
数据挖掘技术在上市公司财务困境预测中的应用
2017-02-04 00:02庄慧饶扬胜
现代经济信息 2016年28期
关键词:数据挖掘
庄慧+饶扬胜
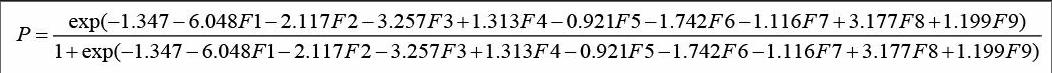
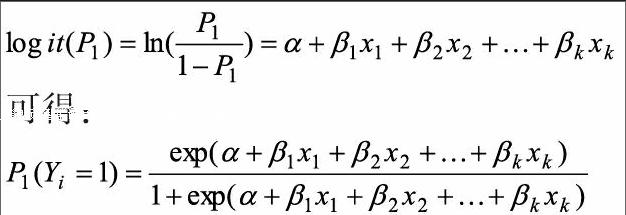
摘要:财务风险不仅严重危害企业的生存和发展,而且也会给投资者带来巨大的投资损失,因此上市公司财务风险的预测越来越受到实务界和学术界的重视。笔者基于中国资本市场的数据,选取了2014-2015两个时间窗口的27家首次被ST(特别处理的股票)的上市公司和54家各项财务指标符合上市规则的公司作为本文的研究数据来源,其中27家ST的公司以被ST前的第二个会计年度的数据为基数,运用CLementine工具,比较准确地实现了数据挖掘技术在上市公司财务困境预测中的运用。研究结果表明数据挖掘技术(Data mining)在财务困境预测模型具有较强预测能力,正确率较高。
关键词:财务困境预测;数据挖掘;Logistic回归
中图分类号:TP182 文献识别码:A 文章编号:1001-828X(2016)028-000-02
一、绪论
1.研究背景
ST(股票被特别处理)规则的实施可以追溯到上个世纪90年代末,正是由于一批公司上市后财务状况严重恶化,投资者利益尤其是那些小股东的利益受到严重损害,深证和上海证券交易所于1998年3月16日正式启动ST规则,这标志着中国资本市场制度的完善。所谓ST规则是指当上市公司财务状况出现异常情况不符合上市条件时,该公司的股票会被特别处理以引起投资者的关注。尽管ST规则的实施出于保护投资者的利益,但是该规则存在着滞后性,这就意味着上市公司出现财务异常状况时投资者的利益已经收到损害。单纯从数量方面来看,2014-2015两年被特别处理的公司都超高50家,而且大部分被ST(特别处理)的原因在于最近连续两个会计年度的净利润为负数,由此可见上市公司被ST只有在公司连续两年财务状况严重恶化的情况下才会出现。
公司被ST后证监会会给出一定的整改时间,在这段时间内公司的高管承受巨大压力,并采取各种手段粉饰财务报表以求尽快摘帽,而这些措施往往是“拆了西墙补东墙”,投资者及其他利益相关者的利益还是会受到实质性的损害。因此,基于该背景,利用数据挖掘技术,从大量的财务数据中挖掘出对上市公司财务困境有预测作用的信息,成为我国市场的一个重要问题,具有一定的理论和现实意义。
2.研究意义
数据挖掘技术(Data mining)是基于大数据背景下产生的数据提取技术,在信息过量的现代企业管理中如何高效准确提取出管理活动中必须的信息是目前比较新的研究领域之一;而如何在上市公司发生财务困境时高效运用现代信息技术预测企业未来的财务状况变化目前是比较棘手的问题。因此本文的研究结果在某种程度上有一定的理论价值。
以此同时,本文利用数据挖掘技术提前预测上市公司的未来各项财务指标的变化具有重要的现实意义。首先,上市公司的财务预测模型具有提前性,相比ST规则的滞后性,财务预测模型可以提前检测上市公司的各项财务指标给管理者充分的时间采取措施扭转经营恶化的趋势,相比被ST后在短暂时间内的“拆了西墙补东墙”的措施,财务预测模型具有时间上的优势,从而减少对利益相关者利益的损害甚至可以增加他们的利益。其次,财务预测模型可见减少上市公司的成本,上市公司被ST后将会发生各种成本,比如信息披露成本,而企业建立财务预测制度和可以以较少的投入避免更大的支出。
二、我国上市公司财务困境预测模型的研究设计
1.实证研究的基本流程
本文的实证研究可以分为三个流程,首先从证券交易所的官网中选取27家2014-2015年度被ST的上市公司和54家没有被ST的公司作为研究对象;并确定能显示上市公司财务状况出现问题的财务或非财务指标,从国泰君安和锐思数据库检索需要的数据。其次,其次,对所选取指标进行特征选择,删除对被解释变量影响不显著的指标,降低变量维度,选择回归结果显著的指标作为预测模型的解释变量(Xi)。最后,将剩余的指标代入预测模型,运用Logistic回归的基本原理对预测模型进行实证检验,并检验模型的稳健性以对模型预测的效果进行最后评价。
2.财务困境预测指标体系的设计
根据国内外研究成果和我国上市公司信息披露的现状,本文选取了以下7个方面47个具体指标,这些指标涵盖企业的财务与非财务,短期与长期,流动与非流动,投资者相关与债权人相关等方面。
(1)上市公司的盈利能力
盈利能力是企业财务状况与经营状况的集中体现。如果一家公司的盈利能力强,这将给起来带来充足的盈余公积以应对未来可能发生的各种财务风险,这将意味者该公司被ST的可能性小。因此本文首先选择盈利能力的财务指标作为本文财务预测的代入变量。
关于盈利能力本文选取的代表指标有:投入资本回报率X1、净资产收益率X2、资产报酬率X3、资产净利率X4、营业利润率X10、销售成本率X6、销售费用率X7、管理费用占率X8、财务费用率X9、销售净利X10、成本费用利润率X11。
(2)上市公司的偿债能力
财务风险的大小很大程度上取决于企业的资本结构,合理的资本结构有利于企业的健康平稳发展;如果企业不能按期偿还债务,将会严重危机企业的发展甚至会导致破产清算。因此,本文将反应偿债能力的指标列入模型的代入变量。
本文选取的指标有:流动比率X12( Current Ratio)、速动比率X13(Quick Ratio)、产权比率X14、有形净值债务率X15、利息保障倍数(Times interest earned)X16、资产负债率(Assets Liabilities Ratio)X17、长期负债比率X18、权益乘数X19。
(3)上市公司成长能力
公司的成长能力代表着公司未来发展的潜力和行业的吸引力,只有具有良好发展潜力的上市公司才能得到投资者的青睐,才能以较低的财务成本获得资金支持。因此成长能力是一个公司是否健康平稳发展的重要指示器。
本文选取得指标有:每股收益的增长率X20、营业收入的增长率X21、销售的净利润率X22、经营活动中发生的现金流量净额增长率X23、每股经营活动发生的现金流量增长率X24、净资产的增长率X25、总资产的增长率X26。
(4)上市公司营运能力
营运能力是指企业对各项资产的利用状况,是企业高管能力的集中体现,他与企业财务风险有着紧密的联系。各项财务指标正常的企业应当具有较强的资产管理能力,各项资产都发挥从其作用,很少出现资产闲置和超负荷工作的情况。
本文选取的代表指有:总资产的周转率(次)X27、营业周期(天/次)X28、总资产的周转率(次)X29、应收账款的周转率(次)X30、流动资产的周转率(次)X31、固定资产的周转率(次)X32、应付账款的周转率(次)X33。
(5)上市公司现金流量
目前的为文献很少将现金流量相关的指标作为财务预测模型的代入变量,但是上市公司的现金流量状况直接影响企业的偿债能力,再加上现金流量信息的不容易被管理层操作,因此本文将该类指标纳入本文的测试范围。
本文选取的的指标有:每股经营活动现金流量(元/股)X33、资本支出/折旧和摊销X34、自由现金流量(元)X35、销售收到现金比率X36、每股净现金流量(元/股)X37。
(6)上市公司杠杆系数
上市公司的杠杆系数包含财务杠杆和经营杠杆,这两种杠杆分别代表企业财务风险和经营风险的大小,这取决于公司的资本结构的合理性。财务杠杆直接决定财务风险的大小,同时经营杠杆系数也是评价企业风险的指标之一,该指标越大,企业的经营风险越大。
选择的指标有:DOL_营业杠杆系数X38、DFL_财务杠杆系数X39、DTL_总杠杆系数X40。
(7)非财务指标
上市公司的财务风险虽然在很大程度上取决于财务指标,但是非财务指标也能影响企业的财务状况,财务指标都能量化,而有些指标不能量化但与公司财务状况息息相关,我们将这些指标归类为非财务指标。
选择的指标有:董事会人数(人)X41、独立董事比例(%)X42、监事会人数X43、股权集中度X44、H5指数X45、国有股比例(%)X46、审计意见类型X47。
三、基于数据挖掘的上市公司财务困境预测
1.测试样本的选取
本文基于中国资本市场的数据,选取了2014-2015两个时间窗口的27家首次被ST(特别处理的股票)的上市公司和54家各项财务指标符合上市规则的公司作为本文的研究数据来源,其中27家ST的公司以被ST前的第二年的财务指标为基期。假定上市公司被ST当年为T年,前两年假定为T-1、T-2年,同时根据我国上市公司信息披露制度的现状,最终选定以T-2为基期来预测T年的财务状况并于真实的状况进行比较,以检测模型的可靠性。
根据以上方法,我们选取了27家被ST的公司作为实验的样本来源,并选取了54家正常的公司作为对照组的数据来源本文研究的所用数据主要来源于锐思数据库和巨潮资讯网。
2.Logistic回归分析
Logistic 回归分析的基本原理:设被解释变量Y为1是代表公司被ST,即公司发生财务预警。Y为0时表示公司各项财务指标正常。P1(0-1)代表公司被ST 的可能性,我们用概率表示,P0=1-P1表示公司正常运行的可能性。
Xk为解释变量,βk为解释变量对应的回归结果得出的系数,α为横向截距。其中截距和回归系数是运用概率论中的最大似然方法估计的结果。由此我们得到回归预测模型通常选择0.5(该数值来源于现有研究结果)为分界点,这就是说当上市公司的P小于0.5时可以判断该公司的各项财务指标符合规定,该公司为正常公司;当P大于0.5时,我们可以据此推测该公司被ST,即该公司发生财务危机。
根据Clementine软件的Logistic回归模型计算结果,对模型的整体显著性、模型中每个解释变量的显著性以及模型的拟合优度进行检验,并对影响财务困境的因素进行分析。其中我们对该预测模型进行显著性检验的目的在于检测自变量X是否与P的线性关系存在显著影响,是否可以得出该模型具有良好的拟合度。
原假设(H0)是回归的结果是:各项系数显示为0,这就意味着解释变量全部与P没有显著的线性关系,因此应该拒绝原假设;拟合优度检验一方面是考察回归方程能够解释被解释变量变差的程度,另一方面是考察回归方程算出的预测值与实际值之间的吻合程度,如果吻合程度越高,则说明拟合优度越高。最后根据Clementine软件给出的判别矩阵,给出模型的每类预测准确率和整体预测准确率。具体分析如下:
回归方程显著性检验的总体情况,各数据项分别是:似然比卡方的观测值、自由度及概率P-值。其中最大似然卡房检验的结果的观察值为95.950,概率的P值为0.000,明显小于显著性水平值(0.05),因此应当拒绝原假设,并认为当所有的回归系数结果不同时为0时,X与P之间的关系是显著的,这也说明所拟合的方程具有统计学意义。
该模型拟合优度方面的指标,其中-2倍的对数似然函数值为7.165,比较小;Nagelkerke R Square为0.964,比较接近1,这说明该模型的拟合优度较高。
根据ST发生前T-2年的模型统计量,Logistic回归方程可表示为:
四、小结
本文以A股上市公司为研究对象,利用SPSS公司的Clementine数据挖掘工具对我国上市公司的财务困境预测进行了实证研究。本文的实证结果表明,上市公司采用数据建立财务预测模型对预测企业未来的财务状况走势具有较强的预警能力,而且本文对各项财务指标进行了量化处理,非财务指标也进行了恰当的处理,由此得出的结论具有一定的说服性。
但是本文也存在一些不足之处,本文只是对数据挖掘在财务困境预测方面做了初步探索,在理论及操作中仍存在很多不足之处。由于公开披露的被ST公司的上市公司的数量每年是有限的,因此本文的研究样本数量不足,此外,虽然对样本数据不断进行修改及替换,但最后选取的样本并不是很完善,造成在特征选择过程中,很多理论上对公司财务状况有重大影响的指标因为缺乏经验数据而被删除。以上的不足及问题均说明该模型仍有许多需要改进之处。
参考文献:
[1]薛薇,陈欢歌编著.基于Clementine的数据挖掘[M].中国人民大学出版社,2012,3.
[2]李健.基于数据挖掘的上市公司财务风险预警研究[D].西安:西安科技大学硕士学位论文,2019,4.
[3]金照林.基于数据挖掘的上市公司财务困境预警研究[D].武汉:武汉理工大学硕士学位论文,2005,5.
[4]彭易成.基于数据挖掘的上市公司财务危机预警模型研究[D].成都:成都理工大学硕士学位论文,2007,5.
[5]赵芳芳.关于上市公司财务风险预警系统的实证研究[J].商场现代化,2007,9:24-29.
[6]张秋水,罗林开,刘晋明.基于支持向量机的中国上市公司财务困境预测[J].计算机应用,2006,6:105-108.
[7]韩建光,惠晓峰,孙洁.基于多特征子集组合分类器的企业财务困境预测[J].系统管理学报,2010,4:420-427.
[8]吴世农.我国上市公司财务风险的预测模型研究[J].通信与信息技术,2001,6:34-38.
[9]陈磊,任若恩.基于比例危险和主成分模型的公司财务困境预测[J].财经问题研究,2007,9:93-96.
[10]卜耀华.基于数据挖掘技术的企业财务困境预测建模[J].计算机仿真,2012,6:355-358.
猜你喜欢
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
河南科技(2014年23期)2014-02-27
电子设计工程(2014年18期)2014-02-27
