(p),即时间序列的现在值Xt可以表示为它的先前值和随机扰动项εt的线性组合函数。

当φ0=0时,自回归模型公式(1)称为中心化(AR)模型。非中心化AR(p)序列都可以通过平移变换转化为AR(p)序列。
引进延迟算子B(xt-1=Bxt),中心化(AR)模型又可简记为:
Φ(B)xt=εt
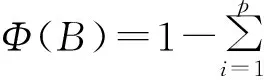
1.2移动平均(MA)模型
模型的结构如下:
(2)
称为q阶移动平均模型,简记(MA),即时间序列Xt是现在和过去的误差或冲击值εt的线性组合函数。
xt=Θ(B)εt
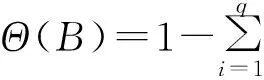
1.3自回归移动平均ARMA模型
模型的结构如下:
(3)
其中p,q分别为自回归移动平均的阶数,简记ARMA(p,q)[4],即时间序列值Xt是现在和过去的误差或冲击值εt以及先前序列Xt-1的线性组合。实数(φ1,φ2,…,φp)称为自回归系数,实数(θ1,θ2,…,θq)称为移动平均系数,特殊地,若p=0,此模型即为MA模型,q=0时,模型为AR模型。模型包含的限制条件与AR(p)相同。模型公式(3)的中心化形式为:
Φ(B)xt=Θ(B)εt
1.4求和自回归移动平均ARIMA模型
在总结前人研究成果的基础上,1970年Box和Jenkins联合出版了《Time Series Analysis:Forecasting and Control》[3]一书,开启了非平稳时间序列分析的篇章,书中系统地阐述了ARIMA模型,其模型结构如下[5]:
Φ(B)dxt=Θ(B)εt
2至上而下的预测调和方法
在实际生产中,短时间序列一般会大量出现,形成短时间数据集。比如,一家企业上市了一年的新产品,新产品的种类有几十种,产品的销量数据就会形成几十个短时间序列数据集;一个商家有几千个客户,每个客户在短期内的购买数据就会形成大量的短时间数据集。对一个短时间序列集,如果对其总量和每一个序列的预测值都进行预测,然后通过预测的总量对每一个序列的预测值进行调节,这就称为至上而下的调节方法[7]。对短时间序列来讲,由于信息量少,其表现出的规律很难被捕捉到,而收集的数据有时候还会出现缺失值或异常值的情形。对一个表现出相似规律的短时间数据集,相比较而言,其总量表现出的规律性会较单个序列明显,在一定程度上还能减轻缺失值或异常值所造成的影响。
以下是贵阳龙洞堡机场2014年4月各变电站用电量以天为时间颗粒度的时间序列数据及趋势图。
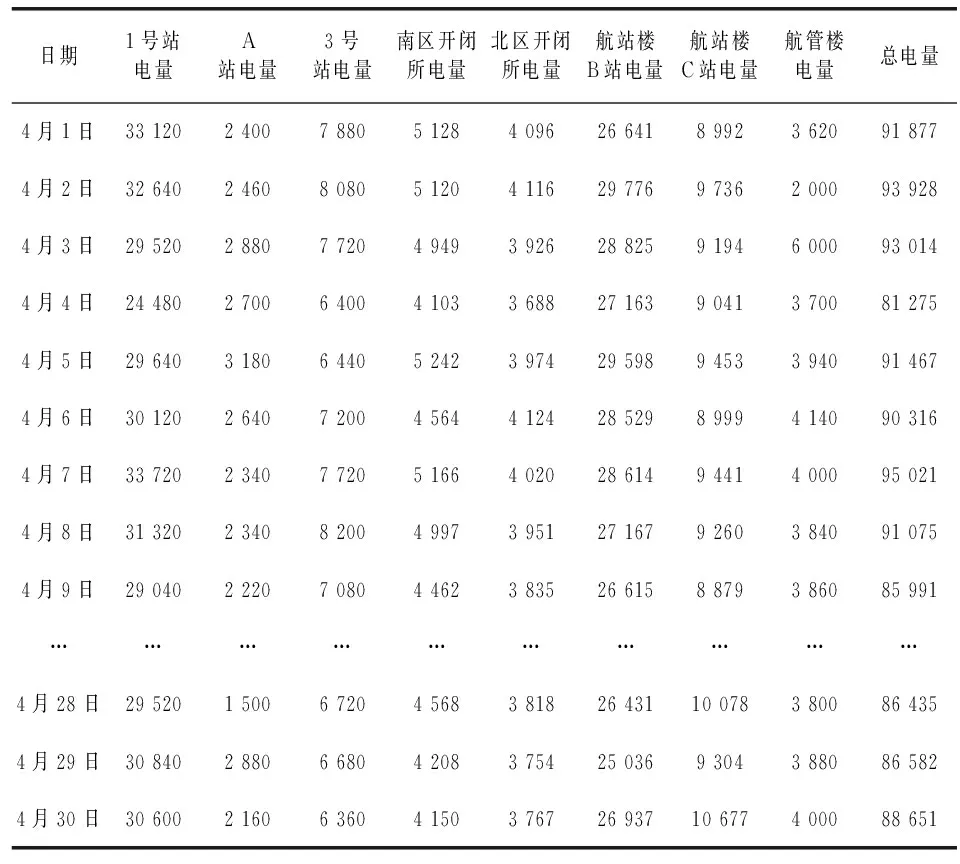
表1 各变电站4月电量数据
现用的ARIMA建模方法[6]对以上9个时间序列进行建模并预测,以4月1日到4月24的数据作为建模数据,用4月25日到4月30日的数据作为检验数据,以相对误差检验模型的精度。预测结果如下图1所示。

表2 ARIMA模型的预测结果

日 期南区开闭所电量ARIMA(0,1,1)北区开闭所电量ARIMA(0,1,2)航站楼B站电量ARIMA(0,1,1)真实值预测值相对误差真实值预测值相对误差真实值预测值相对误差2014/4/2543234204.990.02737274137.820.1102666728648.930.0742014/4/2643124170.610.03338754021.270.0382808128724.970.0232014/4/2738504136.230.07435994018.280.1172680128801.020.0752014/4/2845684101.850.10238184015.290.0522643128877.070.0932014/4/2942084067.470.03337544012.310.0692503628953.110.1562014/4/3041504033.080.02837674009.320.0642693729029.160.078平均相对误差0.050平均相对误差 0.075 平均相对误差 0.083
续表2

日 期航站楼C站电量ARIMA(1,1,1)航管楼电量ARIMA(0,1,1)总电量ARIMA(1,1,1)真实值预测值相对误差真实值预测值相对误差真实值预测值相对误差2014/4/251089911004.200.01039004327.870.1108829686313.120.0222014/4/261128211362.060.00738404357.360.1359223086188.930.0662014/4/271006511610.210.15438804386.860.1318399585999.570.0242014/4/281007811796.750.17138004416.350.1628643585787.060.0072014/4/29930411948.690.28438804445.850.1468658285566.300.0122014/4/301067712081.200.13240004475.340.1198865185342.630.037平均相对误差0.126平均相对误差0.134 平均相对误差0.028

图1 各变电站4月电量趋势图
从预测结果不难看出,不管是每个点的相对误差还是平均相对误差,总量预测效果都是最优异的,这符合之前提出的观点。下面介绍一种通过总量自上而下调节分量的方法,假设{X1,X2,…,XN}为一个时间序列集,{F1,F2,…,FN}为相对应的预测集序列,其中Fi=(fi1,fi2,…,fin)(i=1,2,…,N),Z=(z1,z2,…,zn)为总量所对应的预测值序列,{R1,R2,…,RN}为通过分摊比例调节后的预测集序列,其中Ri=(ri1,ri2,…,rin),则:
以上例来讲,X1为1号站在4月1日至4月24日的电量序列,F1为对应的4月25日至4月30日的预测值集,Z为总量在4月25日至4月30日的预测值集,R1就为1号站的原预测值集F1通过x2调节后的预测值集。
下面利用此调节方法对每一个变电站的电量预测值进行调和。调节的结果如表3。
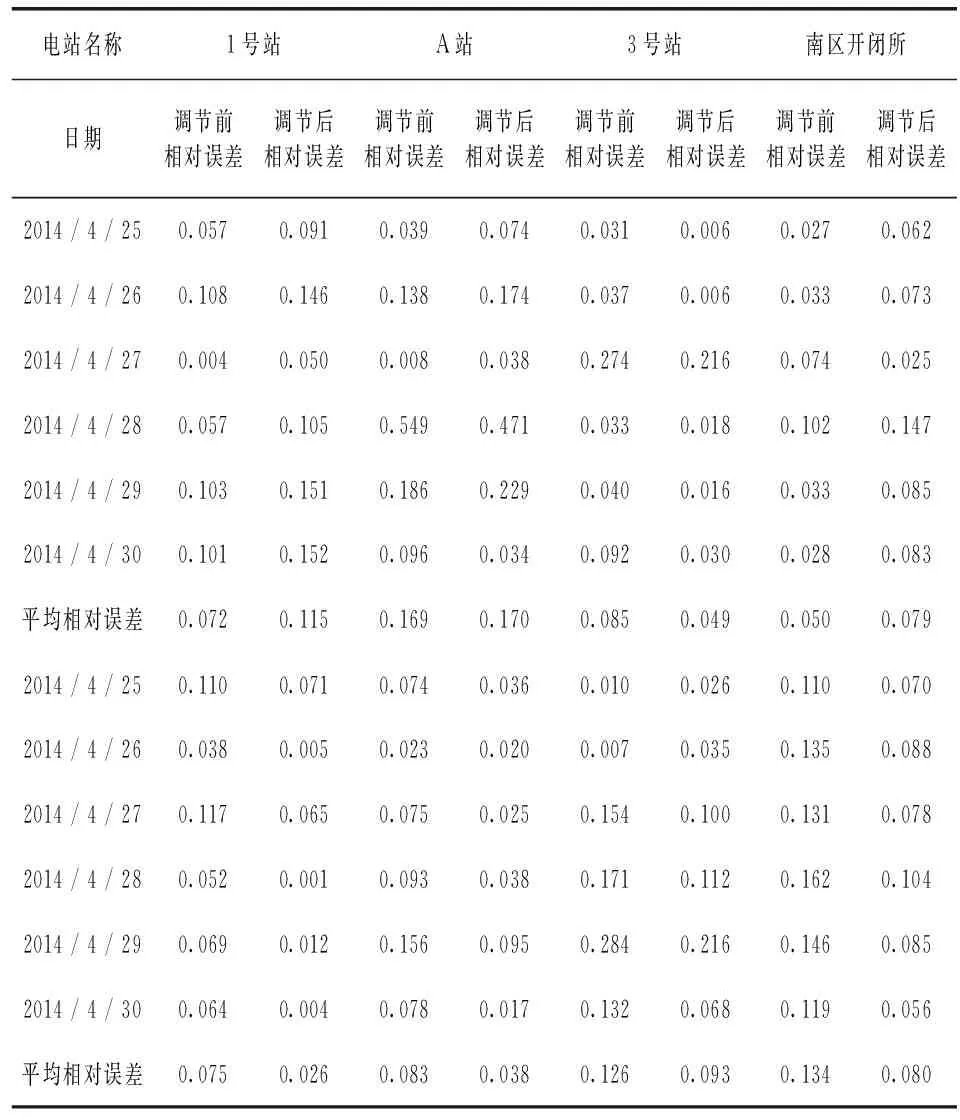
表3 调节前后的预测结果对比
通过观察前后的预测结果,在8个电站中,只有1号站和南区开闭所的平均相对误差有所提升,平均提升幅度为3.6 %,A站的预测精度基本保持不变,而其余的5个电站的平均相对误差都有较明显地降低,平均降低的幅度为4.3 %。此结果说明,自上而下的调节方法对预测的结果有明显改善。
如果短时间序列集的个数较多,比如有几百个甚至几万个,这时可以先将所有的序列按某种指标进行分类,然后再按照每一个分好类的序列集的总量对每个类的序列进行调节,例如,上例中可以将电量作为10 000 kW / h分类指标,则可以将产生电量大于10 000 kW / h的电站分为一类,小于这个指标的分为一类。这样做的好处在于,如果分类的方法切合序列的某一特性,那么每一种分类的总量序列就更能体现这一类序列的规律性,有利于在预测中捕捉其规律性,进而提升预测精度。在处理调节预测结果时,还会遇到序列出现多层级的关系[9],比如一种在全球都有销售的产品,从全球的范围到每一个代理商,中间会出现多个层级,这时对于预测对象来说,上层的个数就不止一个,要运用哪一个层级的总量去调节就要根据具体情况来选择。
3结束语
短时间序列以单个序列的观测数量少为特征,是时间序列分析的一个难点。无论是统计方法,还是数据挖掘的方法,都很难找到一个针对短时间序列预测的有效方法。而如果预测对象是短时间序列集,我们就可以利用其总量去调节单个序列的预测值,从而改善其预测精度。本文提出的时间序列预测的自上而下调和方法,在一定程度上能够提高短时间序列预测的精度,这种方法可以配合任何时间序列模型使用,具有良好的适应性。
在时间序列预测中,通过序列集的总量去调和分量的方法不只一种,本文所提到的分摊比例的方法是精准度较高和适用性较强的一种。根据序列和预测模型的不同特性还可以选择其它的调和方法,比如等分的调和方法[10]等。
参考文献【REFERENCES】
[1]王燕.应用时间序列分析[M].中国人民大学出版社.2005:41-207.
[2]张树京,齐立心.时间序列分析简明教程[M].清华大学出版社,北方交通大学出版社,2003:1-155.
[3]BOX G E P and JENKINS G M.Time series analysis:forecasting and control[M].San Francisco:Holden-Day,1970: 24-210.
[4]SPYROS M,MICHELE H.ARMA models and the Box-Jenkins methodology[J].Journal of Forecasting,1997,16(3):147-163.
[5]PASCUAL L,ROMO J.& RUIZ E.Bootstrap predictive inference for ARIMA processes[J].Journal of Time Series Analysis,2004,(25)4:449-465.
[6]BIANCHI L,JARRETT J,& HANUMARA T C.Improving forecasting for telemarketing centers by ARIMA modeling with interventions[J].International Journal of Forecasting,1998(14)497-504.
[7]CHATFIELE C.What is the “best” method of forecasting[J].Journal of Applied Statistics,1988(15)19-38.
[8]CHOLETTE P A.Prior information and ARIMA forecast-ing[J].Journal of Forecasting,1982(1) 375-383.
[9]CHOLETTE P A & LAMY R.Multivariate ARIMA forecasting of irregular time series[J].International Journal of Forecasting,1986(2) 201-216.
[10]GEURTS M D,& KELLY J P.Comments on:In defense of ARIMA modeling by D.J.Pack[J].International Journal of Forecasting,1990(6)497-499.
收稿日期:2016-03-11;修回日期:2016-03-25
作者简介:伍仕屹(1987-),男,贵州大学理学院数学系硕士研究生。研究方向:应用统计。
中图分类号:O01,O212.1
文献标识码:A
文章编号:1003-6563(2016)03-0056-05
A forecasting adjustment method for the set of short time series
WU Shiyi
(GuizhouUniversity,CollegeofScience,Guiyang550025,China)
Abstract:Along with the flourishing development of the industry of the Internet and Big data,the short time series data appears in various fields.Therefore,analyzing these short time series data and forecasting its future trend is crucial for our production and management.The short time series characterized by small amount data of single time series is difficult for time series analysis.However,the forecasting series is a set of short time series,and we can adjust the forecast results of single series through the forecast results of total amount data.In the paper,a forecasting adjustment method for time series is proposed with using the method to adjust the forecasting results through modeling a set of short time series by ARIMA model.The forecast accuracy has been adjusted for improving ARIMA model.
Keywords:time series,ARIMA,forecasting,adjustment method
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
时代金融(2016年27期)2016-11-25
电脑知识与技术(2016年26期)2016-11-25
商(2016年32期)2016-11-24
软件工程(2016年8期)2016-10-25
