
基于浮动车数据的公交车路线规划研究与实现
2016-11-08 08:36李建明
计算机应用与软件 2016年10期
林 娜 李建明
(沈阳航空航天大学计算机学院 辽宁 沈阳 110136)
基于浮动车数据的公交车路线规划研究与实现
林娜李建明
(沈阳航空航天大学计算机学院辽宁 沈阳 110136)
公交路线规划的传统方法主要是依靠人力调查,虽然这种方法被证明是可行的,但在这期间花费了大量的人力和物力。此外,这种方法也不适应城市的快速发展所导致的路网频繁变化。针对这种情况,根据收集到大量的出租车GPS数据,提出一种夜间公交车路线规划方法。主要包括三个部分:首先,在提取有效轨迹数据的基础上,找出聚集区确定候选车站集。然后,设定规则把复杂的候选车站集简化为有效公交车路线集。最后,提出两种算法选取最为理想的一条路线。结果表明,相关性启发式搜索算法得到的路线综合考虑候选车站间的相关性,是在规定时间内载客量最大的路线。
浮动车数据候选车站集公交车路线集相关性启发式搜索算法
0 引 言
在各个城市中,公交车出行是一种便利经济的出行方式,与其他出行方式相比而言,使用公交车出行更加绿色环保,因为它有助于减少交通拥堵,降低燃料消耗、出行费用以及尾气的排放。因此为了城市的可持续发展,鼓励人们尽量选择公交车出行[1-3]。白天的公交路线是由交通部门考虑各方面因素的基础上精心设计而成,然而在深夜,大多数公交车是不出行的,私家车和出租车成了主流的出行方式。为了给市民提供便利的交通条件,对设计出交通便利的公交车路线提出了需求[4]。现在公路上有到处可见的出租车,它们一般装有GPS设备和无线通信设备,从而可以收集到大量乘客乘坐出租车的GPS信息。通过这些GPS数据可以获得出租车的行驶路线、出发地、目的地、行驶速度、运行状态等[5]。如果对这些数据进行提取、分析、挖掘,就可以了解到人群的出行和流动规律,这就为规划出合理的公交车路线提供了可能性。
本文主要包括两部分:第一部分是候选车站集合的选取。因为乘客的上下车地点是随机分布的,但某些地点分布是相对集中的。这里没有提供一个明确的方式对这些地点标出,因此要寻求一个方法,通过GPS 的出租车轨迹集去寻找候选车站集。第二部分就是以出发地为起始点从候选车站集里筛选出合适的路线到达目的点。因为筛选出的候选车站很多且分布也很广,需要定义出很多规则提取从出发地到目的地有效的候选车站,使它们组成一个有向无循环的路径图,这样就把问题简化成在这个有向无循环图上找出使用时间、最少载客量最多的路径问题[6,7]。以前这方面的算法主要有手工统计方法和k-means方法等,本文提出了相关性启发式搜索算法(SXQ)和基于贝叶斯搜索算法(BYS)。它们结合了相关性算法和启发式算法的优点,能够准确方便找出理想的公交车路线。
1 技术路线
1.1数据的预处理
由于 GPS 卫星定位、大气层、操作错误和 GPS 设备等因素的影响,所获取的 GPS 原始数据存在较大的误差[8]。利用这种原始数据处理得到的交通信息质量必然较差,因此需要对原始的 GPS 数据进行预处理。现有的 GPS 数据预处理方法大多是针对 GPS 系统原理进行数据的识别与修复,将在此基础上充分考虑已有 GPS 数据特点和车辆运行状态进行数据优化,以达到更好的预处理目的。出租车GPS产生误差的原因很多,主要有:GPS设备故障,一段时间内返回相同数据,或者返回数据错误;障碍物遮挡信号,主要原因是被高层建筑物遮挡或者进入停车场或隧道导致信号中断;人为原因,出租车司机在短时间内重复打表,产生重复无效的数据;另外可能还有其他方面的原因,这里不再逐一列举。在筛选过程中主要针对:一是经纬度数据显示越界,本文用的是北京市地图数据,北京市的经纬度坐标范围是北纬39°28′~41°05′,东经115°25′~117°35′。所以,不在该范围内的数据,都是不符合要求的数据,应该予以去除。二是车辆静止。车辆静止需要对此类数据进行分析,将原数据排序,排序第一要素为车辆ID升序排列,第二要素为GPS时间升序排列,也就是将GPS瞬时速度持续为零的剔除。三是车辆持续空载,也就是车辆运营状态长时间静止或者空车运行。这部分数据也是没有意义的。另外就是短时间经纬度跳跃过大。通过投影计算,如果短时间行驶的距离过大,这部分是错误的数据[9-12]。
1.2确定候选车站
在夜间公交车路线规划过程当中,首先利用乘客的上下车记录数(PDR)确定候选车站集,整个过程包括三步:(1) 根据乘客的上下车记录数把整个城市划分成许多大小相等的网格单元,这些网格单元为以后的应用做准备;(2) 合并邻近的网格单元形成“热点“区域,如果区域过大则将其划分成合适大小的聚集区;(3) 然后在聚集区内找到一个合适网格单元作为候选车站,假设周围的地区能够容易到达这个候选车站。
1.2.1网格单元与城市划分
在这步工作中,把整个城市划分成许多大小相等的网格单元,每个网格的大小是100 m×100 m。用这个方法,整个城市总共被划分成6000×3000个网格。在所有的网格之外,超过95%的地方是没有出租车乘客上下车记录的,它们可能是湖泊、山脉、建筑物或高速公路,出租车不能到达或者停车,或者是城郊市民很少到这些地方。如果只记录深夜的时间段,这里面仅仅有0.11%平均每小时上下车记录数超过0.2,因此取名这些网格单元为“热点”网格单元。
每个网格单元最多和八个网格单元相邻。如果定义一个网格单元的连接度是连接周围网格单元的数量,则网格单元连接度的范围是0~8。网格单元连接度是0的称为独立网格单元。城市是由“普通“网格单元和“热点”网格单元混合组成,由“热点”网格单元和“普通“网格单元形成的区域分别叫做“热点”区域和“普通“区域,它们之间彼此连接在一起。这些“热点”区域也叫做城市分区。为了合理规划出公交车候选车站的地点,统筹安排城市分区,把靠近大的“热点”区域的小分区划分进去,下面提出一个简单的策略把彼此靠近的分区规划形成大的聚集区。
1.2.2聚集区的合并和分离
提出聚集区的合并和分离算法如下:
算法1聚集区的合并和分离算法
输入:分区列表 {Pi};
输出: 聚集区列表{Ci};
1:P<-sort(P) (i=1,2,3,…,n);
//按照它们的PDR数量进行分类处理
2:i=1 ;
//初始化
3: while(P≠φ) do;
4: Ci={P1};
5:P=P{P1};
//从P中把P1移除
6:k=|P|;
7:for j:=1 to k do;
8: if dist(Ci,Pi)
//我们设置th为150m
9: Ci=Ci∪Pj;
//合并靠近的分区,形成聚集区
10: P=P{Pj};
//从P中把Pj移除
11:end if;
12:end for;
13:i=i+1;
14:end while;
获取所有的城市分区后,根据乘客上下车的记录数量按照降序分类,反复迭代合并彼此靠近的分区。提出使用“热点”分区去吸收它附近的分区,直到附近没有合适的分区进行合并(8行),这样形成大的分区称作聚集区。这时选择下一个热点分区反复使用相同的程序直到所有分区全部遍历到(8行-12行),形成i个聚集区。每一个聚集区的候选车站地点的确定通过计算里面所有网格单元的平均权重来确定,使用式(1)计算。
(1)
其中,loc(gi)代表网格单元gi的经度/纬度,形成一个聚集区后,再吸收合并相邻的分区(10行)。直到没有分区被合并到此聚集区中,算法终结。然而,一些形成的聚集区面积可能太大,可以设置多个公交车候选车站,因此对大的分区要进行合适的划分。一般来说,形成的聚集区根据它们的大小被分为三组(聚集区的大小被定义为覆盖所有网格单元的最小矩形的面积):(1) 矩形的长和宽超过500 m;(2) 长或宽超过500 m;(3) 长和宽都少于500 m。只有少量的聚集区需要分割操作(大约10%)。在处理第(1)组聚集区时,在水平和垂直两个方向进行切割,将一个大的聚集区划分为几个小的聚集区。为了对出租车上下车的记录的影响降到最低,对于第(2)组聚集区只需要在水平或垂直方向上进行分割。
1.2.3候选车站地点的选择
经过合并和分割的操作,得到一定数量的面积小于500 m×500 m的“热点”聚集区,下一步是在聚集区内选择一个代表性的网格单元作为候选车站。
为了选择代表性的网格单元,要考虑聚集区内每个网格单元的连接度和出租车上下车的记录数。一个网格单元的连接度代表了这个网格的可达性,上下车的记录数代表了它的热点性。这个网格单元具有的最大权重根据式(2)进行计算,在每个聚集区内选择权重最大的作为聚集区中心,成为候选车站。设置ω1=ω2=0.5,最后得到579个公交车候选车站。
(2)
1.3公交车路线的生成
1.3.1产生公交车路线简图
从这些车站里选择合适的路线是非常复杂的过程,必须确保两个原则:一是确保路线经过所筛选的候选车站,二是能够在规定的时间内载到最大数量的乘客。如果直观地从起始点开始选择具有最大客流量的车站,这样一直选下去必然导致两个问题:一是公交车可能绕圈而无法到达终点,二是可能未在规定时间内载到最大数量的乘客。因此在车站选择时必须遵循以下几个规则:
规则1两车站的距离要合适:
dis(si+1,si)<θi=1,2,…,n
(3)
其中,θ是一个常数,代表相邻两车站不超过的最大距离,这里设定θ为2 km。
规则2保证公交车是向前行驶的:
χ(i+1)>χ(i)i=1,2,…,n-1
χ(i)=χ(i)cosθ+y(i)sinθ
(4)
本文所使用的坐标系为WGS84,式(4)代表公交车移动的两点在X轴上的投影的计算,保证公交车是朝着目的地行驶。
规则3公交车每一站要远离出发点:
dis(si+1,s1)>dis(si,s1)i=1,2,…,n-1
(5)
规则4公交车每一站都靠近目的点:
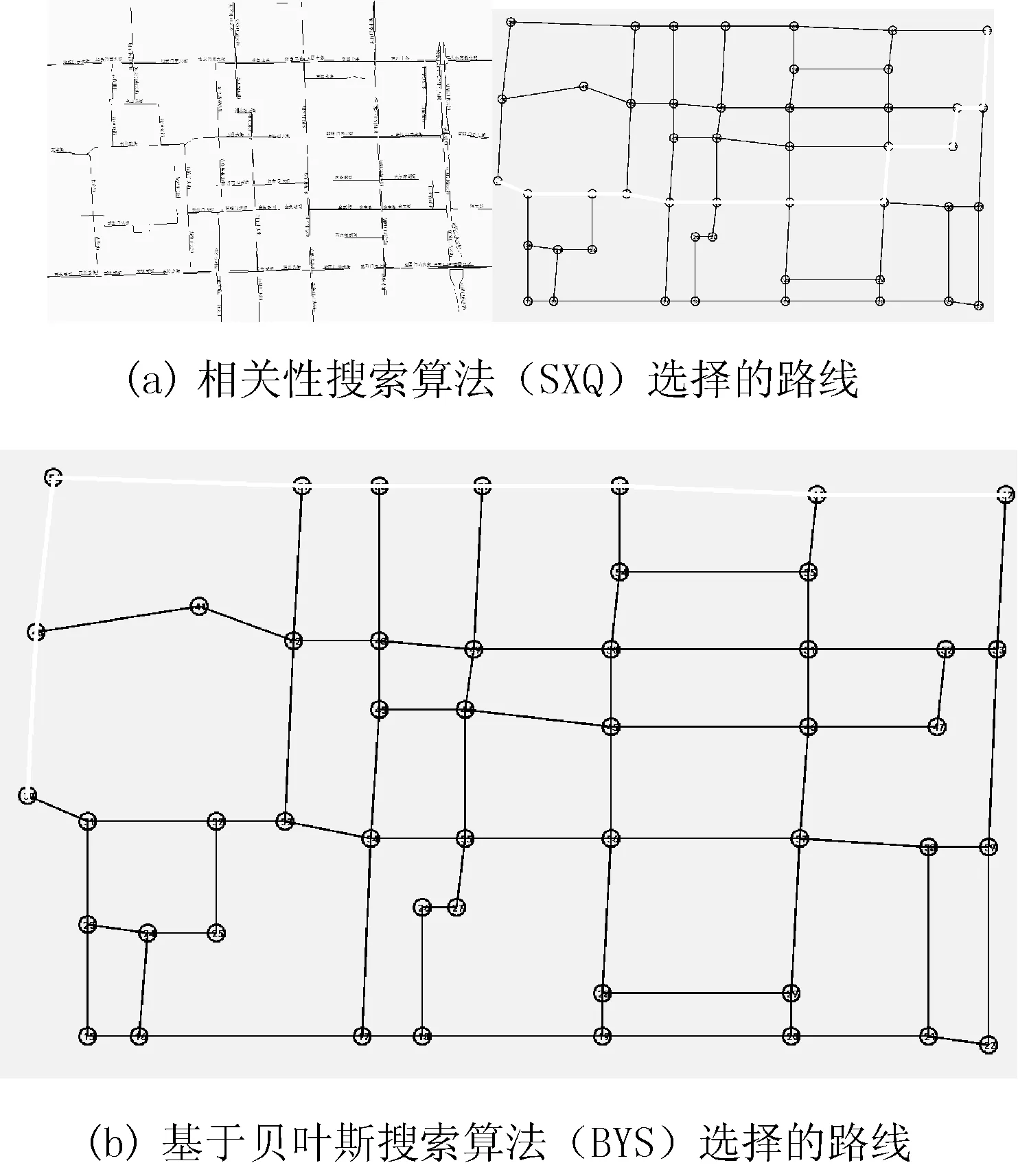
dis(si+1,sn) (6) 规则5保证候选车站的顺序整体向前,防止出现尖刻的“之”字形回路: argmin{dis(si+1,sj)}=sij=1,2,…,i (7) 式(7)确保所有车站投影在从前到后的一条直线上。 通过以上规则的筛选,得到了一个从出发点到目的点的有向无环图,如图1所示。另外,显然从出发地到目的地的有向路段要求每一个结点出度和入度都不为0,简化后如图2所示。 图1 候选车站简图 图2 公交车路线图 1.3.2生成公交车路线的方法 (1) 客流量和运行时间的估计 (2) 相关性启发式搜索算法(SXQ) 尽管通过定义的规则对图进行了修剪,移除无效的结点和边,但是若给定出发地和目的地,枚举所有可能路线也非常困难。事实上,没有必要枚举所有可能的路线然后比较它们,因为大多数路线是被少数路线所决定。 定义1Ri决定Rj的条件:1) T(Ri)≤T(Rj);2) Num(Ri)>Num(Rj)。 这里T和Num表示统计走过候选车站总的乘客累积量和总的运行时间,如式(8)、式(9)所示。 (8) (9) 其中,t0表示在候选车站间的停留时间,设为1.5分钟。主要目标是找出运行时间少、载客累积量多的理想路线,这里提出了相关性启发式搜索算法算法如下: 算法2相关性启发式搜索算法 输入:候选车站集、客流量矩阵 输出:起始地到目的地的公交车路线R* 1:R=∅ //开始为空集 2:Repeat 3:curR=s1 //起始地 4: Repeat 5:利用式(10)计算选取下一个应通过的车站。 //把要走的车站加入集合 //目的地 8: R*=R∪R //表示可能提取多条路线,得到路线集 9: 得到理想的路线集 R* 10:直到R*保持不变 (10) 定义2相似度表示两个集合的交集与并集的比值即: (11) 通过实验证明,对于给出任何一对确定的出发地、目的地(OD),当算法2连续执行到5000~15 000步时,两个集合的相似度逐步达到1,意味着理想路线逐步覆盖到1条,这就说明该算法是收敛的。为了和以分析内部相关性为主的算法2形成鲜明对比,下面提出了以整体相关性为主的基于样本的基于贝叶斯分类搜索算法。 (3) 基于贝叶斯分类搜索算法(BYS) 贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。也就是说,贝叶斯分类器是在最小错误率上的优化[13,14]。应用贝叶斯分类器进行分类主要分成两个阶段:第一阶段是贝叶斯网络分类器的学习,即从样本数据中构造分类器,包括结构学习和条件概率表学习;第二阶段是贝叶斯网络分类器的推理,即计算类节点的条件概率,对分类数据进行分类[15,16]。 在实验中提取大量候选车站的属性(FM和TM)构建一个训练集,然后根据这个训练集构建一个贝叶斯分类器,将该分类器作为判断选取下一个候选车站的依据。假设路网E中候选车站的属性集X={x1,x2,…,xn}(n>0)可以用来确定出经验上m个下一个候选车站集C={c1,c2,…,cm}(m>1),则由贝叶斯定理知: 其中,P(cj)为描述类别cj的先验概率, P(cj|X)为后验概率。判别函数gj(X)可以写成: gj(X)=p(X|cj)P(cj) (12) 基于贝叶斯分类搜索的算法如下: 算法3基于贝叶斯的分类算法 输入:候选车站集、训练集 输出: 起始地到目的地的公交车路线R* 1:R=∅ //开始为空集 2:Repeat 3:curR=s1 //起始地 4: Repeat 5:利用式(12)计算选取下一个应该通过的车站中的概率较大者 //把要走的车站加入集合 //目的地 8: R*=R∪R //表示可能提取多条路线,得到路线集 9: 选择过程中可能某几个车站概率一样,产生多条候选路线 10: 比较整条路线的总人数和总时间,选取性能较好者 该算法特点是:随着训练集的精度不断提高,数量不断增大,相似度越来越接近1,算法运行步数逐渐减少并趋向于收敛。但是构建出高质量的训练集还是一个比较困难的过程。 2.1实验基础 为了验证本文方法和算法的有效性和准确性,我们做了大量对比实验。实验采用Eclipse+ArcMap平台和Java语言来实现,根据真实的北京1万辆出租车共计200万条在一定范围内的两个月的出租车GPS数据来完成。 2.2候选车站筛选 用前文提及的方法筛选出的车站比单纯使用数据挖掘的方法好,例如经典的k-means方法。假设k的取值等于前面筛选出的车站数量即k=579,比较而言,本文方法有两个优势:首先,k-means的中心区域一般是随机分布在整个区域中,这样就带来了许多问题,可能落在一些不可达的区域,例如河流、树林等。用本文方法筛选出的是最好路段,以及路段中最好的人群聚集地。其次,使用k-means方法可能导致一些候选车站挤在一起或相邻候选车站的距离过大,然而用本文方法会让候选车站均匀分布在公交线路上。 2.3理想公交车路线选择 (1) 两种算法在现实中的比较 这里给定一个确定的出发地-目的地(文津街-工人体育场)。根据ArcMap生成的北京市地图,提取这个范围内所有候选车站的简图,在Eclipse搭建环境运行两种算法得到选择的路线,如图3所示。 图3 SXQ和BYS算法选择路线比较 两种算法主要都是对下一个车站进行选择,且两者都是以启发的方式逐个进行筛选。SXQ算法的优点是整体把握乘客的流动性,突出分析内部的关联性。BYS算法的关键是对样本训练集的选择,如果训练集选择数量少、精度不高,会导致算法的性能大大降低,这样也不是收敛的。如果选择的训练集数量巨大、精确度高,得到的结果很接近SXQ,这点非常困难。下面是提高训练集样本质量、数量后BYS得到的路线,如图4所示。 图4 提高训练集BYS得到的路线 (2) 两种算法统计分析 另外,实验还针对每一个OD对在100天内某个时间段内统计的结果求得均值,从运营时间和载客数量两个方面对两种算法进行了比较。 因为公交车夜间行驶速度不是一个主要的限制参数,所产生的时间差主要是由车站乘客上下车导致的,如图5所示。 图5 时间对比 两种算法人数的增加主要集中在中部车站,SXQ主要选择人数相对较多且距离适中的候选车站;而BYS算法在训练集条件的限制下,选择人数较为集中的候选车站,这样就导致车站间距离过大,可能使经过的车站数量相对较少,如图6所示。 图6 SXQ与BYS的对比 本文的目的是把先进的计算机技术应用到中小城市的公交车路线规划当中。因为提出的方法和取得的数据有一些缺陷,所以使得这项工作存在一些限制:首先,通过出租车GPS轨迹去分析整个城市人群的流动规律带有偏见且不完整的,在实际操作中也不能完全正确地反映出公交车的客流量。一些人可能由于各种原因不愿意乘坐公交车出行,这样就可能导致规划出的路线不是最好的。其次,在操作过程中,本文对某些公式或结论做了一些假设。例如,在选择候选车站时,乘客到达公交车站可接受的距离范围是500米,聚集区的合并和分离的临界参数是150米,显然这些参数的假设会影响到最终结果。但是因为现实中整体空间的限制,本文无法研究参数敏感度所带来的问题。最后,目前本文仅仅是探索给定确定的出发地和目的地的公交车路线问题,还不能整体考虑整个路网中公交车路线的规划。 在以后的工作中,将从以下几个方面拓宽和加深研究:第一,去做更多的实际调查,研究统计实际生活当中公交车的运行距离、运行频次以及容量等,为以后规划出更加理想的公交车线路做准备。第二,研究在操作当中改变某些参数对线路的影响,以及在线路的候选车站增加出租车叫车服务。第三,尽力把研究应用到更多城市的路径规划当中,为智慧城市的发展贡献一份力量。 [1] 李清泉,郑年波,徐敬海,等.一种基于道路网络层次拓扑结构的分层路径规划算法[J].中国图象图形学报,2007,12(7):1280-1285. [2] 钟慧玲,章梦,石永强,等.基于路网分层策略的高效路径规划算法[J].西南交通大学学报,2011,46(4):645-650. [3] 张照生,杨殿阁,张德鑫,等.车辆导航系统中基于街区分块的分层路网路径规划[J].中国机械工程,2013,24(23):3255-3259. [4] 胡继华,黄泽,邓俊,等.融合出租车驾驶经验的层次路径规划方法[J].交通运输系统工程与信息,2013,13(1):185-192. [5] 郑年波,李清泉,徐敬海,等.基于转向限制和延误的双向启发式最短路径算法[J].武汉大学学报·信息科学版,2006,31(3):256-259. [6] Yu Z K,Ni M F,Wang Z Y,et al.Dynamic Route Guidance Using Improved Genetic Algorithms[J].Mathematical Problems in Engineering,2013,2013:1-6. [7] Pan G,Qi G D,Wu Z H,et al.Land-Use Classification Using Taxi GPS Traces[J].IEEE Transactions on Intelligent Transportation System,2013,14(1):113-123. [8] Long Q,Zeng G,Zhang J F.Dynamic route guidance method facing driver’s individual demand[J].Journal of Central South University (Science and Technology),2013,44(5):2124-2129. [9] Castro P S,Zhang D Q,Li S J.Urban Traffic Modelling and Prediction Using Large Scale Taxi GPS Traces[C]//Lecture Notes in Computer Science (including subseries Lecture Note in Artificial Intelligence and Lecture Notes in Bioinformatics).Berlin:Springer,2012,7319:57-72. [10] Aslam J,Lim S,Rus D.Congestion-aware Traffic Routing System Using Sensor Data[C]//2012 15th International IEEE Conference on Intelligent Transportation Systems,2012:1006-1013. [11] 胡继华,钟广鹏,谢海莹.基于出租车经验路径的城市可达性计算方法[J].地理科学进展,2012,31(6):711-716. [12] 苏岳龙,路鹭,姚丹亚,等.经典交通流模型在城市车路不均衡发展评价中的应用[J].公路交通科技,2010,27(11):108-112,117. [13] 张红彦,赵丁选,陈宁,等.基于遗传算法的工程车辆自动变速神经网络控制[J].中国公路学报,2006,19(1):117-121.[14] 伊华伟.基于改进蚁群算法的机械手三维操作路径规划[J].计算机应用与软件,2014,31(4):302-304,307. [15] 周峰.基于Tent混沌粒子群算法的滚动窗口路径规划[J].计算机应用与软件,2013,30(5):76-79. [16] 李刚,马良荔,郭晓明,等.交互式拆卸引导装配路径规划方法研究[J].计算机应用与软件,2012,29(10):248-249,290. RESEARCH AND IMPLEMENTATION OF BUS ROUTE PLANNING BASED ON FLOATING CAR DATA Lin NaLi Jianming (SchoolofComputerScience,ShenyangAerospaceUniversity,Shenyang110136,Liaoning,China) Traditional way of bus route planning mainly depends on manpower surveys. Though this method has been proved to be feasible, a great deal of manpower and material resources are taken in this process however. What is more, such method does not adapt to the frequent changes of road network as the result of rapid urban development. To solve this problem, this paper proposes a method for night bus route planning according to the collected huge taxi GPS data. The method mainly consists of three sections. First, we find out the collection area to determine the candidate stations set based on the extracted effective trajectory data. Secondly, we set the rules to simplify the complex candidate bus stations set to the effective bus route set. Thirdly, we propose two algorithms to select the most ideal bus route. Result shows that the bus route derived from correlation heuristic searching algorithm takes the relevance among candidate bus stations into comprehensive consideration, and is the route with maximum passengers load within the set time. Floating car dataCandidate station setBus route setCorrelation heuristic search algorithm 2015-06-22。辽宁省高等学校优秀人才支持计划项目(LJQ2012011);辽宁省自然科学基金联合基金项目(2015020008)。林娜,副教授,主研领域:智能交通,无人机航迹规划。李建明,硕士生。 TP393 A 10.3969/j.issn.1000-386x.2016.10.060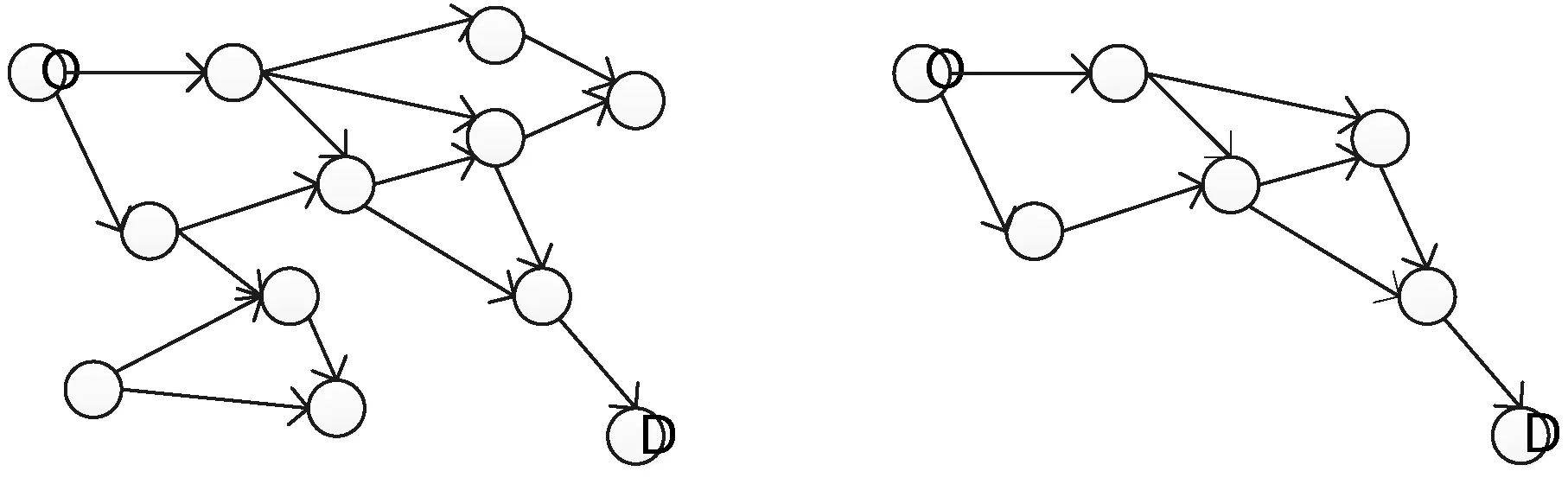



2 实验分析与比较



3 结 语
猜你喜欢
中小企业管理与科技·下旬刊(2022年3期)2022-06-16
数学小灵通·3-4年级(2020年10期)2020-11-10
今古传奇·故事版(2017年24期)2018-02-07
中央民族大学学报(自然科学版)(2017年4期)2017-06-11
铁道通信信号(2016年6期)2016-06-01
山东青年(2016年1期)2016-02-28
汽车观察(2016年3期)2016-02-28
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电子器件(2015年5期)2015-12-29
中国卫生统计(2015年4期)2015-03-09
