
一种新的子带声音强度参数及提取算法
2016-11-09 11:04田春环姜占才李小航
电子设计工程 2016年20期
田春环,姜占才,李小航
(青海师范大学 物理系,青海 西宁810008)
一种新的子带声音强度参数及提取算法
田春环,姜占才,李小航
(青海师范大学 物理系,青海 西宁810008)
为了使混合激励线性预测语音编码器(MELP)的应用更接近实际,提出了一种基于短时幅度与短时平均幅度差函数的子带声音强度提取方法。该方法根据MELP声码器解码语音的(MOS)评分得出最佳的线性组合系数,进而求出5个子带的清/浊音强度,并将其植入MELP声码器中。仿真实验表明,该算法不仅与原算法具有相同的效果,而且算法复杂度低。
清/浊音强度;短时幅度;短时平均幅度差函数;线性组合
高质量的低速率实时语音压缩编码技术始终是语音编码中重要的研究课题[1]。在2.4 kbps的速率上,美国国防部于1996年推出了新的美国联邦标准混合激励线性预测(MELP)算法[2]。该算法综合了LPC和MBE算法的优点,采用了分带LPC模型,并引入混合激励、非周期脉冲、自适应谱增强和脉冲散布滤波等技术。混合激励模型克服了二元激励合成模型中激励源信息描述不准确的缺陷,该模型采用子带清/浊音强度调制五带带通滤波器得到整形滤波器,从而得到较为准确的激励信息。MELP及其改进算法[3-14]虽然在合成语音的自然度和抗噪声性能等方面有了很大的改善,但其带通清/浊音强度最终都是通过求取自相关得到的。求取自相关过程中,乘法运算多、计算复杂,因此增大了处理延时。为了使混合激励线性预测语音编码器的应用更接近实际,本文提出了一种全新的子带声音强度参数及该参数的提取算法,该算法采用短时幅度和短时平均幅度差函数的第一最小值的线性组合表征子带清/浊音强度,并将其植入MELP声码器中进行了大量的仿真实验,实验结果说明该方法不仅与原方法的解码语音有相当的话音质量,而且运算速度快。
1 子带声音强度新参数
1.1 声音强度新参数提取的依据
为方便叙述,先对用到的字母作如下定义:N为帧长,w为矩形窗函数;xw(m)表示x(m)经过加窗处理后的信号,窗函数的长度为N;k为信号x(m)平移的移位量;m为当前帧。
1.1.1 短时幅度
语音信号的短时幅度定义为:

Mn也是一帧语音信号能量大小的表征,是标量,维数为1×1,它与短时能量的区别在于不论采样值大小,不会因取二次方而造成较大的差异,在某些应用领域中会带来一些好处。此外,短时幅度可以区分清音和浊音,因为浊音的能量要比清音的能量大得多。
1.1.2 短时平均幅度差函数
短时平均幅度差函数的定义为:

对于周期性的x(n),γn(k)也呈现周期性。γn(k)为矢量,维数为1×N。与短时自相关函数相反的是,在周期的各整数倍点上γn(k)具有的是谷值,而不是峰值。
图1中(a)为清音语音的短时平均幅度差函数;(b)为浊音语音的短时平均幅度差函数。从图中可以看出,短时平均幅度差函数谷值的大小相差比较多,所以可根据这一特点来判断是清音还是浊音。

图1 一帧语音信号短时平均幅度差函数
1.1.3 线性组合
用上述两个参数单一的提取带通清/浊音强度时,都得设置门限,若门限设置的不合理,则提取出的带通清/浊音强度会有误差。因此,可以将这两个特征参数进行线性组合。文中提出的带通清/浊音强度新参数提取算法的定义为:

其中,fd为每一子带的的短时幅度,fdc为每一子带的短时平均幅度差函数的最小值,α是一个插值参数,α的取值决定了带通清/浊音强度的好坏。而α参数无法事先确定,可能会选得过大或过小,况且信号是时变的。因此,求解此参数是一个逼近过程。
从语音库中取出一段语音(长度为10秒左右的句子),用MATLAB语言对这段语音进行编程,得到实验用MELP声码器。在实验环境下组织测试评听,评听人员预先不知道评听内容,测试小组由10人组成,其中6人是非专业成员,测试后,不同α取值下,基于参数的声码器解码语音的MOS得分曲线如图2所示。
1.2 新算法提取原理
MELP声码器在进行语音帧的清/浊音(U/V)判别时,将信号分为5个子带,提取带通清/浊音强度,分别进行U/V判决,用参数Vi(i=1,2,…,5)表示,其值大于0.6时表示浊音,小于等于0.6时表示清音。Vi代表各子带的声音强度,为一个五维的矢量。子带声音强度新参数提取算法原理如图3所示。
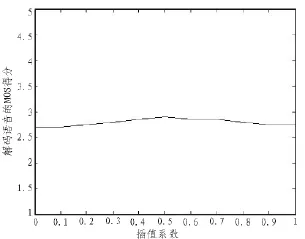
图2 插值系数α与解码语音的MOS得分曲线图

图3 新的子带声音强度提取算法原理图
将输入语音信号经过一个截止频率为100 Hz的高通滤波器,将低于100Hz频率分量的信号滤掉,滤波器输出的信号作为编码器的输入语音信号,其目的是为了防止50Hz电源噪声干扰。提取子带声音强度首先要将语音信号滤波分成5个频带,即用5个六阶Butterworth带通滤波器将输入语音分割为0~ 500Hz、500~1 000 Hz、1 000~2 000 Hz、2 000~3 000 Hz、3 000~ 4 000Hz5个子带,求得每一子带的短时幅度fd与短时幅度差函数fdc,fd为标量,fdc为矢量,为能把两特征值直接进行组合,必须使两特征值的维数一致,因此,求fdc矢量中的最小值,用求得的最小值与短时幅度进行线性组合得到子带声音强度;组合系数根据插值系数α与声码器解码语音的MOS评分得出。
2 算法仿真实验
2.1 实验方案
仿真实验分两组进行:1)对同一语音样本,在一定的信噪比(18 dB)下,分别用新参数提取算法和原提取算法进行仿真实验;2)对同一语音样本在不同信噪比(10 dB和7 dB)下,分别用新参数提取算法和原提取算法进行仿真实验。
2.2 实验材料(语音样本)
实验用语音样本取自笔者导师建立的语音库。其语料为短句、词汇和长篇文章,用正常的语速朗读、在实验室环境下录制,输入计算机转换为8 kHz采样、8 bit量化、线性PCM编码的数字语音。语音库大小为186 MB。实验室用的语音样本是从语音库中挑选的短句,加入高斯白噪声后形成带噪的语音。实验用语音样本帧长、帧移均为160点,帧间无重叠。
2.3 实验程序
对新参数提取算法按图3的算法原理用matlab语言编程,以文件名xvbp.m存储;同时,对原算法编程,以文件名yvbp.m存储;在计算机上仿真实验。通过客观波形显示和算法复杂度分析,评价算法的实际效果。
2.4 应用仿真实验
实验选择标准的MELP声码器(软件),只将其中的提取子带清/浊音强度部分置换为文中提出的新参数提取算法,其余部分保持原样,分别得到两个实验用声码器(软件),编程,分别以文件名xmelp.m和ymelp.m存盘。通过显示原始语音、含噪语音、原声码器解码语音与新算法得到的解码语音的波形,观测效果。
部分实验结果如图4和图5所示。图4是同一段语音在信噪比为10 dB时,原提取算法与新提取算法的应用实验结果。结果显示,对信噪比为10分贝的含噪语音,新提取算法与原提取算法得到的解码语音波形几乎一致。图5是同一段语音在信噪比为7 dB时,基于两种算法的应用实验结果。结果显示,对信噪比为7 dB的含噪语音,新提取算法得到的解码语音波形几乎逼近原提取算法得到的解码语音波形。通过语音波形的客观比较,可以看出,新提取算法与原提取算法的解码语音具有相同的效果。且新提取算法得到的解码语音可懂度和自然度较高。
2.5 算法复杂度分析
原提取子带声音强度算法的运算量很大,其原因是乘法运算所需要的时间较长,利用快速傅里叶变换等简化计算方法都无法避免乘法运算。而新参数提取算法中提取短时幅度和短时幅度差函数只需加、减法和取绝对值的运算,与自相关函数的加法与乘法相比,其运算量大大减少,明显降低了提取算法的复杂度。

图4 10 dB下新、原算法合成语音波形

图5 7 dB下新、原算法合成语音波形
3 结束语
子带声音强度全新参数提取算法的基本思想是采用短时幅度和短时平均幅度差函数的第一最小值的线性组合表征子带清/浊音强度。该算法代替了传统的子带声音强度提取算法,得到的解码语音与基于传统算法的解码语音具有相同的音质效果,其算法不仅原理简单、物理意义清晰、实现复杂度低,而且使混合激励线性预测语音编码器的应用更接近实际。
[1]鲍长春.数字语音编码原理[M].西安:西安电子科技大学出版社,2007.
[2]SUPPLEE L M,McCree A V.MELP:the new federal standard at 2400 bit/s[A].In:Proc ICASSP 97[C].Munich,Germany:1997,1 591-1594.
[3]姜占才,杨林.语音模糊特征提取及码本训练算法[J].吉林大学学报:信息科学版,2012,30(3):279-284.
[4]闵刚,张雄伟,杨吉斌.一种采用混合激励的超低速率分段声码器[J].数据采集与处理,2009,5(24):680-685.
[5]冯晓荣,刘晓明,田雨.改进的MELP低速率语音编码器[J].计算机工程与应用,2011,47(29):131-133,217.
[6]马欣,刘常澍,李文元.一种改进的2.4 kb/s混合激励线性预测声码器方案[J].电路与系统学报,2007,3(12):117-120.
[7]胡剑凌,徐盛,陈健.2.4kb/s MELP算法设计[J].上海交通大学学报,2000,6(34):789-792.
[8]李强,谢虹恩.改进的基于MELP的非连续传输语音编码算法[J].重庆邮电大学学报:自然科学版,2014,5(26):636-641.
[9]韩琼磊,郭立,杨帆.MELP解码器系统的FPGA实现[J].计算机工程与应用,2009,45(9):74-76.
[10]陈双燕,张铁军,王东辉.基于一种可配置可扩展处理器的MELP语音算法的改进与实现[J].微电子学与计算机,2006,6(23):42-44,48.
[11]唐骏,袁江南.基于ARM9的MELPe语音编码算法优化[J].数据采集与处理,2012,S1(27):61-65.
[12]华国刚,戴蓓蒨,张钦.一种改进的MELP语音编码方法[J].电路与系统学报,2003,1(8):101-104.
[13]铁满霞,王都生.基于线性预测系数自适应前后向量化的可变速率MELP语音编码 [J].电子与信息学报,2001,9(23):919-923.
[14]陈亮,张雄伟,陆惠娣.一种改善激励源的1.2 kb/s语音编码算法及其实时实现[J].解放军理工大学学报:自然科学版,2002,4(3):5-9.
A new subband voiced intensity parameter and extraction algorithm
TIAN Chun-huan,JIANG Zhan-cai,LIXiao-hang
(Departmentof Physics,Qinghai Normal University,Xining 810008,China)
In order tomake themixed excitation linear prediction speech coder(MELP)closer to the actualapplication,this paper proposes a method of subband voiced intensity extraction based on a short-time magnitude and short-time average magnitude difference function.The method calculate the linear combination of the two coefficient based on MOS score of decoding speech of MELP vocoder,and calculate 5 bandpass unvoiced/voiced intensity,apply it to the MELP vocoder. Simulation experiments show that the algorithm not only decoding speech with the original algorithm of decoding speech has the same effect,butalso has low algorithm complexity.
unvoiced/voiced intensity;short-time magnitude;short-time average magnitude difference function;linear combination
TN912.35
A
1674-6236(2016)20-0171-03
2015-11-02 稿件编号:201511003
国家社科基金项目资助(15XYY026)
田春环(1988—),女,山东菏泽人,硕士。研究方向:语音与图像处理。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
股市动态分析(2021年25期)2021-12-30
空间电子技术(2021年4期)2021-11-10
电子制作(2019年22期)2020-01-14
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
宇航计测技术(2018年3期)2018-09-08
制造业自动化(2017年2期)2017-03-20
系统工程与电子技术(2016年2期)2016-04-16
