
数据挖掘在图书馆管理中的理论与技术
2016-10-11 00:04邹昕
科技视界 2016年24期
邹昕
【摘 要】随着数据挖掘技术的发展,其应用领域也得到了进一步的拓展,图书馆的现代化建设也因此迎来了新的机遇,在图书馆文献管理过程中,每天都产生大量的读者借阅数据,合理地利用这些有价值的信息对图书馆的采购、馆藏、咨询等业务工作有着很大的指导作用。通过应用数据挖掘技术,图书馆管理者能够更加全面地了解读者访问图书馆的趋势和目的,进一步的改善图书馆系统的人性化服务,为图书馆现代化管理提供技术支持和决策管理支持。
【关键词】数据挖掘;图书馆管理;技术
1 技术背景
随着信息技术和计算机技术的向前发展,近些年信息量呈现爆发式增长,这些超大型数据库能够涉及社会的科学研究、政府部门、天文学、超级市场、行政办公、金融机构等领域,使得传统信息分析方法在一定得程度上不能满足现实的需求。在这种背景下,信息和知识的数据挖掘技术慢慢走入人们的视野。
2 课题研究意义和目的
图书馆作为学术性、科研性、服务性机构,在学校的教学及科研中承担着重要角色,迫切需要聚类分析、序列模式分析、关联分析、分类分析和概念描述等数据挖掘的技术对获取的信息做进一步的加工,以此来更好的发展图书馆管理业务。
文献管理集成系统能够很好的对文献信息资源进行资源共享、有效的开发、科学的管理,这些也恰恰是数字化图书馆建设的重要内容。
3 国内外研究现状
随着互联网技术的快速发展以及市场交易量的逐步扩大,数据挖掘系统的应用也越来越普遍。目前,数据挖掘系统的研究与应用主要集中在医药、天体、电信、零售、体育、营销分析、农业、生物、电力、化工和金融等行业。
在我国,国家自然科学基金对数据挖掘的研究提供支持是在1993年,自此之后,我国很多高等院校和科研单位相继开展发现知识的基础理论研究工作,参与的单位主要有:海军装备论证中心、空军第三研究所、中科院计算技术研究所、清华大学等。其中,在知识发现应用领域中应用模糊方法的研究单位有北京系统工程研究所;对数据立方体代数的研究单位有北京大学;对关联规则开采算法的改造和优化进行了深入研究的单位有华中科技大学、复旦大学、吉林大学、中科院数学研究所、中国科技大学、浙江大学等单位;对非结构化数据的Web数据挖掘以及知识发现研究的单位主要有上海交通大学、四川大学和南京大学等。
在图书馆领域方面,《中国学术文献网络出版总库》(国家“十一五”重大出版工程项目)的建设取得了很好的突破,“网上个人与机构数字图书馆”系统在2008上半年正式投入使用。“网上个人与机构数字图书馆”已经整合《中国学术文献网络出版总库》出版的国内期刊、本博硕士学位论文、会议论文、报纸文献、工具书和年鉴数目分别为9000多种、60多万篇、90多万篇、800多万篇、1600多种和2300多种,同时还整合了科技成果、标准、专利等各类资源。该体系是在知识管理系统(由清华大学开发)的基础上开发出的信息资源服务系统,能够自由定制多种个性化服务,为各类医务人员、公务人员、技术人员、科研人员、管理人员和单位服务,具有实时性、自动化、专业化、个性化的特点。
4 数据挖掘概念
数据挖掘就是从随机的、不完全的、模糊的、有噪声的、大量的应用数据中,挖掘出潜在有用的、事先不知道的、隐含在其中的知识和信息的过程。
从概念上来讲,与数据挖掘相近的有决策支持、数据分析和数据融合等。该概念可能包括的含义有:数据源必须是含噪声的、大量的、真实的;发现的知识是用户所感兴趣的;并不要求知识在任何情况都被人们所接受;发现的知识要可运用、可理解、可接受。
从本质上说,与传统的数据分析相比,数据挖掘可以理解为是在不带任何针对性的条件下去发现知识、挖掘信息,其挖掘出来的信息主要特征有三个,分别为可实用,有效和先未知。
5 数据挖掘的技术
在数据挖掘的过程中,需要采用一定的技术,常用的主要有:关联规则方法、统计技术、神经元网络、决策树和规则推理、连接分析、聚集检测、基于历史的分析MBR方法、遗传算法等。
5.1 关联规则方法
关联规则是数据库中某些特定事件一起发生的概率的简单陈述。运用一定的方法来发现数据库中隐藏的关联规则这个经过是关联规则挖掘。现在数据挖掘领域的研究中关键的一个方向是关联规则挖掘的研究。
5.2 统计技术
挖掘数据集利用统计技术,操作原则是针对已给的数据集合先预设一个概率的模型或者正态分布,后运用特定的方法挖掘模型。
5.3 神经元网络
因特网是由服务器互联形成,而神经网络是由诸多神经元互联形成的,两者形成原理较为相似。可以根据组织的特征或者“神经元”互联形成神经网络。
5.4 决策树和规则推理
类似于一棵树的预测模型是决策树。在决策树中,分布或者类的结果呈现在树叶上,每个属性上的测试结果显现在内部节点上,而每一个分类的问题是呈现在树的每一个分支上的。
5.5 连接分析
图论是其基本理论。找到一个能得出好而不完美结果的算法是图论的思想。这种思想模式可行虽然不完美,所以在更加广泛的用户群中可以使用这种模式。
5.6 聚集检测
聚类是对抽象对象或者物理的集合进行分组,让相似的对象形成若干个类。因此,对象的相似性存在于由聚类产生的数据对象集合中,而有别于其他集合的对象,存在相异性。可以依据对象的属性值来计算出相异度,通常的度量方法是距离。
5.7 基于历史的分析MBR方法
MBR先是从数据中找寻与其类似的数据,其次分类和估值类似的数据。通俗来讲,就是先依据经验找相似的,后根据找到的信息运用到新的数据中。
5.8 遗传算法
基于遗传机理的随机搜索与生物自然选择形成的一种仿生全局优化方法叫遗传算法,其可以在数据挖掘中运用,因为具备易于和其它模型结合、隐含并行性等性质。
6 数据挖掘的体系结构和基本过程
6.1 数据挖掘的体系结构
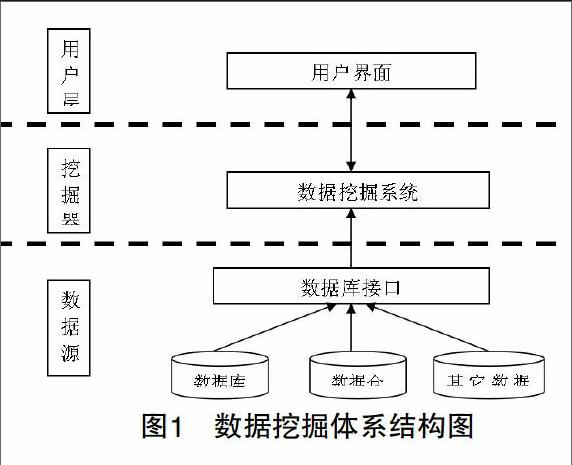
从大型数据库中挖掘出之前可实用的、未知的、有效的信息,并对信息做出丰富知识或者决策的整个过程是数据挖掘。一般来说,如图1所示,常用的数据挖掘系统可分三层。即数据源、挖掘器、用户层。在第一层中,数据仓库、数据库等属于数据源;第二层使用多种数据挖掘方法分析和提取数据库中的数据在数据挖掘系统中,满足用户需要;第三层是通过多种途径将发现的知识和获得的信息反馈给用户。
6.2 数据挖掘的基本过程
数据挖掘是一个从已知数据集合中发现各种模型、概要和导出值的过程。
数据挖掘过程是一个归纳的过程。其过程如下:
6.2.1 确定业务对象
数据挖掘中关键的一步是业务问题的明晰,从而摸准数据挖掘的目的。挖掘的最后结果具有不确定性。
6.2.2 数据准备
从与业务对象相关的所有内外数据信息中寻找并选择出合适的能应用于数据挖掘中的数据是数据的选择。数据挖掘成功的关键是建立一个真正适合挖掘算法的分析模型。
6.2.3 数据挖掘
数据挖掘就是挖掘得到结果转换的数据,其所有的工作是自动完成,除却选择适合的挖掘算法。
6.2.4 结果分析
对结果进行解释和评估。一般使用可视化技术,具体分析方法是根据数据挖掘操作来设定。
6.2.5 知识的同化
在业务信息系统的组织结构中并入分析得到的知识。
当前,作为一门新的学科,数据挖掘技术广泛应用于人工智能技术、数据库技术、模式识别、统计学、计算机网络与应用、信息检索、硬件与操作系统、计算机软件等诸多交叉学科中。目前数据挖掘的研究结果呈现多样性,有诸多成果研究完成,研究者们都是从某一角度去深入挖掘,到目前为止数据挖掘研究没有形成系统完善的体系。除此之外,算法的不高效是当前出现的一个重大的问题,因为数据库的规模、问题的背景、操作系统、编程语言等问题使得横向比较不能用在很多算法中。挖掘有用的知识是数据挖掘的目的,那么数据挖掘关键的研究点是如何创造高效挖掘。
[责任编辑:许丽]
猜你喜欢
电力与能源(2017年6期)2017-05-14
科技传播(2016年19期)2016-12-27
求知导刊(2016年30期)2016-12-03
中小企业管理与科技·上旬刊(2016年10期)2016-11-15
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
