
藏语语音合成系统的关键技术研究
2017-01-11 02:30刘芳
西藏大学学报(自然科学版) 2016年2期
刘芳
(西藏大学藏文信息技术研究中心 西藏拉萨 850000)
藏语语音合成系统的关键技术研究
刘芳
(西藏大学藏文信息技术研究中心 西藏拉萨 850000)
文章根据藏语的语音规律和特点,以统计声学模型为基础,对藏语语音合成系统中的语料库设计与建设、韵律信息及标注、模型设计与训练及语音合成等关键技术进行了分析,对藏语语音合成系统的实现具有一定的参考价值。
藏语;语音合成;统计声学模型
引言
计算机语音合成是依据语音处理规则,将计算机自身产生或通过外部输入所形成的文字信息,转换成相应的语音信号并向外输出的一种技术,是信息处理领域的重要研究内容之一。藏民族是中华民族大家庭中历史悠久、文化发达的民族之一,藏语言作为藏文化传承的工具,对于新思想、新技术的传播起着巨大的作用。由于藏文特有的拼写规则,藏语音独有的发音方式和韵律,藏语语音合成技术研究在国内起步较晚。目前国内很多研究机构都在对藏语语音合成系统中的词性标注、韵律分析、模型构建等关键技术进行了研究,一些藏语语音合成系统的产品也陆续推向了市场。
藏语语音合成系统关键技术的研究,将为藏语语音合成产品的实用化提供一定的技术支撑,对藏文化的传播和促进西藏社会稳定发展具有重要意义。
1 藏语语音合成概述
藏语语音合成系统的最终实现主要靠语音的训练及合成。在具体的训练当中,运用HMM对频谱参数、时长及基频实施建模操作;在具体的合成当中,分析所输入的文本内容,将训练后的模型给与利用,预测参数并生成参数,然后利用语音的参数合成器,来实现对输出语音的合成工作。

图1 藏语语音合成流程图
本文针对藏语语音合成系统,以统计声学模型为基础,分别从语料准备、韵律标注、模型训练及合成等方面进行分析和描述。藏语语音合成系统的具体框架模式见图1,在设计语音合成系统之前,根据藏语的音节结构和发音规律等特点,开展相应的前期准备,如语料库的建设、数据的标注和系统模型中相应配置参数的设计和实验等。
2 语料库建设
拉萨语藏语语料库是藏语语音合成系统的基础内容,语料库的构建流程如图2所示。

图2 语料库建设流程图
对于语料库的建设,语料库的规模应该是越大越好,设计也应该是动态的,可以不断扩充。语料选择的好坏是语料库优劣的关键,对整个系统的性能起着重要的作用。藏语作为一种具有特殊性声调的语言,在对语料的选择上,主要考虑语句的持续时间、清浊搭配、音段的音联现象及声调的组合等方面,选出能基本覆盖藏语当中所使用的有调音节[1]。
在海量的文本中,采用greedy算法完成语料的初选,选择的语料范围和分类要尽可能平衡,要考虑到不同发音人的年龄、性别、本语言中的句法结构及文本类型的比例,尽量选择能反映本语言的发音特征、韵律结构、语调信息和发音变化的句子。再将选中的句子使用16 kHz的采样频率进行录音,用.wav的格式存储[2],最后再进行人工校对,去除错误的语音文件。
3 韵律信息描述与标注
设计出优质的语料库之后,还需要对藏语特殊的音节结构及发音现象进行分析,下面分别从藏语的发音信息和韵律信息两方面,对系统的语境信息标注进行描述。
3.1 发音信息的表示及标注分析
藏语语音分为辅音和元音两种。气流在口腔或咽头受阻而形成的音为辅音;气流震动声带,在口腔和咽头不受阻而形成的音为元音。依据发音方法对藏语语音进行分类,可以分为塞擦音、鼻音及塞音等;依据发音部位的不同,又可划分为喉音、舌根音及双唇音等。发音信息的表示和标注,主要包括当前音素所具有音节当中的后音节的声调信息、前音节的声调信息等,还有当前音素当中所存在的发音特点[3]。
3.2 韵律信息相应表示和标注
对于藏语语音合成系统来说,语音韵律信息的标注须具备32个韵律特征,描述韵律单元的有句子(utterance)、韵律短语(phrase)、韵律词(word)及音素(segment)等。分析韵律特征标注的信息,存在多个韵律层级单元所具有的位置信息,其中后向位置(Bw)、前向位置(Fw)为其主要内容。
3.3 标注信息的表示
语料上下文语境信息当中相应标注的部分信息描述和语境信息的符号表示,见表1。

表1 标注信息表
4 模型训练
基于统计声学模型的藏语语音合成系统,在前期运行环境的配置及数据准备操作完成之后,便开展模型的训练。训练阶段主要包括预处理和模型训练两大部分。
4.1 预处理
在预处理阶段,通过对语料库中的语音数据进行分析,提取出相应的基频和谱参数。在研究过程中,采用连续概率分布HMM对谱参数部分进行建模,而基频部分则采用多空间概率分布HMM进行建模。根据先验知识选择一些对谱、基频和时长等声学参数有一定影响的上下文相关模型聚类[4]。
4.2 模型训练
模型训练过程主要包括模型的初始化、声韵母的HMM训练、扩展上下文相关模型的训练、聚类后模型的训练以及时长模型的训练。
在开展语音合成训练前,需要做与藏语相对应的模型参数的配置工作,即设置声学参数,运用Mel倒谱系数(MFCC)来表征语音的音段特征,采用基频(F0)表示语音信号特征,再加入相应的二阶、一级差分,共78维;建模单元方面,需综合考虑藏语音节结构和其所在位置。在基于统计声学模型的藏语语音合成技术中,以声母和韵母为合成基元,对声母和韵母分别进行声学模型训练以确定最佳参数[5]。
通过计算相邻帧间的一阶与二阶差分,得到各帧完整的观测特征向量然后以训练数据对应模型的似然值函数P(| Oλ)最大为准则,训练一组上下文相关音素的HMM模型λ。这里表示观测特征序列,(·)T表示矩阵转置,N表示序列的长度。通过训练之后,时长的频谱及基频便可得出,为下文合成环节打下基础。
5 语音合成
通过对语料库进行分析,得到经过处理的输入信息。根据文本的环境信息和上下文相关基元序列,对基元进行搜索,从中得出状态时长和频谱的HMM及基频周期。依据统计声学模型,可以获取到基元相应各个状态的持续时间,并求出MFCC参数和基音周期,再将所获得的数据,在合成器当中输入,最终得到所需要的合成语音。总体来说,可将语音的合成部分划分为参数生成和语音合成两大模块[6]。
5.1 参数生成
所谓参数生成,就是将相关数据开展相应的文本分析及深入处理操作,然后对输入文本状态序列进行深入的设置。此外,将已经设置好且训练完成后的HMM模型,进行深入的合并操作和合并计算,最后计算出生成语音的logF0和MFCC参数。该过程的开展及实现,实质上是具体训练过程中的部分逆推环节。由于清音部分对基频参数的获取和计算会产生一定的影响,需要先清除清音段,然后将各个清音段进行相应的拼接,并将其相应邻接位置上的浊音序列在具体的一、二阶进行置零处理,以便更好地进行相应动态特征的展现。当计算完浊音部分的logF0,再将清音部分的logF0在相关的序列当中进行插入操作,将其再按照最初状态进行最后的输出操作。
5.2 语音合成
本次研究所使用的MLSA滤波器,能够与语音信号MFCC参数进行结合使用,并通过相应公式得到结果,最终实现指数函数形式。公式为:

统计声学模型当中采用HMM系统,在系统当中通过对MLSA合成器进行综合运用,最终便可生成所需要的语音,合成器示意图见图3。
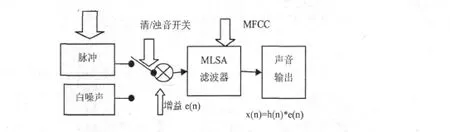
图3 M LSA滤波器示意图
在基于统计声学模型的藏语语音合成系统中,使用MLSA滤波器作为合成器对声道进行相应的模拟。本文研究所使用的模型系统,就是利用此滤波器过对声道进行相应的模拟。对于声门浊音部分运用了冲击序列作为源;对于清音部分运用了白噪声作为源。在语音合成时,通过分析输入的文本,在系统参数生成模块中获得了激励源基频参数、声道及增益参数,然后再将声门波输送到相应的滤波器当中,最后,得到具有很好韵律表现的合成语音。
6 结语
本文以统计声学模型为基础,分别从数据准备、韵律信息描述与标注、模型训练和语音合成四方面,对藏语语音合成系统的相应框架及关键技术进行了剖析,并对其中一些参数的获取给出了具体的实现公式,对藏语语音合成系统的实现有一定的参考意义。
[1]凌震华,王仁华.基于统计声学模型的单元挑选语音合成算法[J].模式识别与人工智能,2008,21(3):280-284.
[2]陶建华,康永国.基于多元激励的高质量语音合成声学模型[J].中文信息学报,2004,18(03):73-80.
[3]陈国平.基于HMM的语音合成中声学建模和模型训练的研究[D].北京:中国科学院声学研究所,2006.
[4]徐世鹏,杨鸿武,王海燕.面向藏语语音合成的语音基元自动标注方法[J].计算机工程与应用,2015,51(6):199-203.
[5]徐世鹏,杨鸿武,王海燕.面向藏语语音合成的语音基元自动标注方法[J].计算机工程与应用,2015,(6):199-203.
[6]胡郁,凌震华,王仁华,等.基于声学统计建模的语音合成技术研究[J].中文信息学报,2011,25(6):127-136.
Research on the key technologiesof Tibetan speech synthesissystem
Liu Fang
(Research Center for Tibetan Information Technology,TibetUniversity,Lhasa 850000,Tibet)
According to the phonetic rules and characteristics of the Tibetan language,the key technologies including corpus design and construction,prosodic information and annotation,model design and training,and speech synthesis in the Tibetan speech synthesis system were analyzed based on the statisticalacousticmodel.It has certain reference value for realization of Tibetan speech synthesissystem.
Tibetan;speech Synthesis;statisticalacousticmodel
10.16249/j.cnki.54-1034/c.2016.02.014
TN912.33
A
1005-5738(2016)01-087-005
[责任编辑:张建伟]
2016-06-28
2015年度西藏自治区自然科学基金项目“基于统计声学建模的藏语语音合成技术研究”阶段性成果,项目号:2015ZR-14-12
刘芳,女,汉族,四川南充人,西藏大学藏文信息技术研究中心讲师,主要研究方向为藏文信息处理技术。
猜你喜欢
客联(2022年2期)2022-04-29
家庭影院技术(2020年6期)2020-07-27
中华诗词(2019年1期)2019-08-23
福建基础教育研究(2019年11期)2019-05-28
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
乡村地理(2018年4期)2018-03-23
周末·校园文学(2017年35期)2018-02-06
西藏研究(2017年3期)2017-09-05
