
基于映射序列码的多叉树防碰撞算法
2017-06-05 14:15何申炎杨恒新
计算机技术与发展 2017年5期
何申炎,杨恒新,张 昀
(南京邮电大学 电子科学与工程学院,江苏 南京 210003)
基于映射序列码的多叉树防碰撞算法
何申炎,杨恒新,张 昀
(南京邮电大学 电子科学与工程学院,江苏 南京 210003)
随着物联网技术的发展,射频识别(RFID)技术得到了广泛应用。标签碰撞问题严重影响RFID系统的识别效率,因此多标签防碰撞算法成为了研究RFID技术的关键。为此,提出了一种基于映射序列码的多叉树标签防碰撞算法,其主要思想是在多叉树的基础上,将阅读器识别范围内的标签识别码进行分组,根据唯一的映射关系确定存在的查询前缀,消除了多叉树的空闲时隙,减少了碰撞时隙;同时标签在响应阅读器时,只需要发送其与查询前缀相匹配后的剩余部分,减少了信息的传输量,降低了系统能耗。Matlab仿真结果表明,所提出的算法有效减少了标签识别的总时隙数,系统的识别效率可以达到71%左右,系统性能有了明显的提升,当标签识别码位数长,标签数量多时,算法性能的提升尤为显著。
射频识别;标签防碰撞;多叉树;映射关系
0 引 言
物联网是新一代信息技术的重要组成部分,即通过射频识别(RFID)、红外感应器、全球定位系统、激光扫描器、气体感应器等信息传感设备,按约定协议,把任何物品与互联网连接起来,进行信息交换和通讯,以实现智能化识别、定位、跟踪、监控和管理的一种网络。RFID技术、传感器技术、纳米技术、智能嵌入技术是实现物联网的四大核心技术。随着物联网技术和应用的不断深入,RFID技术已成为当前研究的热点[1]。
无线射频识别(Radio Frequency IDentification,RFID)技术是一种以空间电磁波为传输媒介的非接触式自动数据采集技术,系统间通过发送无线射频信号实现数据信息的自动识别和双向通信。典型的RFID系统主要由阅读器、电子标签和中央处理系统三大部分组成。当阅读器的作用范围内存在多个标签,并有一个以上的标签同时响应阅读器时将会产生碰撞,这种碰撞称为标签碰撞[2]。这种碰撞会导致阅读器不能成功识别标签,严重影响RFID系统的识别效率。
RFID防碰撞算法一般有基于空分多址(Space Division Multiple Access,SDMA)、频分多址(Frequency Division Multiple Access,FDMA)、码分多址(Code Division Multiple Access,CDMA)、时分多址(Time Division Multiple Access,TDMA)[3]等四种方式。其中TDMA应用最广泛。现有的防碰撞算法主要分为基于ALOHA的随机性算法和基于树的确定性算法。基于ALOHA的防碰撞算法[4]主要包括三种:纯ALOHA算法、帧时隙ALOHA算法和动态帧时隙ALOHA算法。基于树的防碰撞算法[5-6]主要包括二进制树(BT)算法和查询树(QT)算法,以及基于BT和QT进行改进的算法。
基于ALOHA的防碰撞算法需要一个时钟电路来解决同步问题,且存在一个致命缺点:由于标签长时间无法被阅读器识别而导致标签“饿死”。基于树的防碰撞算法不需要同步,并且解决了标签“饿死”问题,但仍存在识别周期长、标签能耗大等问题。
针对上述问题,提出了一种基于映射序列码的多叉树标签防碰撞算法。主要思想是在多叉树的基础上,将阅读器识别范围内的标签识别码进行分组,根据唯一的映射关系确定存在的查询前缀,消除多叉树的空闲时隙,减少碰撞时隙;同时标签在响应阅读器时,只需要发送其与查询前缀相匹配后的剩余部分,减少了信息的传输量,降低了系统能耗。
1 查询树算法
QT算法是一种无记忆算法,对标签计算能力的唯一要求就是将它的识别码与查询命令中的二进制序列进行比较[7],只有当二者一致时,标签才进行响应。当只有一个标签响应阅读器时,标签被成功识别;当有一个以上标签同时响应阅读器时,通过在原查询前缀的基础上加上一位1或0生成新的查询前缀,继续查询,直到成功识别所有的标签[8]。
QT算法的基本识别过程如下:阅读器初始化查询前缀堆栈为0和1,当堆栈不为空时,阅读器发送查询命令,堆栈中的查询前缀出栈并更新堆栈。若只有一个标签响应,则识别该标签;若有一个以上标签响应,则表明发生碰撞,分别在原查询前缀后加0和1作为新的查询前缀,并压入堆栈中;若没有标签响应,则不进行任何操作。重复以上操作,直到堆栈为空。当标签接收到阅读器的查询命令,判断自身的ID号和查询前缀是否一致,若一致则发送ID的剩余部分给阅读器,若不一致,则标签不响应。假设有四个标签A、B、C、D,它们的ID分别为0010、1010、1011、0101。则它们的识别过程如表1所示。
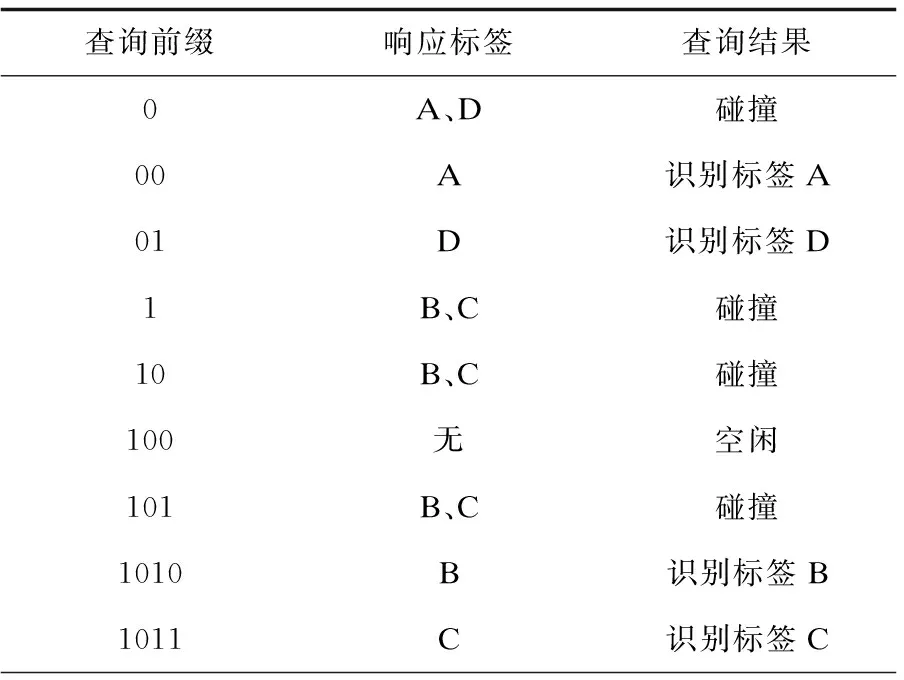
表1 查询树算法识别过程
从表1可以看出,成功识别四个ID长度为4的标签,需要9次查询,其中产生了过多的碰撞时隙,算法的运行时间较长,导致识别效率过低。为此,对QT算法进行了各种改进。Law C等提出了shortcuttingQT算法[9],若在阅读器查询前缀q时发生了碰撞,则在q后加上0和1继续查询。如果阅读器先查询q0,没有标签响应,则前缀为q1的标签至少为2个,肯定会发生碰撞,因此可以跳过前缀q1,直接查询前缀q10和q11,所以shortcuttingQT算法在一定程度上减少了查询次数,缩短了算法的运行时间。Jia等提出了一种CT算法[6],它的查询过程只针对碰撞位,使用查询前缀查询碰撞位,和QT算法相比,避免了对ID号相同部分的查询,减少了碰撞周期和空闲周期,提高了识别效率。另外,最坏的情况下,就是出现大量标签导致所有位都发生碰撞,这种情况下,CT算法的性能和QT算法相同。
2 基于多叉树的改进型防碰撞算法
2.1 算法描述
目前在查询树算法的基础上,提出了很多改进算法。文献[10]提出了一种基于分组码的改进型防碰撞算法,其主要思想是:首先采用分组码将标签识别码进行分组,根据碰撞位置可以确定存在的分组码,在八叉树的基础上,去除了空闲时隙,提高了识别效率。但是,在识别过程中,由于引入了分组码,产生了二次发送,增加了八叉树的时隙数。提出了基于多叉树的防碰撞算法,减少碰撞时隙的同时,引入了映射序列码,消除了空闲时隙,提高了算法的识别效率,同时减少了数据的通信量。
该算法包含分组操作和映射识别操作两个部分。
(1)分组操作。
所有标签先对识别码进行分组,每3比特标签识别码为一组,若最后剩余的标签识别码不足3比特时,剩余比特识别码为一组。假设长度为n的标签识别码为P1P2…Pn,则P1P2P3为第1组标签识别码,P4P5P6为第2组标签识别码,依次类推,若n=3k,则第k组为Pn-2Pn-1Pn,若n=3k-1,则第k组为Pn-1Pn,若n=3k-2,则第k组为Pn。
(2)映射识别操作。
阅读器发送Query(k)指令,第一次发送时k=1,标签将第1组3比特标签识别码的映射序列码发送给阅读器,映射关系如表2和表3所示。
阅读器对接收到的信息进行译码,得到初始查询前缀并压入堆栈。这里,阅读器利用曼彻斯特编码识别出具体碰撞位。假设三个标签分别为a:101,b:001,c:100,由映射关系表得到,它们的映射序列码分别为:a:00100000,b:00000010,c:00010000,阅读器得到译码结果为00XX00X0,可得存在101、100、001三种查询前缀。
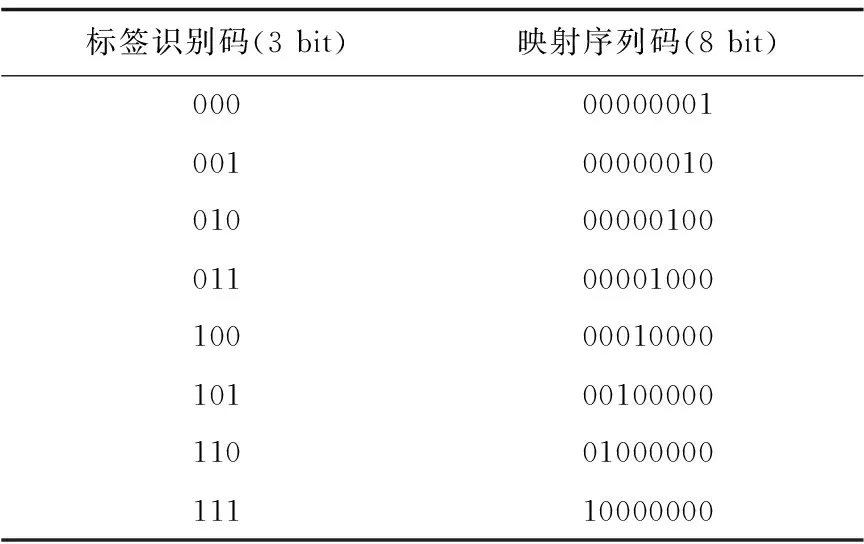
表2 映射关系表(1)
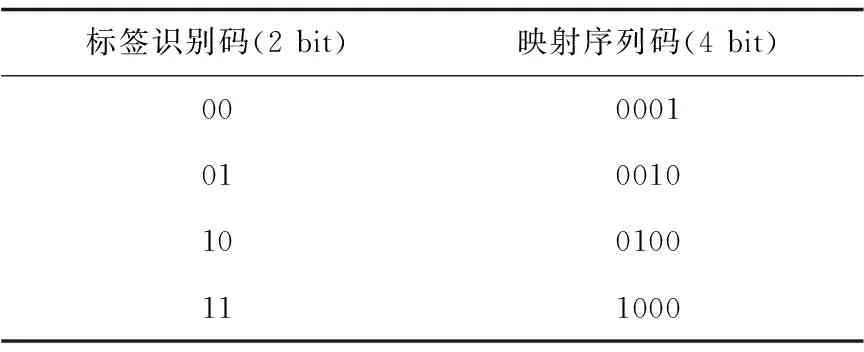
表3 映射关系表(2)
2.2 算法流程
(1)初始化查询前缀堆栈Q,阅读器发送Request(NULL)通信请求命令,使工作范围内的所有标签进行响应。
(2)阅读器发送Query(k)指令,将标签ID号的第k组标签识别码的映射序列码发送给阅读器,第一次发送时k=1,这个映射序列码准确地反映了标签的碰撞信息。阅读器收到映射序列码并进行译码,根据碰撞位置判断存在的查询前缀,然后依次压入查询前缀堆栈Q中。若k不等于1,则在原查询前缀PRE后加上第k组标签序列码得到新的查询前缀,并依次压入堆栈Q中。若第k组标签识别码为2bit,由映射序列码得到标签识别码,并依次压入堆栈。若第k组标签识别码为1bit,则直接识别两个标签。
(3)阅读器发送Request(PRE)命令,PRE取值为堆栈中的查询前缀,与查询前缀匹配的标签响应,检测是否发生碰撞,若没有发生碰撞,则发送标签ID的剩余部分给阅读器,成功识别标签;如果判断出有碰撞,则使k=k+1,发生碰撞的标签发送下一组标签ID的映射序列码给阅读器,跳回步骤2,直到标签被成功识别。
(4)判断堆栈Q是否为空,若不为空,则转回步骤3,若为空,则识别结束。
算法流程如图1所示。

图1 算法流程图
2.3 算法识别过程举例
假设有8个标签A、B、C、D、E、F、G、H在阅读器的工作域,标签ID号分别为:10110101,11100011,10100111,11011011,10000011,11010011,10010101,10011111。
算法查询过程如表4所示。
由表4可知,识别这8个标签一共查询了12次,其中产生3次碰撞,并去除了多叉树中的所有空闲时隙。与QT算法相比,减少了查询次数,提高了识别效率。

表4 算法查询过程
3 仿真分析
为了更好地验证改进算法的性能,通过Matlab仿真工具对该改进算法、shortcuttingQT算法、CT算法、四叉树算法、八叉树算法的各方面性能进行对比。
由文献[6]可知,CT算法识别n个标签所用的总时隙为:
T(n)=2n-1
(1)
算法识别效率为:

(2)
文献[11]对于多叉树的性能分析中,利用式(3)来计算总时隙数:

(3)
由式(4)得到算法的识别效率:
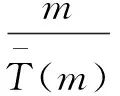
(4)
其中,B为叉数;L为当前所在的层数;m为标签总数。
将分别取B=4(四叉树)和B=8(八叉树)进行仿真。图2中对提出的改进算法以及shortcuttingQT算法、CT算法、四叉树算法、八叉树算法识别标签的总时隙进行了比较。
由图2可以看出,与其他四种算法相比,该改进算法需要的总时隙明显要少。当标签数量达到1 000时,该改进算法需要消耗1 390个总时隙,比QT算法少用了30.5%的时隙,比shortcuttingQT算法少用了接近40%的时隙,比四叉树算法少用了51.9%的时隙,和消耗总时隙最多的八叉树算法相比,节省了64.7%的时隙。该改进算法通过使用映射序列码,消除了空闲时隙,避免了无效查询,同时减少了查询所需的总时隙。所以,相比其他四种算法,使用了最少的识别总时隙,大大提高了算法的总体性能。

图2 五种算法总时隙性能比较
图3对所提出的改进算法以及shortcuttingQT算法、CT算法、四叉树算法、八叉树算法的识别效率(吞吐率)进行了比较。
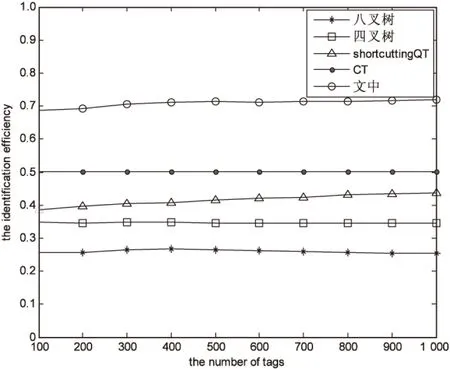
图3 五种算法识别效率比较
从图3可以看出,八叉树算法的识别效率最低,在25%~27%;而四叉树算法和shortcuttingQT算法的识别效率也都低于50%;CT算法的识别效率达到了50%;而改进算法的效率能达到71%左右,性能明显优于其他四种算法。
4 结束语
传统QT算法虽然解决了标签“饿死”问题,但是存在识别周期长、系统能耗大等缺点。为此,提出了一种基于映射序列码的RFID标签防碰撞算法,将标签识别码进行分组,再根据唯一的映射关系确定存在的查询前缀,消除了多叉树的空闲时隙,减少了碰撞时隙,提高了系统的识别效率。同时,标签在响应阅读器时,只需要发送匹配前缀后的剩余部分,降低了系统能耗,尤其是在标签识别码位数长,标签数量多时,算法性能达到最优。但是,在阅读器工作范围内,标签分布密度较小时,算法的识别效率出现不稳定。在后续工作中,可以结合碰撞跟踪技术[12-14],进一步提高算法的识别效率和总体性能。
[1] 宁焕生,徐群玉.全球物联网发展及中国物联网建设若干思考[J].电子学报,2010,38(11):2590-2599.
[2]AliK,HassaneinH,TahaAEM.RFIDanti-collisionprotocolfordensepassivetagenvironments[C]//32ndIEEEconferenceonlocalcomputernetworks.[s.l.]:IEEE,2007:819-824.
[3] 朱 军,张 元,卢小冬,等.基于分段搜索的多RFID标签抗冲突方法[J].计算机应用研究,2011,28(3):1031-1033.
[4] 程文青,赵梦欣,徐 晶.改进的RFID动态帧时隙ALOHA算法[J].华中科技大学学报:自然科学版,2007,35(6):14-16.
[5] 王 雪,钱志鸿,胡正超,等.基于二叉树的RFID防碰撞算法的研究[J].通信学报,2010,31(6):49-57.
[6]JiaX,FengQ,MaC.Anefficientanti-collisionprotocolforRFIDtagidentification[J].IEEECommunicationsLetters,2010,14(11):1014-1016.
[7] 苏 健,文光俊,韩佳利.一种基于ISO18000-6B标准的RFID防碰撞算法[J].电子学报,2014,42(12):2515-2519.
[8] 刘 淼.基于RFID的物联网感知层查询树防碰撞算法研究[D].长春:吉林大学,2013.
[9]LawC,LeeK,SiuKY.Efficientmemorylessprotocolfortagidentification[C]//Proceedingsofthe4thinternationalworkshopondiscretealgorithmsandmethodsformobilecomputingandcommunications.[s.l.]:ACM,2000:75-84.
[10] 张学军,王绪海,蔡文琦.基于分组码的改进型防碰撞算法研究[J].计算机应用研究,2012,29(11):4265-4268.
[11] 丁治国,郭 立,朱学永,等.基于二叉树分解的自适应防碰撞算法[J].电子与信息学报,2009,31(6):1395-1399.
[12]LaiYC,HsiaoLY,ChenHJ,etal.AnovelquerytreeprotocolwithbittrackinginRFIDtagidentification[J].IEEETransactionsonMobileComputing,2013,12(10):2063-2075.
[13]WangG,PengY,ZhuZ.Anti-collisionalgorithmforRFIDtagidentificationusingfastquerytree[C]//InternationalsymposiumonITinmedicineandeducation.[s.l.]:IEEE,2011:396-399.
[14]ChenWC,HorngSJ,FanP.Anenhancedanti-collisionalgorithminRFIDbasedoncounterandstack[C]//2007secondinternationalconferenceonsystemsandnetworkscommunications.[s.l.]:IEEE,2007:21.
Multi-tree Anti-collision Algorithm Based on Mapping Sequence Code
HE Shen-yan,YANG Heng-xin,ZHANG Yun
(College of Electronic Science and Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
With the development of Internet of Things,Radio Frequency Identification (RFID) has been widely used.Tag collision problems seriously affect the efficiency of RFID identification systems.As a result,multi-tag anti-collision algorithm becomes a key point in investigation of RFID technology.A multi-tree anti-collision algorithm based on mapping sequence code has been presented.With the main idea of multi-tree,tag identifiers within the range of reader have been grouped.According to the unique mapping relationship,existing query prefixes has been determined;idle slots of multi-tree have been eliminated and collision slots of multi-tree have been reduced.At the same time,tags only need to send the rest parts matching with the query prefix when responding to the reader.Thus,the amount of information transmission and energy consumption has been reduced.The results of Matlab simulation show that the proposed algorithm has effectively reduced the total slots of tag identification and significantly improved system performance,and that efficiency of identification reaches about 71%,which means this algorithm can achieve optimal performance especially since the length of tag identifier is long and the number of tags is large.
RFID;tag anti-collision;multi-tree;mapping relationship
2016-06-21
2016-09-28 网络出版时间:2017-03-13
国家自然科学基金青年科学基金项目(61302155)
何申炎(1992-),女,硕士研究生,研究方向为智能信息处理;杨恒新,副教授,研究方向为无线射频识别技术;张 昀,硕士生导师,研究方向为通信信号盲检测、神经网络和无线传感器网络等。
http://kns.cnki.net/kcms/detail/61.1450.tp.20170313.1547.086.html
TP301.6
A
1673-629X(2017)05-0054-05
10.3969/j.issn.1673-629X.2017.05.012
猜你喜欢
计算机工程与科学(2022年11期)2022-11-17
电子设计工程(2022年15期)2022-08-17
英语世界(2020年10期)2020-11-06
英语世界(2020年2期)2020-03-08
小读者之友(2019年9期)2019-09-10
东坡赤壁诗词(2018年6期)2018-12-22
意林·少年版(2018年1期)2018-02-07
计算机应用(2017年8期)2017-10-21
军事运筹与系统工程(2017年1期)2017-07-31
CHIP新电脑(2016年3期)2016-03-10
