
基于自学习向量空间模型文本分类算法的研究与应用
2016-11-29 03:42张志强
软件 2016年9期
张志强
(华北计算技术研究所,北京市 100083)
基于自学习向量空间模型文本分类算法的研究与应用
张志强
(华北计算技术研究所,北京市100083)
随着网络信息的迅猛发展,信息处理已经成为人们获取有用信息不可缺少的工具。文本自动分类是信息处理的重要研究方向。它是指在给定的分类体系下,根据文本的内容自动判别文本类别的过程。本文对文本分类中所涉及的关键技术,包括向量空间模型,特征提取,机器学习方法等进行了研究和探讨。最后,本文实现了一套基于自学习向量空间模型的文本分类系统,并基于kafka消息队列和storm流计算框架,实时地为文本进行分类。
文本分类;向量空间模型;机器学习;kafka消息队列;storm流计算
本文著录格式:张志强. 基于自学习向量空间模型文本分类算法的研究与应用[J]. 软件,2016,37(9):118-121
1 引言
随着信息技术的不断普及,人们对信息资源的依赖性越来越大,如何实现信息的自动分类,尤其是中文文本信息的有效分类是目前中文信息处理研究的一个重要分支领域。
中文文本分类已经不是一个新的课题,但随着信息化带来的信息量急剧增长,现有的中文文本分类技术面临着新的挑战,主要表现在:
1)动态性。当今社会日新月异,知识更新存在于每一领域,内容变化迅速,信息交换变得更为频繁。分类模型如果缺乏适应性,分类质量将无法得到保障。
2)非结构化。网络文本信息来源各异,往往具有不同的形式和语法。如何对这些非结构化的数据进行有效的处理,给文本分类技术提出了新的难题。
3)数据量大。因特网的发展带来了信息海量式膨胀,信息出现的速度远远超出了人们接受的速度。这样庞大的数据量对文本分类技术的时间效率和分类性能提出了新的挑战。
本文研究的是一种基于自学习向量空间模型[1]文的本分类系统,这是在传统的文本分类模型的基础上的一种主动学习的文本分类方法。本文还增加了对非结构化的文本的处理,提供了把非结构化文本标准化成词向量模型的方法。同时本文最后实现的文本分类系统使用kafka消息队列发布订阅文本数据,并运行在storm流计算框架上,增强了文本数据的处理数据量及实时处理的能力。
2 文本分类涉及的概念及文本分类算法的介绍
2.1文本分类涉及的概念
中文文本分类所涉及到的概念主要包括分词技术、文本表示、特征抽取和分类算法的选择。
1)分词技术:相比于西方文本分类,中文文本分类的一个重要的区别在于预处理阶段,中文文本的标准化需要分词。分词方法从简单的查字典的方法,到后来的基于统计语言模型的分词方法,中文分词的技术已趋于成熟。比较有影响力的当属于中科院计算所开发的汉语词法分析系统ICTCLAS,现已发布供中文文本分类的研究使用。
2)文本表示:计算机不具有人类的智慧,不能读懂文字,所以必须把文本转换成计算机能够理解的形式,即进行文本表示。目前文本表示模型主要是Gerard Salton和McGill于1969年提出的向量空间模型(VSM)。向量空间模型的基本思想是把文档简化为特征项的权重,并使用向量表示:(w1,w2, w3,…,wn),其中wi为第i个特征项的权重,一般选取词作为特征项,权重用词频表示。
最初的向量表示完全是0、1的形式,即:如果文本中出现了该词,那么文本向量的该维为1,否则为0。这种方法无法体现这个词在文本中的作用程度,所以0,1逐渐被更精确地词频代替,词频分为绝对词频和相对词频。绝对词频使用词在文本中出现的频率表示文本;相对词频为归一化的词频,其计算方法主要运用TF-IDF公式。本文采用的TF-IDF公式为:

3)特征抽取[2]:由于文本数据的半结构化至于无结构化的特点,当用特征向量对文档进行表示时,特征向量通常会达到几万维甚至几十万维。因此我们需要进行维数压缩的工作,这样做的目的主要有两个:第一,为了提高程序的效率,提高运行速度;第二,所有词对文本分类的意义是不同的,一些通用的、各个类别都普遍存在的词汇对分类的贡献小;为了提高分类精度,对于每一类,我们应该去除那些表现力不强的词汇,筛选出针对该类的特征项集合,存在多种筛选特征项的算法,如下所列:
a)根据词和类别的互相信息量判断
b)根据词熵判断
c)根据KL距离判断
本文采用了词和类别的互信息量进行特征抽取的判断标准,其算法过程如下:
① 初始情况下,该特征项集合包含所有该类中出现的词。
② 对于每个词,计算词和类别的互信息量。③ 对于该类中所有的词,依据上面计算的互信息量排序。
④ 抽取一定数量的词作为特征项。具体 需要抽取多少维的特征项,目前无很好的解决办法,一般采用先定初始值,然后根据实验测试和统计结果确定最佳值。一般初始值定义在几千左右。
⑤ 将每类中所有的训练文本,根据抽取的特征项进行向量维数压缩,精简向量表示。
4)分类算法:分类算法是研究文本分类的核心问题。目前基于统计和机器学习的方法已经成为文本分类的主流方法,并且还在不断发展,比较常见的文本分类算法有:朴素贝叶斯,KNN分类算法[3-5],决策树算法,神经网络,支持向量机。本文在接下来的一小节重点介绍和比较KNN分类算法和朴素贝叶斯算法。
2.2文本分类算法的介绍
2.2.1KNN算法
K Nearest Neighbor算法,简称KNN算法,KNN算法是一个理论上比较成熟的方法,最初由Cover和Hart于1968年提出,其思路非常简单直观,易于快速实现,以及错误低的优点。KNN算法的基本思想为:根据距离函数计算待分类样本x和每个训练样本的距离,选择与待分类样本距离最小的K个样本作为x的K个最近邻,最后根据x的K个最近邻判断x的类别。
它是一种比较简单的机器学习算法,它的原理也比较简单。下面用最经典的一张图来说明,如下图:

如图所示,假设现在需要对中间绿色的圆进行分类,假设我们寻找距离这个绿色圆最近的3个样本,即K=3,那么可以看出这个绿色圆属于红色三角形所在的类;如果K=5,因为蓝色方框最多,所以此时绿色圆属于蓝色方框所在的类。从而得到当K值取值不同时,得到的分类结果也可能不一样,所以很多时候K值得选取很关键,这就是KNN的核心思想。如果类别个数为偶数,那么K通常会设置为一个奇数;如果类别个数为奇数,K通常设置为偶数,这样就能保证不会有平局的发生。
KNN算法是惰性学习法,学习程序直到对给定的测试集分类前的最后一刻对构造模型。在分类时,这种学习法的计算开销在和需要大的存储开销。总结KNN方法不足之处主要有下几点:①分类速度慢。②属性等同权重影响了准确率。③样本库容量依懒性较强。④K值的确定。
2.2.2朴素贝叶斯算法
贝叶斯法则建立了P(h|d)、P(h)和P(d|h)三者之间的联系如下:

其中:(1)P(h)是根据历史数据或主观判断所确定的h 出现的概率,该概率没有经过当前情况的证实,因此被称为类先验概率,或简称先验概率(prior probability)。(2)P(d|h)是当某一输出结果存在时,某输入数据相应出现的可能性。对于离散数据而言,该值为概率,被称为类条件概率(classconditional probability);对于连续数据而言,该值为概率密度,被称为类条件概率密度(classconditional probability density),统计学中通常应使用P(d|h)表示,以示与概率区别。(3)P(h|d)的意义同前,它反映了当输入数据d时,输出结果h出现的概率,这是根据当前情况对先验概率进行修正后得到的概率,因此被称为后验概率(posterior probability)。
显然,当机器处理问题时,它关心的是P(h|d)。对于两个不同的输出结果h1和h2,如果P(h1|d)> P(h2|d),表示结果h1的可能性更大,从而最终结果应为h1。也就是说,应优先选择后验概率值大的结果,这一策略被称为极大后验估计(Maximum A Posteriori),简称MAP。设H表示结果集,则极大后验估计为

在朴素贝叶斯分类器中,假设数据向量中各分量相互独立,从而将高维数据分布转化为若干一维数据分布进行处理。设d=(d1,d2,…,dn),其中n为数据维数,则根据各分量相互独立的假设,类条件概率(或概率密度)可表示为:

于是朴素贝叶斯分类器的决策公式为

公式表明:只要获得每个数据分量对应的P(d h)i,便获得了类条件概率(或概率密度)。这一过程的计算量远远小于不做各分量独立性假设而直接估计高维类条件概率(或类条件概率密度)的计算量。例如,设d=(d1,d2,…,dn)为离散数据向量,其中每个分量上的可能取值为m。如果假设各分量相互独立,则只需学习mn个概率值;而如果假设各分量彼此相关,则需要考虑所有可能的分量组合,这便需要学习个概率,显然这两个数据量之间的差距是惊人的。
3 自学习的文本分类算法的研究
就目前研究情况来说,国内学者提出了很多文本分类算法,这些分类算法在封闭测试中表现良好,但是在开放测试中,尤其面对异常庞杂的网络文本的测试中,往往不尽人意。究其原因,大多数的文本分类系统都采取“训练-分类”模式,训练和分类是两个彼此独立的过程,训练过程一般只针对训练语料进行学习,在这种模式下,分类系统的性能依赖于训练预料的质量,缺乏适应性,不适宜海量、非结构化、动态的文本信息的处理要求。
本文研究的基于自学习向量空间模型文的本分类系统,该系统将训练过程延伸到分类过程中,以训练驱动分类,以分类结果反馈进行再训练,使得训练和分类两个过程成为一个有机的整体,从而打破了训练、分类相对独立的传统模式,同时在训练过程中,克服了对训练预料的完全依赖性,从而增强了分类系统的自适应能力。
本文介绍的自学习文本分类算法[6-7],首先得到分类后的结果,主观的对结果进行评估,并反馈给训练样本,调整训练样本的向量空间模型。这是个不断学习的过程,通过迭代反馈,逐渐提高分类的准确率。
4 标准化非结构化文本
本文为适应不同格式的非结构化文本,提供了文档适配处理模块[8]。利用Apache POI开源工具处理不同类型的电子文档,包括Word、PDF、TXT等等,处理结果统一为文本分类系统能处理的纯文本格式数据。然后把纯文本格式数据标准化成向量空间模型。
5 kafka消息队列及Storm流计算框架下的实时分类
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中所有动作流数据。由于采集数据的速度和数据处理的速度不一定同步,本文添加一个消息中间件kafka来作为缓冲。
Storm是一个免费开源、分布式、高容错的实时流计算框架。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。本文为提供高实时性的文本分类系统,使用了storm实时流计算框架。
本文的文本分类系统,使用kafka消息队列做缓冲中间件,并建立在Storm流计算框架的基础之上。众所周知,kafka负责高吞吐的读取消息,并对消息保存到消息队列中,保存时可以根据Topic进行归类,消息发送者成为Producer,消息接收者成为Consumer。在本文中,kafka负责高吞吐地读取消息成为消息生产者,kafka还负责缓冲消息到消息队列中成为消息缓冲中间件,storm实时读取缓冲区的消息并处理成为消息消费者。Storm的两个核心组件spout和bolt,译为中文为喷口和螺栓更加形象贴切。Spout是storm流处理中流的源头,本文中的spout负责从缓冲队列中读取消息。Bolt是storm流处理中具体的处理单元,本文中的文本分类算法就是运行在bolt上的。
6 文本分类系统测试结果说明
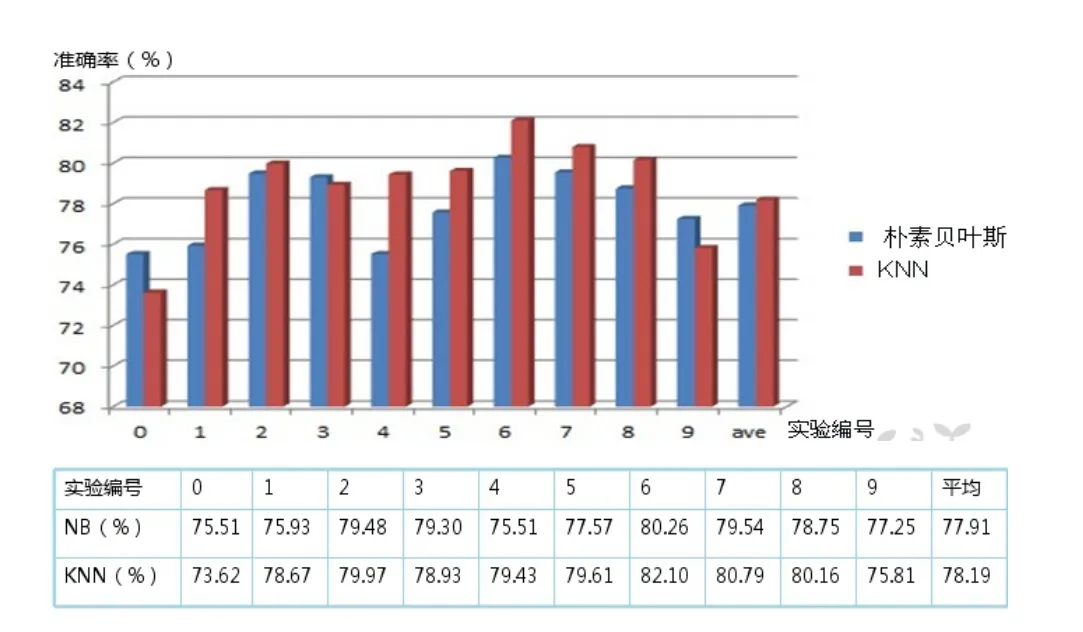
通过大量的不同格式的电子文档的导入,进行文本分类,本文的文本分类系统能够实时地处理并返回分类结果,分类的效果较好,分类准确率平均在80%。用户可以通过对文本和分类结果进行比对,反馈给系统人为分类的结果,系统会根据反馈的结果,调整向量空间模型。通过这样的不断迭代反馈,逐步提高分类准确率。实验结果图如下:
7 结束语
本文所实现的文本分类系统,实现了对本文开始提出的文本分类目前存在的三个问题数据量大、非结构化、动态性的解决,为传统的文本分类方式注入新鲜的血液。
本文所提出的文本分类系统,仍然存在一些问题,具体体现在:
1)半监督的学习模式。这种学习模式需要人为地干预,这样会一定程度上把分类的准确性寄托在人为分类的基础之上。
2)文本分类结果的准确率上。本文实验的文本分类准确率在80%,除了通过自学习这种“后天学习”方式来提高准确率,还需提高“先天”的向量空间模型的建立以及分类算法的选择上。
[1] 庞剑锋, 卜东波, 白硕. 基于向量空间模型的文本自动分类系统的研究与实现[J]. 计算机应用研究, 2001, 09: 23-26.
[2] 张东礼, 汪东升, 郑纬民. 基于VSM的中文文本分类系统的设计与实现[J]. 清华大学学报(自然科学版), 2003, 09: 1288-1291.
[3] 黄萱菁, 夏迎炬, 吴立德. 基于向量空间模型的文本过滤系统[J]. 软件学报, 2003, 03: 435-442.
[4] 周炎涛, 唐剑波, 吴正国. 基于向量空间模型的多主题Web文本分类方法[J]. 计算机应用研究, 2008, 01: 142-144.
[5] 李文波, 孙乐, 张大鲲. 基于Labeled-LDA模型的文本分类新算法[J]. 计算机学报, 2008, 04: 620-627.
[6] 马凯航, 高永明, 吴止锾, 等. 大数据时代数据管理技术研究综述[J]. 软件, 2015, 36(10): 46-49.
[7] 谢子超. 非结构化文本的自动分类检索平台的研究与实现[J]. 软件, 2015, 36(11): 112-114.
[8] 路同强. 基于半监督学习的微博谣言检测方法[J]. 软件, 2014, 35(9): 104-108.
[9] 申超波, 王志海, 孙艳歌. 基于标签聚类的多标签分类算法[J]. 软件, 2014, 35(8): 16-21.
Research and Implementation of Text Categorization System Based on VSM and ML
ZHANG Zhi-qiang
(CETC 15 Institute, Beijing 100083, China)
In recent years, information processing turns more and more important for us to get useful information. Text categorization, the automated assigning of natural language texts to predefined categories based on their contents, is a task of increasing importance. This paper gives a research to several key techniques about text categorization, including vector space model, feature extraction, machine learning. At the last of this paper, a text categorization system based on VSM and ML is implemented, and it also can dispose text categorization at real time through kafka and storm, which is a flow calculation framework.
Text categorization; Vector space model; Machine learning; Kafka; Storm flow calculation
TP391.1
A
10.3969/j.issn.1003-6970.2016.09.028
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
园林科技(2021年3期)2022-01-19
河北理科教学研究(2021年4期)2021-04-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机教育(2020年5期)2020-07-24
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
计算机工程(2015年8期)2015-07-03
读者·校园版(2015年7期)2015-05-14
深圳大学学报(理工版)(2015年5期)2015-02-28
