
几种基于MOOC的文本分类算法的比较与实现
2016-11-29 03:42刘鑫昊谭庆平唐国斐
软件 2016年9期
刘鑫昊,谭庆平,曾 平,唐国斐
(国防科学技术大学 计算机科学与技术学院,湖南 长沙 410073)
几种基于MOOC的文本分类算法的比较与实现
刘鑫昊,谭庆平,曾平,唐国斐
(国防科学技术大学 计算机科学与技术学院,湖南 长沙410073)
机器学习是人工智能的主要内容之一,文本分类正是机器学习中典型的监督学习场景。而机器学习在在线教育平台中的应用正是现阶段的发展趋势。首先介绍了文本分类的背景及意义,文本分类系统中的文本预处理部分,介绍了信息增益算法、主要成分分析等相关技术;文本分类的分类算法部分,主要介绍了AdaBoost技术。在遵循文本分类流程的基础上,设计了一个3模块文本分类系统:一、中文分词及去停止词模块;二、文本向量化及特征降维模块;三、分类器模块。文本分类系统的具体实现上,全部采用开源工具完成,使用Ansj实现模块一,Weka实现模块二、三。按照文本分类流程,利用文本分类系统进行了实验,并对实验中得到的数据进行了分析和总结。为了提升最后的分类效果,在特征降维这一步中,添加了IG-LSA(信息增益(IG)-潜在语义分析(LSA))的混合降维方法。
文本分类,机器学习,特征选择,特征抽取
本文著录格式:刘鑫昊,谭庆平,曾平,等. 几种基于MOOC的文本分类算法的比较与实现[J]. 软件,2016,37(9):27-33
1 引言
在当今的信息时代,Internet已经大规模普及,借助互联网技术的发展,每天我们所生活的这个世界都会出现大量的信息,信息的增长速度绝对是前人无法想像的,而这其中,各种电子文档、电子邮件和网页一方面丰富着网络,另一方面也对信息管理提出了更高的要求。在这样的条件下,本文致力于处理MOOC在线教育平台中课程、课件以及相关论坛中的讨论信息,对先关信息进行处理、分析,以便于得到有用的信息,对老师和学生提出改进性的建议,便于MOOC在线教育平台更好的发展。而利用机器完成自动文本分类,时间和资源开销得到有效控制的情况下,文本分类效果也能满足人们对分类的需求。除此之外,文本分类技术在信息过滤、信息检索、文本数据库、数字化图书馆、搜索引擎等诸多领域也都得到了广泛的应用。
本文对文本分类[1]算法进行了研究,文本分类的主要流程如图1.1所示,本文设计实现了一个多分类文本分类系统,采用不同特征抽取,结合不同分类算法进行实验,分析对比了实验结果,给出了结论,给出一种最具有时效性的,能够短期内满足需求的解决方法——分类器组合。

图1 .1 文本分类流程
文章重点介绍了文本预处理、分类器选择、分类器优化以及实验四个部分,介绍了中文分词[2]、去停止词,文本表示(即转换为更适合机器学习的向量空间模型( VSM)),以及为了降低特征维度所采用的几个特征提取算法:信息增益IG,潜在语义分析LSA,主成分分析PCA。以及属Booosting类算法的Addaboost算法。最后进行全文总结。
2 文本预处理
在进行文本分类时,由于文本文件中的文本内容以字符串的形式存储,无法直接被计算机处理用于文本分类,所以,必须对所用文本数据进行处理,转换为计算机能直接处理,适用于文本分类的形式,而这一过程,称之为文本预处理。主要包括中文分词、去停止词、词频统计等。这里重点介绍信息增益、潜在语义分析和主要成分分析。
2.1信息增益
信息增益(information gain)[3,4]是特征选择时常用的一个评估算法,在信息增益中,重要性的衡量标准就是特征能够为分类系统带来信息的多少,一个特征带来的信息越多,信息量越大,该特征越重要。

信息增益是针对一个个特征而言的,计算信息增益,就是看一个系统中,存在特征ti和不存在特征ti时系统的信息量各是多少,其差值就是就是特征ti带给系统的信息量,即增益。存在特征ti时系统的信息量可直接由熵值计算公式得出。而系统不含特征ti的熵值无法直接得到,所以采用固定ti的方法得到,即将特征ti固定为每一个可能取值Xi,算出此时熵值,然后根据概率Pi取均值。
2.2潜在语义分析
潜在语义分析LSA[5](Latent Semantic Analysis)属于特征抽取类算法,它首先利用统计计算的方法,先行分析数据集,进而提取出词与词之间潜存的语义结构,并使用这种潜在的语义结构,表示词和文本,以消除词之间的相关性和简化文本向量,最终实现降维的目的。
潜在语义分析的基础是奇异值分解SVD[6](Singular Value Decomposition),利用SVD把高维的向量空间模型(VSM)表示的文本映射到低维的潜在语义空间中。SVD是线性代数中一种重要的矩阵分解,是矩阵分析中正规矩阵酉对角化的推广。在信号处理、统计学等领域有重要应用。
假设M是一个m×n阶矩阵,其中的元素全部属于域K,也就是实数域或复数域。如此存在一个分解使得:

X:m×m阶酉矩阵;Y:半正定m×n阶对角矩阵;Z*:Z的共轭转置,是n×n阶酉矩阵。这样的分解称作M的奇异值分解。Y对角线上的元素Yi,i即为M的奇异值。常见做法是由大到小排列奇异值。如此由M唯一确定Y(X、Z仍不能确定)。
2.3主要成分分析
主成分分析PCA(Principal Component Analysis),是一种特征提取常用的方法。主成分分析将多个变量通过线性变换以选出较少个数重要变量。主成分分析PCA主要方法是通过对协方差矩阵进行特征分解[7],以得出数据的主成分(即特征向量)与它们的权值(特征值[8])。
在很多情况下,特征与特征之间具有一定的相关关系,当两个特征之间有一定相关关系时,可以理解为这两个特征代表的类别的信息有一定的重叠。主成分分析PCA对于原有特征集,重新构建尽可能少特征的新特征集,并且使得新特征集中的这些新特征是两两不相关的,而且这些新特征在反映类别的信息方面尽可能保持原有的信息。
主成分分析作为一种分析、简化数据集的技术,经常用于减少数据集的维数,同时保持数据集中的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。由于主成分分析依赖所给数据,所以数据的准确性对分析结果影响很大。
主成分分析PCA是最简单的以特征量分析多元统计分布的方法。其结果可以理解为对原数据中的方差做出解释:哪一个方向上的数据值对方差的影响最大?换而言之,PCA 提供了一种降低数据维度的有效办法;如果分析者在原数据中除掉最小的特征值所对应的成分,那么所得的低维度数据必定是最优化的(这样降低维度也必定是失去信息量最少的方法)。
3 分类器的选择
目前很多分类算法被研究者从不同角度提出,判断不同分类算法的好坏可以由准确率、速度、健壮性、可伸缩性、可解释性等几个标准来衡量。经典的分类算法在不同的领域取得成功,比如贝叶斯算法、决策树算法、支持向量机算法等。针对MOOC在线教育平台的数据处理中,通过实验发现,相比于其他算法,Adaboost算法在处理这些数据上有一定的优势。因此这里具体介绍一下Adaboost算法。
Adaboost[9]是英文“Adaptive Boosting”(自适应增强)的缩写,是一个能提高文本分类算法效果的一种迭代算法,Adaboost属于Boosting类算法[10]的代表算法,Adaboost本身并不分类,而是旨在由弱分类器构成强分类器。Boosting方法是一种在弱分类算法基础上提高准确度的方法,它是一种框架算法,首先对样本集S操作获得样本子集S1,然后用弱分类算法在样本子集S1上训练生成的基分类器C1。将弱分类算法生成的基分类器C1放于Boosting框架中,通过Boosting框架对训练样本集的操作,得到新的训练样本子集S2,用该样本子集S2去训练生成基分类器C2每得到一个样本集Si就用该基分类算法在该样本集Si上产生一个基分类器Ci,这样在给定训练轮数n后,就可产生n个基分类器,然后Boosting框架算法将这n个基分类器进行加权融合,产生一个最后的结果分类器,在这n个基分类器中,每个单个的分类器C1的识别率不一定很高,但集合后的强分类器有很高的识别率,这样便提高了弱分类算法的识别率。在产生单个的基分类器时可用相同的分类算法,也可用不同的分类算法,这些算法一般是不稳定的弱分类算法,如神经网络(BP),决策树(C4.5)等。

图1 Boosting算法流程
图1中,矩形代表过程,平行四边形代表数据。总数据集S根据分发权值Di得到子数据集Si,经过训练得到基分类器Ci,得到下一个基分类器Ci+1对应的数据集分发权重Di+1。最终将所有基分类器整合,得到一个强分类器C。实际使用中,由于事先很难知道弱分类算法分类正确率的下限,所以Boosting算法在解决实际问题时有重大缺陷。AdaBoost解决了这一问题,文章以DSAE(降噪稀疏自动编码器)为弱分类器基本原型,调整层数以及激励函数种类构造不同条件下的弱分类器,使用NLPIR分词系统提取文本特征,TF-IDF作为词语的权值,根据该权值来选择特征次,并统计词频作为文本特征训练集。AdaBoost方法使用的弱分类器只要不是随机概率0.5,最终模型都会得到提高,因为即使使用的弱分类器准确率小于0.5,只要权值Wi取负数,最终模型也会提高准确率。
AdaBoost每一轮利用前一个分类器分错的样本Si,训练一个新的弱分类器Ci,直到的错误率小于某一个阈值。每一个训练样本最终都会被赋予一个相应权重Di,对应被其中某分类器选入训练集的概率。已经被准确地分类的样本点,会有更低概率被选入下一个训练集中;反之,概率就提高。如此通过不断迭代的方式,AdaBoost方法最终能“聚焦”于那些弱分类器较难分样本上。在具体实现时,最初每个样本的权重都一样,每次迭代,根据权重选取样本点,进而训练分类器Ci正确分类样本的权重。更新过权重的样本集又用于下一轮迭代,不断跌待下去直到达到制定阈值。
4 实验的设计与实现
这里的实验主要分为三个部分,分别是分词及去停止词模块、特征降维模块和分类器模块。
4.1分词及去停止词模块
分词及去停止词模块承担对中文文本的分词及去停止词两个操作,输入为语料库中的文档,输出为已完成中文分词及去停止词的文档。
中文分词采用汉语词法分析系统ICTCLAS (Institute of Computing Technology,Chinese Lexical Analysis System)的java实现,工具Ansj。ICTCLAS由中国科学院计算技术研究所发布,无论是准确率还是处理速度都较同类算法有很大的优势。是目前最好的中文分词开源系统。分词系统中的分词数据结构采用tire树结构,也就是词典树,一种哈希树变种。常见应用于统计和排序大量的字符串(不仅限字符串),所以也常被搜索引擎系统用于文本的词频统计。
4.2特征降维模块
文本向量化及降维模块将原始的多文档形式的语料库转换为单一文件,内部结构为VSM[11],然后在此基础上实现特征提取。输入为包含多文档的文件夹,各类文档文件存放于类同名子文件夹中。输出为单文件。模块功能的具体实现由调用Weka完成,先将文件夹转化为单文件,然后统计计算生成词的TF-IDF值,并以此作为VSM的权值把的数据向量化,转化为VSM,最后得到单文件的ARFF(Weka定义及使用的机器学习用文件格式)文件,而其中SMO优化算法(Sequential minimal optimization)[12],由Microsoft Research的John C.Platt在1998年提出,并称为最快的二次规划优化算法,特别针对线性SVM和数据稀疏性能更优。
降维使用的算法方面, 特征选择和特征抽取算法都会采用,特征选择算法方面,考虑到以词作为特征,选择了信息增益IG算法[13],因为其对词特征的评估比较适合;特征提取算法方面,主题模型类算法选择了潜在语义分析LSA,非主题模型类算法采用了主成分分析PCA,这两个算法都能适用于文本分类的任务。
一般情况下,特征选择和特征抽取两者在一个分类任务里只有一种会被采用,两种方法各有自己特点、优劣,但是很少有直接两者一起使用的。所以,本次实验,增加了一个特征选择和特征抽取两者混合使用进行降维的方法,称之为IG-LSA,具体为先使用IG进行初步降维,然后使用LSA进一步降维这样混合的两步降维方法。先使用IG进行初步降维后特征集的平均熵值较之前能得到提高,这样的特征集再使用LSA进行在此降维,理论上,得到的数据集相较仅使用LSA得到的数据集在分类器上能有更好的表现。
4.3分类器部分
分类器模块实现训练分类器及测试分类器的功能。训练部分,输入为已经过降维处理的数据集,选择目标分类算法后利用训练数据即可获得一个对应的分类器;测试部分,输入测试数据,并用训练所得的分类器进行测试,输出测试结果。
训练及测试的具体实现由Weka[14]提供的强大机器学习算法集合提供,文本分类可用算法众多,综合考虑各算法的优缺点后,选择了朴素贝叶斯[15]、决策树算法[16],由于支持向量机在分类问题上表现优异,是最好的分类器之一,所以选择了SVM作为第3种分类算法,考虑到朴素贝叶斯以与决策树并不稳定,所以将朴素贝叶斯、决策树与优化后的AdaBoost算法结合进行了对比实验。
5 实验结果及分析
5.1数据集
中文语料库选择:《Coursera研究数据集》。 选取文本类别及数量见表1,文本皆存放在所属类同名子文件夹内,5个子文件夹存放于resource文件夹内。经过转化后得到了可用于文本分类的“vsm.arff”,统计信息见表2。

表1 实验用语料

表2 vsm.arff统计信息
对vsm.arff进行特征提取,采用的特征提取算法及保留特征集大小见表3. 最后得到的数据见表4,共80个数据集。

表3 特征抽取情况

表4 特征抽取后得到的数据集
IG50代表对vsm.arff使用IG,保留50个特征,得到IG50.arff;
IG-LSA,IG-PCA设定为使用IG时保留特征量为1000,然后使用LSA,PCA进一步降维;
IG1000LSA5代表对vsm.arff使用IG保留1000个特征,然后使用LSA得5个特征,得到IG1000L SA50.arff;
5.2评估标准
P(Precision):准确率,分类后,在某一特定类中,分对文本数/实际分到该类文本总数。
R(Recall):召回率,分类后,在某一特定类中,分对文本数/应分到该类文本总数。
F-Measure又称为F-Score,信息检索时常用的评价标准,计算公式为:

其中β是参数,P是精确率(Precision),R是召回率(Recall)。当参数β=1时,就是最常见的F-1:

5.3实验结果
5.3.1朴素贝叶斯分类器实验结果
由F-1数据图2可以看出,当使用朴素贝叶斯分类器时,随着保留的特征数量下降,IG得到的数据集在朴素贝叶斯分类器上的表现也随之下降,其他三种方法LSA、IG-LSA和IG-PCA则随着保留特征数量的下降F-1值逐渐上升,但是使用IG总体准确率依旧较其他三种特征抽取方法更高,仅当特征保留数降至20,IG方法的F-1值被其他三种方法所超过。

表5 朴素贝叶斯分类器

图2 朴素贝叶斯分类器F-1折线图
5.3.2决策树分类器实验结果
图3,决策树分类器F-1值折线图中,IG方法F-1值随特征保留量减少而下降,且特下降幅度逐渐增大。LSA、IG-LSA、IG-PCA三种方法则随着特征保留量的下降,F-1值呈轻微稳定上升趋势。特征保留量小于50时,IG方法表现降至4种方法最差一位。

表6 决策树分类器

图3 决策树分类器F-1折线图
5.3.3支持向量机分类器实验结果
从图4可以看到,支持向量机分类器的实验部分,使用IG-LSA得到的数据集在分类器中的表现十分优秀,F-1值已达99%以上。LSA和IG-PCA两种方法最终实验结果F-1值也能达到92.7%~94.4%。从数据来看,随着特征保留量减少,4种方法的表现都随之下降。IG-LSA下降幅度极低,LSA和IG-PCA两种方法较小,从94%左右下降到92%左右。IG方法下降较大,且下降幅度逐渐增大。

表7 支持向量机分类器

图4 支持向量机分类器F-1折线图
使用SMO已有相当高的准确率,所以AdaBoost实验部分只结合朴素贝叶斯和决策树进行实验。
5.3.4Adaboost-朴素贝叶斯分类器实验结果
图5中,IG1,IG-LSA1折线为Adaboost-朴素贝叶斯分类器实验结果,IG2,IG-LSA2折线为朴素贝叶斯分类器实验结果。从图中可以看出,使用IG时,仅当特征量为200时,使用AdaBoost对朴素贝叶斯分类算法有提高作用,当特征保留量更小时,使用AdaBoost没有提高作用。使用IG-LSA时,AdaBoost对朴素贝叶斯分类算法提升很大,不过提升幅度逐渐减少。

表8 Adaboost-朴素贝叶斯分类器

图5 Adaboost算法对比实验F-1实验图
5.3.5Adaboost-决策树分类器实验结果
图6中,IG1,IG-LSA1折线为Adaboost-决策树分类算法实验结果,IG2,IG-LSA2 折线为决策树分类算法实验结果。从图中可以看出,使用IG时,使用改进后的AdaBoost对决策树分类算法有提高作用,但是随着特征维数降低而减少。使用IG-LSA时,使用改进后的AdaBoost对决策树算法有较大的稳定提升。
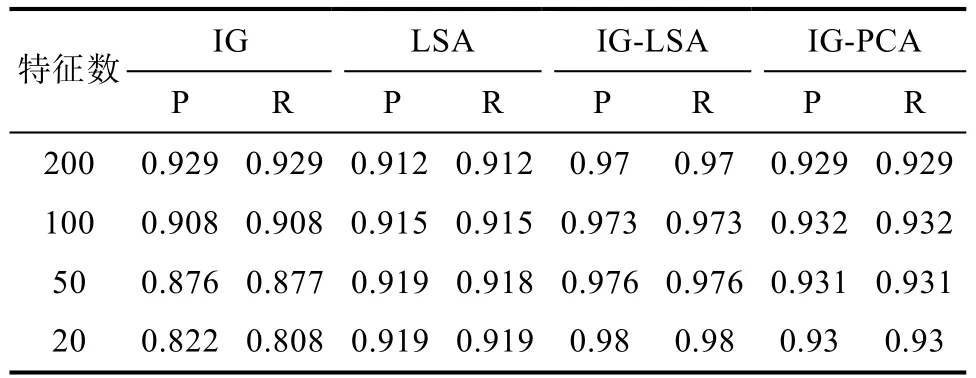
表9 Adaboost-决策树分类器

图6 Adaboost-决策树对比实验F-1折线图
5 结束语
从5个分类实验的F-1值折线图可以看出,使用IG时,所有分类器的表现都随着特征保留量的下降而下降,而使用特征抽取类算法如LSA,IG-PCA,IG-LSA时,随着特征保留量的下降,各分类器上的表现呈上升或保持原有水平。实验结果表明,当直接使用词作为特征时,分类表现与特征保留量呈正相关关系,若计算机处理能力能够接受的情况下,使用特征选择降维时应尽可能保留多的特征。
使用AdaBoost技术对分类算法的表现有一定的提升,当使用IG作为降维算法,提升幅度与特征数呈正相关,当特征数降至一定程度后,AdaBoost技术带来的提升可以基本忽略不计;但是使用IGLSA作为降维算法时,AdaBoost技术对分类算法能带来稳定的提升,且提升程度较高。
实验结果可以看到,IG-LSA的混合降维方法,无论相比IG还是LSA,得到的数据集在分类器上的表现都比较优秀。词与词之间往往是存在联系的,而特征抽取方法旨在消除这种联系,重构出词与词之间没有联系的新特征集。而在特征保留量较多时,LSA,IG-PCA,IG-LSA在分类器上的表现反而较低。这说明,当特征保留量较多时,LSA,IG-PCA,IG-LSA方法构建出的新特征集含有较多无法完全消除词与词之间联系的新特征,这些多余的特征不仅不能帮助提高分类表现,反而拖累了分类的结果。
对比IG-LS与LSA算法,可以看到IG-LSA数据集在分类器上的表现远好于LSA数据集,而LSA数据集相比IG数据集在分类器上的表现各有优劣。LSA基于统计分析原数据集以构建新特征集,但是即使去掉了停止词,原数据集的特征集中往往依旧包含不少对分类没有贡献或贡献很低的词特征,整体的平均贡献度不高,对含有不少低贡献词特征的特征集进行统计分析重构出的新数据集往往达不到理想的分类效果。但是先使用信息增益对词特征进行筛选,得到只保留对分类贡献较大的1000个词特征的新数据集IG1000,这样新的数据集中保留的词特征平均贡献度更高。对新数据集IG1000进行统计分析重构出的新特征集,在分类器上的表现相对LSA和IG方法都提高很多。
[1] Su Jinshu, ZhangBofeng, Xu Xin. Advances in Machine Learning Based Text Categorization [J]. Journal of Software, 2006, 17(9): 1848-1859.
[2] Long Shuquan, Zhao Wenzheng, Tang Hua. Overview on Chinese Segmentation Algorithm[J].Computer Knowledge and Technology, 2009, 5(10): 2605-2607.
[3] F. Sebastiani. Machine learning in automated text categorization[J] ACM Computing Surveys, 34(1): 1-47, 2002.
[4] 李玲, 刘华文, 徐晓丹,等. 基于信息增益的多标签特征选择算法[J]. 计算机科学, 2015, 42(07): 52-56.
[5] Evangelopoulos N E. Latent semantic analysis[J]. Annual Review of Information Science & Technology, 2013, 4(6): 683-692.
[6] Lange K. Singular Value Decomposition[M]. Wiley StatsRef: Statistics Reference Online. John Wiley & Sons, Ltd, 2010: 129-142.
[7] DNA AI,LAN Laboratory. Wiley Interdisciplinary Reviews: Computational Statistics[M]. 2010.
[8] PJA Shaw. Multivariate statistics for the environmental sciences[J]. 2003.
[9] AdaBoost[M].Encyclopedia of Biometrics. Springer US, 2009: 9-9.
[10] Dong Lehong, Geng Guohua, Zhou Mingquan. Design of auto text categorization classfier based on Boosting algorithm[J]. Computer Application, 2007, 27(2): 384-386.
[11] Li Yanmei, Guo Qinglin, Tang Qi. Similarity computing of document based on VSM[C]. Application Research of Computers. 2007.
[12] Platt J C. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines[C]. Advances in Kernel Methods-support Vector Learning. 1998: págs. 212-223.
[13] Zhang Yufang, Chen Xiaoli, Xiong Zhongyang. Improved approach to weighting terms using information gain[J]. Computer Engineering and Applications, 2007(35): 159-161.
[14] Frank E, Hall M, Holmes G, et al. Weka-A Machine Learning Workbench for Data Mining[M]. Data Mining and Knowledge Discovery Handbook. 2009: 1269-1277.
[15] White, Myles. J. Machine learning for hackers[M].
[16] Yang Xuebing, Zhang Jun. Decision Tree and Its Key Techniques[J]. Computer Technology and Development, 2007, 17(1): 43-45.
Comparision and Implementation of Serveral MOOC-Based Text Classification
LIU Xin-hao, TAN Qing-ping, ZENG Ping, TANG Guo-fei
(Academy of Computer Science and Technology, National University of Defense Technology, Changsha Hunan, ZipCode 41000, China)
Machine learning is one of the main content of artificial intelligence, text classification is a typical supervised learning scene. The development trend of machine learning in online education platform is the stage of the application. This paper firstly introduces the background and significance of text classificatio, The text preprocessing part, include the introductions of the text preprocessing part. mentioned Information Gain, Principal Componet Anlysis and anyother technology. The classification algorithm part, include the introductions of AdaBoost technology. Designed a text classification system consists of three module: module one, Chinese segmentation and stop word removal module; module two, text to vector and feature dimension reduction module; module three, classifier module. Completed the implementation of text classification system by using open source tools, Ansj and Weka. According to the text classification process, carried out experiments by using text classification system, and the experimental data obtained are analyzed and summarized. In order to improve the performance of classification, in feature dimension reduction step, added IG-LSA (information gain-latent semantic analysis) method.
Text classification; Machine learning; Feature selection; Feature extraction
TP181
A
10.3969/j.issn.1003-6970.2016.09.007
国家自然课基金项目(61930007);国家“八六三”高技术研究发展计划基金项目(2015BA3005)。
猜你喜欢
车主之友(2022年4期)2022-08-27
海峡姐妹(2019年12期)2020-01-14
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
数理化解题研究(2017年4期)2017-05-04
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
铁道通信信号(2016年6期)2016-06-01
电子器件(2015年5期)2015-12-29
郑州大学学报(医学版)(2015年1期)2015-02-27
计算物理(2014年1期)2014-03-11
